
Github Star 7.6K!高精度开源集成数据标注、合成功能的OCR模块,强烈推荐!

来源:机器之心
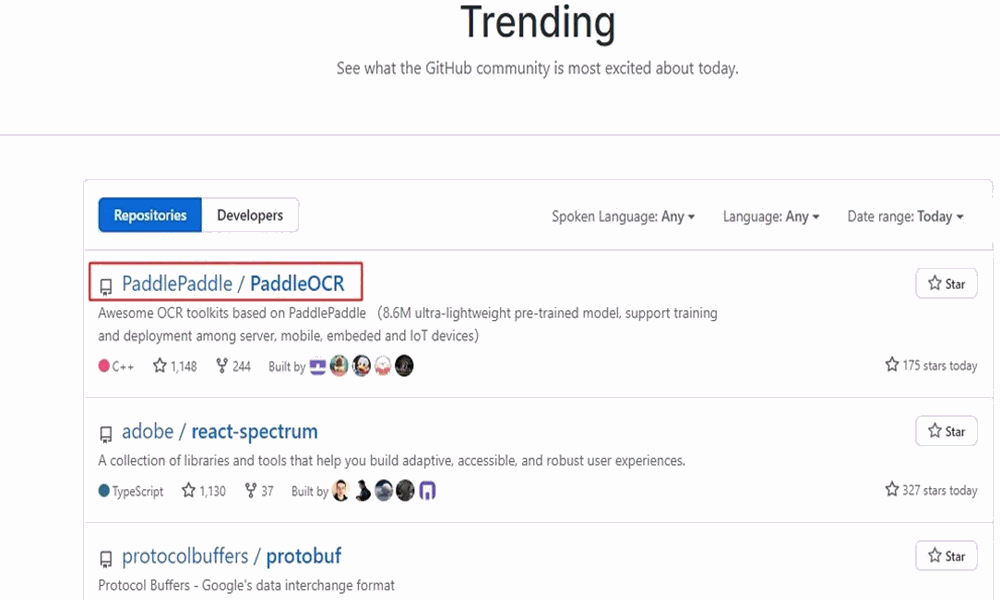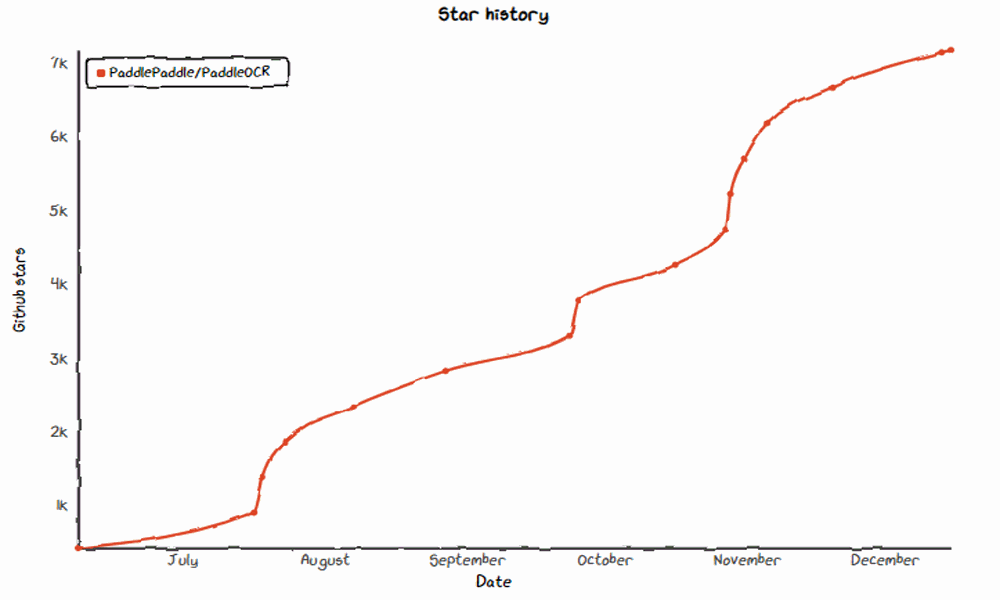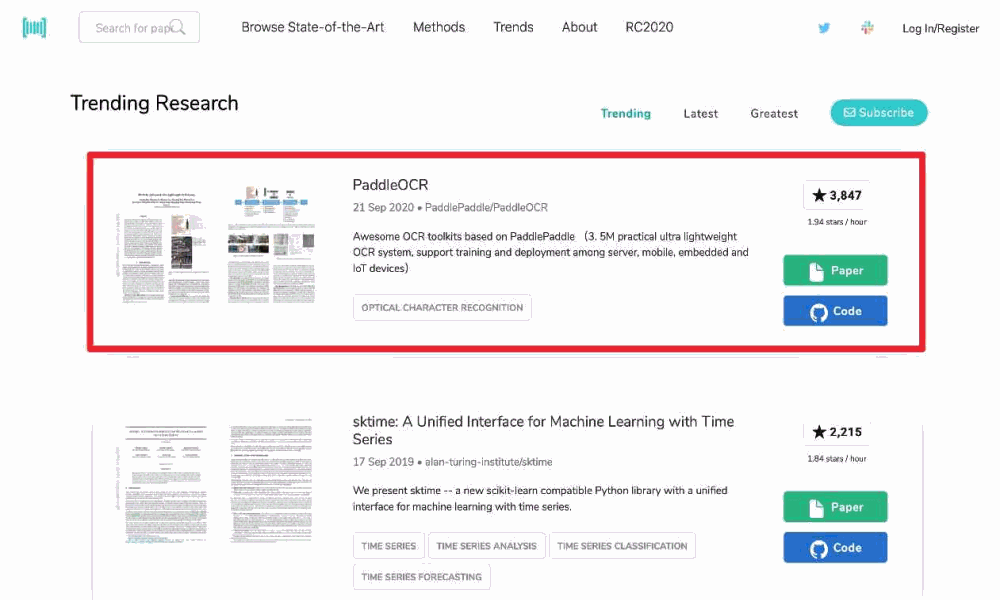
OCR 方向的工程师,一定需要知道这个 OCR 开源项目:PaddleOCR。短短几个月,累计 Star 数量已超过 7.2K,频频登上 Github Trending 日榜月榜,称它为 OCR 方向目前最火的 repo 绝对不为过。
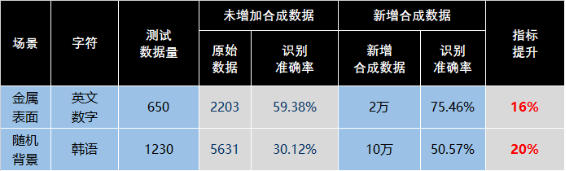
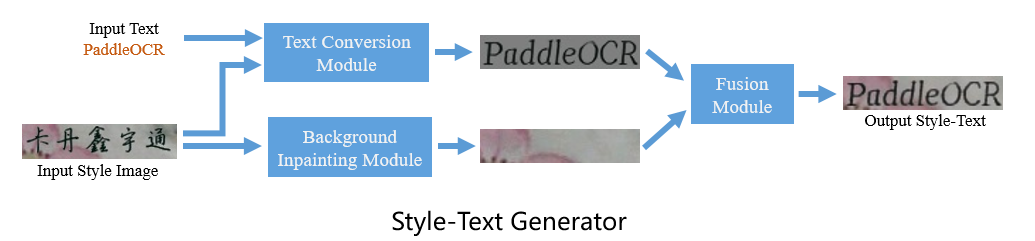
全新发布数据合成工具 Style-Text:可以批量合成大量与目标场景类似的图像,在多个场景验证,效果均提升 15% 以上。
全新发布半自动数据标注工具 PPOCRLabel:有了它数据标注工作事半功倍,相比 labelimg 标注效率提升 60% 以上,社区小规模测试,好评如潮。
多语言识别模型效果升级:中文、英文、韩语、法语、德语、日文识别效果均优于 EasyOCR。
PP-OCR 开发体验再升级:支持动态图开发(训练调试更方便),静态图部署(预测效率更高),鱼与熊掌可以兼得。
6 月,8.6M 超轻量模型发布,GitHub Trending 全球趋势榜日榜第一。
8 月,开源 CVPR2020 顶会 SOTA 算法,再上 GitHub 趋势榜单!
10 月,发布 PP-OCR 算法,开源 3.5M 超超轻量模型,再下 Paperswithcode 趋势榜第一




