
分享一次实用的爬虫经验
共 2068字,需浏览 5分钟
·
2021-11-28 12:57
回复“书籍”即可获赠Python从入门到进阶共10本电子书
大家好,我是Python进阶者。
前言
前几天铂金群有个叫【艾米】的粉丝在问了一道关于Python网络爬虫的问题,如下图所示。
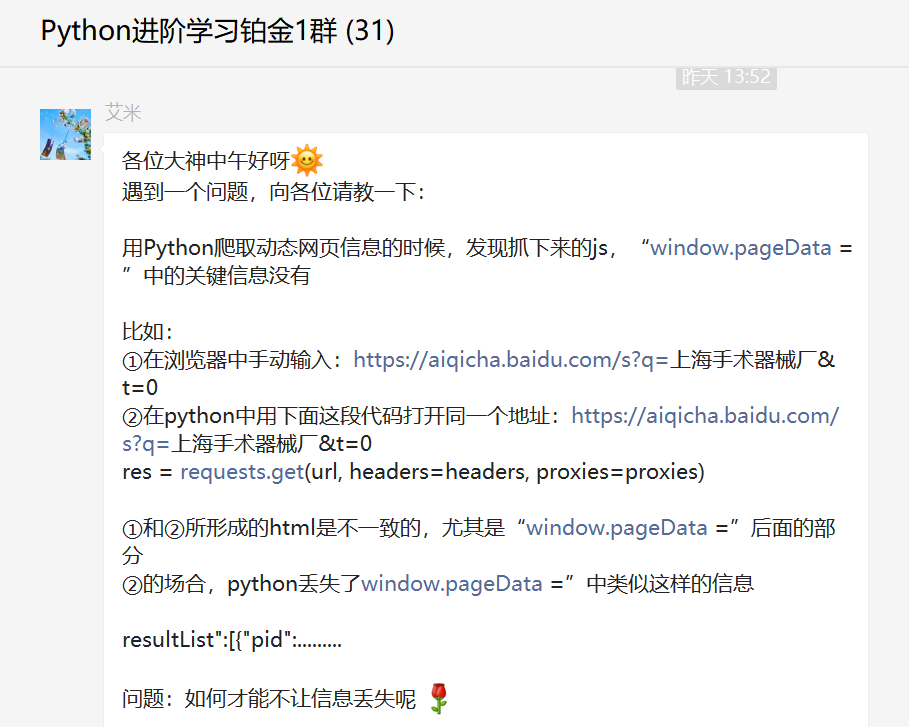
不得不说这个粉丝的提问很详细,也十分的用心,给他点赞,如果大家日后提问都可以这样的话,想必可以节约很多沟通时间成本。
其实他抓取的网站是爱企查,类似企查查那种。
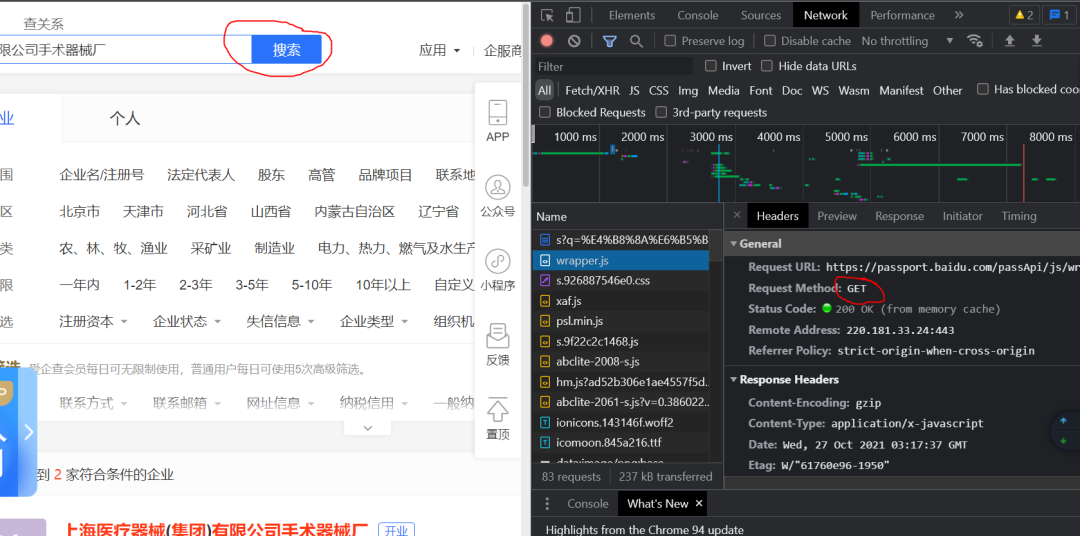
一、思路
