
教大家爬取喜马拉雅全站音频数据,探秘喜马拉雅的天籁之音
共 4541字,需浏览 10分钟
·
2021-10-18 22:46

一、前言
喜马拉雅FM是一个知名的音频分享平台,在移动音频行业的市场占有率已达73%,用户规模突破4.8亿,今天我们就带大家突破层层障碍,探秘喜马拉雅的天籁之音,实现实时抓捕并保存到本地。
个人觉得,听书也是对情感的一种认知和感受。看书的时候我们可以天马行空,有各种理解,但听的时候呢,听一些优质的声音和读物,可以试着从别人的声音里感知一些信息和情绪,就像我们在日常生活中一样,不仅要用眼睛看,还需要用耳朵去听呀。
二、寻找音频的URL
首先打开喜马拉雅的网址:https://www.ximalaya.com/
然后我们输入关键字 进行搜索,此处以荒村阴阳师为例,如下图:
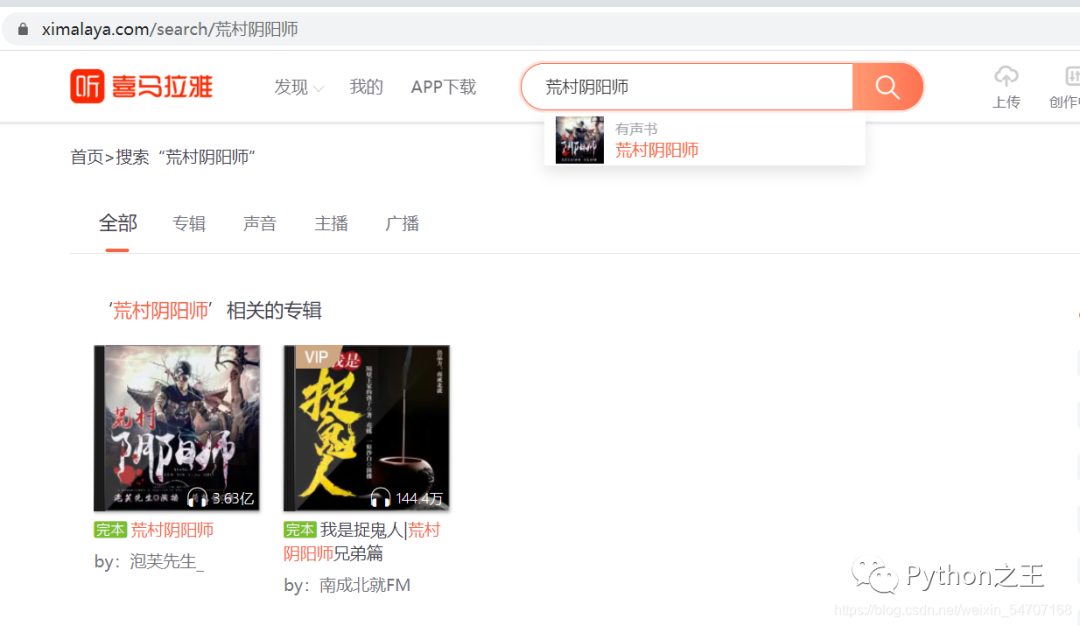
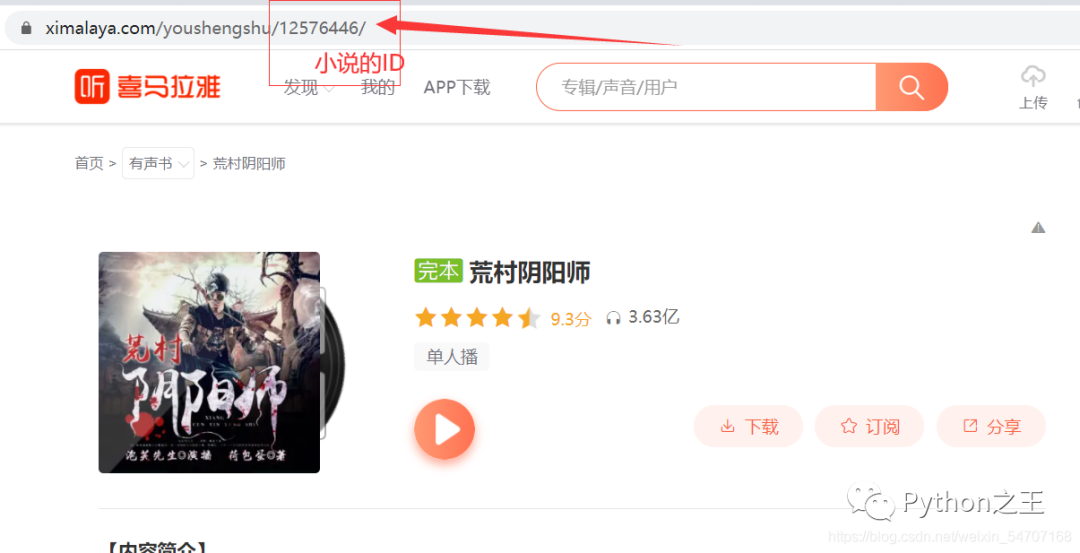 爬取的数据如下
爬取的数据如下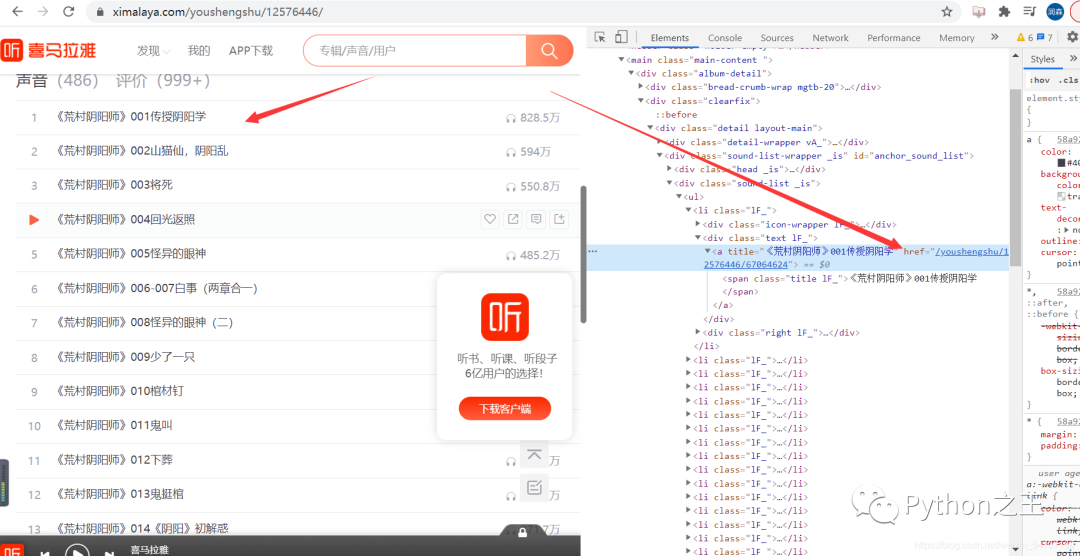
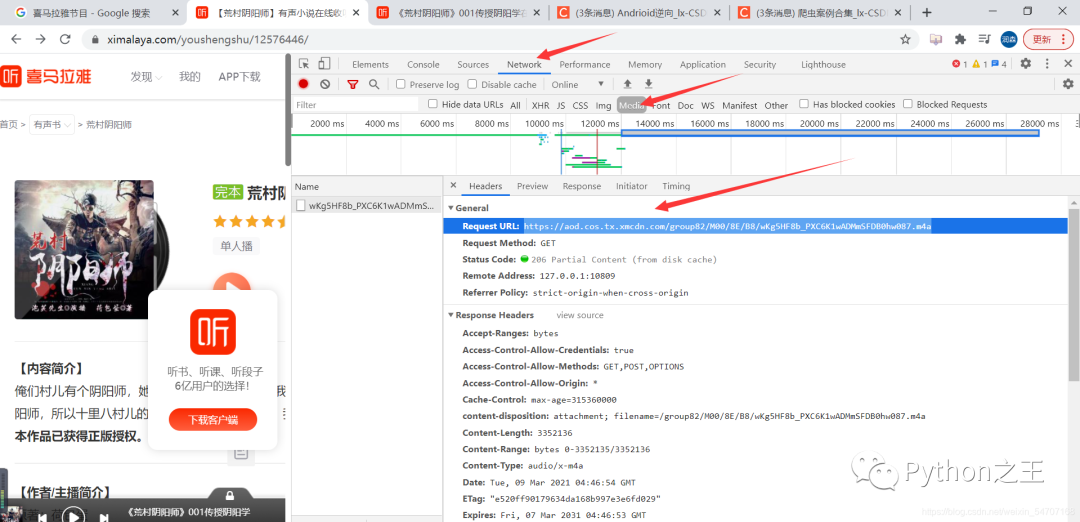
你就会发现了:https://aod.cos.tx.xmcdn.com/group82/M00/8E/B8/wKg5HF8b_PXC6K1wADMmSFDB0hw087.m4a 就是下载一个MP3的链接,点击下载
访问下:https://aod.cos.tx.xmcdn.com/
 j经过我的分析,这个应该Nigux代理请求,因此需要找到这个url的来源
j经过我的分析,这个应该Nigux代理请求,因此需要找到这个url的来源
