
CVPR 2022|一文详解MSRA提出的掩码图像建模的简单框架SimMIM

极市导读
SimMIM 是继 BEiT 之后,MSRA 又提出的一个 MIM 任务上的预训练 CV 模型。这个模型也是直接回归预测原始像素 RGB 值,而不是像 BEiT 或者 iBOT 一样重建 tokens。作者在这篇论文中想探讨的是:究竟是什么使得 MIM 任务能够使得目标网络能学到更好的 visual representation。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
深度了解自监督学习,就看这篇解读 !Hinton团队力作:SimCLR系列
深度了解自监督学习,就看这篇解读 !微软首创:运用在 image 领域的BERT
深度了解自监督学习,就看这篇解读 !何恺明新作MAE:通向CV大模型
本文目录
1 SimMIM
1.1 SimMIM 方法概述
1.2 Masking Strategy
1.3 Encoder 结构
1.4 Prediction head
1.5 Prediction target
1.6 Evaluation protocols
1.7 Masking strategy 对表征学习的影响
1.8 Projection head 对表征学习的影响
1.9 Projection resolution 对表征学习的影响
1.10 Projection target 对表征学习的影响
1.11 ImageNet-1k 实验结果
1.12 可视化结果
Self-Supervised Learning,又称为自监督学习,我们知道一般机器学习分为有监督学习,无监督学习和强化学习。而 Self-Supervised Learning 是无监督学习里面的一种,主要是希望能够学习到一种通用的特征表达用于下游任务 (Downstream Tasks)。其主要的方式就是通过自己监督自己。作为代表作的 kaiming 的 MoCo 引发一波热议, Yann Lecun也在 AAAI 上讲 Self-Supervised Learning 是未来的大势所趋。所以在这个系列中,我会系统地解读 Self-Supervised Learning 的经典工作。
1 SimMIM
论文名称:SimMIM: A Simple Framework for Masked Image Modeling
论文地址:
https://arxiv.org/abs/2111.09886
前段时间,何恺明等人的一篇论文成为了计算机视觉圈的焦点。这篇论文仅用简单的 idea(即掩蔽自编码器,MAE)就达到了非常理想的性能,让人们看到了 Transformer 扩展到 CV 大模型的光明前景,给该领域的研究者带来了很大的鼓舞:
深度了解自监督学习,就看这篇解读 !何恺明新作MAE:通向CV大模型
SimMIM 是继 BEiT 之后,MSRA 又提出的一个 MIM 任务上的预训练 CV 模型。这个模型更像是 kaiming 的 MAE,也是直接回归预测原始像素 RGB 值,而不是像 BEiT 或者 iBOT 一样重建 tokens。作者在这篇论文中想探讨的是:究竟是什么使得 MIM 任务能够使得目标网络能学到更好的 visual representation。得出了以下3条结论:(1) 在 MIM 任务中,mask patch 的大小如果是32×32,就能使得预训练任务成为一个 strong pre-text task,非常有利于预训练大模型性能的提升。(2) 直接回归预测原始像素 RGB 值的效果并不比复杂设计的patch分类方法差。(3) prediction head 可以设计成轻量化的模型,比如一个线性层,它的表现不比 heavy 模型差。
1.1 SimMIM 方法概述
上来先引用一句名言:)
“What I cannot create, I do not understand.” — Richard Feynman
作者可能是想说:要想玩明白 Masked Signal Learning 任务 (就是指这样一种任务:挡住输入信号的一部分,把残缺的信号送入模型,希望模型能够预测出这些被 masked 掉的信号),或者说,要想让模型创造出这些被 masked 掉的信号,就得使得模型首先理解它们。
对于自监督学习的任务而言,我们之前介绍的方法,如 MoCo,MoCo v2,MoCo v3,SimCLR,BYOL 等,它们都是采用对比学习的策略完成,属于自监督学习范式中的 Contrastive 系列。问:对于图像而言,Contrastive Learning 的做法真的是最好的吗?或者,直接把 NLP 领域的 MLM 方法迁移到 CV 领域的 MIM,是可取的吗?
第一,我们知道对于图像信号而言,相邻像素之间联系非常紧密 (highly correlated),所以解决 MIM 问题的好方法可能是更多地借助或者 copy masked 部分周围的像素,而不是更高维的语义信息的推理。
第二,语言和视觉信号的语义高度不同,这点和 kaiming 的信息密度的观点是一致的,即:视觉信号是 raw 和 low-level 的,而文本信号是 high-level 的。那么,预测 low level 信号会有利于 high level 的图像识别问题吗?
第三,视觉信号通常是连续的,而文本信号通常是离散的。
