
持续测试之下的正确质量度量丨IDCF

来源:独行高飞
作者:CrissChan
比尔·盖茨曾经说过用代码行数来衡量软件的生产力,就像用飞机的重量来衡量飞机的生产进度一样。所以找到正确的度量质量的指标我们才能得到正确的质量结果。这就如同被很多人千行代码缺陷率遭到很多人的诟病一样,网上曾经有一个笑话就是说千行代码缺陷率的。
一个笑话

某公司有两个开发团队,团队间针对缺陷密度的千行代码缺陷率这个指标做对比,千行代码缺陷率高的团队扣奖金奖励给千行代码缺陷率低的团队。
在第一个月团队A的千行代码缺陷率高过了团队B,团队A的小伙伴很不情愿的被扣了绩效,但是团队B的成员却很开心。
在第二个月开始的时候,团队A的负责人就召集团队成员讨论对策,总不能每个月都被扣绩效奖金,最后讨论的结果就是将一些用递归、抽象等优秀的方法写的代码改成最原始的写法,这样通过增大千行代码缺陷率的分母来降低这个度量指标,果不其然,在第二个月月底统计的时候,团队A的千行代码缺陷率大幅度低于团队B,团队A终于报了仇,很是开心。
团队B的成员就觉得蹊跷,因此私下打听到了团队A的做法,因此团队B也决定效仿,但是就算这样肯定也无法低于团队A的千行代码缺陷率,在团队B内部不断的讨论中,他们决定将Tomcat源代码引入项目中,在千行代码缺陷率分母上占领绝对的统治地位。那么结果就是一来一往几个月下来公司因为项目代码写的越来越难以维护,无法按时交付很多需求,最后导致两个团队的项目都失败了,公司也因此关门大吉,但是团队A和团队B的项目代码仓库中有当前所有开源项目的源代码。
麦克纳马拉谬误
当然,上面只是一个笑话。但是这则笑话却说明了一个道理,你度量什么,就会得到什么。这也是著名的古德哈特定律的体现,古德哈特定律是说当一个度量成为目标,它就不再是一个好的度量。这也就是说如果一个指标被用作政策目标时,它很快就失去了捕捉被测量的现象或特征的能力,以经济学家查尔斯·古德哈特之名命名。他在1975年的一篇批判撒切尔货币政策文章中指出,一旦为控制它而对其施加压力,任何观察到的统计规律将会坍塌。这里面还有一个印度有关眼镜蛇的故事。
在殖民时期的印度,德里的眼镜蛇泛滥成灾。为了减少城里的眼镜蛇数量,当地政府的解决方案是奖励猎杀眼镜蛇。由于赏金足够慷慨,许多人开始猎捕眼镜蛇,这正好导致了预期的结果:眼镜蛇数量减少。随着眼镜蛇数量的下降,在野外寻找眼镜蛇变得越来越困难,人们开始变得相当有创业精神。他们开始在家里养眼镜蛇,然后像以前一样杀死眼镜蛇来领取赏金。地方当局意识到,在这个城市里已经很少有眼镜蛇,但他们支付赏金仍然像以前一样多。于是,地方官员决定取消赏金。其结果是人们把毫无价值的眼镜蛇放回野外,导致了比开始前更大的眼镜蛇问题。
在制定度量指标的时候,一旦一个指标被作为组织绩效的一部分被采纳,那么他就会导致行为的改变,从而发生不正当的激励,导致非计划内后果。所以在质量上既要有度量,更要选择正确的度量指标。