一开始我以为很简单,我照着他给的网站,然后一顿抓包操作,到头来竟然没有找到响应数据,不论是在ALL还是XHR里边都没有找到任何符合要求的数据,真是纳闷。讲到这里,【杯酒】大佬一开始也放大招,吓得我不敢说话。
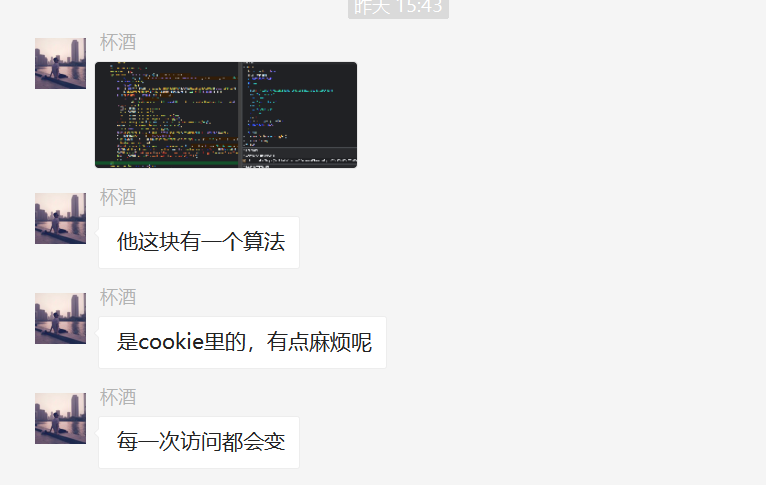
其实是想复杂了,一会儿你就知道了。
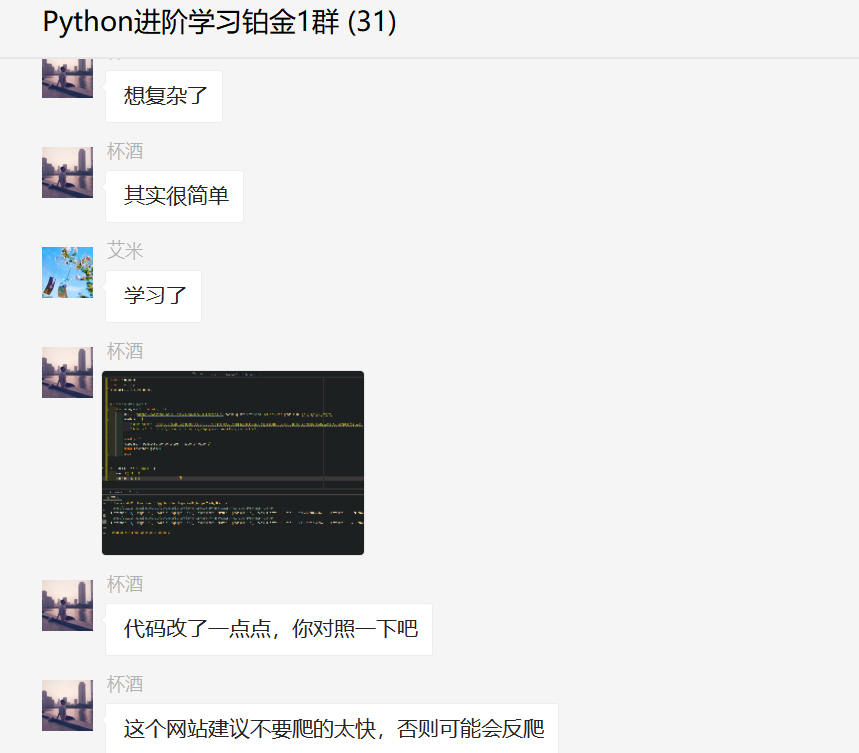
怀着一颗学习的心,我看了杯酒的代码,发现他构造的URL中有下图这个:
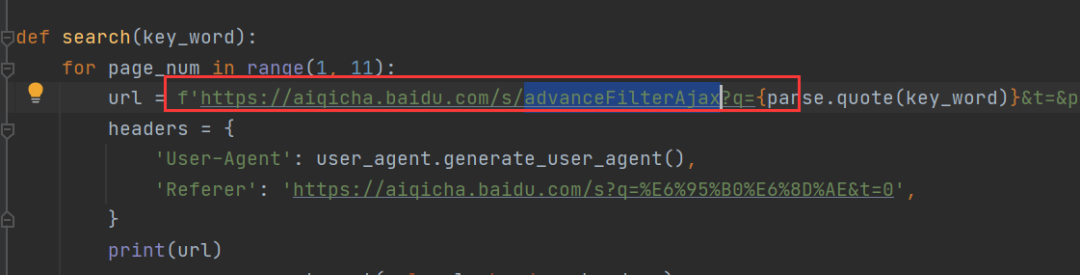
然后我再去网页中去找这个URL,可是这个URL在原网页中根本就找不到???这就离谱了,总不能空穴来风吧,事出必有因!