总之,基于以上3点分析,作者提出了 SimMIM 模型,和一周之前 kaiming 的 MAE 在思路上面十分相似,很多具体做法都是一样的,但是在模型设计上给出了不同的见解。不一样的地方是:MAE 重建所有的 patches,不论是 masked 还是 unmasked,MAE 本质上属于 Reconstruction 的任务;而 SimMIM 实验证明重建所有的 patches 的效果不如只重建 masked patches 的效果,SimMIM 本质上属于 Prediction 的任务。值得注意的是二者是完全同期的工作 (前后只差一周),说明实力很强的大厂对于 CV 大模型的训练和设计都得出了比较相似的结论。
1.2 Masking Strategy
SimMIM 的 Masking Strategy 和 kaiming 的 MAE 不同,MAE 采取的做法是直接扔掉被 mask 的 patches,但是 SimMIM 采取的做法和 BEiT,BERT 一致,即把 mask 的 patches 替换成可学习的 mask token vector,并随着网络一起训练。mask 的基本单位仍然是 Image Patches,对于 ViT 模型,masked patch size 使用32×32;对于 Swin Transformer 模型,masked patch size 使用4×4-32×32。
1.3 Encoder 结构
即目标网络的架构,实际使用了 ViT 模型和 Swin Transformer 模型。
1.4 Prediction head
只要输入与 Encoder 的输出一致,输出达到预测目的,Prediction head 就可以具有任意结构,哪怕是一个 Linear Layer。
1.5 Prediction target
作者希望 Prediction head 的输出就是重建之后的原图,所以,为了预测输入图像在 full-resolution 下的所有像素值,我们将 feature map 映射回原始分辨率,并由这个 feature map 负责对相应原始像素的预测。
比如,当使用 Swin Transformer Encoder 时,输出是 downsample 32倍的 feature map。此时要先通过1×1的卷积 (或者叫 Linear Layer),输出维度是3072=3×32×32。再使用 loss:
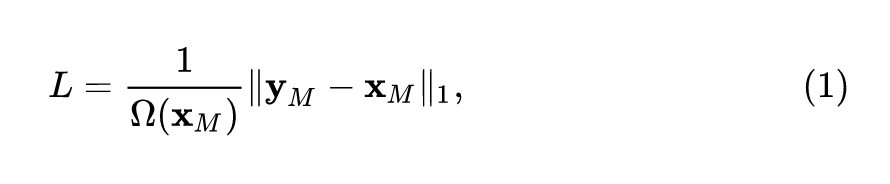
式中, 是输入的 RGB 值和预测值, 是 element 的数量。
1.6 Evaluation protocols
作者使用的评价指标是 Fine-tuning,即在模型最后添加一层线性分类器 Linear Classifier (它其实就是一个 FC 层) 完成分类,同时使用全部 label 训练目标网络 Backbone 部分的权重和分类器的权重。也报了 linear probing 的结果,即把目标网络 Backbone 部分的权重冻结,在模型最后添加一层线性分类器 Linear Classifier 完成分类,只训练 Linear Classifier 的参数。
1.7 Masking strategy 对表征学习的影响
作者采用 Swin-B 作为消融研究的默认骨干。为了减少实验开销,默认的输入图像大小为 192×192,并将窗口大小调整为6以适应改变的输入图像大小。
预训练配置: AdamW,100 epochs,cosine learning rate scheduler,batch size=2048,base lr=8e-4,weight decay=0.05,warmup epochs=10。
预训练 Data Augmentation: Random resize cropping,比例范围为[0.67,1],宽高比范围为[3/ 4,4 /3],Random flipping + Color normalization。
Fine-tuning 配置: AdamW,100 epochs,cosine learning rate scheduler,batch size=2048,base lr=5e-3,weight decay=0.05,warmup epochs=10,stochastic depth ratio=0.1。
Fine-tuning Data Augmentation: RandAug,Mixup,Cutmix,Label smoothing,Random erasing。
首先研究了不同 masking strategy 对表征学习的影响,结果如下图1所示。最佳的 random masking strategy 使得 Accuracy 达到了83.0%。此时超参数是 mask patch size=32,mask ratio=50%,即挡住50%的原图。这个结果比 BEiT 高0.3%。
此外,当 mask patch size=32 时,mask ratio 在10%-70%时都能够取得很不错的结果。作者认为这个实验结果产生的原因是:一个 mask 中心的像素距离边界可见像素是足够远的,因此可以强迫网络学习到一些 long-range 的关系,即使 mask 掉的像素足够多。将 mask ratio 由0.4增加至0.8,在 patch size 大小为4,8和16的情况下,准确率分别提高了0.2%,0.4%和0.4%。使用更大的 mask ratio ,这也证明了相对较小的 patch 尺寸有利于微调性能。然而,这些较小的 patch 的总体精度不如较大的 patch(32) 的高。进一步将 patch 大小增加到64的观测精度下降,可能是由于预测距离太大。

