
理解Javascript执行过程

比如javascript/python等都是解释型语言(但是javascript是先编译完成后,再进行解释的)。
2. 它是一种非常低的语言,它只针对特定的体系结构和处理器进行优化。
3. 开发效率低。容易出现bug,不好调试。
为什么会有那么多引擎,那是因为他们每个都被设计到不同的web浏览器或者像Node.js那样的运行环境当中。
Mozilla浏览器 -----> 解析引擎为 Spidermonkey(由c语言实现的)
Chrome浏览器 ------> 解析引擎为 V8(它是由c++实现的)
Safari浏览器 ------> 解析引擎为 JavaScriptCore(c/c++)
IE and Edge ------> 解析引擎为 Chakra(c++)
Node.js ------> 解析引擎为 V8
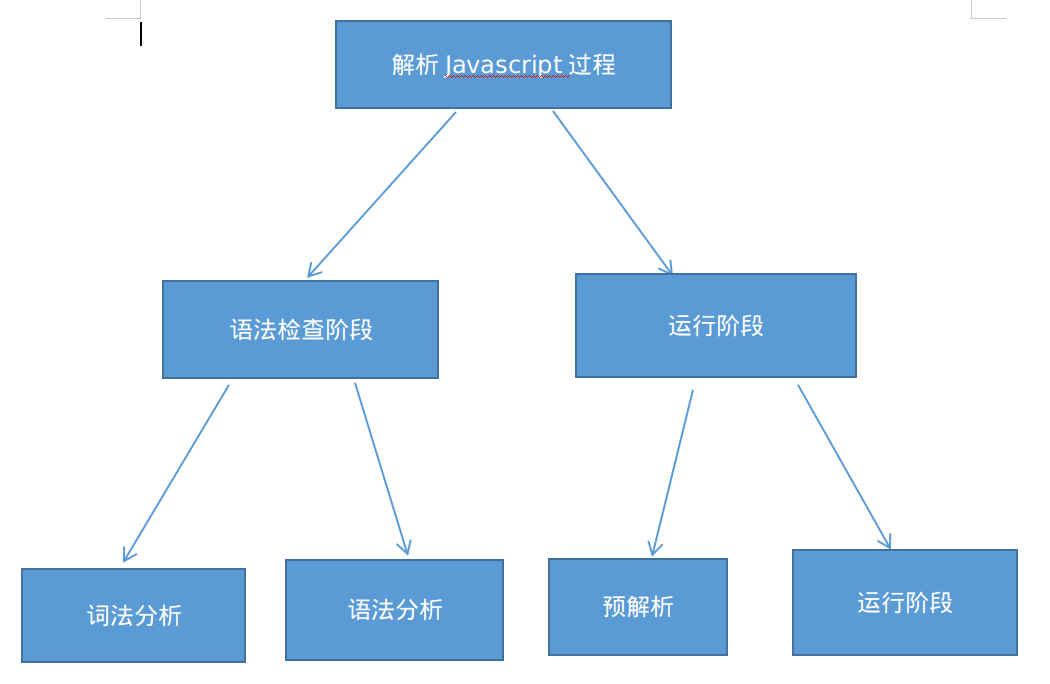
运行阶段分为:预解析 和 运行阶段。
比如上面词义分析后结果变成如下:
[{"type": "Keyword","value": "var"},{"type": "Identifier","value": "a"},{"type": "Punctuator","value": "="},{"type": "Numeric","value": "1"}]

代码我们可以简单的分析下如下:
首先代码调用如下:
var str = 'var a = 1';console.log(tokenizer(str));
然后会判断该字符串是否为关键字,如关键字: var KEYWORD = /function|var|return|let|const|if|for/;这些其中的一个,如果是的话,直接标记为关键字,存入tokens数组中,如下代码:
tokens.push({type: 'Keyword',value: value});
tokens = [{ type: 'Keyword', value: 'var' }];
// 标记变量tokens.push({type: 'Identifier',value: value});
tokens = [{ type: 'Keyword', value: 'var' },{ type: 'Identifier', value: 'a' },{ type: 'Punctuator', value: '=' }];
tokens = [{ type: 'Keyword', value: 'var' },{ type: 'Identifier', value: 'a' },{ type: 'Punctuator', value: '=' },{ type: 'Numeric', value: '1' }];
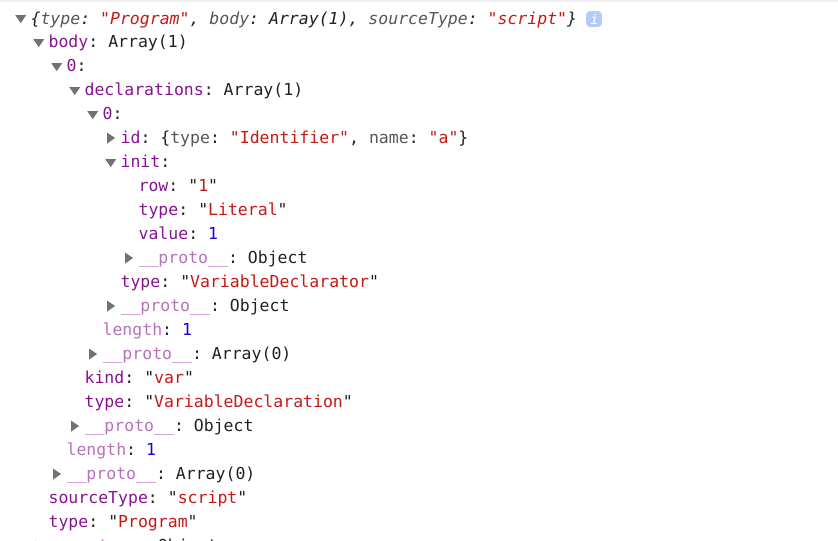
我们也可以使用这个在线的网址转换(https://esprima.org/demo/parse.html),结果变为如下所示:
{"type": "Program","body": [{"type": "VariableDeclaration","declarations": [{"type": "VariableDeclarator","id": {"type": "Identifier","name": "a"},"init": {"type": "Literal","value": 1,"raw": "1"}}],"kind": "var"}],"sourceType": "script"}
// 接收tokens作为参数, 生成抽象语法树ASTfunction parser(tokens) {// 记录当前解析到词的位置var current = 0;// 通过遍历来解析token节点function walk() {// 从token中第一项进行解析var token = tokens[current];// 检查是不是数字类型if (token.type === 'Numeric') {// 如果是数字类型的话,把current当前的指针移动到下一个位置current++;// 然后返回一个新的AST节点return {type: 'Literal',value: Number(token.value),row: token.value}}// 检查是不是变量类型if (token.type === 'Identifier') {// 