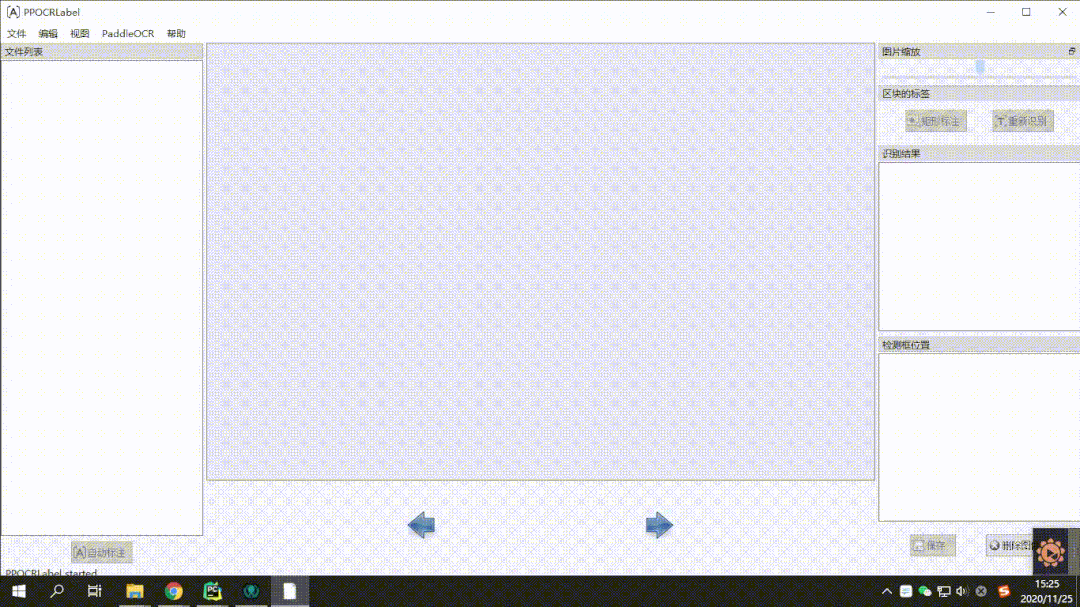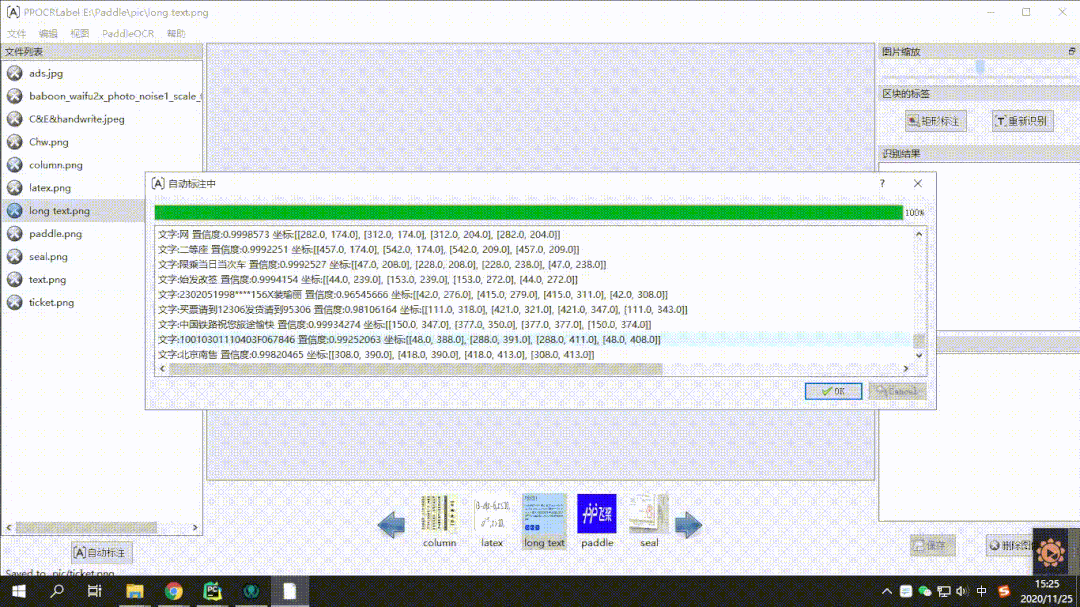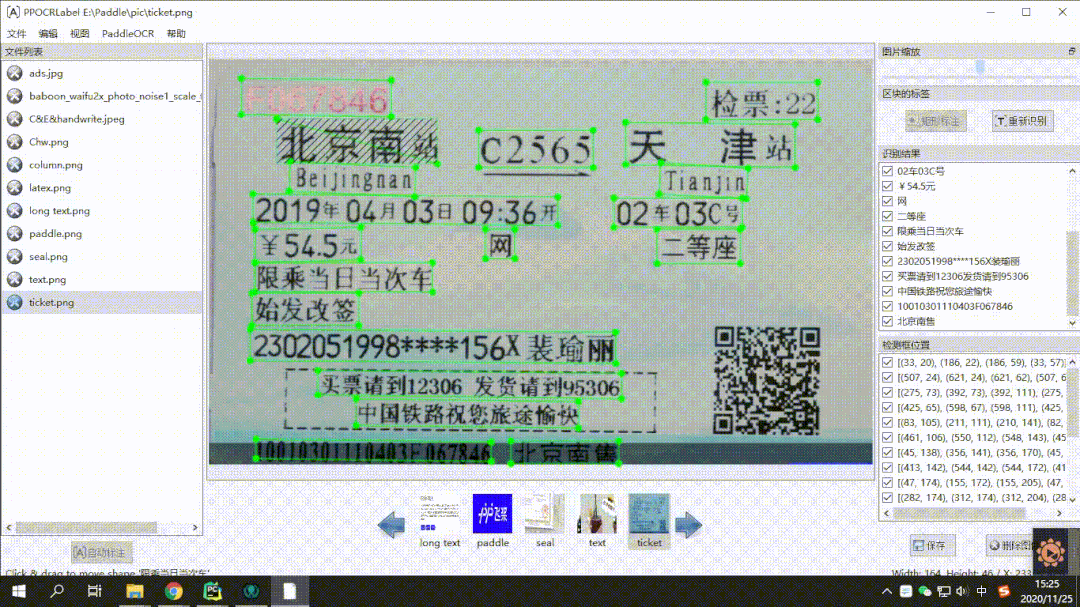