
清华&旷视:让VGG再次伟大!
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
丰色 发自 凹非寺
量子位 报道 | 公众号 QbitAI
CNN经典模型VGG自2014年诞生以来,由于相比于各种多分支架构(如ResNet) 性能不佳,已渐“没落”……
但来自清华大学和旷视科技等机构的研究人员,他们居然只用3x3卷积和ReLU激活函数的超级简单架构,通过结构重参数化 (structural re-parameterization),就让这个7年前的老架构再次“容光焕发”!Great Again!
简单到什么程度?研究人员表示:
下午5点看完文章,晚饭前就能写完代码开始训练,第二天就能看到结果。如果没时间看完这篇文章,只要点开GitHub上的代码,看完前100行就可以完全搞明白。
新架构RepVGG结合了多分支架构和单路架构的优点,在速度和性能上直达SOTA,在ImageNet上精度超过80%!

相关论文已被CVPR 2021接收,开源预训练模型和代码在GitHub上也已收获1700+ 标星!

兼顾多分支和单路架构的优点
一个已经快要“没落”的老模型,为什么还要重新捡起利用?
研究人员介绍道,因为简单的VGG式模型(单路架构、仅使用3x3卷积和ReLU激活函数)有五大现实优势:
1、3x3卷积非常快。在GPU上,3x3卷积的计算密度(理论运算量除以所用时间)可达1x1和5x5卷积的四倍。
2、单路架构因为并行度高也非常快。同样的计算量,“大而整”的运算效率远超“小而碎”的运算。
3、单路架构省内存。例如,ResNet的shortcut虽然不占计算量,却增加了一倍的显存占用。
4、单路架构灵活性更好,容易改变各层的宽度(如剪枝)。
5、RepVGG主体部分只有一种算子:3x3卷积接ReLU。在设计专用芯片时,给定芯片尺寸或造价,我们可以集成海量的3x3卷积-ReLU计算单元来达到很高的效率。别忘了,单路架构省内存的特性也可以帮我们少做存储单元。
由于多分支架构性能更好,为了让新架构RepVGG兼顾两者优点,他们提出一个新的做法:先训练一个多分支模型,然后将多分支模型等价转换为单路模型,最后部署这个单路模型。
具体来说,首先借鉴ResNet的做法,在训练时为每一个3x3卷积层添加平行的1x1卷积分支和恒等映射分支,构成一个RepVGG Block。
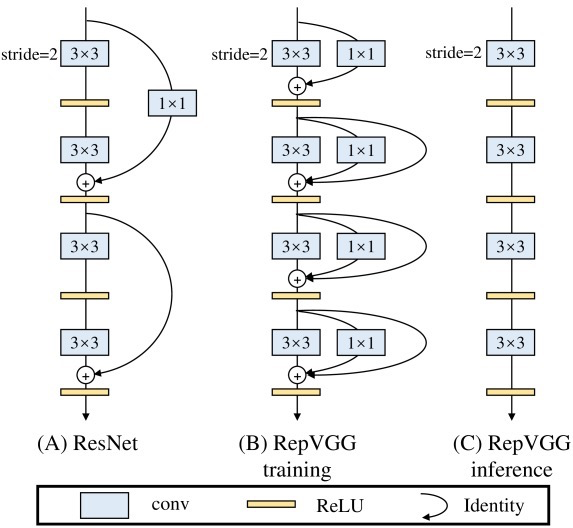
然后需将RepVGG Block转换为一个卷积,也就是将训练好的模型等价转换为只有3x3卷积的单路模型。
怎么转换?结构重参数化!
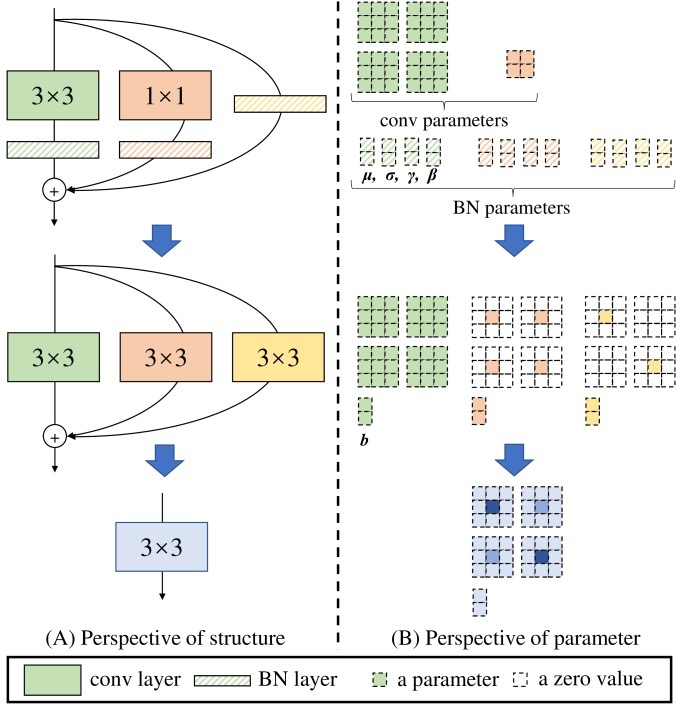
如上图,利用卷积的相加性,需经过两次变换。
示例中,输入输出通道数都是2,那3x3卷积核所对应的参数矩阵为2x2x3x3,也就是4个3x3矩阵,1x1卷积核对应的参数矩阵为2x2x1x1,也就是4个1x1矩阵,为了画图方便换成1个2x2矩阵。
