
阿里菜鸟实时数仓2.0进阶之路
点击上方“数据管道”,选择“置顶星标”公众号
干货福利,第一时间送达

分享嘉宾:张庭 菜鸟 数据工程师
文章整理:comn
出品平台:DataFunTalk
主要内容包括:
相关背景介绍
进口实时数仓演进过程
挑战及实践
总结与展望
1. 进口业务简介
进口业务的流程大致比较清晰,国内的买家下单之后,国外的卖家发货,经过清关,干线运输,到国内的清关,配送,到消费者手里,菜鸟在整个过程中负责协调链路上的各个资源,完成物流履约的服务。去年考拉融入到阿里体系之后,整个进口业务规模占国内进口单量的规模是非常高的。并且每年的单量都在迅速增长,订单履行周期特别长,中间涉及的环节多,所以在数据建设时,既要考虑把所有数据融合到一起,还要保证数据有效性,是非常困难的一件事情。
2. 实时数仓加工流程
① 一般过程
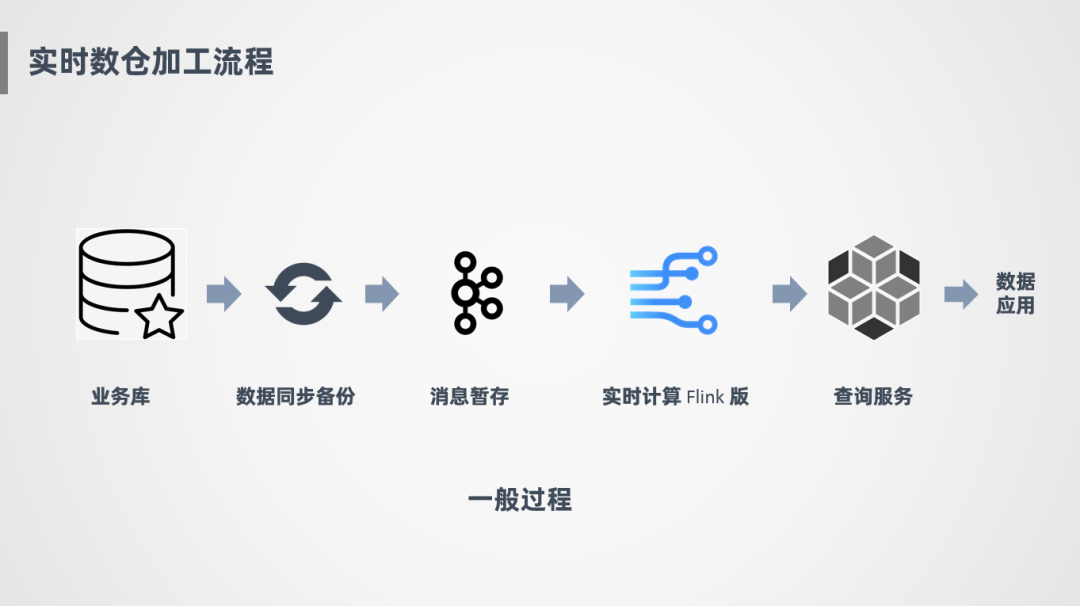
下面简单介绍一下实时数仓的加工流程,一般会对接业务库或者日志源,通过数据同步的方式,比如Sqoop或DataX把消息同步到消息中间件中暂存,下游会接一个实时计算引擎,对消息进行消费,消费之后会进行计算、加工,产出一些明细表或汇总指标,放到查询服务上供数据应用端使用。
② 菜鸟内部流程
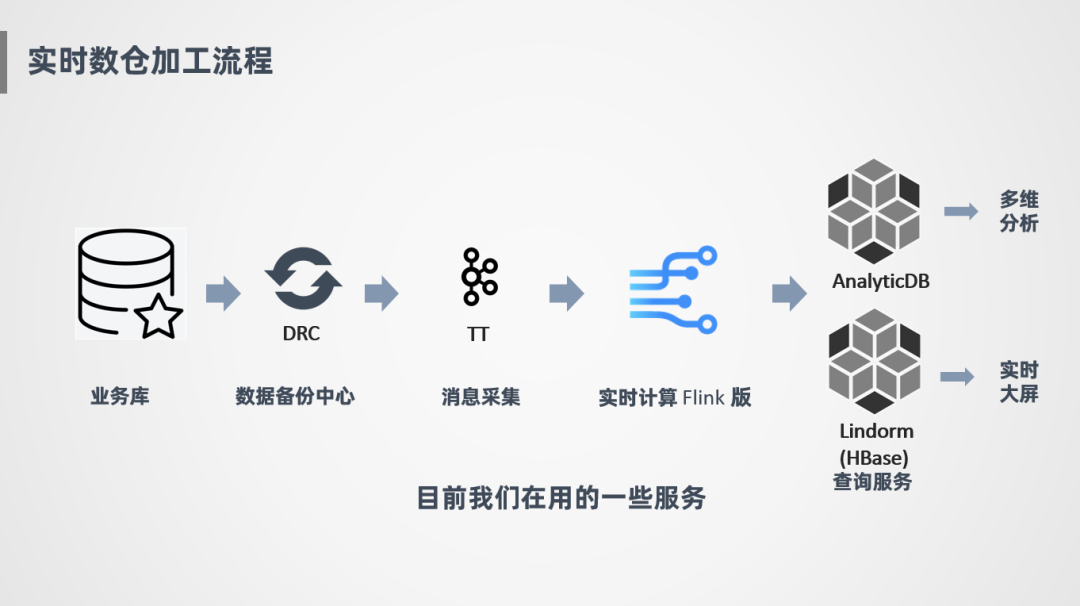
在菜鸟内部也是同样的流程,我们将业务库数据通过DRC ( 数据备份中心 ) 增量采集Binlog日志的方式,同步到TT ( 类似Kafka的消息中间件 ) 做一个消息暂存,后面会接一个Flink实时计算引擎进行消费,计算好之后写入两种查询服务,一种是ADB,一种是HBase ( Lindorm ),ADB是一个OLAP引擎,阿里云对外也提供服务,主要是提供一些丰富的多维分析查询,写入的也是一些维度比较丰富的轻度汇总或明细数据,对于实时大屏的场景,因为维度比较少,指标比较固定,我们会沉淀一些高度汇总指标写到HBase中供实时大屏使用。
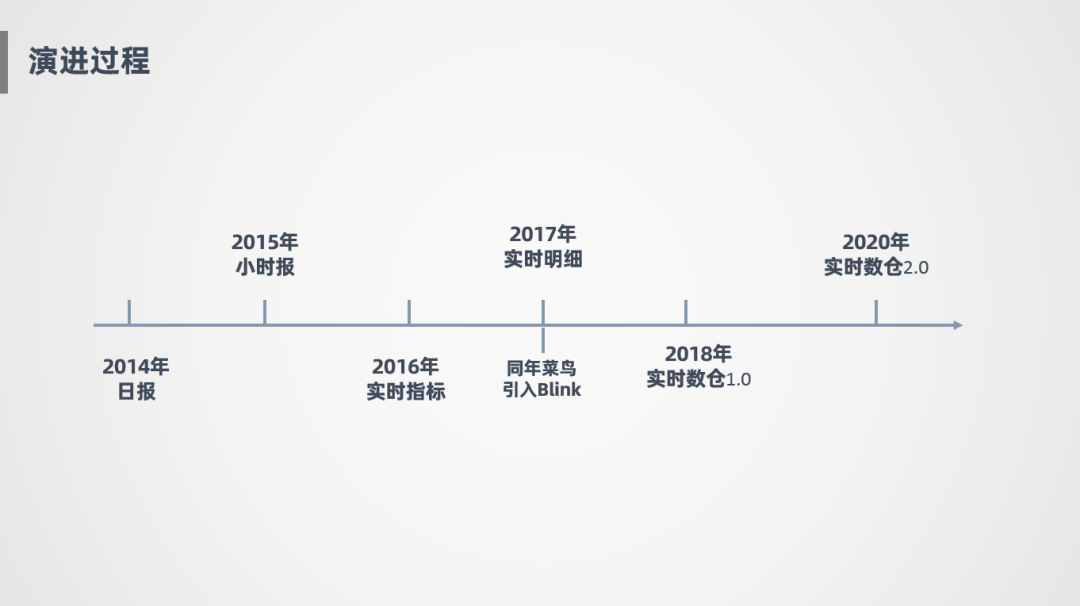
接下来讲一下进口实时数仓的演进过程:
2014年:进口业务线大概在14年时,建好了离线数仓,能提供日报。