在度量质量的时候,除了要避免古德哈特定律也要避免麦克纳马拉谬误,麦克纳马拉谬误是指使可测量的重要而不是试图使重要的可测量。它由美国社会学家丹尼尔·扬克洛维奇(Daniel Yankelovich)于1972年提出,但直至1994年因管理大师查尔斯·汉迪《空雨衣》一书而广为流传。该谬论以曾任美国国防部部长的罗伯特·麦克纳马拉之名命名。麦克纳马拉谬论的描述如下:
第一步是测量任何容易测量的,这目前没有什么问题。
第二步是无视那些不容易测量的,或赋予它任意的数值,这是人为误导。
第三步是假设那些不容易测量的都不重要,这是盲目。
第四步是宣称不容易测量的不存在,这是自杀。
麦克纳马拉一生有着耀眼的履历。1937年毕业于美国加州大学伯克利分校、获得经济与哲学双学位,1939年获得美国哈佛大学工商管理硕士(MBA)。曾任福特汽车公司总裁,是该公司成立初期以来第一位担任该职位的非福特家族总裁。其后任美国国防部部长(1961年-1968年,为美国史上任期最久的国防部长),以及世界银行行长(1968年-1981年)。肯尼迪总统邀请麦克纳马拉担任国防部长,希望他能将他在福特公司使用的管理技术应用到美军的管理中,发起一场“麦克纳马拉革命(McNamara Revolution)”。在越战期间,他依据定量观察(或量度)做出决策,或以量化数据衡量成功,如击毙敌军的尸体数量,敌我双方死亡数量的比率等,但忽略了其他因素。其理由是这些其他因素无法得到证实。由此带来的误判是越战失利的原因之一。在度量指标的选取上要避免在灯下找钥匙,通过指定的度量指标将所有人的关注点集中在了灯光之下,这可能导致忽略不易测量或实际上不可测量的方面,即使它们同等重要或更重要。那么对于一个持续迭代的项目的度量指标,最本质的选取原则就是度量的好处要大于成本,如果度量的成本超过了益处,必将导致很多偷奸取巧的办法出现。
设计一些“测谎题”
20世纪80年代,范·海伦是一个超级巨星乐队,《滚石》杂志中曾经写过,他们出现在哪里,盛大、喧闹的狂欢都会跟随。那么每次他们和其他合作商开演唱会的时候都会提供一个有50页附件的巡演合同,合同中有常规的安保要求、技术细节之外,有一些很特别的内容,例如在零食的要求部分他们指定了薯片、坚果、蝴蝶饼和M&M巧克力豆,在边上还有一个超级醒目的特别注释:绝对不要棕色的。这份要求被一些合作商宣传出来大家都认识为范·海伦在耍大牌,难道棕色的巧克力豆和其他颜色的味道不一样吗?这个我相信大家的答案都是否定的。其实这是因为,范·海伦的演唱会利用了很多先进的技术设计规模庞大、思维超前,以便能够造就盛大的狂欢效果,因此他们才需要50多页附件,为了能确保合作商能够详细看过附件,他们的棕色巧克力豆就是验证条件,如果他们到达了演出场地,看到了有装有棕色巧克力豆的碗,那么说明合作商根本没有好好看他们的附件,因此他们就需要花费更多的精力去检查全部的设备是否安装合格。
