
「Python实用秘技01」复杂zip文件的解压

添加微信号"CNFeffery"加入技术交流群
❝本文完整示例代码及文件已上传至我的
❞Github仓库https://github.com/CNFeffery/PythonPracticalSkills
这是我的新系列文章「Python实用秘技」的第1期,本系列立足于笔者日常工作中使用Python辅助办公的心得体会,每一期为大家带来一个3分钟即可学会的简单小技巧。
作为系列第1期,我们即将学习的是:复杂zip文件的解压。

废话不多说,直接看问题,使用过Python中的标准库zipfile解压过zip格式压缩包的朋友们,可能遇到过,当压缩文件中的目录或文件名中包含中文等常见unicode字符时,典型如下面的例子:
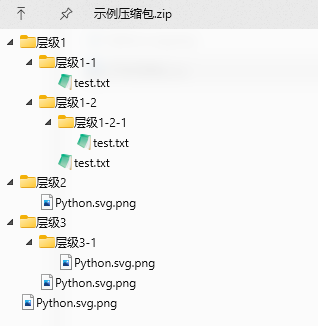
使用zipfile的extract()或extractall()方法直接解压时,产生的解压结果名充斥着乱码,这一点我们通过调用namelist()方法就可以看出来:
from zipfile import ZipFile
# 读入压缩包文件
file = ZipFile('示例压缩包.zip')
# 查看压缩包内目录、文件名称
file.namelist()

这是因为zipfile中针对压缩包内容的编码兼容性差,但我们可以通过下面的函数自行矫正:
def recode(raw: str) -> str:
'''
编码修正
'''
try:
return raw.encode('cp437').decode('gbk')
except:
return raw.encode('utf-8').decode('utf-8')
for file_or_path in file.namelist():
print(file_or_path, ' -------> ' , recode(file_or_path))
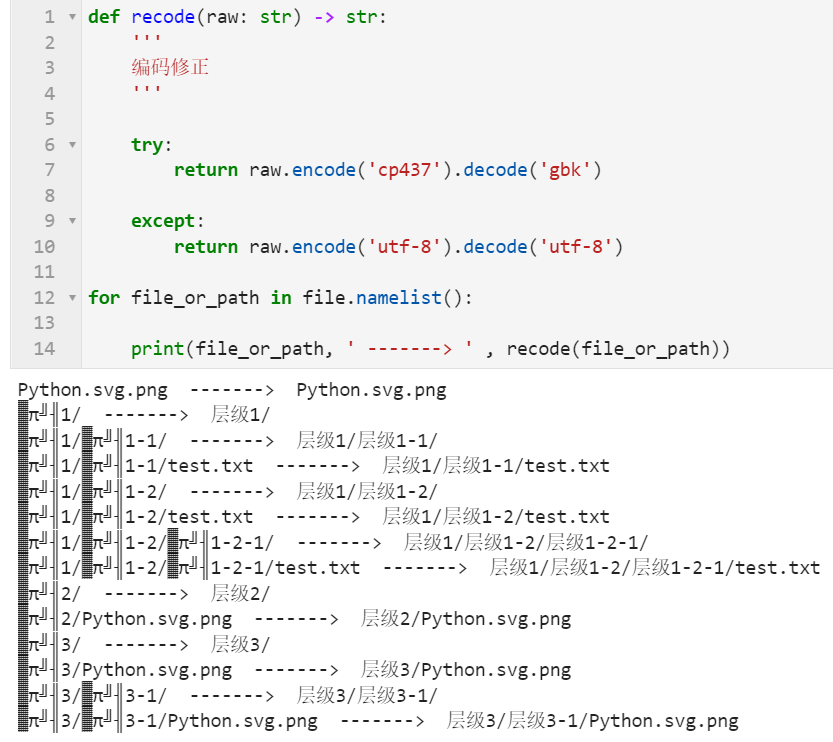
解决了文件名乱码的问题后,接下来我们就可以配合shutil与os标准库中的相关功能,实现将指定任意zip压缩包,完好地解压到指定的目录中,代码如下:
def zip_extract_all(src_zip_file: ZipFile, target_path: str) -> None:
# 遍历压缩包内所有内容
for file_or_path in file.namelist():
# 若当前节点是文件夹
if file_or_path.endswith('/'):
try:
# 基于当前文件夹节点创建多层文件夹
os.makedirs(os.path.join(target_path, recode(file_or_path)))
except FileExistsError:
# 若已存在则跳过创建过程
pass
# 否则视作文件进行写出
else:
# 利用shutil.copyfileobj,从压缩包io流中提取目标文件内容写出到目标路径
with open(os.path.join(target_path, recode(file_or_path)), 'wb') as z:
# 这里基于Zipfile.open()提取文件内容时需要使用原始的乱码文件名
shutil.copyfileobj(src_zip_file.open(file_or_path), z)
# 向已存在的指定文件夹完整解压当前读入的zip文件
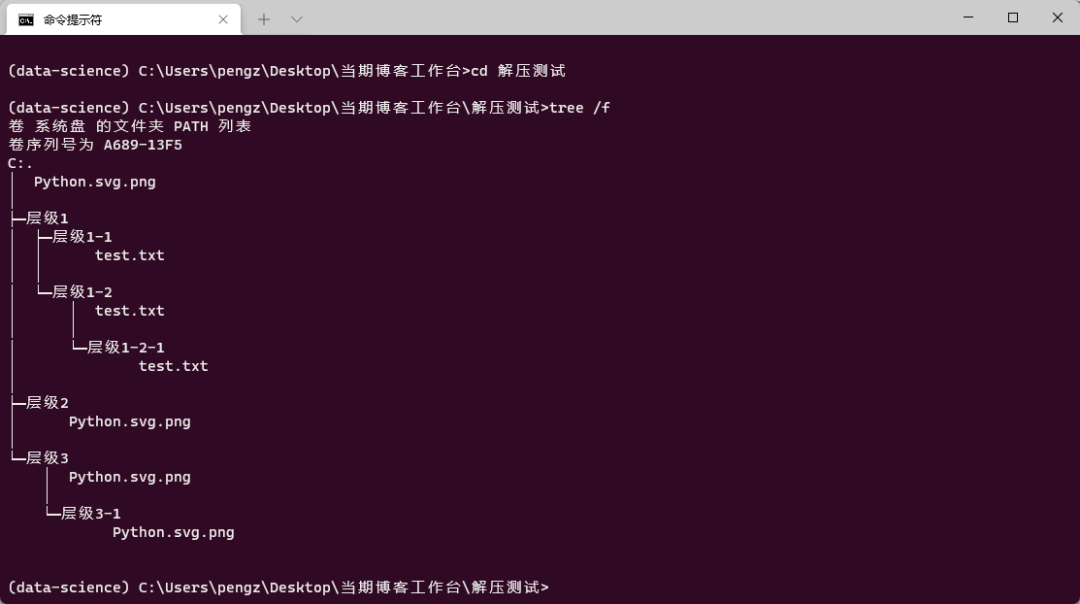
zip_extract_all(file, '解压测试')
可以看到,效果完美🥳:
本期分享结束,咱们下回见~👋
加入知识星球【我们谈论数据科学】
400+小伙伴一起学习!
· 推荐阅读 ·
评论