2015年:能提供小时报,更新频度从天到小时。
2016年:基于JStorm探索了一些实时指标的计算服务,越来越趋向于实时化。由于16年刚开始尝试实时指标,指标还不是特别丰富。
2017年:菜鸟引进了Blink,也就是Flink在阿里的内部版本,作为我们的流计算引擎,并且进口业务线在同一年打通了实时明细,通过实时明细大宽表对外提供数据服务。
2018年:完成了菜鸟进口实时数仓1.0的建设。
2020年:开始了实时数仓2.0的建设,为什么开始2.0?因为1.0在设计过程中存在了很多问题,整个模型架构不够灵活,扩展性不高,还有一些是因为没有了解Blink的特性,导致误用带来的一些运维成本的增加,所以后面进行了大的升级改造。
1. 实时数仓1.0
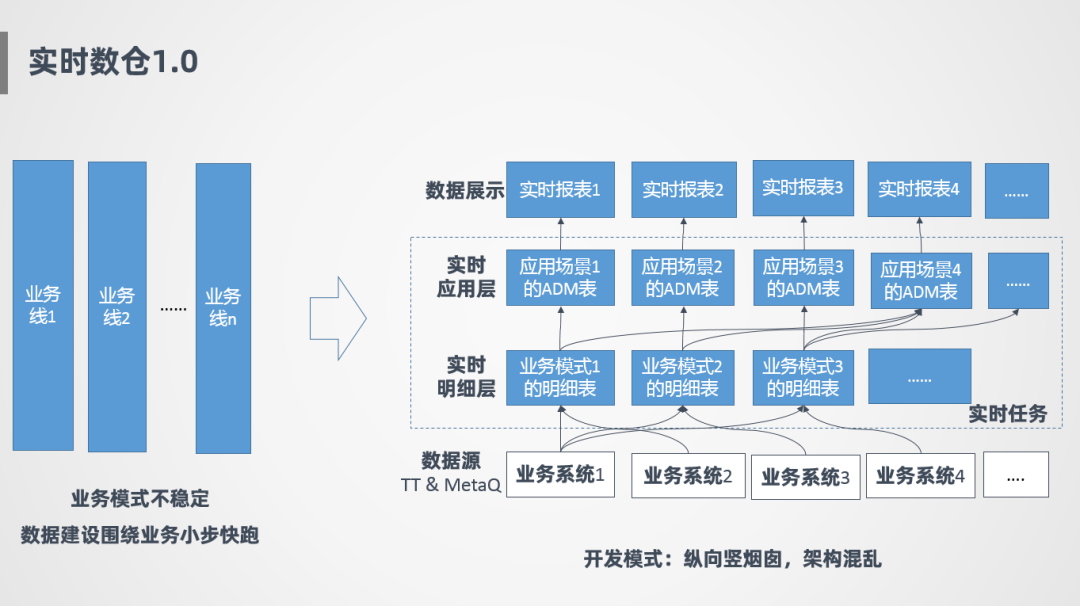
接下来讲一下实时数仓1.0的情况,一开始因为在发展初期,业务模式不太稳定,所以一开始的策略就是围绕业务小步快跑,比如针对业务1会开发一套实时明细层,针对业务2也会开发一套实时任务,好处是可以随着业务发展快速迭代,互相之间不影响,早期会更灵活。
如上图右侧所示,最底层是各个业务系统的消息源,实时任务主要有两层,一层是实时明细层,针对业务线会开发不同的明细表,明细表就是针对该条业务线需要的数据把它抽取过来,在这之上是ADM层,也就是实时应用层,应用层主要针对具体的场景定制,比如有个场景要看整体汇总指标,则从各个明细表抽取数据,产生一张实时汇总层表,整个过程是竖向烟囱式开发,模型比较混乱,难扩展,并且存在很多重复计算。
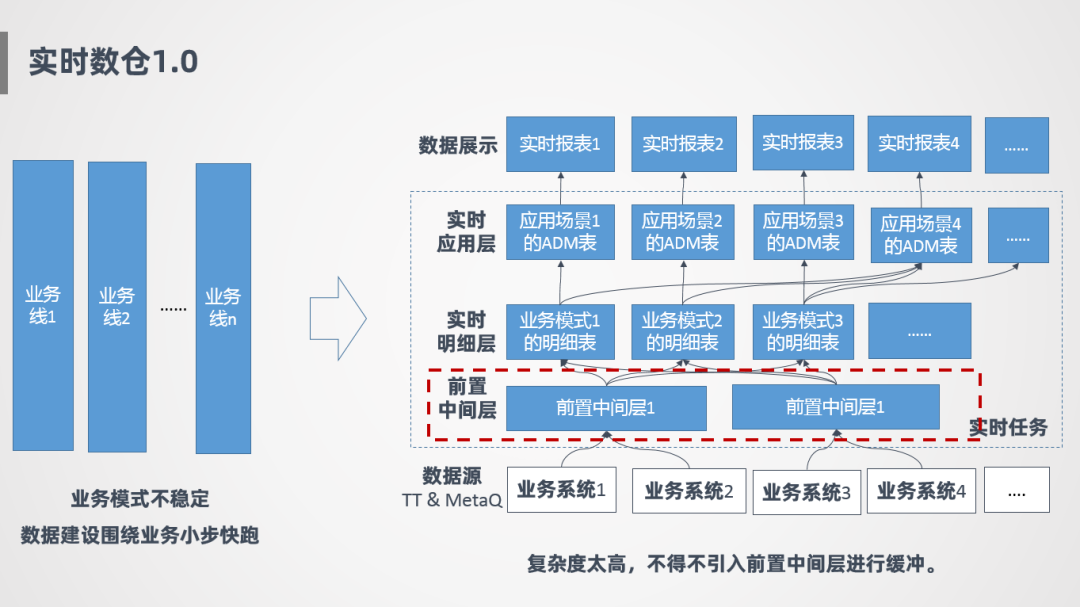
后面也是由于重复计算的问题,进行了一层抽象,加了一个前置中间层,对公共的部分进行提取,但是治标不治本,整个模型还是比较混乱的,数据建设上也没有进行统一,模型扩展性上也很差。
2. 实时数仓2.0

2.0升级完之后是比较清晰的一张图:
前置层:底层数据源会接入到前置中间层,屏蔽掉底层一些非常复杂的逻辑。
明细层:前置层会把比较干净的数据给到明细表,明细层打通了各个业务线,进行了模型的统一。
汇总层:明细层之上会有轻度汇总和高度汇总,轻度汇总表维度非常多,主要写入到OLAP引擎中供多维查询分析,高度汇总指标主要针对实时大屏场景进行沉淀。