如果是,把current当前的指针移动到下一个位置current++;// 然后返回我们一个新的AST节点return {type: 'Identifier',name: token.value}}// 检查是不是运输符类型if (token.type === 'Punctuator') {// 如果是,current自增current++;// 判断运算符类型,根据类型返回新的AST节点if (/[\+\-\*/]/im.test(token.value)) {return {type: 'BinaryExpression',operator: token.value}}if (/\=/.test(token.value)) {return {type: 'AssignmentExpression',operator: token.value}}}// 检查是不是关键字if (token.type === 'Keyword') {var value = token.value;// 检查是不是定义的语句if (value === 'var' || value === 'let' || value === 'const') {current++;// 获取定义的变量var variable = walk();// 判断是否是赋值符号var equal = walk();var rightVar;if (equal.operator === '=') {// 获取所赋予的值rightVar = walk();} else {// 不是赋值符号, 说明只是定义的变量rightVar = null;current--;}// 定义声明var declaration = {type: 'VariableDeclarator',id: variable, // 定义的变量init: rightVar};// 定义要返回的节点return {type: 'VariableDeclaration',declarations: [declaration],kind: value}}}// 遇到一个未知类型就抛出一个错误throw new TypeError(token.type);}// 现在,我们创建一个AST,根节点是一个类型为 'Program' 的节点var ast = {type: 'Program',body: [],sourceType: 'script'};// 循环执行walk函数,把节点放入到ast.body中while(current < tokens.length) {ast.body.push(walk());}// 最后返回我们的ASTreturn ast;}var tokens = [{ type: 'Keyword', value: 'var' },{ type: 'Identifier', value: 'a' },{ type: 'Punctuator', value: '=' },{ type: 'Numeric', value: '1' }];console.log(parser(tokens));
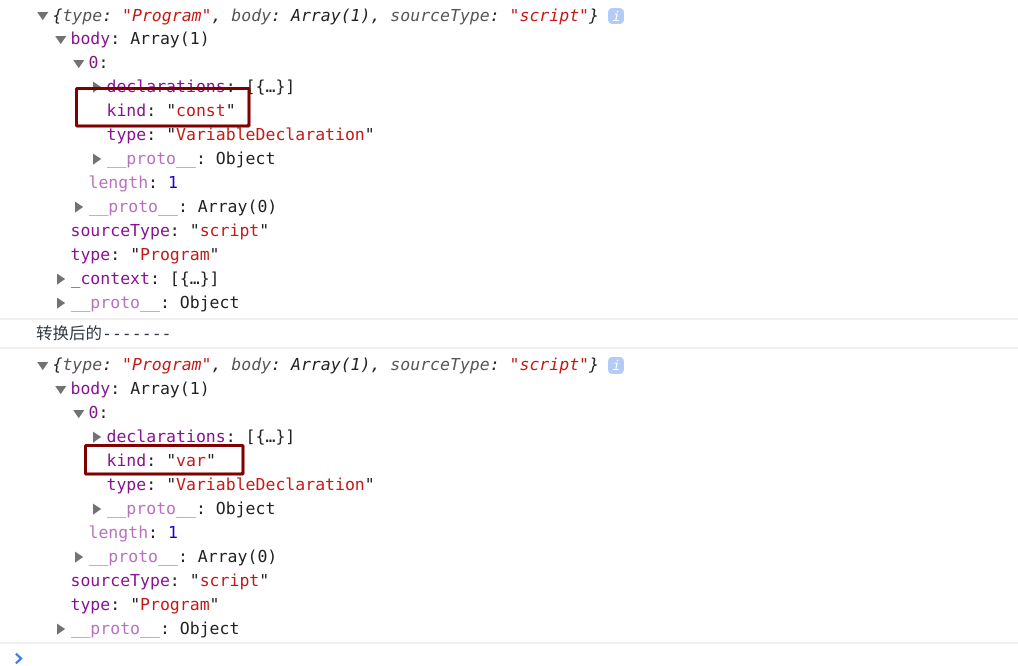
因此我们需要对AST树节点进行转换操作。
/*为了修改AST抽象树,我们首先要对节点进行遍历@param AST语法树@param visitor定义转换函数,也可以使用visitor函数进行转换*/function traverser(ast, visitor) {// 遍历树中的每个节点function traverseArray(array, parent) {if (typeof array.forEach === 'function') {array.forEach(function(child) {traverseNode(child, parent);});}}function traverseNode(node, parent) {// 看下 vistory中有没有对应的type处理函数var method = visitor[node.type];if (method) {method(node, parent);}switch(node.type) {// 从顶层的Program开始case 'Program':traverseArray(node.body, node);break;// 如下的是不需要转换的case 'VariableDeclaration':case 'VariableDeclarator':case 