上述观察和分析也可以很好地反映在一个新提出的 AvgDist 度量,该度量测量掩码像素到最近的可见像素的平均欧氏距离。 不同掩码策略与不同掩蔽率的 AvgDist 如图2(a)所示。从图中可以看出,所有的 masking strategy 的AvgDist 都随着 masking ratio 的增大而平滑增大。对于随机掩码策略,当 patch size 较小 (如4或8) 时, AvgDist 相对较低,且随着掩码率的增加而增长缓慢。另一方面,当 patch size 较大时 (如64),很小的 mask ratio (如10%) 仍然会产生较大的 AvgDist。
图2(b)绘制了微调精度和 AvgDist 度量之间的关系,它遵循山脊 (ridge) 形状。微调精度高的条目大致分布在 AvgDist 的[10,20]范围内,而 AvgDist 越小或越高的条目表现越差。这表明掩码图像建模中的预测距离应该适中,既不要太大,也不要太小。

在掩码预测中,AugDist 太小的话,网络可能会学习到太多的短连接,AugDist 太大的话,网络可能会很难学习。这些结果也表明,AvgDist可能是一个很好的指标用于检测掩码建模的有效性。
实际使用的 mask ratio=0.6,patch size=32。
1.8 Projection head 对表征学习的影响
下图3对比了不同结构的 Projection head 对结果的影响。作者依次尝试了 Linear layer,2层 MLP,inverse 的 Swin-T 和 inverse 的 Swin-B 架构。发现参数量大的 Projection head 会带来更低的 loss,但是 Top-1 的 Accuracy 反而变低了。这意味着预训练 impainting 的能力并不代表下游任务的能力。
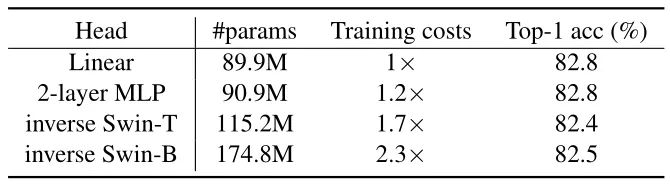
另外,一个有意思的发现是:之前的基于 Contrastive learning 的自监督学习工作,如 MoCo,MoCo v2,MoCo v3,SimCLR 等等它们发现 Projection head 用2层的比单层 MLP 好一点。原因是 Projection head 太深的话会导致 Pre-text 的任务学习到的 latent representation 与下游任务需要的差距过大。所以 SimMIM 发现 Projection head 就用一层 MLP 就非常好,也意味着 Contrastive learning 任务设计 Projection head 的方法可能并不适用于 MIM 任务。
1.9 Projection resolution 对表征学习的影响
下图4对比了不同的 Projection resolution 对结果的影响。大范围的分辨率 (12×12-192×192) 都能表现良好。传输性能只有在6×6的分辨率的低分辨率下才会下降,可能是因为6×6的分辨率丢弃了太多信息。这些结果反映了下游图像分类任务所需的信息粒度。也告诉我们:MLM 任务的 pre-text 属于分类任务,但是这并不意味着 MIM 任务的 pre-text 的最优选择也是分类任务,比如 MAE 和 SimMIM 的 pre-text 属于回归任务。