接口服务:汇总层之上会根据统一的接口服务对外提供数据输出。
数据应用:应用层主要接入包括实时大屏,数据应用,实时报表以及消息推送等。
这就是实时数仓2.0升级之后的模型,整个模型虽然看起来比较简单,其实背后从模型设计到开发落地,遇到了很多困难,花费了很大的精力。下面为大家分享下我们在升级过程中遇到的挑战及实践。
我们在实时数仓升级的过程中,面临的挑战如下:

1. 业务线和业务模式多

第一个就是对接的业务线比较多,不同的业务线有不同的模式,导致一开始小步快跑方式的模型比较割裂,模型和模型之间没有复用性,开发和运维成本都很高,资源消耗严重。
解决方案:逻辑中间层升级
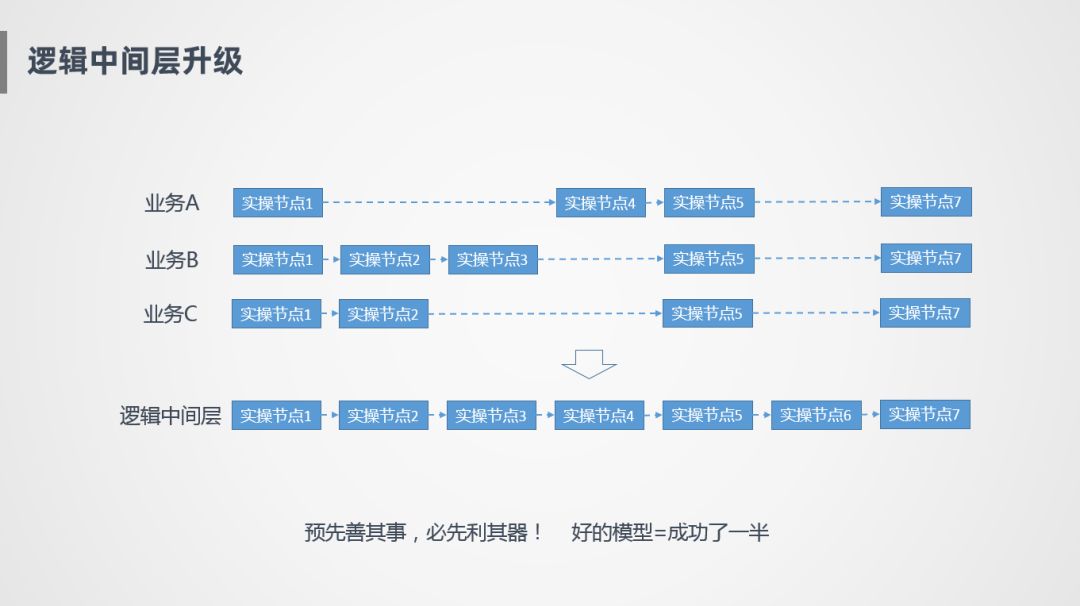
我们想到的比较简单的思路就是建设统一的数据中间层,比如业务A有出库、揽收、派送等几个业务节点,业务B可能是另外几个节点,整个模型是割裂的状态,但实际上业务发展到中后期比较稳定的时候,各个业务模式之间相对比较稳定,这个时候可以对数据进行一个抽象,比如业务A有节点1、节点5和其他几个业务模式是一样的,通过这种对齐的方式,找出哪些是公共的,哪些是非公共的,提取出来沉淀到逻辑中间层里,从而屏蔽各业务之间的差距,完成统一的数据建设。把逻辑中间层进行统一,还有一个很大的原因,业务A,B,C虽然是不同的业务系统,比如履行系统,关务系统,但是本质上都是同一套,底层数据源也是进行各种抽象,所以数仓建模上也要通过统一的思路进行建设。
2. 业务系统多,超大数据源

第二个就是对接的系统非常多,每个系统数据量很大,每天亿级别的数据源就有十几个,梳理起来非常困难。带来的问题也比较明显,第一个问题就是大状态的问题,需要在Flink里维护特别大的状态,还有就是接入这么多数据源之后,成本怎么控制。
解决方案:善用State
State是Flink的一大特性,因为它才能保证状态计算,需要更合理的利用。我们要认清State是干什么的,什么时候需要State,如何优化它,这些都是需要考虑的事情。State有两种,一种是KeyedState,具体是跟数据的Key相关的,例如SQL中的Group By,Flink会按照键值进行相关数据的存储,比如存储到二进制的一个数组里。第二个是OperatorState,跟具体的算子相关,比如用来记录Source Connector里读取的Offset,或者算子之间任务Failover之后,状态怎么在不同算子之间进行恢复。