二、分析
原来这里有个小技巧,有图有真相。
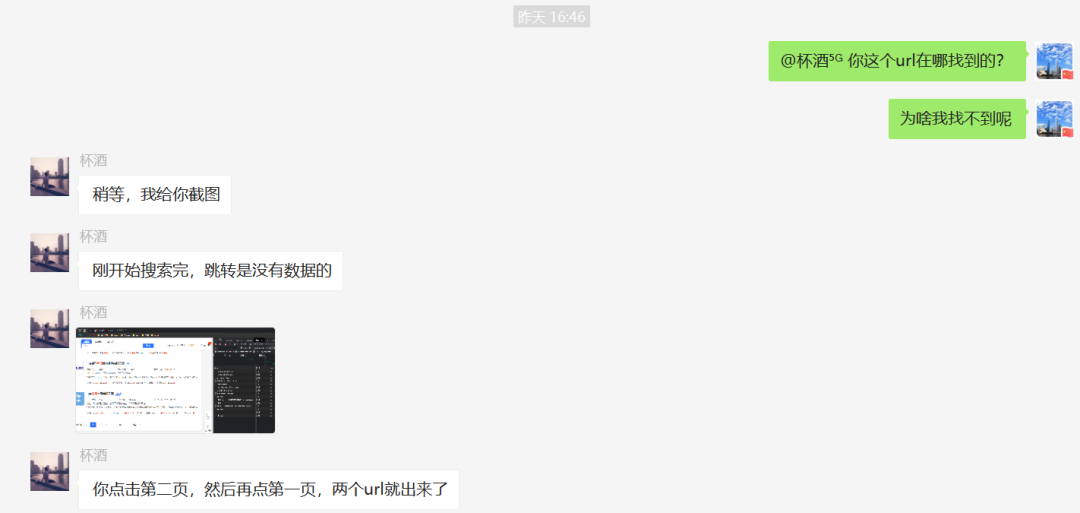
之后根据抓包情况,就可以看到数据了。
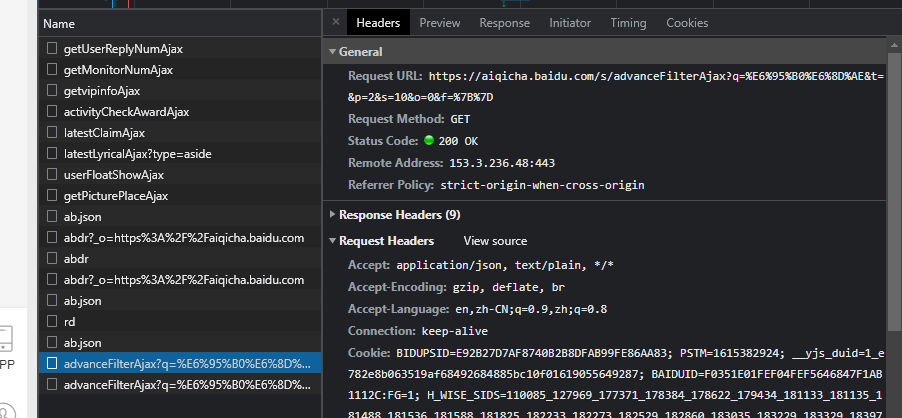
在里边可以看到数据:
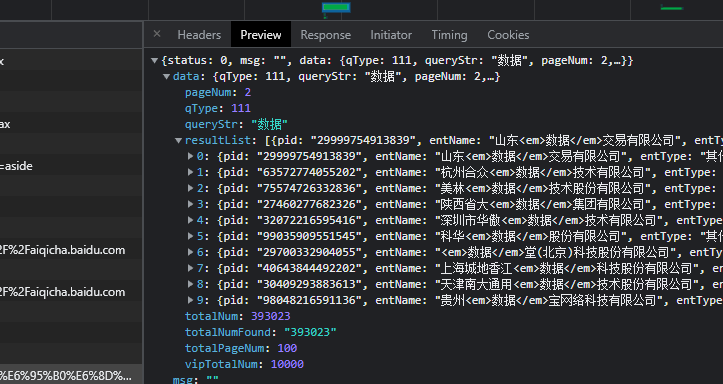
