
React 是如何创建 vdom 和 fiber tree

-
作者:linxiangjun -
原文链接:https://www.linxiangjun.com/react-render-source.html#JSX
前言
本篇文章作为react源码分析与优化写作计划的第一篇,分析了react是如何创建vdom和fiber tree的。本篇文章通过阅读react 16.8及以上版本源码以及参考大量分析文章写作而成,react框架本身算法以及架构层也是不断的在优化,所以源码中存在很多legacy的方法,不过这并不影响我们对于react设计思想的学习和理解。
阅读源码一定要带着目的性的去展开,这样就会减少过程中的枯燥感,而写作能够提炼和升华自己的学习和理解,这也是本篇以及后续文章的动力所在。如果写作的文章还能够帮助到其他开发者,那就更好了。
JSX
首先,来看一个简单的 React 组件。
import React from 'react';
export default function App() {
return (
<div className="App">
<h1>Hello Reacth1>
div>
);
}
上面常用的语法称之为 JSX,是 React.createElement 方法的语法糖,使用 JSX 能够直观的展现 UI 及其交互,实现关注点分离。
每个 react 组件的顶部都要导入 React,因为 JSX 实际上依赖 Babel(@babel/preset-react)来对语法进行转换,最终生成React.createElemnt的嵌套语法。
下方能够直观的看到 JSX 转换后的渲染结果。
function App() {
return React.createElement(
'div',
{
className: 'App',
},
React.createElement('h1', null, 'Hello React')
);
}
createElement
createElement()方法定义如下:
React.createElement(type, [props], [...children]);
createElement()接收三个参数,分别是元素类型、属性值以及子元素,它最终会生成 Virtual DOM。
我们将上面的
组件内容打印到控制台中。
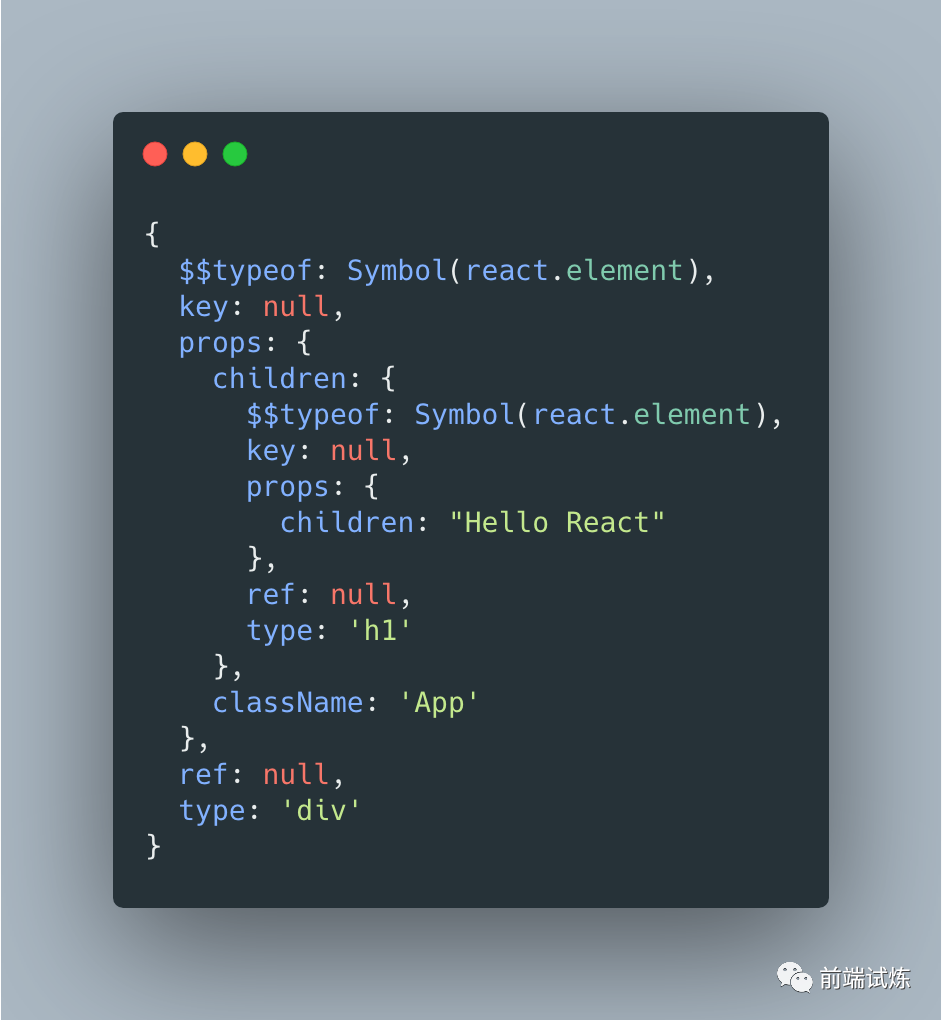
可以看到 Virtual DOM 本质上是 JS 对象,将节点信息通过键值对的方式存储起来,同时使用嵌套来表示节点间的层级关系。使用 VDOM 能够避免频繁的进行 DOM 操作,同时也为后面的 React Diff 算法创造了条件。现在回到createElement()方法,来看一下它究竟是如何生产 VDOM 的。
