
25 个例子学会Pandas Groupby 操作!
import pandas as pdsales = pd.read_csv("sales_data.csv")sales.head()
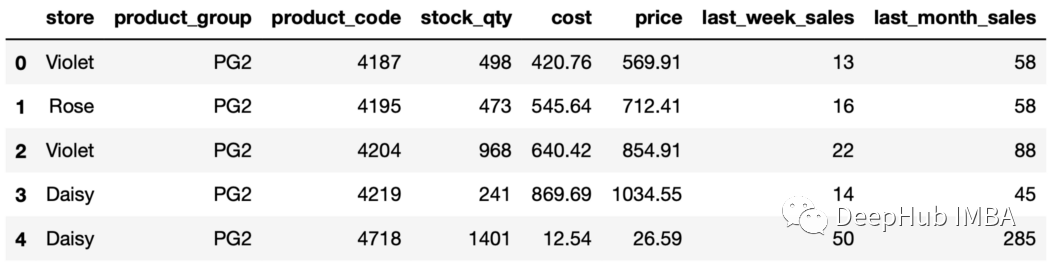
sales.groupby("store")["stock_qty"].mean()#输出storeDaisy 1811.861702Rose 1677.680000Violet 14622.406061Name: stock_qty, dtype: float64
sales.groupby("store")[["stock_qty","price"]].mean()
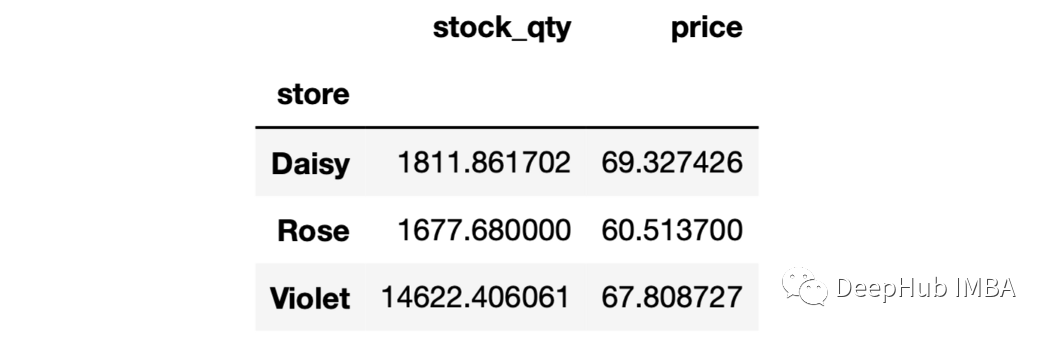
sales.groupby("store")["stock_qty"].agg(["mean", "max"])
sales.groupby("store").agg(avg_stock_qty = ("stock_qty", "mean"),max_stock_qty = ("stock_qty", "max"))
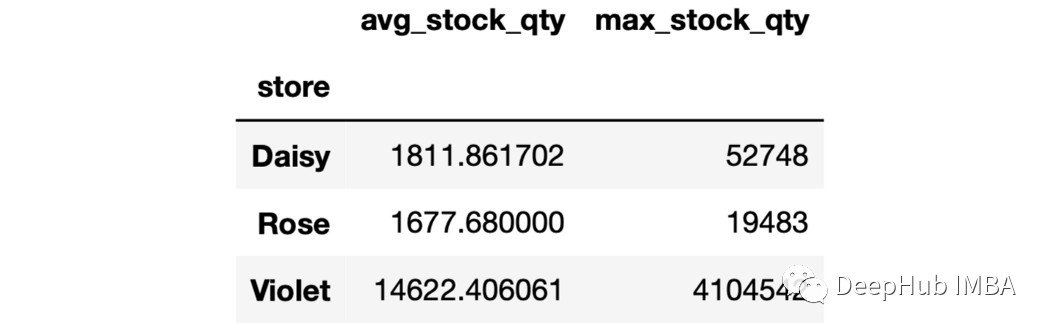