这里【杯酒】大佬查询的关键词是:数据,所以得到了好几页数据,而我和【艾米】都是直接查的:上海手术器械厂,这个只有一页,不太好观察规律,所以一直卡住了。
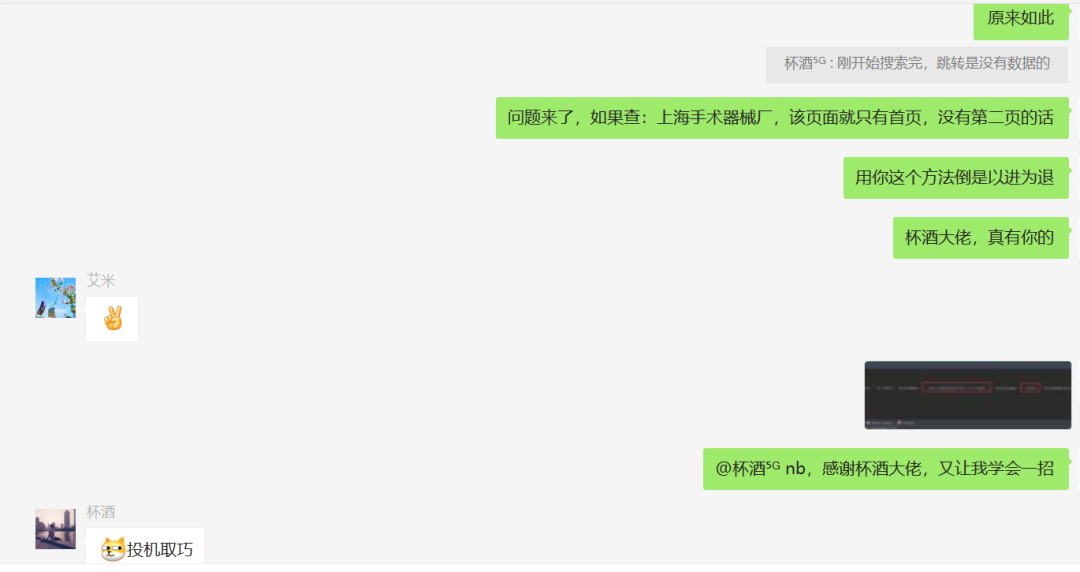
之后将得到的代码中的URL的关键词,改为:上海手术器械厂,就可以顺利的得到数据,是不是很神奇呢?