① 数据接入时"去重"
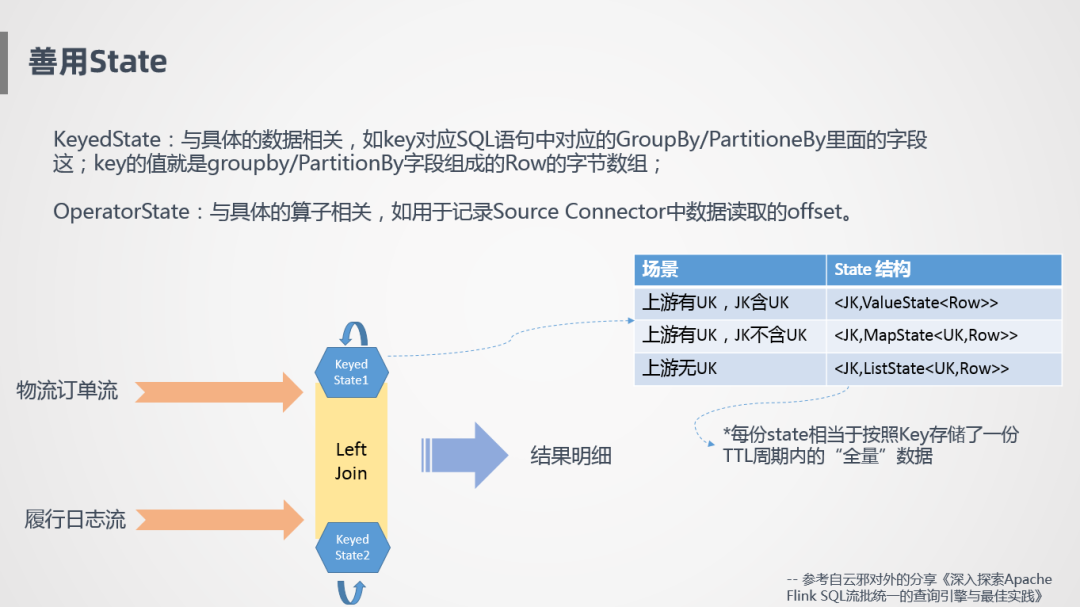
下面举个例子,怎么用到KeyedState,比如物流订单流和履行日志流,两个作业关联产生出最终需要的一张大表,Join是怎么存储的呢?流是一直不停的过来的,消息到达的前后顺序可能不一致,需要把它存在算子里面,对于Join的状态节点,比较简单粗暴的方式是把左流和右流同时存下来,通过这样的方式保证不管消息是先到还是后到,至少保证算子里面数据是全的,哪怕其中一个流很晚才到达,也能保证匹配到之前的数据,需要注意的一点是,State存储根据上游不同而不同,比如在上游定义了一个主键Rowkey,并且JoinKey包含了主键,就不存在多笔订单对应同一个外键,这样就告诉State只需要按照JoinKey存储唯一行就可以了。如果上游有主键,但是JoinKey不包含Rowkey 的话,就需要在State里将两个Rowkey的订单同时存下来。最差的情况是,上游没有主键,比如同一笔订单有10条消息,会有先后顺序,最后一条是有效的,但是对于系统来说不知道哪条是有效的,没有指定主键也不好去重,它就会全部存下来,特别耗资源和性能,相对来说是特别差的一种方式。
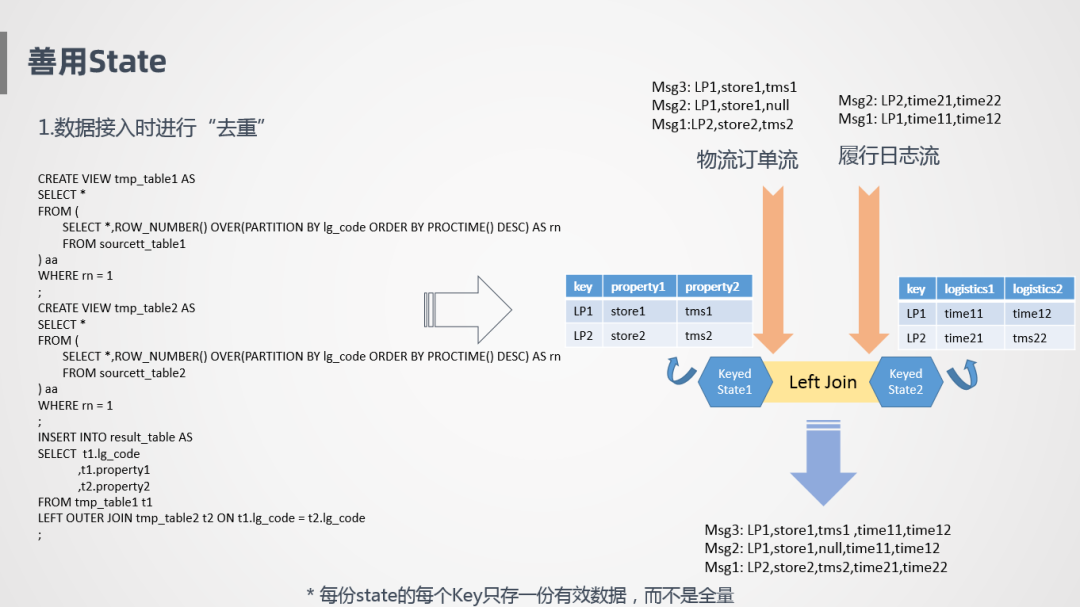
因此,我们在数据接入时进行"去重"。数据接入时,按照row_number进行排序,告诉系统按照主键进行数据更新就可以了,解决10条消息不知道应该存几条的问题。在上面这个case里面,就是按照主键进行更新,每次取最后一条消息。
按照row_number这种方式并不会减少数据处理量,但是会大大减少State存储量,每一个State只存一份有效的状态,而不是把它所有的历史数据都记录下来。
② 多流join优化
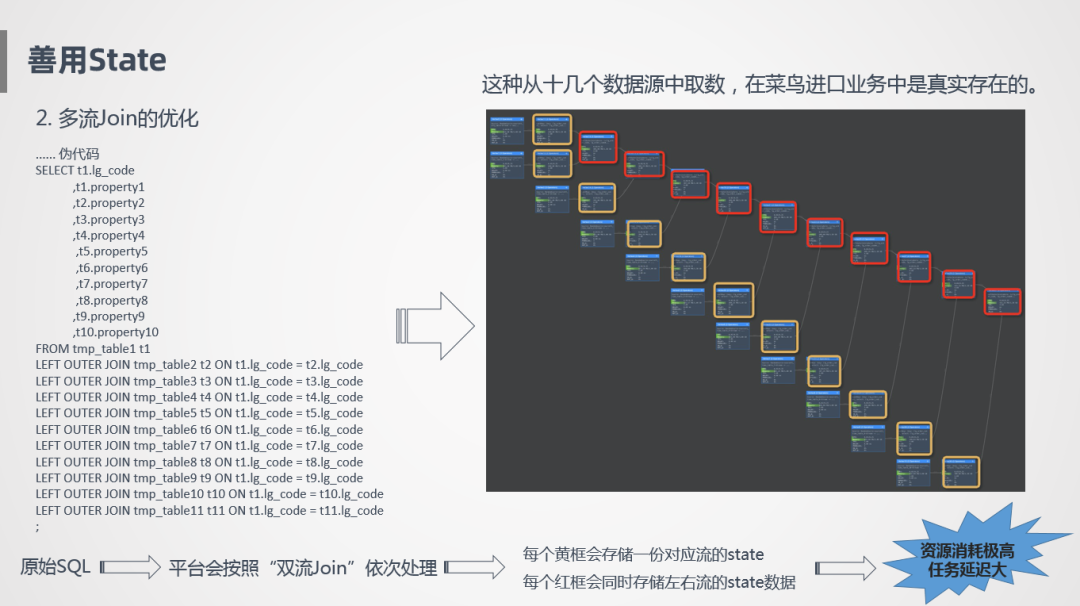