sales.groupby("store")[["stock_qty","price"]].agg(["mean", "max"])

sales.groupby("store").agg(avg_stock_qty = ("stock_qty", "mean"),avg_price = ("price", "mean"))
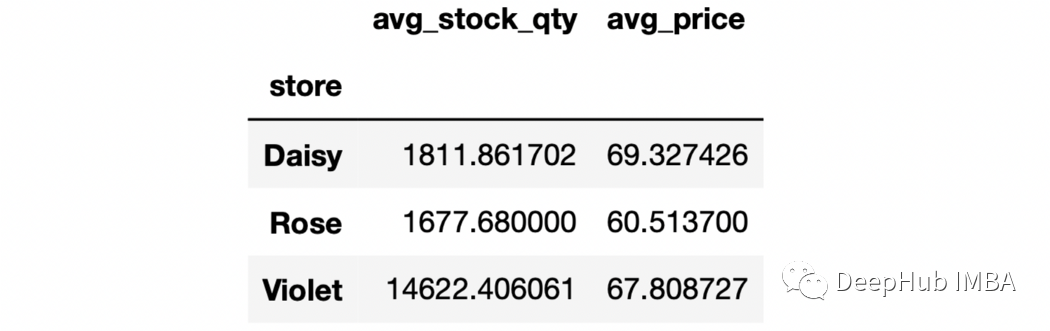
sales.groupby("store", as_index=False).agg(avg_stock_qty = ("stock_qty", "mean"),avg_price = ("price", "mean"))
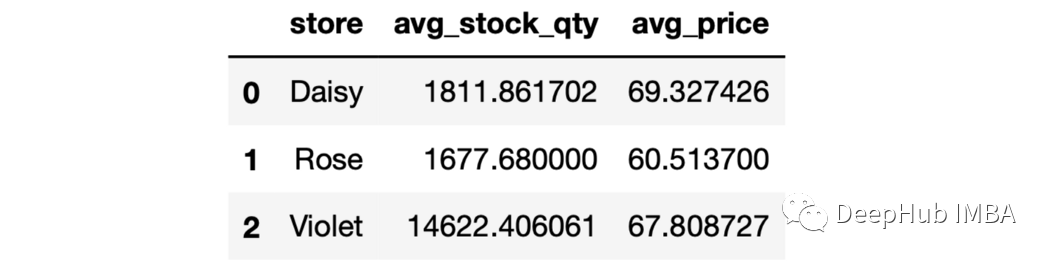
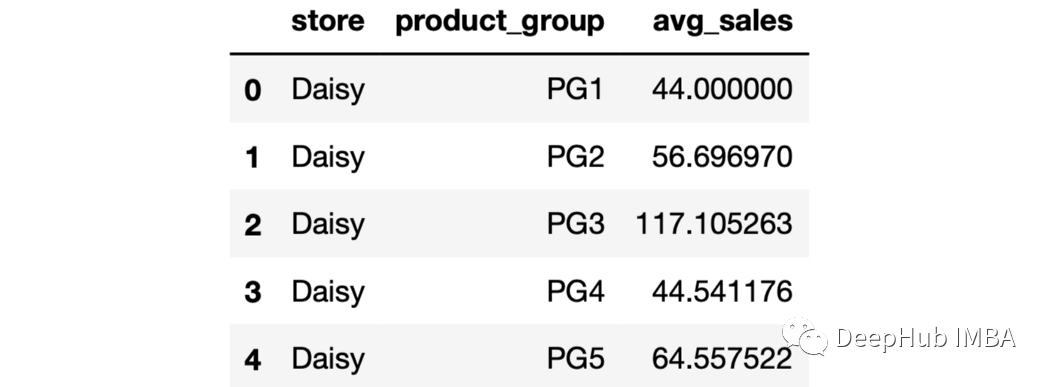
sales.groupby(["store","product_group"], as_index=False).agg(avg_sales = ("last_week_sales", "mean")).head()
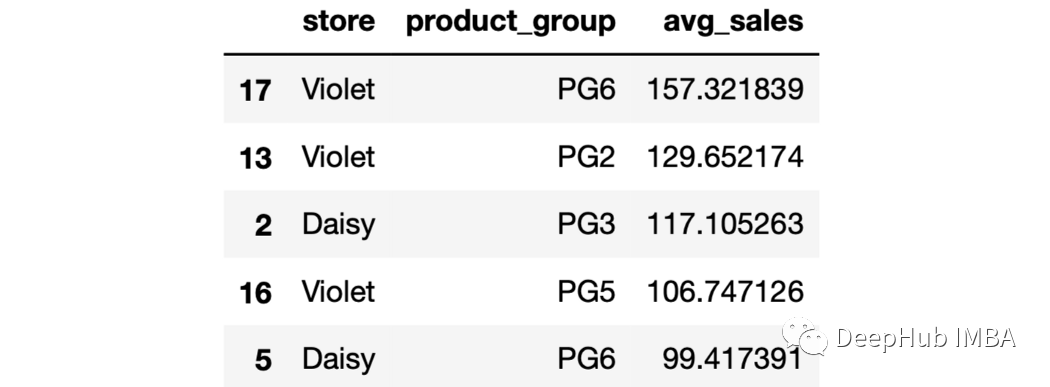