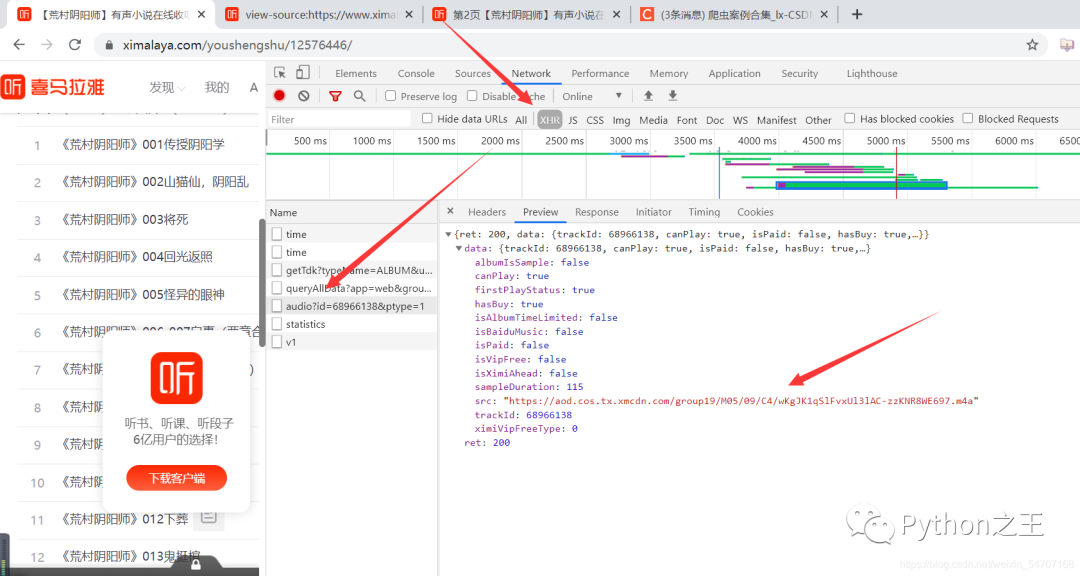
三、请求参数的处理
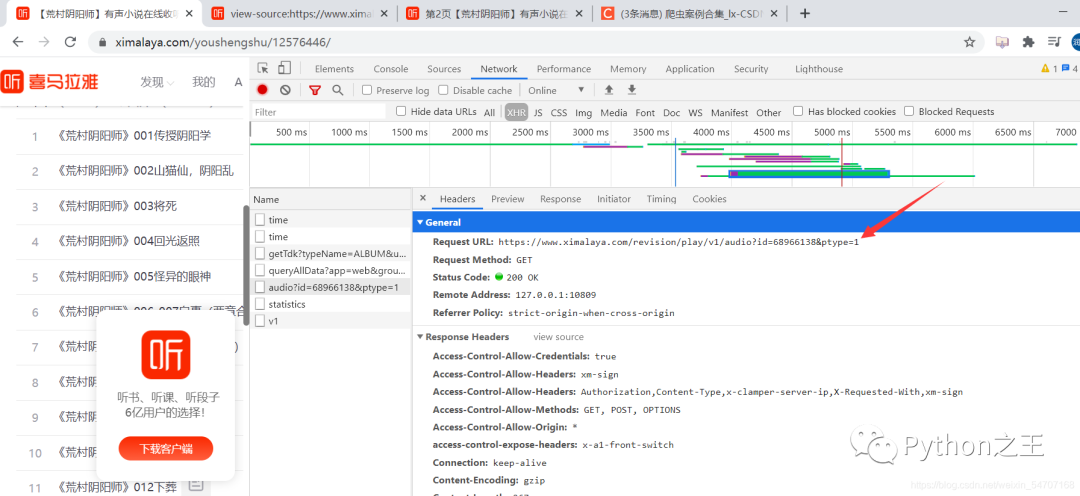
没错,就是这个:https://www.ximalaya.com/revision/play/v1/audio?id=68966138&ptype=1
在请求参数中,有一个xm-sign需要处理下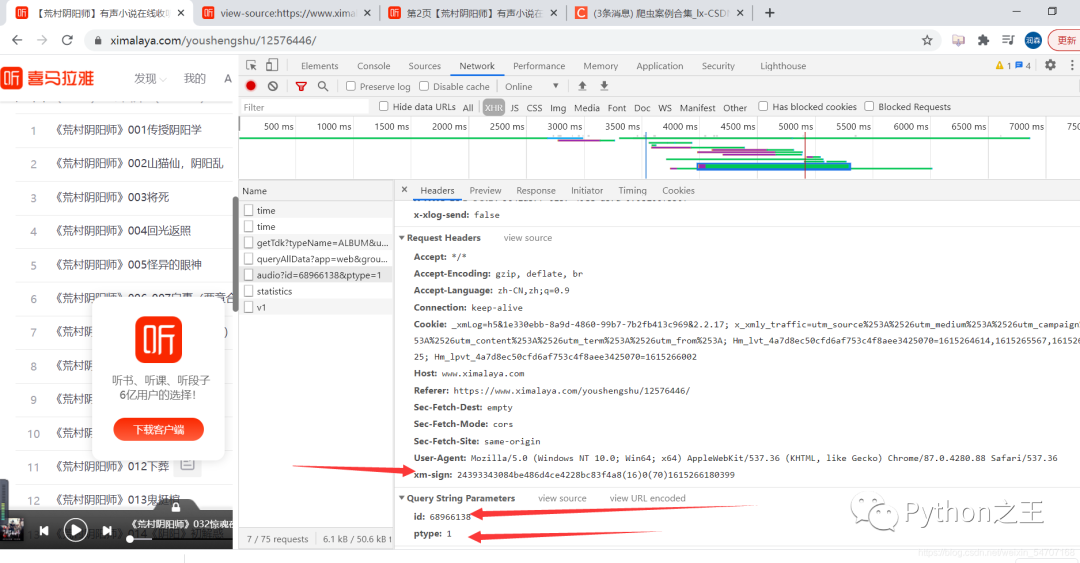
这个xm-sign是:md5(服务器时间戳)(100以内随机数)服务器时间戳(100以内随机数)现在时间戳。
这个我看出来的,为什么呢?因为我是大神,没有为什么???
获取服务器时间戳,这个我也发现了,是https://www.ximalaya.com/revision/time
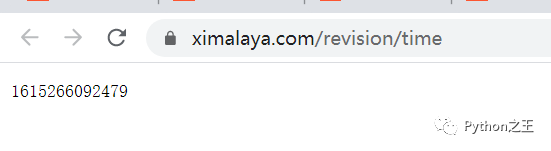 「我真的大神,你们可以叫我大师」
「我真的大神,你们可以叫我大师」
四、重新分析目标网站
重新分析目标网站:https://www.ximalaya.com/yinyue/12576446/
分析每一页网页url有什么不同:第一页的是https://www.ximalaya.com/revision/play/albumalbumId=12576446&pageNum=1&sort=1&pageSize=30第二页https://www.ximalaya.com/revision/play/albumalbumId=12576446&pageNum=2&sort=1&pageSize=30第三页https://www.ximalaya.com/revision/play/albumalbumId=12576446&pageNum=3&sort=1&pageSize=30