把1x1卷积等价转换为3x3卷积,只要用0填充一下就行了。
而恒等映射是一个特殊(以单位矩阵为卷积核)的1x1卷积,因此也是一个特殊的3x3卷积。
以上三个分支都有BN(batch normalization)层,推理时的卷积层和其后的BN层可转换为一个带bias的卷积层。
最后,将三分支得到的卷积核和bias分别相加,完成等价转换为只有3x3卷积的单路模型。
从这一转换过程中,我们看到了“结构重参数化”的实质:训练时的结构对应一组参数,推理时我们想要的结构对应另一组参数;只要能把前者的参数等价转换为后者,就可以将前者的结构等价转换为后者。
不少人都称赞这篇论文的思路非常有意思,简单易懂,让人眼前一亮!
效果确实也非常不错——
速度和精度达SOTA
RepVGG这样只用3x3卷积和ReLU激活函数的简单架构,特别适用于GPU和特殊推理芯片(inference chips)。
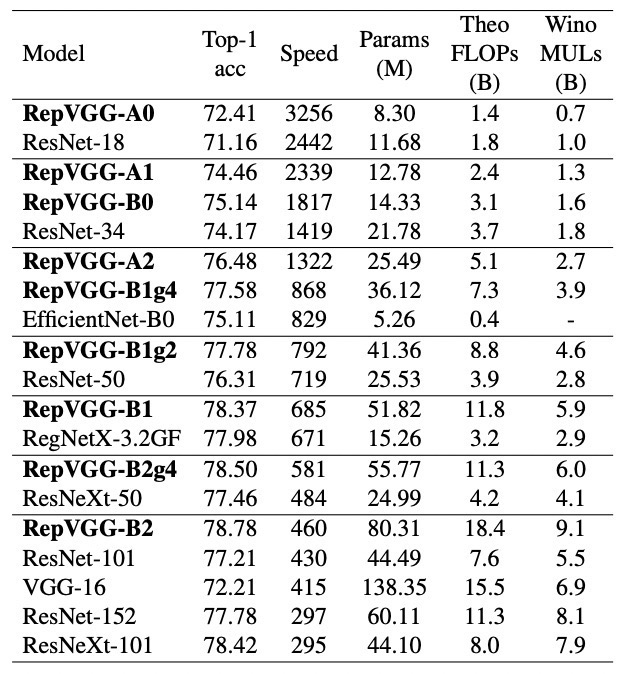
研究人员在1080Ti上对RepVGG进行了测试。在公平的训练设定下,同精度的RepVGG速度是ResNet-50的183%,ResNet-101的201%,EfficientNet的259%,RegNet的131%。
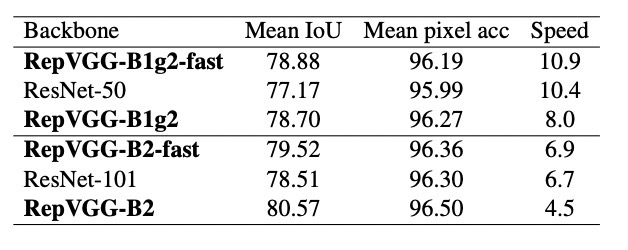
在Cityscapes上的语义分割实验表明,在速度更快的情况下,RepVGG模型比ResNet系列高约1%到1.7%的mIoU,或在mIoU高0.37%的情况下速度快62%。
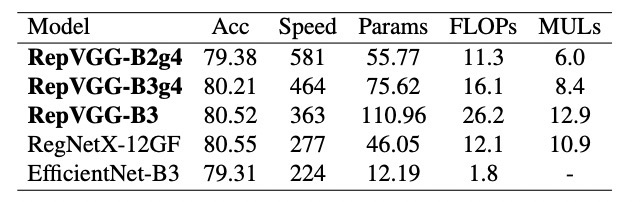
通过结构重参数化,RepVGG在ImageNet上达到了80.57%的top1精度,与最先进的复杂模型相比,速度-精度都非常出色。
关于作者
论文一作:丁霄汉,清华大学计算机视觉博士生,研究方向是计算机视觉和机器学习。在CVPR、ICML、ICCV、NeurIPS作为第一作者发表论文5篇。曾获得第七届百度奖学金荣誉——“十位顶尖 AI 学子”之一。

论文二作:张详雨,旷视科技旷视研究院base model组负责人,西安交大博士生。曾在微软亚洲研究院实习,是ResNet的主要作者之一。

论文三作:马宁宁,香港科技大学与旷视联合培养博士,主要研究方向为计算机视觉和高性能卷积神经网络。

论文地址:https://arxiv.org/abs/2101.03697
GitHub地址:https://github.com/DingXiaoH/RepVGG
参考链接:
[1]https://www.reddit.com/r/MachineLearning/comments/nqflsp/rrepvgg_making_vggstyle_convnets_great_again/
[2]https://zhuanlan.zhihu.com/p/344324470
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。

点个在看 paper不断!