sales.groupby(["store","product_group"], as_index=False).agg( avg_sales = ("last_week_sales", "mean")).sort_values(by="avg_sales", ascending=False).head()
sales.groupby("store")["last_week_sales"].nlargest(2)storeDaisy 413 1883231 947Rose 948 883263 623Violet 991 3222339 2690Name: last_week_sales, dtype: int64
sales.groupby("store")["last_week_sales"].nsmallest(2)
sales_sorted = sales.sort_values(by=["store","last_month_sales"], ascending=False, ignore_index=True)
sales_sorted.groupby("store").nth(4)
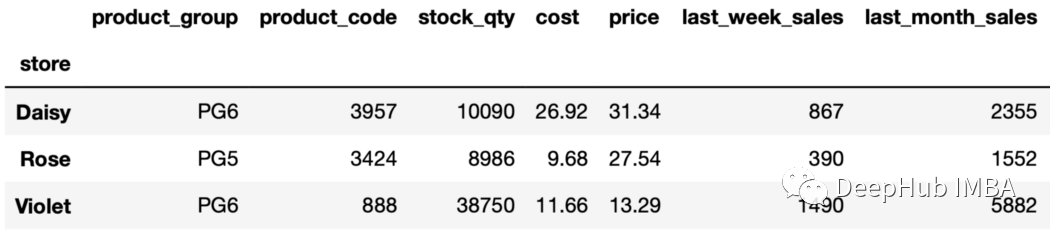
sales_sorted.groupby("store").nth(-2)
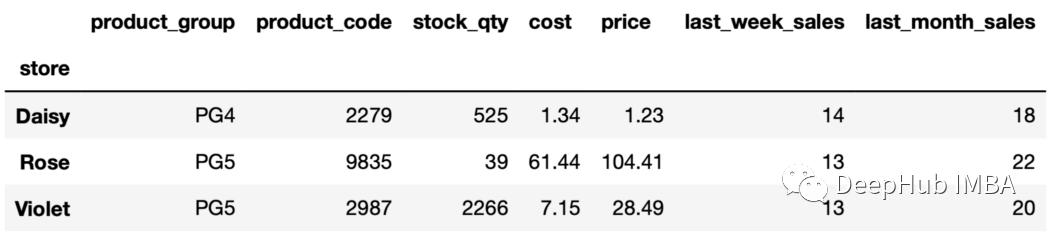