从而可以看出,度量以及一些测谎度量的设置也是很重要的。回到开始的笑话,如果团队的度量是驱使大家用优秀的编码实践去考察千行代码缺陷率,那么也并不会导致一切皆输的地步,因此这么多的度量指标,也是相互制约的,这就和很多心理测试问卷一样,他里面有很多来衡量受测者心理是不是健康之外,还有很多是测谎题,来考察受测者是不是说谎了。也就是说在整体的度量指标的选择中,千行代码缺陷率可以选择,但是一定要有一个可以制约笑话中的问题的指标来做“测谎题”。综合了上述全部的对于度量指标的选取的原则和定律之上。
质量度量指标
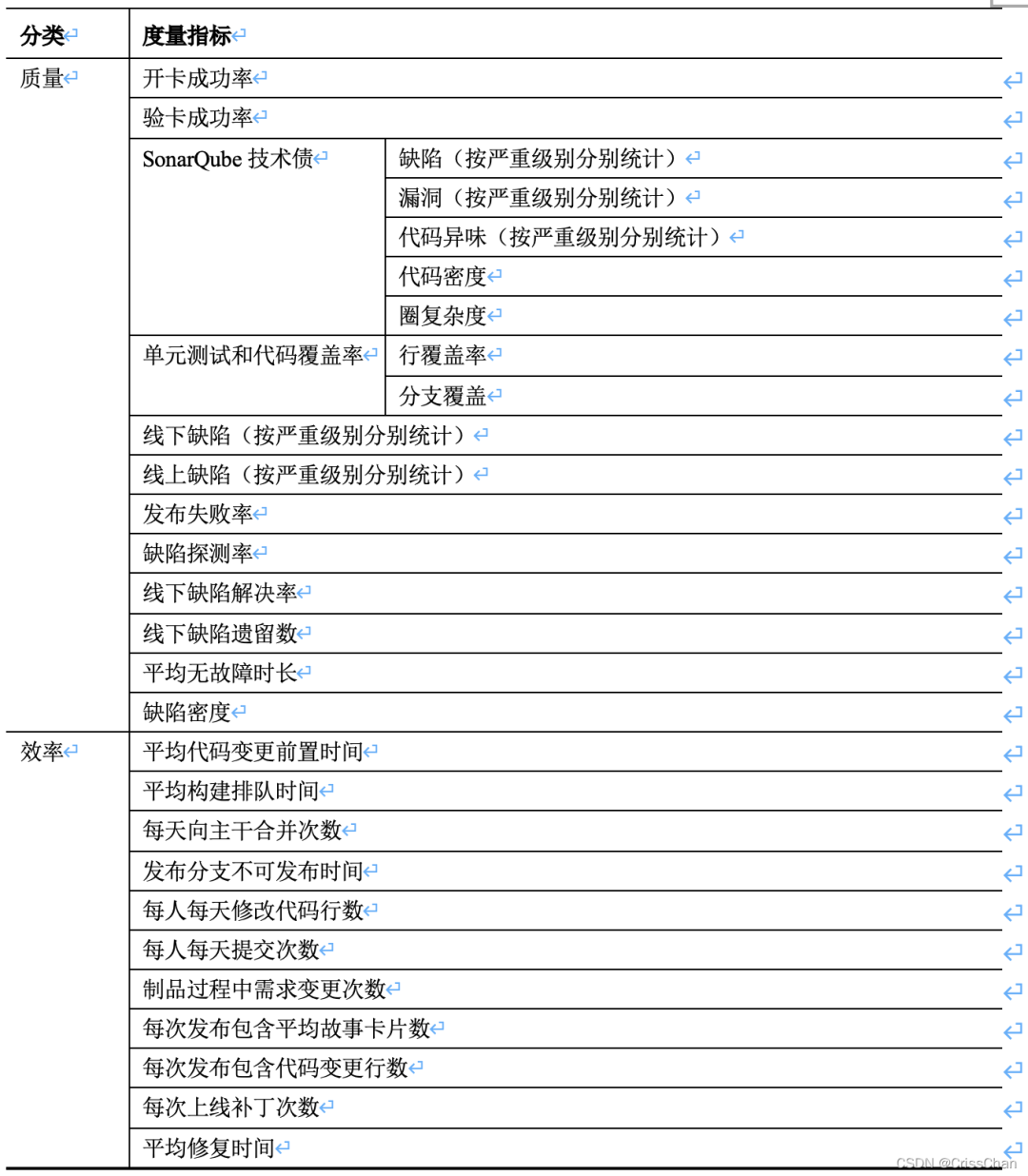 分别在质量和效率两个方向制定这几十个指标,每一个指标的制定都有它自己的度量角度,具体如下:
分别在质量和效率两个方向制定这几十个指标,每一个指标的制定都有它自己的度量角度,具体如下:
开卡成功率,主要是指在测试左移的时候,在开卡阶段,每次开卡都能够顺利完成将需求故事卡片移动进入看板中的开发负责的泳到中。如果开卡失败,那么需要产品经理继续补充完善后,再次开卡,那么这就不算开卡成功,因此开卡成功率是由第一次开卡就可顺利进入开发负责泳道的需求故事卡片数量除以进入开卡的需求故事卡总数量。这个值越接近1,说明需求故事卡片设计的很完善,产品经理的产出物质量很好。
验卡成功率,是指在测试左移的时候,在验卡阶段,每次验卡都能够顺利完成将需求故事卡片移动进入看板中的测试负责的泳到中。如果验卡失败,那么需要开发完善实现后,再次验卡,那么这就不算验卡成功,因此验卡成功率是由第一次验卡就可顺利进入测试负责泳道的需求故事卡片数量除以进入验卡的需求故事卡总数量。这个值越接近1,说明研发实现的代码完善,并且符合需求故事卡片的要求。
SonarQube技术债包含缺陷、漏洞、代码异味,这些都是按照组织级的约定统一承诺要遵守的规范而制定的,因此出现了类似的技术债务,只能说明有没有遵守组织约定的代码,因此按照严重级别按照从高到低分为阻塞级、严重级、主要级、次要级、提示级,项目中缺陷、漏洞、代码异味越少,或者存在的上述技术债务级别越低,那说明项目的静态质量越好。SonarQube技术债还包含了代码密度,这主要是说么代码有多少是重复的,越多的重复说明项目应该进行代码抽象,因此需要重新设计所以代码密度也是稍微低一点为好,但是也没必要追求这个指标必须是零。圈复杂度也叫条件复杂度,是有由托马斯·J·麦凯布于1976年提出,用来表示程序的复杂度,它是衡量一个模块判定结构的复杂程度,数量上表现为独立现行路径条数,也可理解为覆盖所有的可能情况最少使用的测试用例数。圈复杂度大说明程序代码的判断逻辑复杂,可能质量低且难于测试和维护,因此圈复杂度稍微低一点可以为一个交付更好质量的系统的加分。
单元测试和代码覆盖率,单元测试毋庸置疑是分层测试第一层测试,通过代码覆盖率来评价,在这里行覆盖和分支覆盖是比较常用的判定条件,其他覆盖也并不是不可取,只是既关注了行覆盖,也关注了分支覆盖也就说明单元测试是一个既能满足每一行都覆盖还能满足每一个逻辑分支都覆盖了,这是程序实现的最基本的两个角度。在实际项目中,分支覆盖比较推荐是100%,除非有一些异常捕获、预留代码、工具生成代码部分可以放宽一些标准,那么在行覆盖上,推荐达到60%到80%的行覆盖,但是这个也是分不同团队和开发的逻辑复杂度的,也并不是一概而论的一个指标。