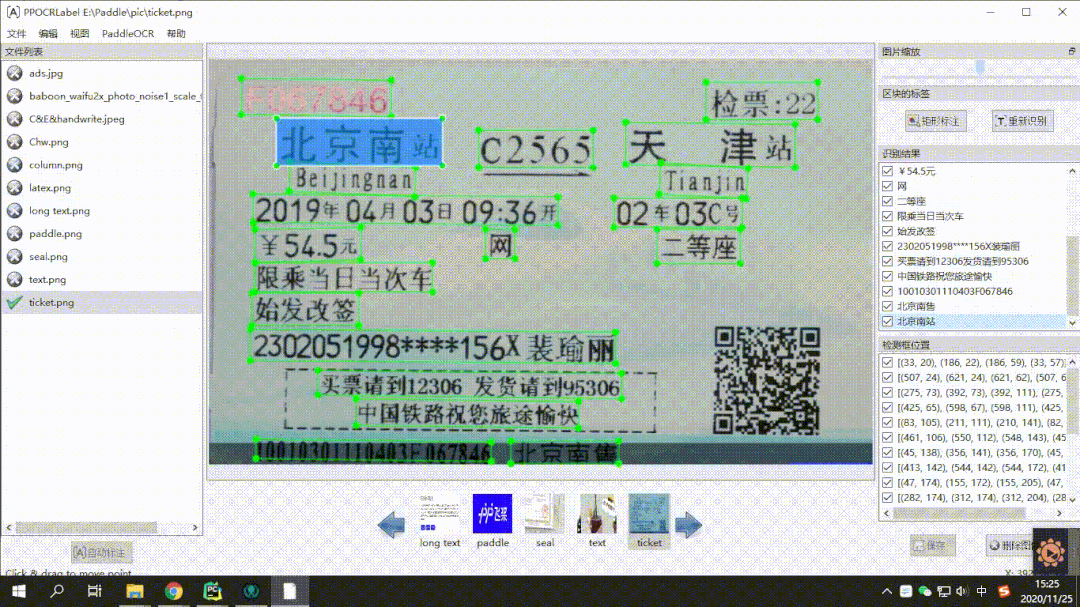
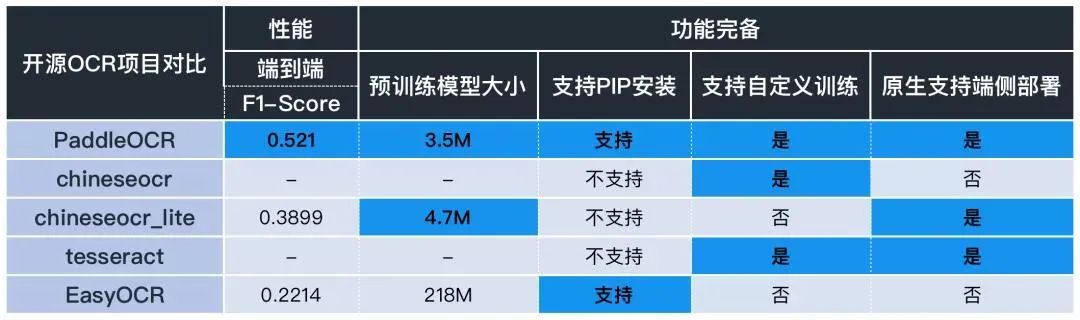

