
略干,Kubernetes 集群二进制无损升级实践
作者:vivo互联网服务器团队-Shu Yingya
一、背景
活跃的社区和广大的用户群,使 Kubernetes 仍然保持3个月一个版本的高频发布节奏。高频的版本发布带来了更多的新功能落地和 bug 及时修复,但是线上环境业务长期运行,任何变更出错都可能带来巨大的经济损失,升级对企业来说相对吃力,紧跟社区更是几乎不可能,因此高频发布和稳定生产之间的矛盾需要容器团队去衡量和取舍。

vivo 互联网团队建设大规模 Kubernetes 集群以来,部分集群较长时间一直使用 v1.10 版本,但是由于业务容器化比例越来越高,对大规模集群稳定性、应用发布的多样性等诉求日益攀升,集群升级迫在眉睫。集群升级后将解决如下问题:
高版本集群在大规模场景做了优化,升级可以解决一系列性能瓶颈问题。
高版本集群才能支持 OpenKruise 等 CNCF 项目,升级可以解决版本依赖问题。
高版本集群增加的新特性能够提高集群资源利用率,降低服务器成本同时提高集群效率。
公司内部维护多个不同版本集群,升级后减少集群版本碎片化,进一步降低运维成本。
这篇文章将会从0到1的介绍 vivo 互联网团队支撑在线业务的集群如何在不影响原有业务正常运行的情况下从 v1.10 版本升级到 v1.17 版本。之所以升级到 v1.17 而不是更高的 v1.18 以上版本, 是因为在 v1.18 版本引入的代码变动 [1] 会导致 extensions/v1beta1 等高级资源类型无法继续运行(这部分代码在 v1.18 版本删除)。
二、无损升级难点
容器集群搭建通常有二进制 systemd 部署和核心组件静态 Pod 容器化部署两种方式,集群 API 服务多副本对外负载均衡。两种部署方式在升级时没有太大区别,二进制部署更贴合早期集群,因此本文将对二进制方式部署的集群升级做分享。
对二进制方式部署的集群,集群组件升级主要是二进制的替换、配置文件的更新和服务的重启;从生产环境 SLO 要求来看,升级过程务必不能因为集群组件自身逻辑变化导致业务重启。因此升级的难点集中在下面几点:
首先,当前内部集群运行版本较低,但是运行容器数量却很多,其中部分仍然是单副本运行,为了不影响业务运行,需要尽可能避免容器重启,这无疑是升级中最大的难点,而在 v1.10 版本和 v1.17 版本之间,kubelet 关于容器 Hash 值计算方式发生了变化,也就是说一旦升级必然会触发 kubelet 重新启动容器。
其次,社区推荐的方式是基于偏差策略 [2] 的升级以保证高可用集群升级同时不会因为 API resources 版本差异导致 kube-apiserve 和 kubelet 等组件出现兼容性错误,这就要求每次升级组件版本不能有2个 Final Release 以上的偏差,比如直接从 v1.11 升级至 v1.13是不推荐的。
再次,升级过程中由于新特性的引入,API 兼容性可能引发旧版本集群的配置不生效,为整个集群埋下稳定性隐患。这便要求在升级前尽可能的熟悉升级版本间的 ChangeLog,排查出可能带来潜在隐患的新特性。
三、无损升级方案
针对前述的难点,本节将逐个提出针对性解决方案,同时也会介绍升级后遇到的高版本 bug 和解决方法。希望关于升级前期兼容性筛查和升级过程中排查的问题能够给读者带来启发。
3.1 升级方式
在软件领域,主流的应用升级方式有两种,分别是原地升级和替换升级。目前这两种升级方式在业内互联网大厂均有采用,具体方案选择与集群上业务有很大关系。
替换升级
1)Kubernetes 替换升级是先准备一个高版本集群,对低版本集群通过逐个节点排干、删除最后加入新集群的方式将低版本集群内节点逐步轮换升级到新版本。
2)替换升级的优点是原子性更强,逐步升级各个节点,升级过程不存在中间态,对业务安全更有保障;缺点是集群升级工作量较大,排干操作对pod重启敏感度高的应用、有状态应用、单副本应用等都不友好。
原地升级
1)Kubernetes 原地升级是对节点上服务如 kube-controller-manager、 kubelet 等组件按照一定顺序批量更新,从节点角色维度批量管理组件版本。
2)原地升级的优点是自动化操作便捷,并且通过适当的修改能够很好的保证容器的生命周期连续性;缺点是集群升级中组件升级顺序很重要,升级中存在中间态,并且一个组件重启失败可能影响后续其他组件升级,原子性差。