线下缺陷,开发过程中发现的缺陷,这里的开发过程中是在制品中代码编译打包后对外提供服务阶段,这个阶段的缺陷有致命、严重、一般、建议四个级别,也分按照严重级别分别统计,这里并不是希望这个过程的数据越少越好,这就如同一个测谎指标一样,收集这个数量重点是为了证明制品过程质量保障是行之有效的。
线上缺陷,系统上线后系统出现的缺陷,这个阶段的缺陷有可能是客户发现的也有可能是制品团队的成员发现的,同样采取了线下缺陷的严重程度的级别定义分为致命、严重、一般、建议四个级别,在交付系统过程中,团队都希望交付出去的系统没有问题,因此线上缺陷还是一追准零为目标的。
发布失败率,这是指在发布新的变更的时候,无论是人工发布还是流水线自动发布,都希望一次发不成功而不是发现发布失败后再修复问题后发布,这里的发布即包含了一次全量发布,也包含了灰度发布,灰度发布仅仅是提高了客户感知的系统质量,但是并没有从真正意义上提高发布成功的次数,发布失败率是由第一次发布失败的次数除以共发布的版本数量而计算得出的,在团队中当然都系统一次交付成功,因此这个指标所有的团队也都在追逐零的目标。
缺陷探测率,DDP是Defect Detection Percentage的缩写,这是一个计算指标,是由线下缺陷除以线下缺陷和线上缺陷之和,DDP越高,说明测试者发现的Bugs数目越多,发布后客户发现的Bugs就越少,实现了越早发现问题解决起来成本越低的改进目标,达到了节约总成本的目的,因此高的缺陷探测率是团队追逐的目标,但是测试在超过95%的探测率,每提升1%的覆盖率,基本成本翻一倍,因此在具体度量指标的选取上还需要更加慎重。
线下缺陷解决率,这个是说有测试工程师发现的缺陷在系统发布变更前被修复的比例,通过已经修复的缺陷数量除以总共发现的线下缺陷数量所得的结果。这个指标主要是度量团队交付制品中遗留一致问题的比例,这个比例是越接近于1越好。
线下缺陷遗留数,这里所指的是一直是问题,但是并不修改,要“带病上场”的变更,这个数量主要是为了评估上线风险的,当然每个团队都希望每个迭代这个指标是零。
平均无故障时间是指在正常运行过程中,系统从一个先前故障到下一个故障之间经过的预期时间。平均无故障时间是通过总运行时间除以失败次数计算而来的,主要用于未预见故障,但不考虑因例行定期维护或例行预防性升级而停机的服务。平均无故障时间衡量可用性和可靠性。平均无故障时间值越高,系统在发生故障前运行的时间就越长。假设系统在上线后的100个小时里,发生了3次故障导致10个小时无法对外提供服务,那么平均无故障时间等于(100-10)/3,所以平均无故障时间是30小时。
缺陷密度,常用的千行代码缺陷率,计算方法是缺陷数量除以变更代码行数,前面已经介绍了这个不好的度量指标,这里为什么还要推荐呢?这是因为在整个度量指标的选取中设计了“测谎题”,就是下面的每天向主干合并次数、发布分支不可发布时间、每人每天修改代码行数、每人每天提交次数等指标才会让这个指标变得有意义而且是一个正确方向的度量。