中英文场景:针对 OCR 实际应用场景,包括合同,车牌,铭牌,火车票,化验单,表格,证书,街景文字,名片,数码显示屏等,收集的 300 张图像,每张图平均有 17 个文本框,PaddleOCR 的 F1-Score 超过 0.5,这个性能已经很不错了。
多语言场景:PaddleOCR 选择了开源数据 ICDAR2017 – MLT(多语言文本识别测试集),并抽取其中的法语、德语、日语、韩语数据作为评测集合。其中测试图片大多来自于自然场景,例如广告牌、路标、海报等。



?????

送书福利

推荐理由:本书结合Python在数据分析领域的特点,介绍如何在数据平台上集成使用Python。内容分为3大部分。第1部分(第1~3章)为搭建开发环境和导入测试数据;第2部分(第4~12章)为Python对HDFS、Hive、Pig、HBase、Spark的操作,主要是对常用API的说明;第3部分(第13~16章)是在前面章节的基础上,介绍如何进行数据的分析、挖掘、可视化等内容。
活动奖品:
《python大数据分析从入门到精通》*4
活动规则:
活动截止时将从精选留言中点赞数最多的前4位送出以上四本书籍,先到先得(每人当月仅限一次中奖机会)。
另外我们每天还会在文末的留言中随机抽取 3位 小伙伴赠送 6.6元的现金红包,感谢大家一直以来的支持。
6.6元的现金红包,感谢大家一直以来的支持。
截止时间: 2020 年 12 月 21 日 16:00 整


以上三位小伙伴,加小编微信:yumeko370 领取小小红包一份哦!



以上四位小伙伴,加小编微信:yumeko370 提供收货地址,以及想要的书籍,先到先选。

以上四位小伙伴,加小编微信:yumeko370 提供收货地址。