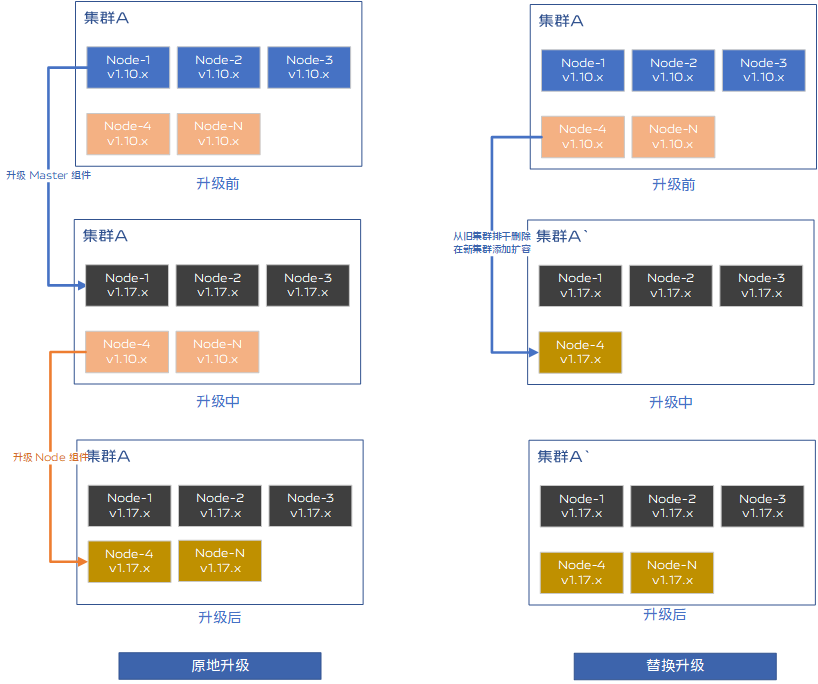
vivo 容器集群上运行的部分业务对重启容忍度较低,尽可能避免容器重启是升级工作的第一要务。当解决好升级版本带来的容器重启后,结合业务容器化程度和业务类型不同,因地制宜的选择升级方式即可。二进制部署集群建议选择原地升级的方式,具有时间短,操作简捷,单副本业务不会被升级影响的好处。
3.2 跨版本升级
由于Kubernetes 本身是基于 API 的微服务架构,Kuberntes 内部架构也是通过 API 的调用和对资源对象的 List-Watch 来协同资源状态,因此社区开发者在设计 API 时遵循向上或向下兼容的原则。这个兼容性规则也是遵循社区的偏差策略 [2],即 API groups 弃用、启用时,对于 Alpha 版本会立即生效,对于 Beta 版本将会继续支持3个版本,超过对应版本将导致 API resource version 不兼容。例如 kubernetes 在 v1.16 对 Deployment 等资源的 extensions/v1beta1 版本执行了弃用,在v1.18 版本从代码级别执行了删除,当跨3个版本以上升级时会导致相关资源无法被识别,相应的增删改查操作都无法执行。
如果按照官方建议的升级策略,从 v1.10 升级到 v1.17 需要经过至少 7 次升级,这对于业务场景复杂的生产环境来说运维复杂度高,业务风险大。
对于类似的 API breaking change 并不是每个版本都会存在,社区建议的偏差策略是最安全的升级策略,经过细致的 Change Log 梳理和充分的跨版本测试,我们确认这几个版本之间不能存在影响业务运行和集群管理操作的 API 兼容性问题,对于 API 类型的废弃,可以通过配置 apiserver 中相应参数来启动继续使用,保证环境业务继续正常运行。
3.3 避免容器重启
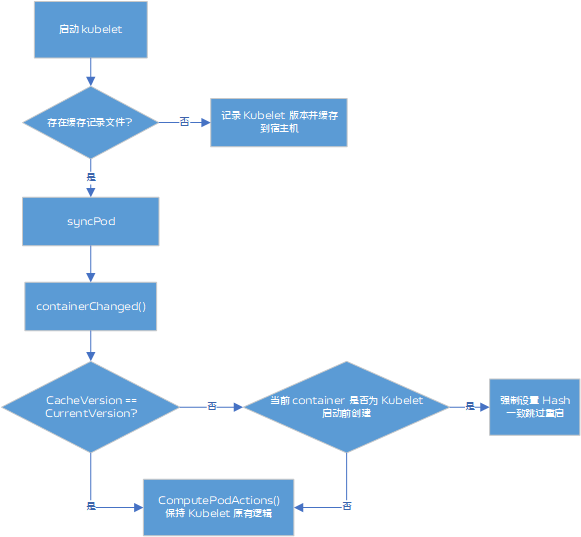
在初步验证升级方案时发现大量容器都被重建,重启原因从升级后 kubelet 组件日志看到是 "Container definition changed"。结合源码报错位于 pkg/kubelet/kuberuntime_manager.go 文件 computePodActions 方法,该方法用来计算 pod 的 spec 哈希值是否发生变化,如果变化则返回 true,告知 kubelet syncPod 方法触发 pod 内容器重建或者 pod 重建。
kubelet 容器 Hash 计算;
func (m *kubeGenericRuntimeManager) computePodActions(pod *v1.Pod, podStatus *kubecontainer.PodStatus) podActions {restart := shouldRestartOnFailure(pod)if _, _, changed := containerChanged(&container, containerStatus); changed {message = fmt.Sprintf("Container %s definition changed", container.Name)// 如果 container spec 发生变化,将会强制重启 container(将 restart 标志位设置为 true)restart = true}...if restart {message = fmt.Sprintf("%s, will be restarted", message)// 需要重启的 container 加入到重启列表changes.ContainersToStart = append(changes.ContainersToStart, idx)}}func containerChanged(container *v1.Container, containerStatus *kubecontainer.ContainerStatus) (uint64, uint64, bool) {// 计算 container spec 的 Hash 值expectedHash := kubecontainer.HashContainer(container)return expectedHash, containerStatus.Hash, containerStatus.Hash != expectedHash}