createElement()方法精简版(v16.8)
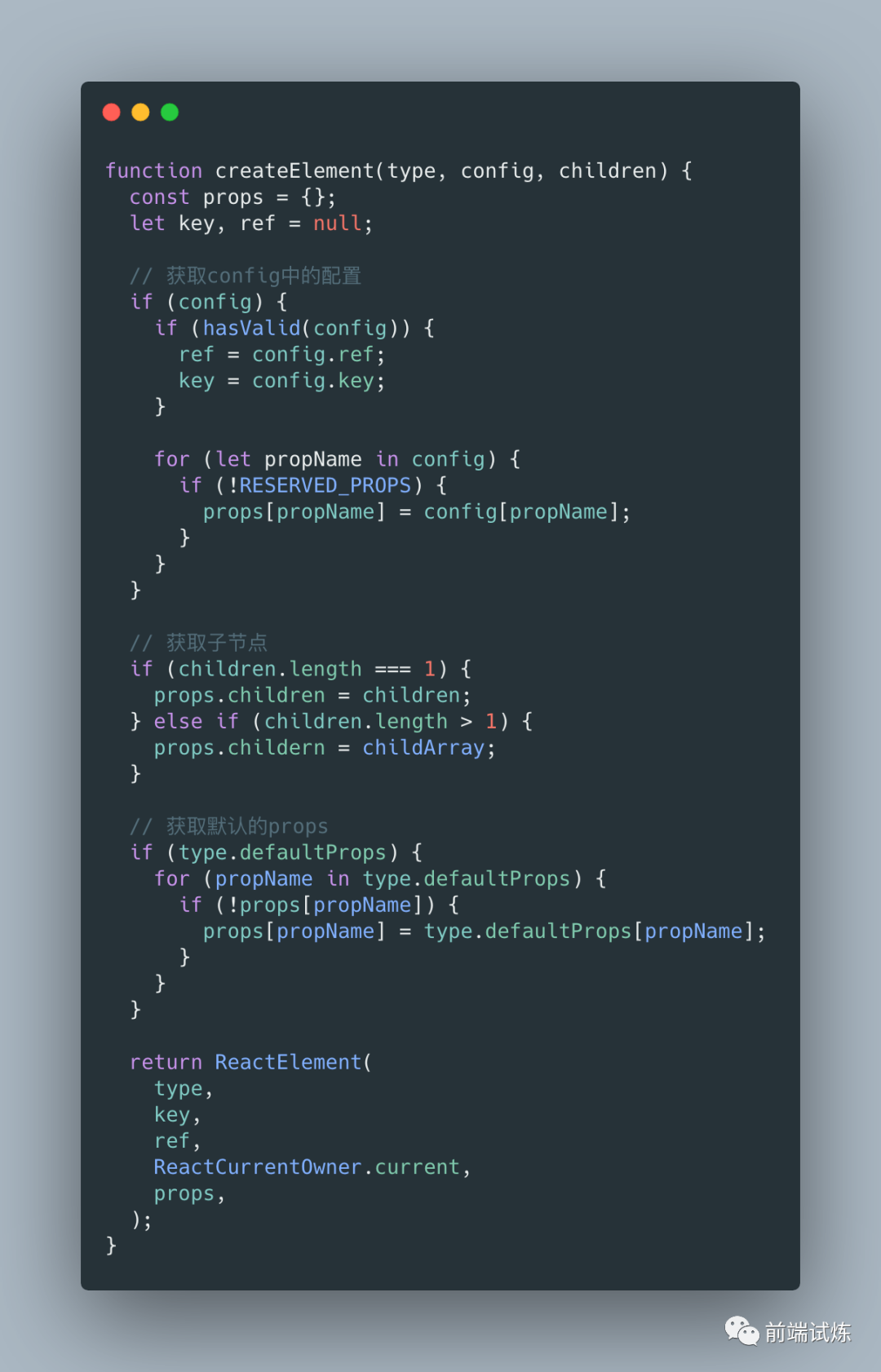
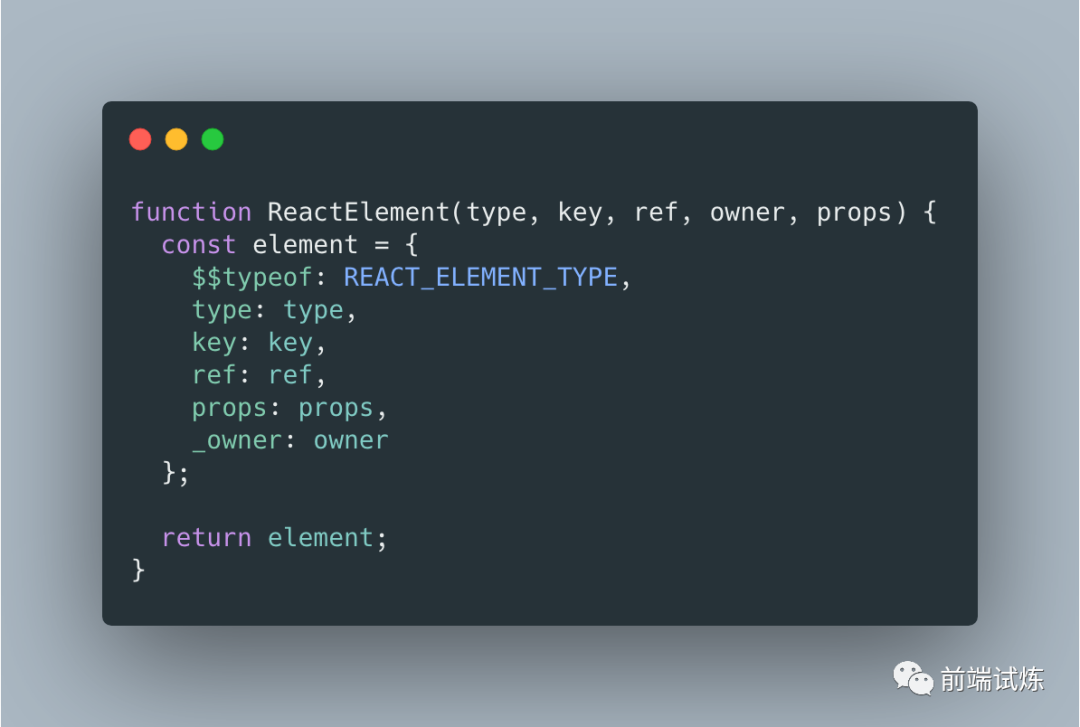
首先,createElement()方法会先通过遍历config获取所有的参数,然后获取其子节点以及默认的props的值。然后将值传递给ReactElement()调用并返回 JS 对象。
值得注意的是,每个 react 组件都会使用$$typeof来标识,它的值使用了Symbol数据结构来确保唯一性。
ReactDOM.render
到目前为止,我们得到了 VDOM,react通过协调算法(reconciliation)去比较更新前后的VDOM,从而找到需要更新的最小操作,减少了浏览器多次操作DOM的成本。但是,由于使用递归的方式来遍历组件树,当组件树越来越大,递归遍历的成本就越高。这样,由于持续占用主线程,像布局、动画等任务无法立即得到处理,就会出现丢帧的现象。所以,为不同类型的任务赋予优先级,同时支持任务的暂停、中止与恢复,是非常有必要的。
为了解决上面存在的问题,React团队给出了React Fiber算法以及fiber tree数据结构(基于单链表的树结构),而ReactDOM.render方法就是实现React Fiber算法以及构建fiber tree的核心API。
render()方法定义如下:
ReactDOM.render(element, container[, callback])
这里重点从源码层面讲解下ReactDOM.render是如何构建fiber tree的。
ReactDOM.render实际调用了legacyRenderSubtreeIntoContainer方法,调用过程以及传参如下:
ReactDOM = {
render(element, container, callback) {
return legacyRenderSubtreeIntoContainer(
null,
element,
container,
false,
callback
);
},
};
其中的element和container我们都很熟悉了,而callback是用来渲染完成后需要执行的回调函数。再来看看该方法的定义。
function legacyRenderSubtreeIntoContainer(
parentComponent,
children,
container,
forceHydrate,
callback
) {
let root = container._reactRootContainer;