sales.groupby("store", as_index=False).agg(unique_values = ("product_code","unique"))

sales.groupby("store", as_index=False).agg(number_of_unique_values = ("product_code","nunique"))

sales.groupby("store").agg(total_sales_in_thousands = ("last_month_sales",lambda x: round(x.sum() / 1000, 1)))
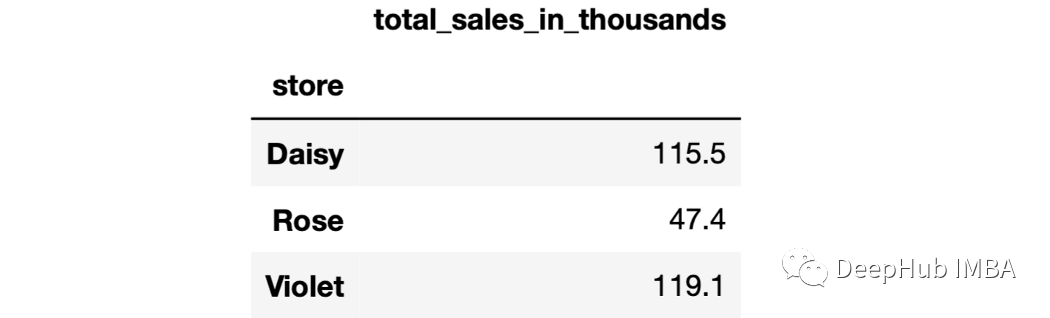
sales.groupby("store").apply(lambda x: (x.last_week_sales - x.last_month_sales / 4).mean())storeDaisy 5.094149Rose 5.326250Violet 8.965152dtype: float64
sales.loc[1000] = [None, "PG2", 10000, 120, 64, 96, 15, 53]