相对于 v1.10 版本,v1.17 版本在计算容器 Hash 时使用的是 container 结构 json 序列化后的数据,而不是 v1.10 版本使用 container struct 的结构数据。而且高版本 kubelet 中对容器的结构也增加了新的属性,通过 go-spew 库计算出结果自然不一致,进一步向上传递返回值使得 syncPod 方法触发容器重建。
那是否可以通过修改 go-spew 对 container struct 的数据结构剔除新增的字段呢? 答案是肯定的,但是却不是优雅的方式,因为这样对核心代码逻辑侵入较为严重,以后每个版本的升级都需要定制代码,并且新增的字段越来越多,维护复杂度也会越来越高。换个角度,如果在升级过渡期间将属于旧版本集群 kubelet 创建的 Pod 跳过该检查,则可以避免容器重启。
和圈内同事交流后发现类似思路在社区已有实现,本地创建一个记录旧集群版本信息和启动时间的配置文件,kubelet 代码中维护一个 cache 读取配置文件,在每个 syncPod 周期中,当 kubelet 发现自身 version 高于 cache 中记录的 oldVersion, 并且容器启动时间早于当前 kubelet 启动时间,则会跳过容器 Hash 值计算。升级后的集群内运行定时任务探测 Pod 的 containerSpec 是否与高版本计算方式计算得到 Hash 结果全部一致,如果是则可以删除掉本地配置文件,syncPod 逻辑恢复到与社区完全一致。
具体方案参考 这种实现的好处是对原生 kubelet 代码侵入小,没有改变核心代码逻辑,而且未来如果还需要升级高版本也可以复用该代码。如果集群内所有 Pod 都是当前版本 kubelet 创建,则会恢复到社区自身的逻辑。
3.4 Pod 非预期驱逐问题
Kubernetes 虽然迭代了十几个版本,但是每个迭代社区活跃度仍然很高,保持着每个版本大约30个关于拓展性增强和稳定性提升的新特性。选择升级很大一方面原因是引入很多社区开发的新特性来丰富集群的功能与提升集群稳定性。新特性开发也是遵循偏差策略,跨大版本升级很可能导致在部分配置未加载的情况下启用新特性,这就给集群带来稳定性风险,因此需要梳理影响 Pod 生命周期的一些特性,尤其关注控制器相关的功能。
这里注意到在 v1.13 版本引入的 TaintBasedEvictions 特性用于更细粒度的管理 Pod 的驱逐条件。在 v1.13基于条件版本之前,驱逐是基于 NodeController 的统一时间驱逐,节点 NotReady 超过默认5分钟后,节点上的 Pod 才会被驱逐;在 v1.16 默认开启 TaintBasedEvictions 后,节点 NotReady 的驱逐将会根据每个 Pod 自身配置的 TolerationSeconds 来差异化的处理。
旧版本集群创建的 Pod 默认没有设置 TolerationSeconds,一旦升级完毕 TaintBasedEvictions 被开启,节点变成 NotReady 后 5 秒就会驱逐节点上的 Pod。对于短暂的网络波动、kubelet 重启等情况都会影响集群中业务的稳定性。
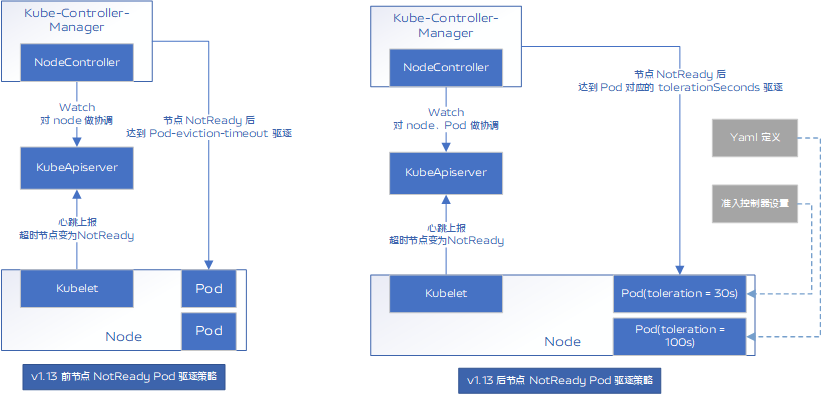
TaintBasedEvictions 对应的控制器是按照 pod 定义中的 tolerationSeconds 决定 Pod 的驱逐时间,也就是说只要正确设置 Pod 中的 tolerationSeconds 就可以避免出现 Pod 的非预期驱逐。
在v1.16 版本社区默认开启的 DefaultTolerationSeconds 准入控制器基于 k8s-apiserver 输入参数 default-not-ready-toleration-seconds 和 default-unreachable-toleration-seconds 为 Pod 设置默认的容忍度,以容忍 notready:NoExecute 和 unreachable:NoExecute 污点。