let fiberRoot;
// 初次渲染
if (!root) {
// 初始化挂载,获得React根容器对象
root = container._reactRootContainer = legacyCreateRootFromDOMContainer(
container,
forceHydrate
);
fiberRoot = root._internalRoot;
// 初始化安装不需要批量更新,需要尽快完成
unbatchedUpdates(() => {
updateContainer(children, fiberRoot, parentComponent, callback);
});
} else {
fiberRoot = root._internalRoot;
updateContainer(children, fiberRoot, parentComponent, callback);
}
return getPublicRootInstance(fiberRoot);
}
上面是简化后的源码。先来看传参,因为是挂载root,所以parentComponent设置为null。另外一个参数forceHydrate代表是否是服务端渲染,因为调用的render()方法为客服端渲染,所以默认为false。另外callback使用少,所以关于它的处理过程就省略了。
因为是首次挂载,所以root从container._reactRootContainer获取不到值,就会创建FiberRoot对象。在FiberRoot对象创建过程中考虑到了服务端渲染的情况,并且函数之间相互调用非常多,所以这里直接展示其最终调用的核心方法。
// 创建fiberRoot和rootFiber并相互引用
function createFiberRoot(containerInfo, tag, hydrate, hydrationCallbacks) {
const root = new FiberRootNode(containerInfo, tag, hydrate);
if (enableSuspenseCallback) {
root.hydrationCallbacks = hydrationCallbacks;
}
// 创建fiber tree的根节点,即rootFiber
const uninitializedFiber = createHostRootFiber(tag);
root.current = uninitializedFiber;
uninitializedFiber.stateNode = root;
initializeUpdateQueue(uninitializedFiber);