一共有十七页,可以使用Python当中的.format方法来占位(方法不唯一)
五、实现代码
代码如下
import hashlib
import json
import os
import re
import time
import random
import requests
'''有声书下载'''
class ximalaya(object):
def __init__(self):
self.base_url = 'https://www.ximalaya.com'
self.base_api = 'https://www.ximalaya.com/revision/play/album?albumId={}&pageNum={}&sort=0&pageSize=30'
self.time_api = 'https://www.ximalaya.com/revision/time'
self.header = {'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:63.0) Gecko/20100101 Firefox/63.0'}
self.s = requests.session()
def get_time(self):
"""
获取服务器时间戳
:return:
"""
r = self.s.get(self.time_api, headers=self.header)
return r.text
def get_sign(self):
"""
获取sign:md5(服务器时间戳)(100以内随机数)服务器时间戳(100以内随机数)现在时间戳
:return: xm_sign
"""
nowtime = str(round(time.time() * 1000))
servertime = self.get_time()
sign = str(hashlib.md5("himalaya-{}".format(servertime).encode()).hexdigest()) + "({})".format(
str(round(random.random() * 100))) + servertime + "({})".format(str(round(random.random() * 100))) + nowtime
self.header["xm-sign"] = sign
def index_choose(self):
xm_id = input(u'请输入要获取喜马拉雅节目的ID:')
xima.get_fm(xm_id)
self.index_choose()
@staticmethod
def make_dir(xm_fm_id):
# 保存路径,请自行修改,这里是以有声书ID作为文件夹的路径
fm_path = './{}'.format(xm_fm_id)
f = os.path.exists(fm_path)
if not f:
os.makedirs(fm_path)
print('make file success')
else:
print('file already exists')
return fm_path
