
Prometheus 存储层的演进
Prometheus 是当下最流行的监控平台之一,它的主要职责是从各个目标节点中采集监控数据,后持久化到本地的时序数据库中,并向外部提供便捷的查询接口。本文尝试探讨 Prometheus 存储层的演进过程,信息源主要来自于 Prometheus 团队在历届 PromConf 上的分享。
时序数据库是 Promtheus 监控平台的一部分,在了解其存储层的演化过程之前,我们需要先了解时序数据库及其要解决的根本问题。
TSDB
时序数据库 (Time Series Database, TSDB) 是数据库大家庭中的一员,专门存储随时间变化的数据,如股票价格、传感器数据、机器状态监控等等。时序 (Time Series) 指的是某个变量随时间变化的所有历史,而样本 (Sample) 指的是历史中该变量的瞬时值:
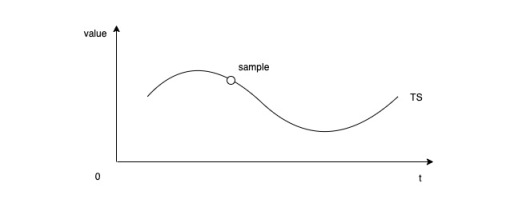
每个样本由时序标识、时间戳和数值 3 部分构成,其所属的时序就由一系列样本构成。由于时间是连续的,我们不可能、也没有必要记录时序在每个时刻的数值,因此采样间隔 (Interval) 也是时序的重要组成部分。采样间隔越小、样本总量越大、捕获细节越多;采样间隔越大、样本总量越小、遗漏细节越多。以服务器机器监控为例,通常采样间隔为 15 秒。
数据的高效查询离不开索引,对于时序数据而言,唯一的、天然的索引就是时间 (戳)。因此通常时序数据库的存储层相比于关系型数据库要简单得多。仔细思考,你可能会发现时序数据在某种程度上就是键值数据的一个子集,因此键值数据库天然地可以作为时序数据的载体。通常一个时序数据库能容纳百万量级以上的时序数据,要从其中搜索到其中少量的几个时序也非易事,因此对时序本身建立高效的索引也很重要。
The Fundamental Problem of TSDBs
TSDB 要解决的基本问题,可以概括为下图:

研究过存储引擎结构和性能优化的工程师都会知道:
许多数据库的奇技淫巧都是在解决内存与磁盘的读写模式、性能的不匹配问题
时序数据库也是数据库的一种,只要它想持久化,自然不能例外。但与键值数据库相比,时序数据库存储的数据有更特殊的读写特征,Björn Rabenstein 将称其为:
Vertical writes, horizontal(-ish) reads 垂直写,水平读
图中每条横线就是一个时序,每个时序由按照 (准) 固定间隔采集的样本数据构成,通常在时序数据库中会有很多活跃时序,因此数据写入可以用一个垂直的窄方框表示,即每个时序都要写入新的样本数据;用户在查询时,通常会观察某个、某几个时序在某个时间段内的变化趋势,或对其进行聚合计算,因此数据读取可以用一个水平的方框表示。是谓 “垂直写、水平读”。
Storage Layer of Prometheus
Prometheus 是为云原生环境中的数据监控而生,在其设计过程中至少需要考虑以下两个方面:
1、在云原生环境中,实例可能随时出现、消失,因此时序也可能随时出现或消失,即系统中存在大量时序,其中部分处于活跃状态,这会在多方面带来挑战:
如何存储大量时序避免资源浪费 如何定位被查询的少数几个时序
2、监控系统本身应该尽量少地依赖外部服务,否则外部服务失效将引发监控系统失效
对于第 2 点,Prometheus 团队选择放弃集群,使用单机架构,并且在单机系统中使用本地 TSDB 做数据持久化,完全不依赖外部服务;第 1 点是需要存储、索引、查询引擎层合作解决的问题,在下文中我们将进一步分析存储层在其中的作用。Prometheus 存储层的演进可以分成 3 个阶段:
1st Generation: Prototype 2nd Generation: Prometheus V1 3rd Generation: Prometheus V2
注意:本节只关注 Prometheus 时序数据的存储,不涉及索引、WAL 等其它数据的存储。
Data Model
尽管数据模型是存储层之上的抽象,理论上它不应该影响存储层的设计。但理解数据模型能够帮助我们更快地理解存储层。
在 Prometheus 中,每个时序实际上由多个标签 (labels) 标识,如:
api_http_requests_total{path="/users",status=200,method="GET",instance="10.111.201.26"}
该时序的名字为 api_http_requests_total,标签为 path、status、method 和 instance,只有时序名字和标签键值完全相同的时序才是同一个时序。事实上,时序名字就是一个隐藏标签:
{name="api_http_requests_total",path="/users",status=200,method="GET", instance="10.111.201.26"}
对于用户来说,标签之间不存在先后顺序,用户可能关注:
所有 api 调用的 status 某个 path 调用的成功率、QPS 某个实例、某个 path 调用的成功率 …
1st Generation: Prototype
在 Prototype 阶段,Prometheus 直接利用开源的键值数据库 (LevelDB) 作为本地持久化存储,并采用与 BigTable 推荐的时序数据方案 类似的 schema 设计:

将时序名称、标签 (固定顺序)、时间戳拼接成每个样本的键,于是同一个时序的数据就能够连续存储在键值数据库中,提高范围查询的效率。但从图中可以看出,这种方式存储的键很长,尽管键值数据库内部会对数据进行压缩,但是在内存中这样存储数据很浪费空间,这无法满足项目的设计要求。Prometheus 希望在内存中压缩数据,使得内存中可以容纳更多活跃的时序数据,同时在磁盘中也能按类似的方式压缩编码,提高效率。时序数据比通用键值数据有更显著的特征。即使键值数据库能够压缩数据,但针对时序数据的特征,使用特殊的压缩算法能够取得更好的压缩率。因此在 Prototype 阶段,使用三方键值数据库的方案最终流产。