三、代码
下面就奉上本次爬虫的代码,欢迎大家积极尝试。
# -*- coding: utf-8 -*-import requestsimport user_agentfrom urllib import parsedef search(key_word):for page_num in range(1, 2):url = f'https://aiqicha.baidu.com/s/advanceFilterAjax?q={parse.quote(key_word)}&t=&p={str(page_num)}&s=10&o=0&f=%7B%7D'headers = {'User-Agent': user_agent.generate_user_agent(),'Referer': 'https://aiqicha.baidu.com/s?q=%E6%95%B0%E6%8D%AE&t=0',}print(url)response = requests.get(url=url, headers=headers)print(requests)print(response.json())# breakif __name__ == '__main__':search('上海手术器械厂')
只需要将关键词换成你自己想要搜索的就可以了。
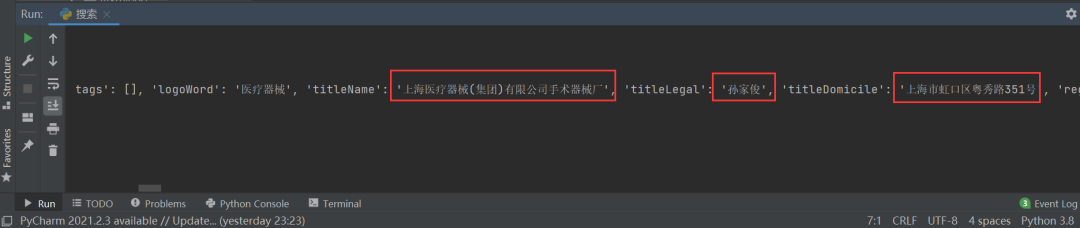
下图是运行的结果:

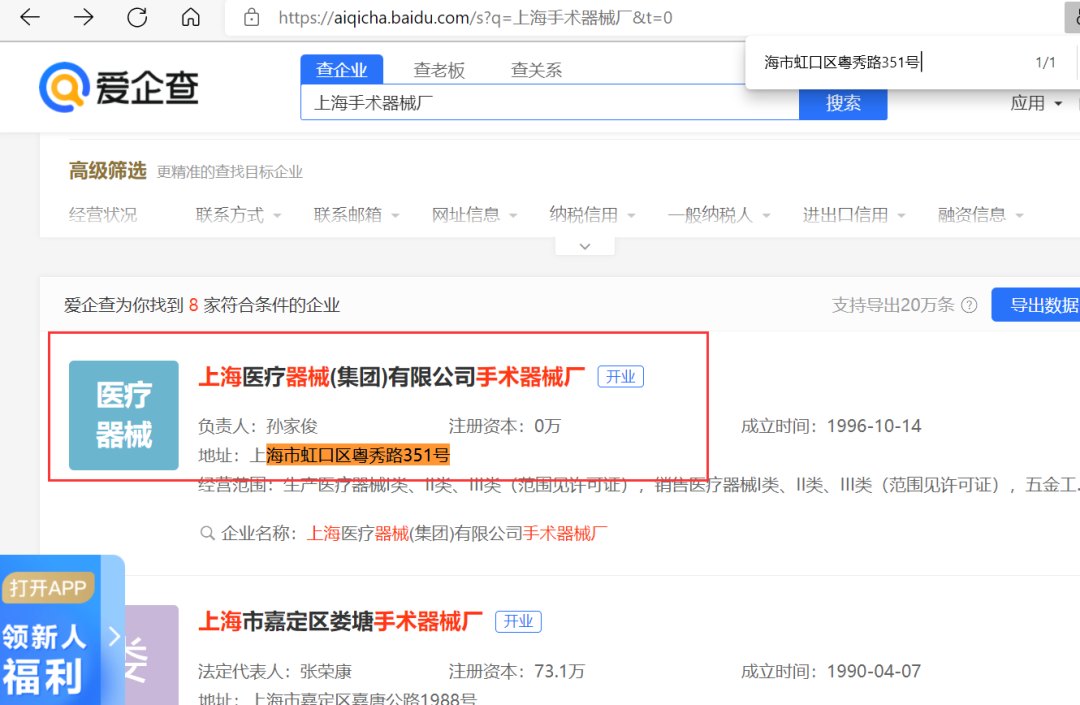
下图是原网页的截图,可以看到数据可以对的上:
四、总结
我是Python进阶者。本文基于粉丝提问,针对一次有趣的爬虫经历,分享一个实用的爬虫经验给大家。下次再遇到类似这种首页无法抓取的网页,或者看不到包的网页,不妨试试看文中的“以退为进,投机取巧”方法,说不定有妙用噢!
最后感谢【艾米】提问,感谢【杯酒】大佬解惑,感谢小编精心整理,也感谢【磐奚鸟】积极尝试。
针对本文中的网页,除了文章这种“投机取巧”方法外,用selenium抓取也是可行的,速度慢一些,但是可以满足要求。小编相信肯定还有其他的方法的,也欢迎大家在评论区谏言。

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~