新建 Pod 在请求发送后会经过 DefaultTolerationSeconds 准入控制器给 pod 加上默认的 tolerations。但是这个逻辑如何对集群中已经创建的 Pod 生效呢?查看该准入控制器发现除了支持 create 操作,update 操作也会更新 pod 定义触发 DefaultTolerationSeconds 插件去设置 tolerations。因此我们通过给集群中已经运行的 Pod 打 label 就可以达成目的。
tolerations:effect: NoExecutekey: node.kubernetes.io/not-readyoperator: ExiststolerationSeconds: 300effect: NoExecutekey: node.kubernetes.io/unreachableoperator: ExiststolerationSeconds: 300
3.5 Pod MatchNodeSelector
为了判断升级时 Pod 是否发生非预期的驱逐以及是否存在 Pod 内容器批量重启,有脚本去实时同步节点上非Running状态的Pod和发生重启的容器。
在升级过程中,突然多出来数十个 pod 被标记为 MatchNodeSelector 状态,查看该节点上业务容器确实停止。kubelet 日志中看到如下错误日志;
predicate.go:132] Predicate failed on Pod: nginx-7dd9db975d-j578s_default(e3b79017-0b15-11ec-9cd4-000c29c4fa15), for reason: Predicate MatchNodeSelector failedkubelet_pods.go:1125] Killing unwanted pod "nginx-7dd9db975d-j578s"
经分析,Pod 变成 MatchNodeSelector 状态是因为 kubelet 重启时对节点上 Pod 做准入检查时无法找到节点满足要求的节点标签,pod 状态就会被设置为 Failed 状态,而 Reason 被设置为 MatchNodeSelector。在 kubectl 命令获取时,printer 做了相应转换直接显示了Reason,因此我们看到 Pod 状态是 MatchNodeSelector。通过给节点加上标签,可以让 Pod 重新调度回来,然后删除掉 MatchNodeSelector 状态的 Pod 即可。
建议在升级前写脚本检查节点上 pod 定义中使用的 NodeSelector 属性节点是否都有对应的 Label。
3.6 无法访问 kube-apiserver
预发环境升级后的集群运行在 v1.17 版本后,突然有节点变成 NotReady 状态告警,分析后通过重启 kubelet 节点恢复正常。继续分析出错原因发现 kubelet 日志中出现了大量 use of closed network connection 报错。在社区搜索相关 issue 发现有类似的问题,其中有开发者描述了问题的起因和解决办法,并且在 v1.18 已经合入了代码。
问题的起因是 kubelet 默认连接是 HTTP/2.0 长连接,在构建 client 到 server的连接时使用的 golang net/http2 包存在 bug,在 http 连接池中仍然能获取到 broken 的连接,也就导致 kubelet 无法正常与 kube-apiserver 通信。
golang社区通过增加 http2 连接健康检查规避这个问题,但是这个 fix 仍然存在 bug ,社区在 golang v1.15.11 版本彻底修复。我们内部通过 backport 到 v1.17 分支,并使用 golang 1.15.15 版本编译二进制解决了此问题。
3.7 TCP 连接数问题
在预发布环境测试运行期间,偶然发现集群每个节点 kubelet 都有近10个长连接与 kube-apiserver 通信,这与我们认知的 kubelet 会复用连接与 kube-apiserver 通信明显不符,查看 v1.10 版本环境也确实只有1个长连接。这种 TCP 连接数增加情况无疑会对 LB 造成了压力,随着节点增多,一旦 LB 被拖垮,kubelet 无法上报心跳,节点会变成 NotReady,紧接着将会有大量 Pod 被驱逐,后果是灾难性的。因此除去对 LB 本身参数调优外,还需要定位清楚kubelet 到 kube-apiserver 连接数增加的原因。