2nd Generation: Prometheus V1
Compression
Why Compression
假设监控系统的需求如下:
500 万活跃时序 30 秒采样间隔 1 个月数据留存
那么经过计算可以得到具体的存储要求:
平均每秒采集 166000 个样本 存储样本总量为 4320 亿个样本
假设没有任何压缩,不算时序标识,每个样本需要 16 个字节存储空间 (时间戳 8 个字节、数值 8 个字节),整个系统的存储总量为 7TB,假设数据需要留存 6 个月,则总量为 42 TB,那么如果能找到一种有效的方式压缩数据,就能在单机的内存和磁盘中存放更多、更长的时序数据。
Chunked Storage Abstraction
上文提到 TSDB 的根本问题是 “垂直写,水平读”,每次采样都会需要为每个活跃时序写入一条样本数据,但如果每次为每个时序写入 16 个字节到 HDD/SSD 中,显然这对块存储设备十分不友好,效率低下。因此 Prometheus V2 将数据按固定长度切割相同大小的分段 (Chunks),方便压缩、批量读写。
访问时序数据时,Prometheus 使用 3 层抽象,如下图所示:
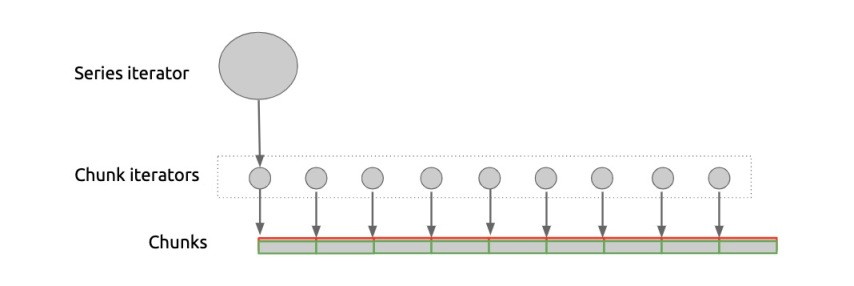
应用层使用 Series Iterator 顺序访问时序中的样本,而 Series Iterator 底下由一个个 Chunk Iterator 拼接而成,每个 Chunk Iterator 负责将压缩编码的时序数据解码返回。这样做的好处是,每个 Chunk 甚至可以使用完全不同的方式编码,方便开发团队尝试不同的编码方案。
Timestamp Compression: Double Delta
由于通常数据采样间隔是固定值,因此前后时间戳的差值几乎固定,如 15s,30s。但如果我们更近一步,只存储差值的差值,那么几乎不用再为新的时间戳花费额外的空间,这便是所谓的 “Double Delta“。本质上,如果未来所有的采集时间戳都可以精准预测,那么每个新时间戳的信息熵为 0 bit。但现实并不完美,网络可能延迟、中断,实例可能遇到 GC、重启,采样间隔随时有可能波动:
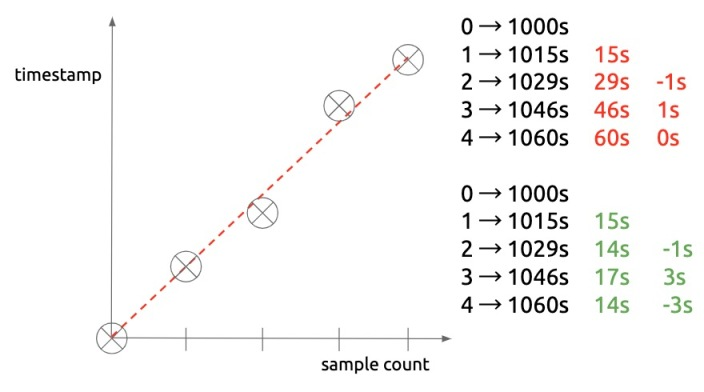
但这种波动的幅度有限,Prometheus 采用了和 FB 的内存时序数据库 Gorilla 类似的方式编码时间戳,详情可以参考 Gorilla) 以及 Björn Rabenstein 在 PromConn 2016 的演讲 ppt ,细节比较琐碎,这里不赘述。
Value Compression
Prometheus 和 Gorilla 中的每个样本值都是 float64 类型。Gorilla 利用 float64 的二进制表示 (IEEE754) 将前后两个样本值 XOR 来寻找压缩的空间,能获得 1.37 bytes/sample 的压缩能力。Prometheus V2 采用的方式比较简单:
如果可能的话,使用整型 (8/16/32 位) 存储,否则用 float32,最后实在不行就直接存储 float64 如果数值增长得很规律,则不使用额外的空间存储
以上做法给 Prometheus V1 带来了 3.3 bytes/sample 的压缩能力。相比于为完全存储于内存中的 Gorilla 相比,这样的压缩能力对于 Prometheus 已经够用,但在 V2 中,Prometheus 也融合了 Gorilla 采用的压缩技术。
Chunk Encoding
Prometheus V1 将每个时序分割成大小为 1KB 的 chunks,如下图所示:
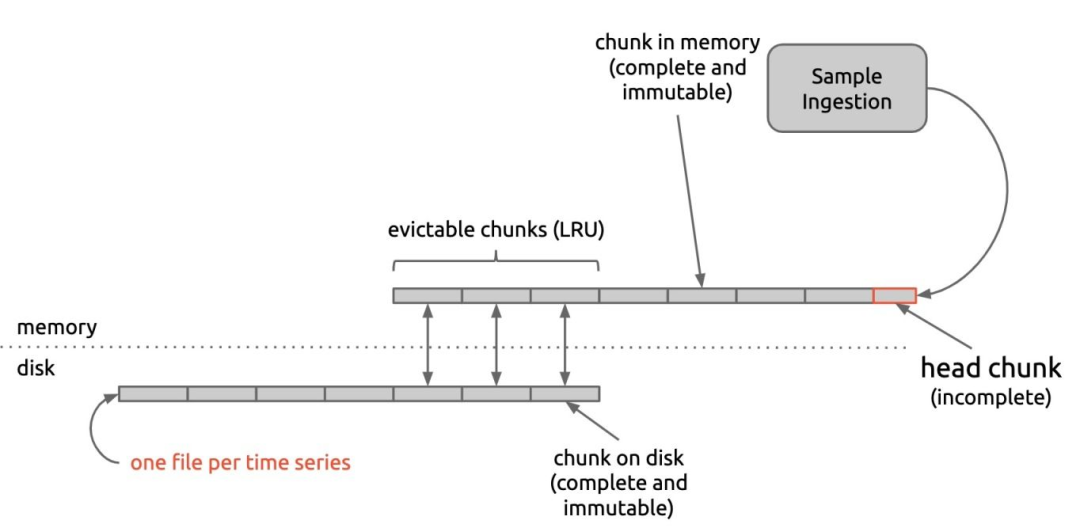
在内存中保留着最近写入的 chunk,其中 head chunk 正在接收新的样本。每当一个 head chunk 写满 1KB 时,会立即被冻结,我们称之为完整的 chunk,从此刻开始该 chunk 中的数据就是不可变的 (immutable) ,同时生成一个新的 head chunk 负责消化新的请求。每个完整的 chunk 会被尽快地持久化到磁盘中。内存中保存着每个时序最近被写入或被访问的 chunks,当 chunks 数量过多时,存储引擎会将超过的 chunks 通过 LRU 策略清出。
在 Prometheus V1 中,每个时序都会被存储到在一个独占的文件中,这也意味着大量的时序将产生大量的文件。存储引擎会定期地去检查磁盘中的时序文件,是否已经有 chunk 数据超过保留时间,如果有则将其删除 (复制后删除)。
Prometheus 的查询引擎的查询过程必须完全在内存中进行。因此在执行之前,存储引擎需要将不在内存中的 chunks 预加载到内存中:
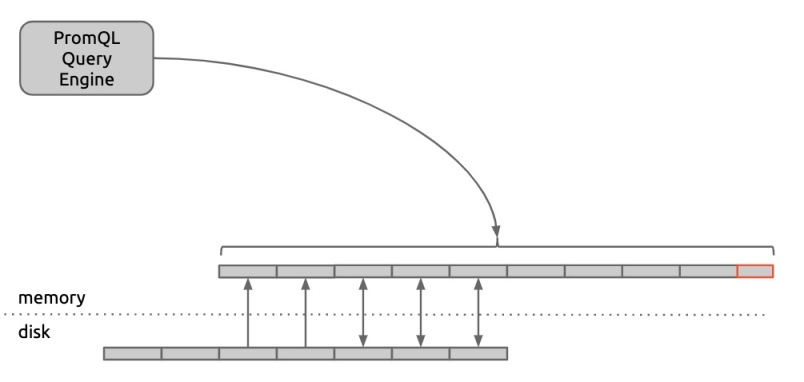
如果在内存中的 chunks 持久化之前系统发生崩溃,则会产生数据丢失。为了减少数据丢失,Prometheus V1 还使用了额外的 checkpoint 文件,用于存储各个时序中尚未写入磁盘的 chunks:
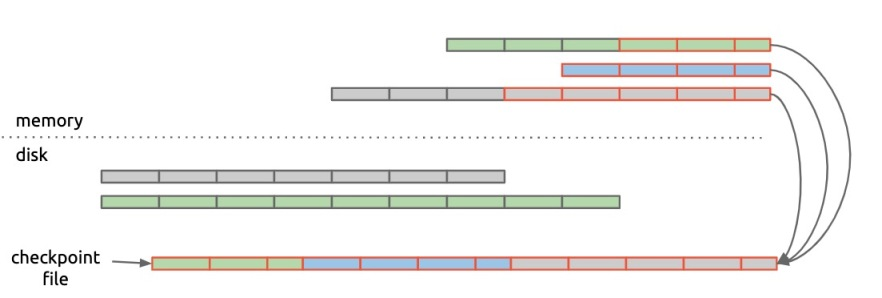
Prometheus V1 vs. Gorilla
正因为 Prometheus V1 与 Gorilla 的设计理念、需求有所不同,我们可以通过对比二者来理解其设计过程中使用不同决策的原因。

3rd Generation: Prometheus V2
The Main Problem With 2nd Generation
Prometheus V1 中,每个时序数据对应一个磁盘文件的方式给系统带来了比较大的麻烦:
由于在云原生环境下,会不断产生新的时序、废弃旧的时序 (Series Churn),因此实际上存储层需要的文件数量远远高于活跃的时序数量。任其发展迟早会将文件系统的 inodes 消耗殆尽。而且一旦发生,恢复系统将异常麻烦。不仅如此,在新旧时序大量更迭时,由于旧时序数据尚未从内存中清出,系统的内存消耗量也会飙升,造成 OOM。 即便使用 chunks 来批量读写数据,从整体上看,系统每秒钟仍要向磁盘写入数千个 chunks,造成 I/O 压力;如果通过增大每批写入的量来减少 I/O 次数,又将造成内存的压力。 同时将所有时序文件保持打开状态很不合理,需要消耗大量的资源。如果在查询前后打开、关闭文件,又会增加查询的时延。 当数据超过留存时间时需要删除相关的 chunks,这意味着每隔一段时间就要对数百万的文件执行一次删除数据操作,这个过程可能需要持续数小时。 通过周期性地将未持久化的 chunks 写入 checkpoint 文件理论上确实可以减少数据丢失,但是如果执行数据恢复需要很长时间,那么实际上又错过了新的数据,还不如不恢复。
因此 Prometheus 的第三代存储引擎,主要改变就是放弃 “一个时序对应一个文件” 的设计理念。
Macro Design
第三代存储引擎在磁盘中的文件结构如下图所示:

根目录下,顺序排列着编了号的 blocks,每个 block 中包含 index 和 chunk 文件夹,后者里面包含编了号的 chunks,每个 chunk 包含许多不同时序的样本数据。其中 index 文件中的信息可以帮我我们快速锁定时序的标签及其可能的取值,进而找到相关的时序和持有该时序样本数据的 chunks。值得注意的是,最新的 block 文件夹中还包含一个 wal 文件夹,后者将承担故障恢复的职责。
Many Little Databases
第三代存储引擎将所有时序数据按时间分片,即在时间维度上将数据划分成互不重叠的 blocks,如下图所示:
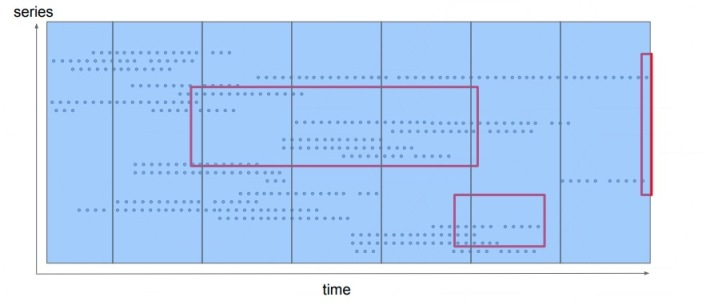
每个 block 实际上就是一个小型数据库,内部存储着该时间窗口内的所有时序数据,因此它需要拥有自己的 index 和 chunks。除了最新的、正在接收新鲜数据的 block 之外,其它 blocks 都是不可变的。由于新数据的写入都在内存中,数据的写效率较高:
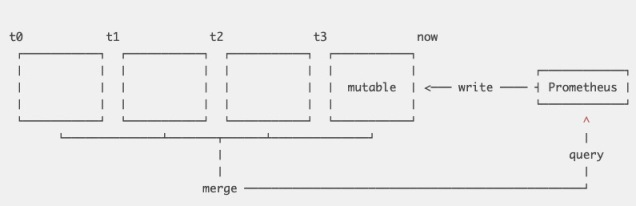
为了防止数据丢失,所有新采集的数据都会被写入到 WAL 日志中,在系统恢复时能快速地将其中的数据恢复到内存中。在查询时,我们需要将查询发送到不同的 block 中,再将结果聚合。
按时间将数据分片赋予了存储引擎新的能力:
当查询某个时间范围内的数据,我们可以直接忽略在时间范围外的 blocks 写完一个 block 后,我们可以将轻易地其持久化到磁盘中,因为只涉及到少量几个文件的写入 新的数据,也是最常被查询的数据会处在内存中,提高查询效率 (第二代同样支持) 每个 chunk 不再是固定的 1KB 大小,我们可以选择任意合适的大小,选择合适的压缩方式 删除超过留存时间的数据变得异常简单,直接删除整个文件夹即可