sales.groupby("store")["price"].mean()storeDaisy 69.327426Rose 60.513700Violet 67.808727Name: price, dtype: float64
dropna=False)["price"].mean()storeDaisy 69.327426Rose 60.513700Violet 67.808727NaN 96.000000Name: price, dtype: float64
sales.groupby(["store", "product_group"]).ngroups18
aisy_pg1 = sales.groupby([]).get_group(("Daisy","PG1"))daisy_pg1.head()
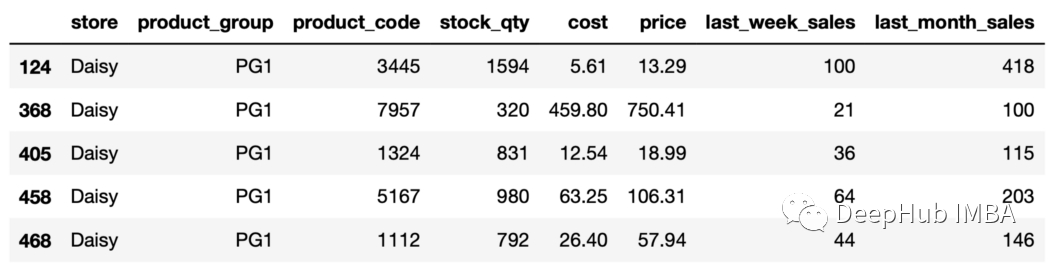
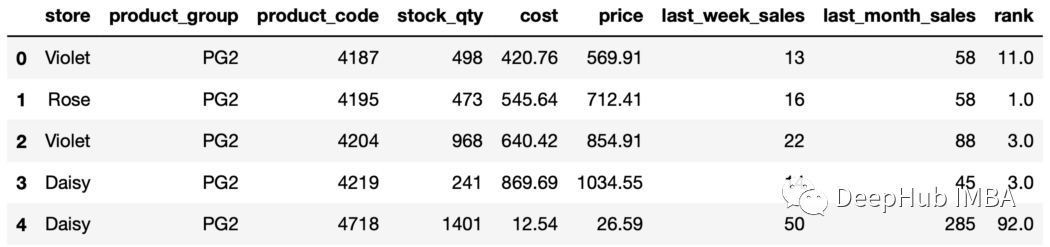
sales["rank"] = sales.groupby("store"["price"].rank(ascending=False, method="dense")sales.head()
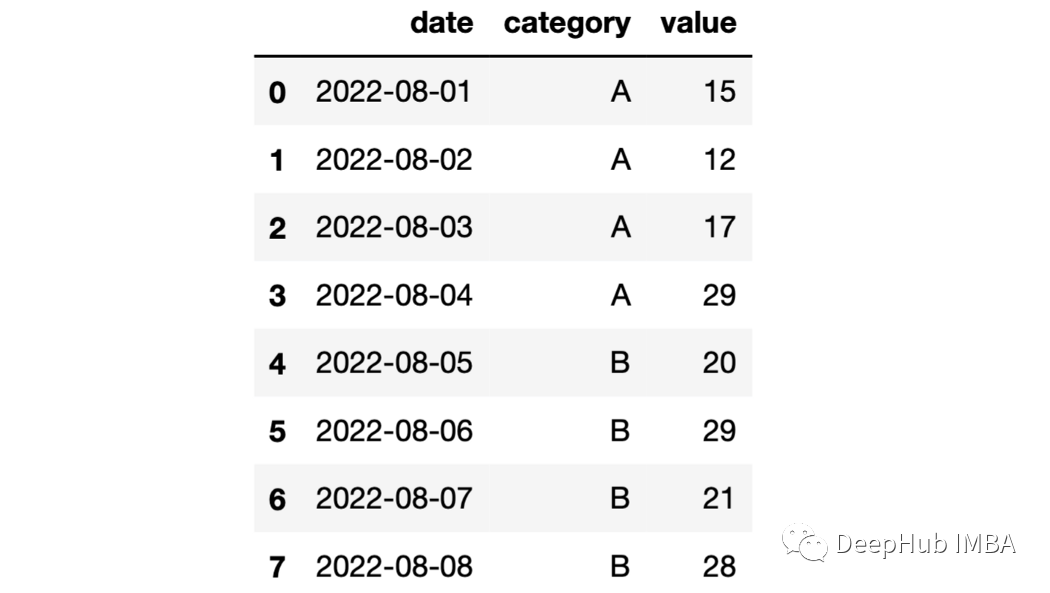
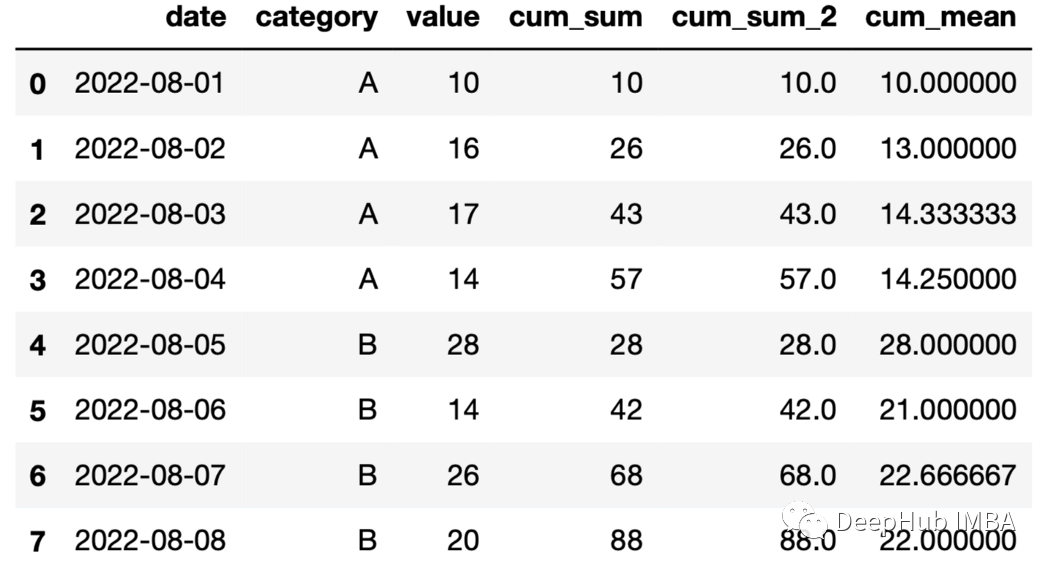