第二个是多流Join的优化,比如像上图左侧的伪代码,一张主表关联很多数据源产生一个明细大宽表,这是我们喜欢的方式,但是这样并不好,为什么呢?这样一个SQL在实时计算里会按照双流Join的方式依次处理,每次只能处理一个Join,所以像左边这个代码里有10个Join,在右边就会有10个Join节点,Join节点会同时将左流和右流的数据全部存下来,所以会看到右边这个图的红框里,每一个Join节点会同时存储左流和右流的节点,假设我们订单源有1亿,里面存的就是10亿,这个数据量存储是非常可怕的。
另外一个就是链路特别长,不停的要进行网络传输,计算,任务延迟也是很大的。像十几个数据源取数关联在一起,在我们的实际场景是真实存在的,而且我们的关联关系比这个还要更复杂。
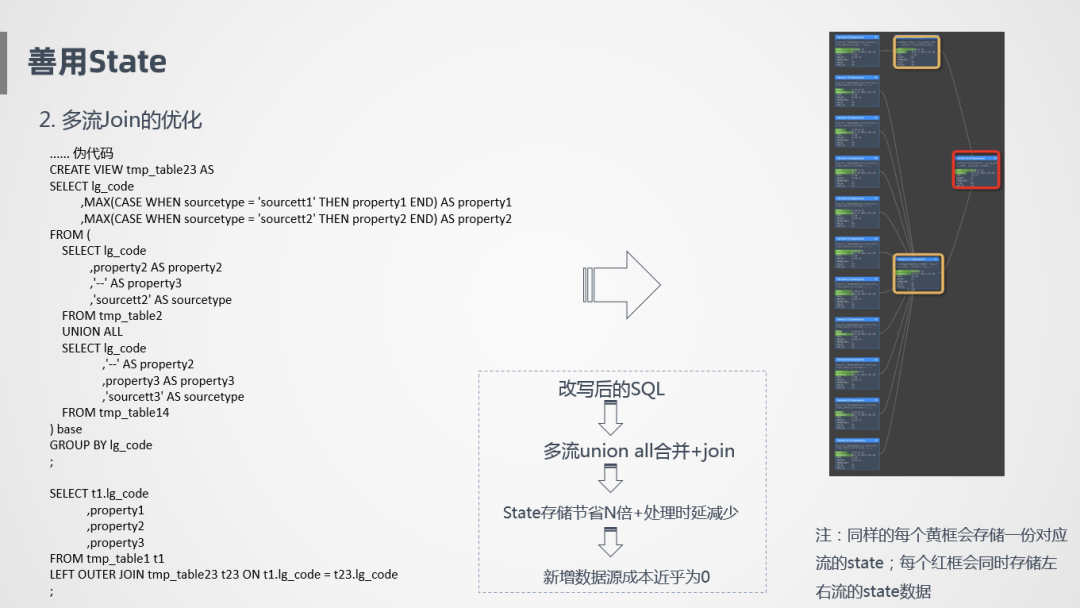
那我们怎么优化呢?我们采用Union All的方式,把数据错位拼接到一起,后面加一层Group By,相当于将Join关联转换成Group By,它的执行图就像上图右侧这样,黄色是数据接入过程中需要进行的存储,红色是一个Join节点,所以整个过程需要存储的State是非常少的,主表会在黄色框和红色框分别存一份,别看数据源非常多,其实只会存一份数据,比如我们的物流订单是1000万,其他数据源也是1000万,最终的结果有效行就是1000万,数据存储量其实是不高的,假设又新接了数据源,可能又是1000万的日志量,但其实有效记录就是1000万,只是增加了一个数据源,进行了一个数据更新,新增数据源成本近乎为0,所以用Union All替换Join的方式在State里是一个大大的优化。
3. 取数外键多,易乱序

第三个是取数外键多,乱序的问题,乱序其实有很多种,采集系统采集过来就是乱序的,或者传输过程中导致的乱序,我们这边要讨论的是,在实际开发过程中不小心导致的乱序,因为其他层面的东西平台已经帮我们考虑好了,提供了很好的端到端的一致性保证。
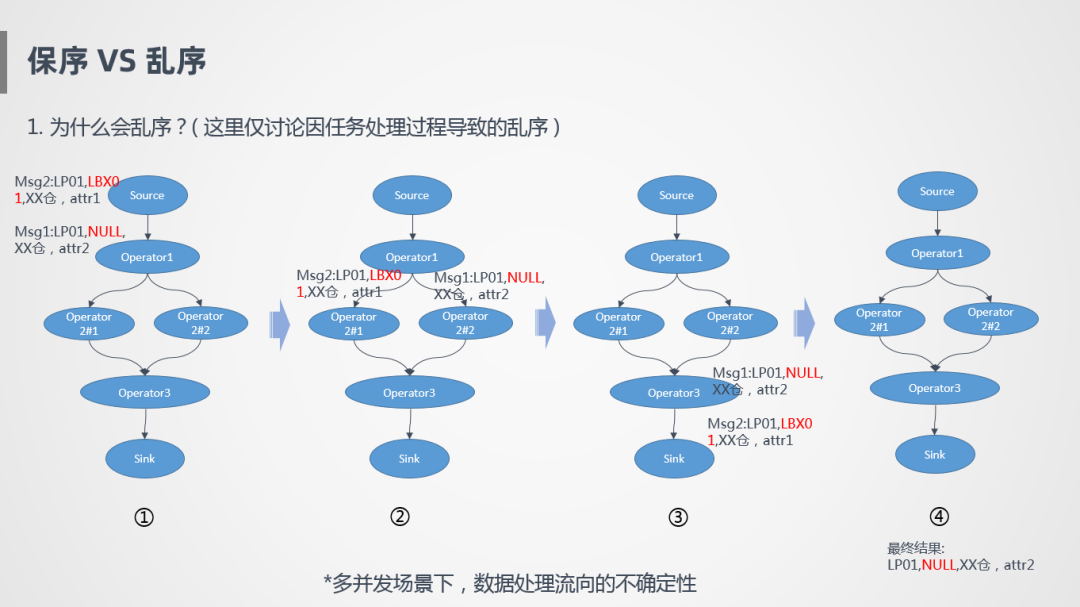
举个例子比如说有两个单子都是物流单,根据单号取一些仓内的消息,消息1和消息2先后进入流处理里面,关联的时候根据JoinKey进行Shuffle,在这种情况下,两个消息会流到不同的算子并发上,如果这两个并发处理速度不一致,就有可能导致先进入系统的消息后完成处理,比如消息1先到达系统的,但是处理比较慢,消息2反倒先产出,导致最终的输出结果是不对的,本质上是多并发场景下,数据处理流向的不确定性,同一笔订单的多笔消息流到不同的地方进行计算,就可能会导致乱序。