1.10 Projection target 对表征学习的影响
下图5对比了不同的 Projection target 对结果的影响。使用 loss,smooth loss, loss 的结果都差不多。
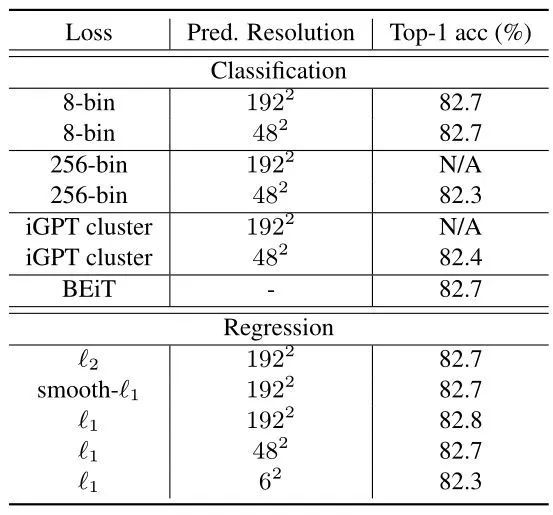
值得注意的是:SimMIM 和 MAE 的另一个很重要的不同是:SimMIM 只重建 masked patches (Prediction),而 MAE 则重建所有的 patches (Reconstruction)。SimMIM 也做了实验:如果目标设置为重建所有的 patches,则性能略有下降。
1.11 ImageNet-1k 实验结果
预训练实验设置:800 epochs,cosine learning rate scheduler,20 epochs linear warm-up。
Fine-tuning 实验设置:200 epochs,layer-wise learning rate decay。
下图6为实验结果,SimMIM 超过了 DINO 和 BEiT,因为和 MAE,iBOT 是2021年11月同时期的工作,所以它们之间没有互相对比性能。

1.12 可视化结果
下图7想研究的是 SimMIM 模型通过预训练 masked image modeling 任务获得了一种什么样的能力。我们看到每一行里面的 mask 分为 Random mask,挡住主要物体的 mask,挡住全部主要物体的 mask。结果显示:
1. 如果使用 Random mask,物体的形状和纹理可以得到重建。但是,unmasked 部分因为模型没有学习这部分的重建,导致最终结果出现了很多的 artifacts。
2. 如果挡住主要物体的 mask,模型仍然能够重建出物体的部分。
3. 如果挡住全部主要物体的 mask,则模型就使用背景去填充。

下图9对比了只重建 masked patches (Prediction),或者重建所有的 patches (Reconstruction) 的结果。每组图片的1是原图,2是 Corrupted image,3是重建所有的 patches 的复原结果,4是只重建 masked patches 的复原结果。显然,4视觉效果更好,说明只重建 masked patches 的效果更好,这个结论是 MAE 没注意到的。

下图10对比了不同大小的 mask patches 的重建结果。注意所有实验 mask ratio=0.6,结果发现当 mask patches 较小时,可以得到更好的重建结果。

总结
SimMIM 是继 BEiT 之后,MSRA 又提出的一个 MIM 任务上的自监督预训练 CV 模型。这个模型更像是 kaiming 的 MAE,也是直接回归预测原始像素 RGB 值,而不是像 BEiT 或者 iBOT 一样重建 tokens。和 MAE 作法一致的地方是:(1) 随机 mask image patches。(2) 直接回归预测原始像素 RGB 值。(3) Decoder (Prediction head) 是轻量的模型。不一样的地方是:MAE 重建所有的 patches,不论是 masked 还是 unmasked,MAE 本质上属于 Reconstruction 的任务;而 SimMIM 实验证明重建所有的 patches 的效果不如只重建 masked patches 的效果,SimMIM 本质上属于 Prediction 的任务。
公众号后台回复“CVPR 2022”获取论文打包合集下载~


# 极市平台签约作者#

科技猛兽
知乎:科技猛兽
清华大学自动化系19级硕士
研究领域:AI边缘计算 (Efficient AI with Tiny Resource):专注模型压缩,搜索,量化,加速,加法网络,以及它们与其他任务的结合,更好地服务于端侧设备。
作品精选