def get_fm(self, xm_fm_id,lable='youshengshu'):
# 根据有声书ID构造url
fm_url = self.base_url + '/{}/{}'.format(lable,xm_fm_id)
r_fm_url = self.s.get(fm_url, headers=self.header)
fm_title = re.findall('(.*?)' , r_fm_url.text, re.S)[0]
print('书名:' + fm_title)
# 新建有声书ID的文件夹
fm_path = self.make_dir(xm_fm_id)
# 取最大页数
s = re.findall(r'/{}/{}/p(\d+)/'.format(lable,xm_fm_id), r_fm_url.text, re.S)
max_page = sorted([int(i) for i in s])[-1]
if max_page:
for page in range(1, int(max_page) + 1):
print('第' + str(page) + '页')
self.get_sign()
r = self.s.get(self.base_api.format(xm_fm_id, page), headers=self.header)
r_json = json.loads(r.text)
for audio in r_json['data']['tracksAudioPlay']:
audio_title = str(audio['trackName']).replace(' ', '')
audio_src = audio['src']
self.get_detail(audio_title, audio_src, fm_path)
# 每爬取1页,30个音频,休眠3秒
time.sleep(3)
else:
print(os.error)
def get_detail(self, title, src, path):
r_audio_src = self.s.get(src, headers=self.header)
m4a_path = path+'/' + title + '.m4a'
if not os.path.exists(m4a_path):
with open(m4a_path, 'wb') as f:
f.write(r_audio_src.content)
print(title + '保存完毕...')
else:
print(title + 'm4a已存在')
if __name__ == '__main__':
xima = ximalaya()
xima.index_choose()
# 12576446
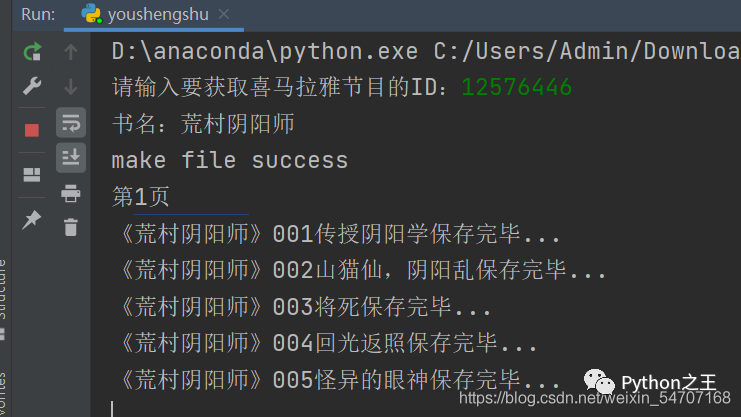
六、爬取结果
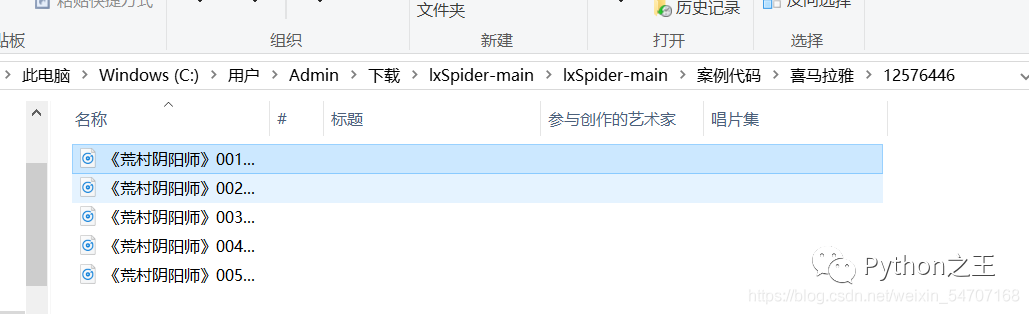
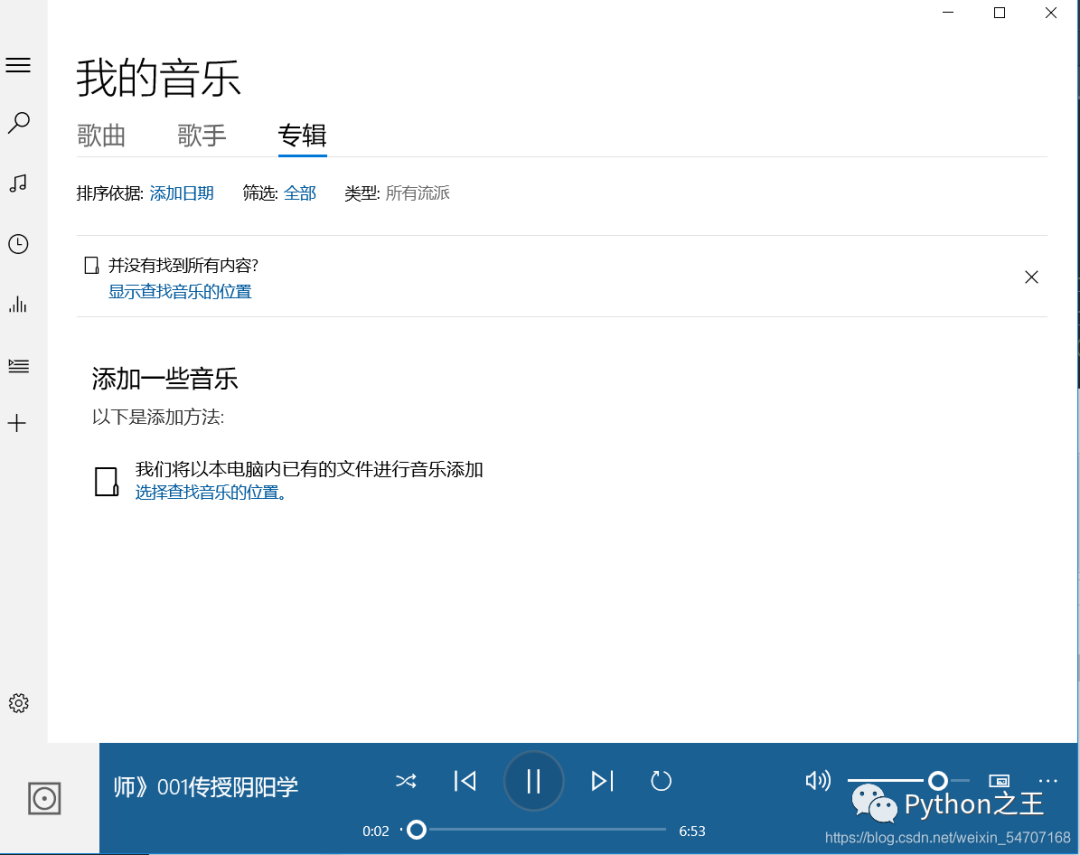 可能有人问这样的目的是什么?我可以在APP或者网页上的直接听啊!
可能有人问这样的目的是什么?我可以在APP或者网页上的直接听啊!
诶~对于某些需要的收费的节目,量又很大,你可能会员过期了就无法享受其中的内容,所以可以通过这种方式“下载”
当然最终要的还是为了让大家理解爬虫的一些思路