在本地搭建的 v1.17.1 版本 kubeadm 集群 kubelet 到 kube-apiserver 也仅有1个长连接,说明这个问题是在 v1.17.1 到升级目标版本之间引入的,排查后(问题)发现增加了判断逻辑导致 kubelet 获取 client 时不再从 cache 中获取缓存的长连接。transport 的主要功能其实就是缓存了长连接,用于大量 http 请求场景下的连接复用,减少发送请求时 TCP(TLS) 连接建立的时间损耗。在该 PR 中对 transport 自定义 RoundTripper 的接口,一旦 tlsConfig 对象中有 Dial 或者 Proxy 属性,则不使用 cache 中的连接而新建连接。
// client-go 从 cache 获取复用连接逻辑func tlsConfigKey(c *Config) (tlsCacheKey, bool, error) {...if c.TLS.GetCert != nil || c.Dial != nil || c.Proxy != nil {// cannot determine equality for functionsreturn tlsCacheKey{}, false, nil}...}func (c *tlsTransportCache) get(config *Config) (http.RoundTripper, error) {key, canCache, err := tlsConfigKey(config)...if canCache {// Ensure we only create a single transport for the given TLS optionsc.mu.Lock()defer c.mu.Unlock()// See if we already have a custom transport for this configif t, ok := c.transports[key]; ok {return t, nil}}...}// kubelet 组件构建 client 逻辑func buildKubeletClientConfig(ctx context.Context, s *options.KubeletServer, nodeName types.NodeName) (*restclient.Config, func(), error) {...kubeClientConfigOverrides(s, clientConfig)closeAllConns, err := updateDialer(clientConfig)...return clientConfig, closeAllConns, nil}// 为 clientConfig 设置 Dial属性,因此 kubelet 构建 clinet 时会新建 transportfunc updateDialer(clientConfig *restclient.Config) (func(), error) {if clientConfig.Transport != nil || clientConfig.Dial != nil {return nil, fmt.Errorf("there is already a transport or dialer configured")}d := connrotation.NewDialer((&net.Dialer{Timeout: 30 * time.Second, KeepAlive: 30 * time.Second}).DialContext)clientConfig.Dial = d.DialContextreturn d.CloseAll, nil
在这里构建 closeAllConns 对象来关闭已经处于 Dead 但是尚未 Close 的连接,但是上一个问题通过升级 golang 版本解决了这个问题,因此我们在本地代码分支回退了该修改中的部分代码解决了 TCP 连接数增加的问题。
最近追踪社区发现已经合并了解决方案 ,通过重构 client-go 的接口实现对自定义 RESTClient 的 TCP 连接复用。
四、无损升级操作