import numpy as npdf = pd.DataFrame({"date": pd.date_range(start="2022-08-01", periods=8, freq="D"),"category": list("AAAABBBB"),"value": np.random.randint(10, 30, size=8)})
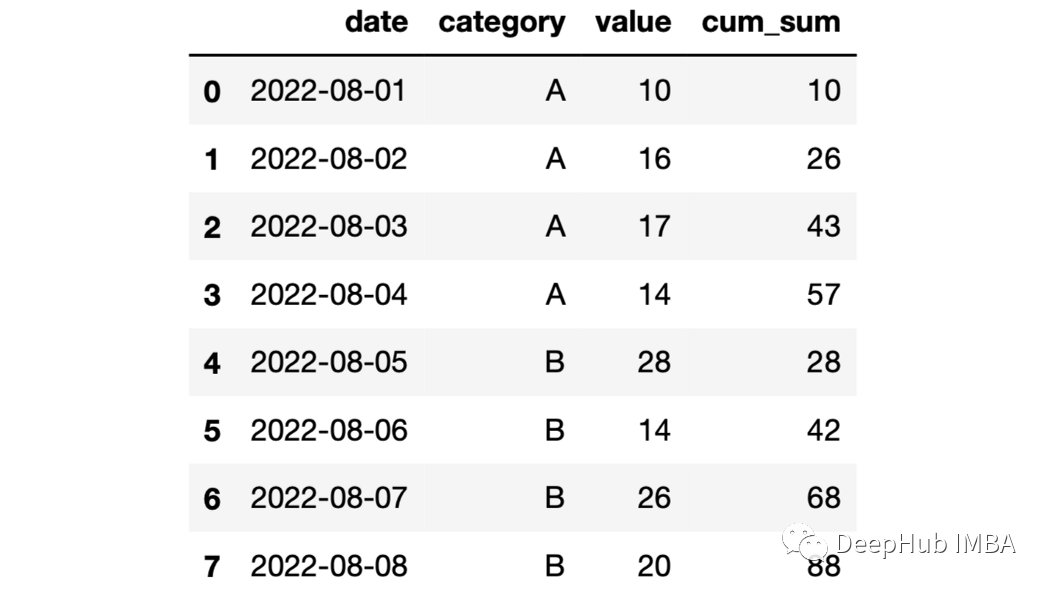
df["cum_sum"] = df.groupby("category")["value"].cumsum()
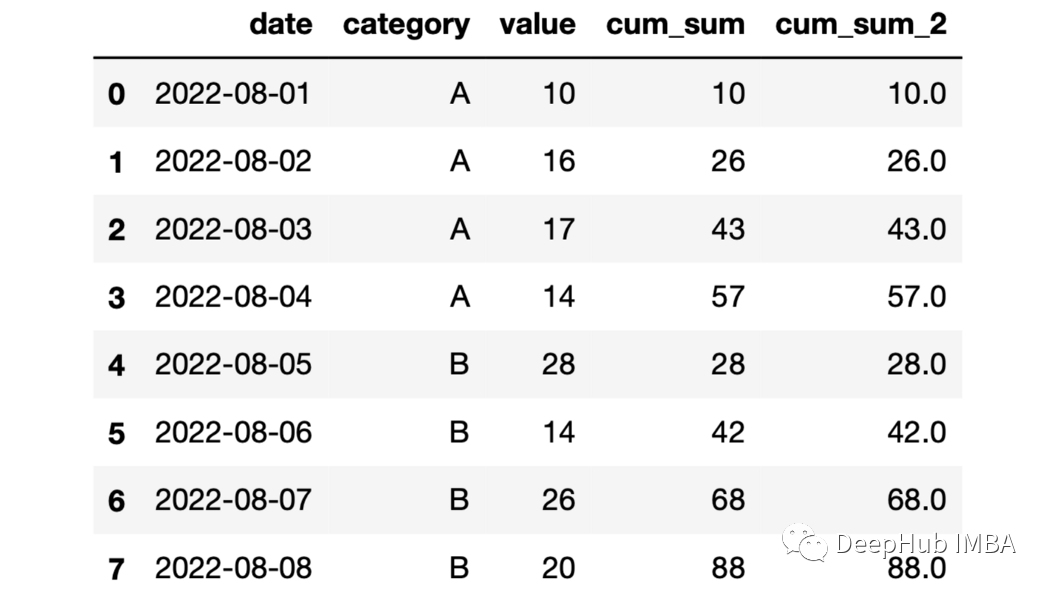
df["cum_sum_2"] = df.groupby("category")["value"].expanding().sum().values
df["cum_mean"] = df.groupby("category")["value"].expanding().mean().values
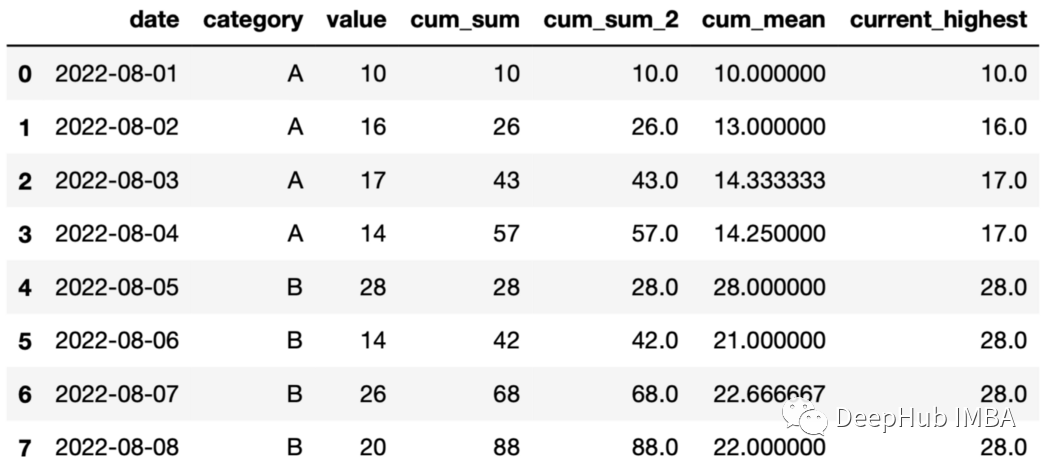
df["current_highest"] = df.groupby("category")["value"].expanding().max().values
评论