平均代码变更前置时间,一次代码变更从提交到部署所需的时间的总和除以变更次数,在当前自动化流水线的支持下,一般也就需要分钟级别的时间就可以完成从提交到部署,一般不会超过30分钟,如果时间很长到了小时级别,那么肯定说明急需改进的地方提高效率,这个指标也是越小越好,但是肯定不会等于零。
平均构建排队时间,代码变更在执行构建之前的等待时间,变更提交后排队等待构建时间的总和除以提交变更的次数获得,这个指标高度依赖于组织的规模,以及同时并行开发的特性的数量。长时间的排队就会造成成本的浪费,因此团队希望这个是指标越小越好。
每天向主干合并次数,这个说明了开发人员完成需求故事卡的速度,这个次数也并没有好坏之分,但是还是希望团队中的数据都差不多,这样可以保证持续交付变更,这个度量指标在很多互联网公司也都是小于1的。
平均发布分支不可发布时间,这个是指标主要是来衡量主干见过多久才可以发布,也是为研发效能的提升提供有力的依据。这个时间越短说明代码可发布的窗口期越长,交付的制品质量越好,流水线的流畅度越高。
每人每天修改代码行数,这种是在衡量团队平均生产效率,重点是为了其他指标的“测谎”而存在,facebook的Android 和 iOS 开发人员每天每人分别平均生产 70 行代码和 64.7 行代码。如果有了大量代码的增加,那么就要考了是不是有人大面积复制了代码,或者加入很多无用代码。
每人每天提交次数这个指标也是一个“测谎题”,facebook的Android 和 iOS 的开发人员每人每天分别平均提交0.7次和0.8次。
制品过程中需求变更次数,在已经进入在制品的需求,如果要发生变更比较会付出一些额外的成本,那么这个次数可以提升成本浪费的次数。
每次发布包含平均故事卡片数,这可以衡量团队每个迭代的制品速率,方便评估团队的容量。
每次发布包含平均代码变更行数,这样可以评估项目的复杂程度和维护难易度,同时也可以承担“测谎题”的作用
每次上线补丁次数,每次发布版本后到下一次发布版本前,一共为了修复缺陷、维护数据,修复故障等为系统提供补丁的次数。
平均修复时间,指修复系统并将其恢复到完整功能所需的时间量。这包括修复时间、测试时间和恢复正常工作状态所需要的时间周期。平均修复时间是通过维护时间总和除以维护次数得到的。平均修复时间用来衡量系统的可用性,时间越短,说明系统可用性越高。
如上的指标,只是一些质量度量的常用指标,并不是必须的指标,那么选取那些应该以团队中适合为主,而不应该照本宣科,否则就会出现古德哈特定律和麦克纳马拉谬误的错误了。

超级工程师实战营第六模块【测试模块】邀请到测试、敏捷及DevOps专家 陈晓鹏老师带来3小时大时段课程分享,主题是《敏捷环境下的测试自动化实践指南》
6月28日(周二)和6月29日(周三)晚上19:30-21:00,线上直播,扫码立即报名,精彩内容,不容错过