跨版本升级最大的风险是升级前后对象定义不一致,可能导致升级后的组件无法解析保存在 ETCD 数据库中的对象;也可能是升级存在中间态,kubelet 还未升级而控制平面组件升级,存在上报状态异常,最坏的情况是节点上 Pod 被驱逐。这些都是升级前需要考虑并通过测试验证的。
经过反复测试,上述问题在 v1.10 到 v1.17 之间除了部分废弃的 API Resources 通过增加 kube-apiserver 配置方式其他情况暂时不存在。为了保证升级时及时能处理未覆盖到的特殊情况,强烈建议升级前备份 ETCD 数据库,并在升级期间停止控制器和调度器,避免非预期的控制逻辑发生(实际上这里应该是停止 controller manager 中的部分控制器,不过需要修改代码编译临时 controller manager ,增加了升级流程步骤和管理复杂度,因此直接停掉了全局控制器)。
除却以上代码变动和升级流程注意事项,在替换二进制升级前,就剩下比对新老版本服务的配置项的区别以保证服务成功启动运行。对比后发现,kubelet 组件启动时不再支持 --allow-privileged 参数,需要删除。值得说明的是,删除不代表高版本不再支持节点上运行特权容器,在 v1.15 以后通过 Pod Security Policy 资源对象来定义一组 pod 访问的安全特征,更细粒度的做安全管控。
基于上面讨论的无损升级代码侧的修改编译二进制,再对集群组件配置文件中各个配置项修改后,就可以着手线上升级。整个升级步骤为:
备份集群(二进制,配置文件,ETCD数据库等);
灰度升级部分节点,验证二进制和配置文件正确性
提前分发升级的二进制文件;
停止控制器、调度器和告警;
更新控制平面服务配置文件,升级组件;
更新计算节点服务配置文件,升级组件;
为节点打 Label 触发 pod 增加 tolerations 属性;
打开控制器和调度器,启用告警;
集群业务点检,确认集群正常。
升级过程中建议节点并发数不要太高,因为大量节点 kubelet 同时重启上报信息,对 kube-apiserver 前面使用的 LB 带来冲击,特别情况下可能节点心跳上报失败,节点状态会在 NotReady 与 Ready 状态间跳动。
五、总结
集群升级是困扰容器团队比较长时间的事,在经过一系列调研和反复测试,解决了上面提到的数个关键问题后,成功将集群从 v1.10 升级到 v1.17 版本,1000 个节点的集群分批执行升级操作,大概花费 10 分钟,后续在完成平台接口改造后将会再次升级到更高版本。
集群版本升级提高了集群的稳定性、增加了集群的扩展性,同时还丰富了集群的能力,升级后的集群也能够更好的兼容 CNCF 项目。
如开篇所述,按照偏差策略频繁对大规模集群升级可能不太现实,因此跨版本升级虽然风险较大,但是也是业界广泛采用的方式。在 2021 年中国 KubeCon 大会上,阿里巴巴也有关于零停机跨版本升级 Kubernetes 集群的分享,主要是关于应用迁移、流量切换等升级关键点的介绍,升级的准备工作和升级过程相对复杂。相对于阿里巴巴的集群跨版本替换升级方案,原地升级的方式需要在源码上做少量修改,但是升级过程会更简单,运维自动化程度更高。
由于集群版本具有很大的可选择性,本文所述的升级并不一定广泛适用,笔者更希望给读者提供生产集群在跨版本升级时的思路和风险点。升级过程短暂,但是升级前的准备和调研工作是费时费力的,需要对不同版本 Kubernetes 特性和源码深入探索,同时对 Kubernetes 的 API 兼容性策略和发布策略拥有完整认知,这样便能在升级前做出充分的测试,也能更从容面对升级过程中突发情况。
六、参考链接
[1]https://github.com
[2] https://kubernetes.io/version-skew-policy
[3] 具体方案参考:https://github.comstart
[4] 类似的问题: https://github.com/kubernetes
[5] https://github.com/golang/34978
[6] https://github.com/kubernetes/100376
[7] https://github.com/kubernetes/95427
[8] https://github.com/kubernetes/105490