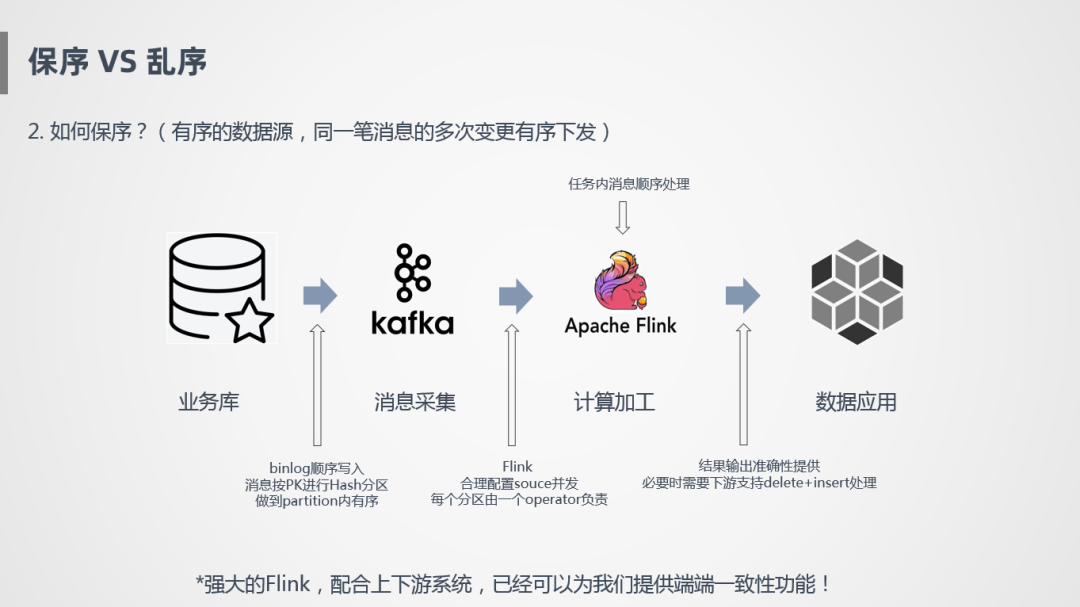
所以,同一笔订单消息处理完之后,如何保证是有序的?
上图是一个简化的过程,业务库流入到Kafka,Binlog日志是顺序写入的,需要采用一定的策略,也是顺序采集,可以根据主键进行Hash分区,写到Kafka里面,保证Kafka里面每个分区存的数据是同一个Key,首先在这个层面保证有序。然后Flink消费Kafka时,需要设置合理的并发,保证一个分区的数据由一个Operator负责,如果一个分区由两个Operator负责,就会存在类似于刚才的情况,导致消息乱序。另外还要配合下游的应用,能保证按照某些主键进行更新或删除操作,这样才能保证端到端的一致性。
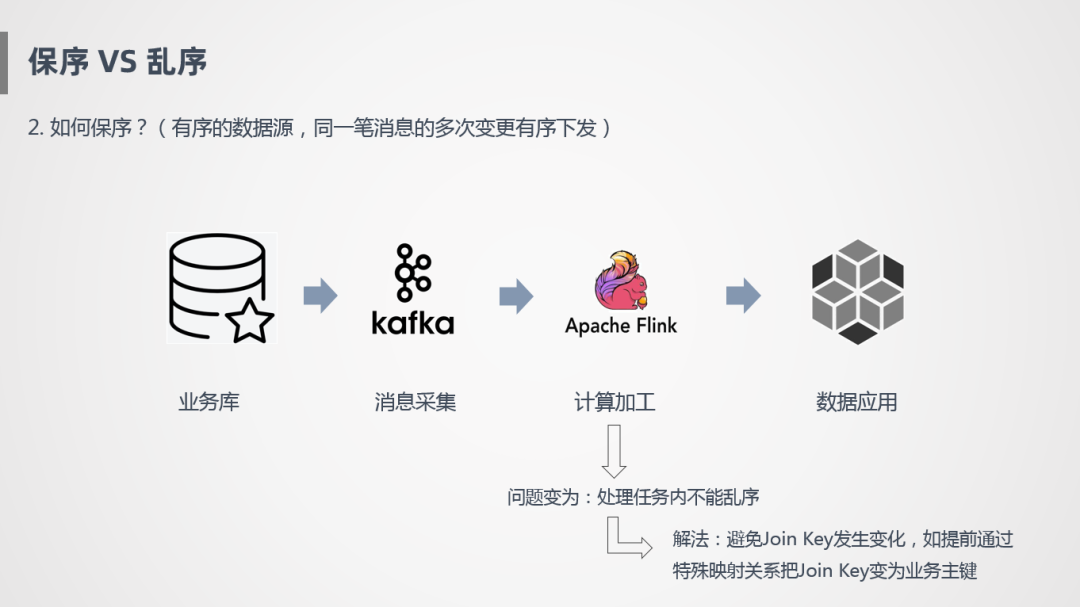
Flink已经配合上下游系统已经帮我们实现了端到端的一致性功能,我们只需要保证内部处理任务不能乱序。我们的解法是避免Join Key发生变化,如提前通过特殊映射关系把Join Key变为业务主键,来保证任务处理是有序的。
4. 统计指标依赖明细,服务压力大

另外一个难点就是我们的很多统计指标都依赖明细,主要是一些实时统计,这种风险比较明显,服务端压力特别大,尤其是大促时,极其容易把系统拖垮。
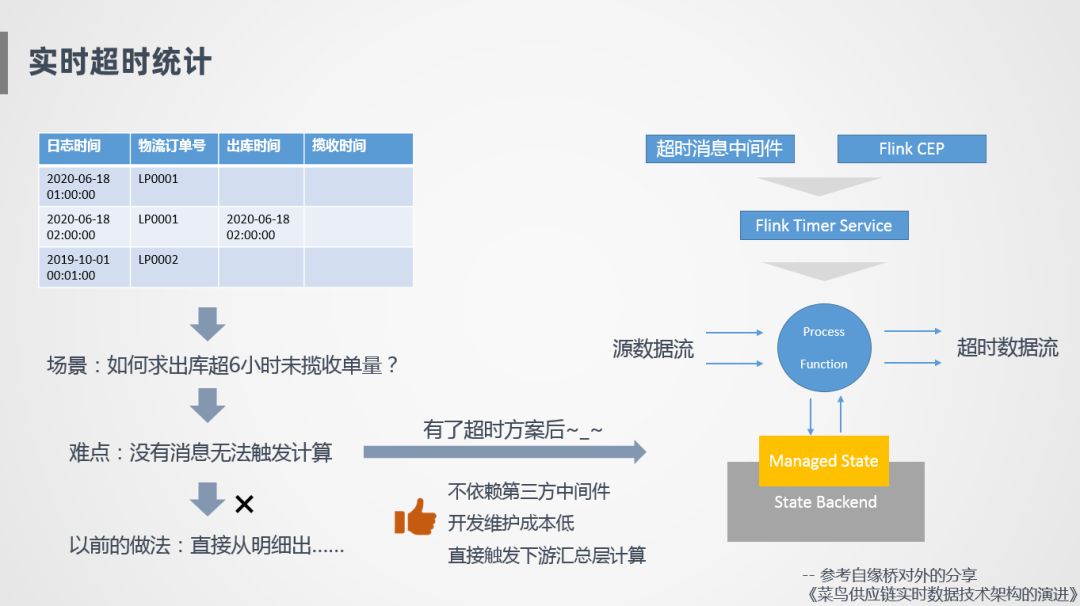
实时超时统计就是一个典型的场景,比如说会有这样两笔订单,一笔订单1点钟创建了物流订单,2点钟进行出库,如何统计超6小时未揽收的收单量,因为没有消息就无法触发计算,Flink是基于消息触发的,比如说2点钟出库了,那理论上在8点钟的时候超6小时未揽收的单量要加1,但是因为没有消息触发,下游系统不会触发计算,这是比较难的事情,所以一开始没有特别好的方案,我们直接从明细表出,比如订单的出库时间是2点钟,生成这条明细之后,写到数据库的OLAP引擎里,和当前明细进行比较计算。