'AssignmentExpression':case 'Identifier':case 'Literal':break;default:throw new TypeError(node.type)}}traverseNode(ast, null)}/*下面是转换器,它用于遍历过程中转换数据,我们接收之前的AST树作为参数,最后会生成一个新的AST抽象树*/function transformer(ast) {// 创建新的ast抽象树var newAst = {type: 'Program',body: [],sourceType: 'script'};ast._context = newAst.body;// 我们把AST 和 vistor 作为参数传入进去traverser(ast, {VariableDeclaration: function(node, parent) {var variableDeclaration = {type: 'VariableDeclaration',declarations: node.declarations,kind: 'var'};// 把新的 VariableDeclaration 放入到context中parent._context.push(variableDeclaration);}});// 最后返回创建号的新ASTreturn newAst;}var ast = {"type": "Program","body": [{"type": "VariableDeclaration","declarations": [{"type": "VariableDeclarator","id": {"type": "Identifier","name": "a"},"init": {"type": "Literal","value": 1,"raw": "1"}}],"kind": "const"}],"sourceType": "script"}console.log(ast);console.log('转换后的-------');console.log(transformer(ast));
var newAst = {"type": "Program","body": [{"type": "VariableDeclaration","declarations": [{"type": "VariableDeclarator","id": {"type": "Identifier","name": "a"},"init": {"type": "Literal","value": 1,"raw": "1"}}],"kind": "var"}],"sourceType": "script"}function codeGenerator(node) {console.log(node.type);// 对于不同类型的节点分开处理\switch (node.type) {// 如果是Program节点,我们会遍历它的body属性中的每一个节点case 'Program':return node.body.map(codeGenerator).join('\n');// VariableDeclaration节点case 'VariableDeclaration':return node.kind + ' ' + node.declarations.map(codeGenerator);// VariableDeclarator 节点case "VariableDeclarator":return codeGenerator(node.id) + ' = ' + codeGenerator(node.init);// 处理变量case 'Identifier':return node.name;//case 'Literal':return node.value;default:throw new TypeError(node.type);}}console.log(codeGenerator(newAst));
var a = 1;function abc() {console.log(a);var a = 2;}abc();
var a = 1;function abc() {var a;console.log(a);a = 2;}abc();
2. 只有var 和 function 声明会被提升。
3. 在所在的作用域会被提升,不会扩展到其他的作用域。
4. 预编译后会顺序执行代码。