mmap
第三代引擎将数百万的小文件合并成少量大文件,也让 mmap 成为可能。利用 mmap 将文件 I/O 、缓存管理交给操作系统,降低 OOM 发生的频率。
Compaction
在 Macro Design 中,我们将所有时序数据按时间切割成许多 blocks,当新写满的 block 持久化到磁盘后,相应的 WAL 文件也会被清除。写入数据时,我们希望每个 block 不要太大,比如 2 小时左右,来避免在内存中积累过多的数据。读取数据时,若查询涉及到多个时间段,就需要对许多个 block 分别执行查询,然后再合并结果。假如需要查询一周的数据,那么这个查询将涉及到 80 多个 blocks,降低数据读取的效率。
为了既能写得快,又能读得快,我们就得引入 compaction,后者将一个或多个 blocks 中的数据合并成一个更大的 block,在合并的过程中会自动丢弃被删除的数据、合并多个版本的数据、重新结构化 chunks 来优化查询效率,如下图所示:

Retention
当数据超过留存时间时,删除旧数据非常容易:

直接删除在边界之外的 block 文件夹即可。如果边界在某个 block 之内,则暂时将它留存,知道边界超出为止。当然,在 Compaction 中,我们会将旧的 blocks 合并成更大的 block;在 Retention 时,我们又希望能够粒度更小。所以 Compaction 与 Retention 的策略之间存在着一定的互斥关系。Prometheus 的系统参数可以对单个 block 的大小作出限制,来寻找二者之间的平衡。
看到这里,相信你已经发现了,这不就是 LSM Tree **吗?**每个 block 就是按时间排序的 SSTable,内存中的 block 就是 MemTable。
Compression
第三代存储引擎融合了 Gorilla 的 XOR float encoding 方案,将压缩能力提升到 1-2 bytes/sample。具体方案可以概括为:按顺序采用以下第一条适用的策略
Zero encoding:如果完全可预测,则无需额外空间 Integer double-delta encoding:如果是整型,可以利用 double-delta 原理,将不等的前后间隔分成 6/13/20/33 bits 几种,来优化空间使用 XOR float encoding:参考 Gorilla Direct encoding:直接存 float64
平均下来能取得 1.28 bytes/sample 的压缩能力。
原文链接:https://zhuanlan.zhihu.com/p/155719693
K8S 进阶训练营

 点击屏末 | 阅读原文 | 即刻学习
点击屏末 | 阅读原文 | 即刻学习

扫描二维码获取
更多云原生知识
k8s 技术圈