我们也探索了一些方案比如基于消息中间件,进行一些定时超时消息下发,或者也探索过基于Flink CEP的方式,第一种方式需要引入第三方的中间件,维护成本会更高,CEP这种方式采用时间窗口稳步向前走,像我们这种物流场景下会存在很多这样的情况,比如回传一个2点出库的时间,后面发现回传错了,又会补一个1点半的时间,那么我们需要重新触发计算,Flink CEP是不能很好的支持的。后面我们探索了基于Flink Timer Service这种方式,基于Flink自带的Timer Service回调方法,来制造一个消息流,首先在我们的方法里面接入数据流,根据我们定义的一些规则,比如出库时间是2点,会定义6小时的一个超时时间,注册到Timer Service里面,到8点会触发一次比较计算,没有的话就会触发一个超时消息,整个方案不依赖第三方组件,开发成本比较低。
5. 履行环节多,数据链路长

另外一个难点就是我们的履行环节比较多,数据链路比较长,导致异常情况很难处理。比如消息要保留20多天的有效期,State也要存20多天,状态一直存在Flink里面,如果某一天数据出现错误或者逻辑加工错误,追溯是个很大问题,因为上游的消息系统一般保持三天数据的有效期。

这边说几个真实的案例。
案例1:
我们在双十一期间发现了一个Bug,双十一已经过去好几天了,因为我们的履行链路特别长,要10~20天,第一时间发现错误要改已经改不了了,改了之后DAG执行图会发生变化,状态就无法恢复,而且上游只能追3天的数,改了之后相当于上游的数全没了,这是不能接受的。
案例2:
疫情期间的一些超长尾单,State的TTL设置都是60天,我们认为60天左右肯定能够全部完结,后来发现超过24天数据开始失真,明明设置的有效期是60天,后来发现底层State存储用的是int型,所以最多只能存20多天的有效期,相当于触发了Flink的一个边界case,所以也证明了我们这边的场景的确很复杂,很多状态需要超长的State生命周期来保证的。
案例3:
每次代码停止升级之后,状态就丢失了,需要重新拉取数据计算,但是一般上游的数据只保留3天有效期,这样的话业务只能看3天的数据,用户体验很不好。
解决方案:批流混合
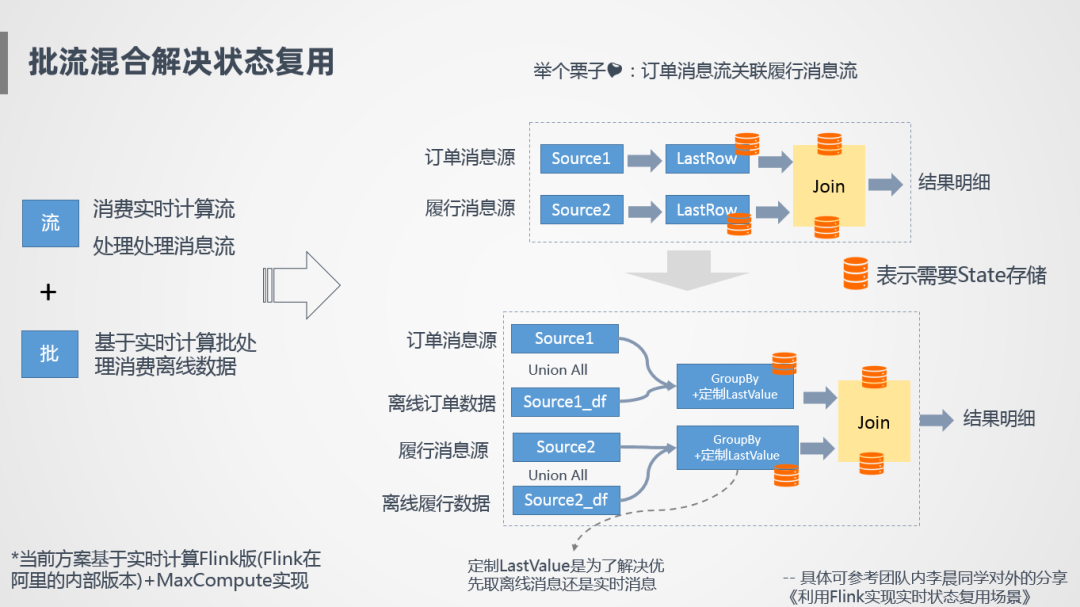
我们怎么做?
采用批流混合的方式来完成状态复用,基于Blink流处理来处理实时消息流,基于Blink的批处理完成离线计算,通过两者的融合,在同一个任务里完成历史所有数据的计算,举个例子,订单消息流和履行消息流进行一个关联计算,那么会在任务里增加一个离线订单消息源,跟我们的实时订单消息源Union All合并在一起,下面再增加一个Group By节点,按照主键进行去重,基于这种方式就可以实现状态复用。有几个需要注意的点,第一个需要自定义Source Connector去开发,另外一个涉及到离线消息和实时消息合并的一个问题,GroupBy之后是优先取离线消息还是实时消息,实时消息可能消费的比较慢,哪个消息是真实有效的需要判断一下,所以我们也定制了一些,比如LastValue来解决任务是优先取离线消息还是实时消息,整个过程是基于Blink和MaxCompute来实现的。
6. 一些小的Tips
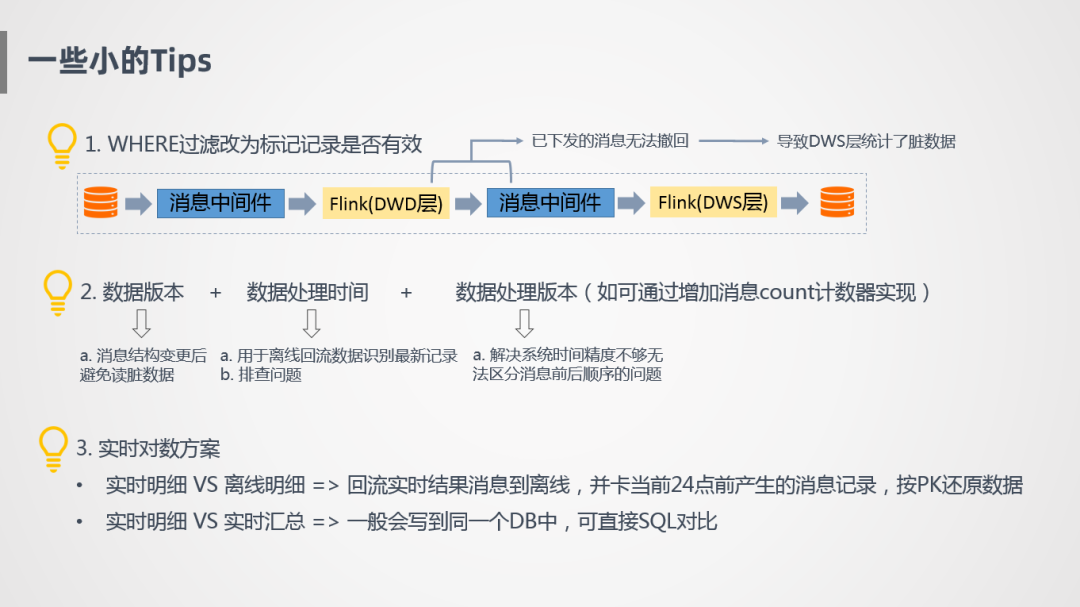
① 消息下发无法撤回问题
第一个就是消息一旦下发无法撤回,所以有些订单一开始有效,后面变成无效了,这种订单不应该在任务中过滤,而是打上标记下传,统计的时候再用。
② 增加数据版本,数据处理时间以及数据处理版本
数据版本是消息结构体的版本定义,避免模型升级后,任务重启读到脏数据。
处理时间就是消息当前的处理时间,比如消息回流到离线,我们会按照主键进行时间排序,取到最新记录,通过这种方式还原一份准实时数据。
增加数据处理版本是因为即使到毫秒级也不够精确,无法区分消息的前后顺序。
③ 实时对数方案
实时对数方案有两个层面,实时明细和离线明细,刚刚也提到将实时数据回流到离线,我们可以看当前24点前产生的消息,因为离线T+1只能看到昨天23点59分59秒的数据,实时也可以模拟,我们只截取那个时刻的数据还原出来,然后实时和离线进行对比,这样也可以很好的进行数据比对,另外可以进行实时明细和实时汇总对比,因为都在同一个DB里,对比起来也特别方便。
1. 总结

简单做下总结:
模型与架构:好的模型和架构相当于成功了80%。
准确性要求评估:需要评估数据准确性要求,是否真的需要对齐CheckPoint或者一致性的语义保证,有些情况下保证一般准确性就ok了,那么就不需要这么多额外消耗资源的设计。
合理利用Flink特性:需要合理利用Fink的一些特性,避免一些误用之痛,比如State和CheckPoint的使用。
代码自查:保证数据处理是正常流转的,合乎目标。
SQL理解:写SQL并不是有多高大上,更多考验的是在数据流转过程中的一些思考。
2. 展望
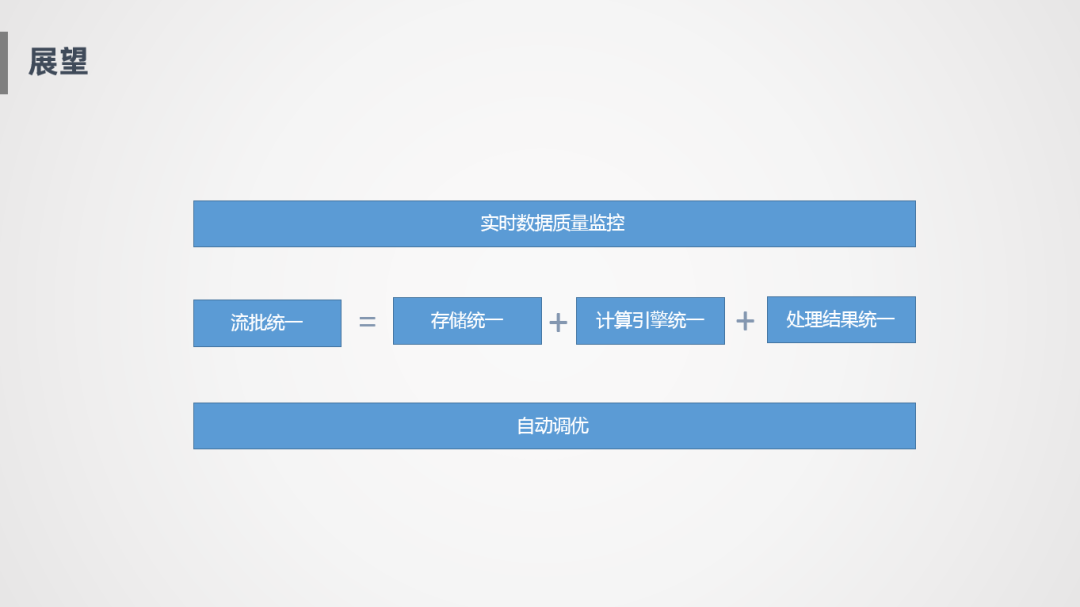
① 实时数据质量监控
实时处理不像批处理,批处理跑完之后可以在跑个小脚本统计一下主键是否唯一,记录数波动等,实时的数据监控是比较麻烦的事情·。
② 流批统一
流批统一有几个层面,第一个就是存储层面的统一,实时和离线写到同一个地方去,应用的时候更方便。第二个就是计算引擎的统一,比如像Flink可以同时支持批处理和流处理,还能够写到Hive里面。更高层次的就是可以做到处理结果的统一,同一段代码,在批和流的语义可能会不一样,如何做到同一段代码,批和流的处理结果是完全统一的。
③ 自动调优
自动调优有两种,比如在大促的时候,我们申请了1000个Core的资源,1000个Core怎么合理的分配,哪些地方可能是性能瓶颈,要多分配一些,这是给定资源的自动调优。还有一种比如像凌晨没什么单量,也没什么数据流量,这个时候可以把资源调到很小,根据数据流量情况自动调整,也就是自动伸缩能力。
以上是我们整体对未来的展望和研究方向。
张庭
菜鸟 | 数据工程师