return root;
}
在该方法中containerInfo就是root节点,而tag为FiberRoot节点的标记,这里为LegacyRoot。另外两个参数和服务端渲染有关。这里使用FiberRootNode方法创建了FiberRoot对象,并使用createHostRootFiber方法创建RootFiber对象,使FiberRoot中的current指向RootFiber,RootFiber的stateNode指向FiberRoot,形成相互引用。
下面的两个构造函数是展现出了fiberRoot以及rootFiber的部分重要的属性。
FiberRootNode部分属性:
function FiberRootNode(containerInfo, tag, hydrate) {
// 用于标记fiberRoot的类型
this.tag = tag;
// 指向当前激活的与之对应的rootFiber节点
this.current = null;
// 和fiberRoot关联的DOM容器的相关信息
this.containerInfo = containerInfo;
// 当前的fiberRoot是否处于hydrate模式
this.hydrate = hydrate;
// 每个fiberRoot实例上都只会维护一个任务,该任务保存在callbackNode属性中
this.callbackNode = null;
// 当前任务的优先级
this.callbackPriority = NoPriority;
}
Fiber Node构造函数的部分属性:
function FiberNode(tag, pendingProps, key, mode) {
// rootFiber指向fiberRoot,child fiber指向对应的组件实例
this.stateNode = null;
// return属性始终指向父节点
this.return = null;
// child属性始终指向第一个子节点
this.child = null;
// sibling属性始终指向第一个兄弟节点
this.sibling = null;
// 表示更新队列,例如在常见的setState操作中,会将需要更新的数据存放到updateQueue队列中用于后续调度
this.updateQueue = null;
// 表示当前更新任务的过期时间,即在该时间之后更新任务将会被完成
this.expirationTime = NoWork;
}
最终生成的fiber tree结构示意图如下:

React Diff 算法
react 并不会比原生操作 DOM 快,但是在大型应用中,往往不需要每次全部重新渲染,这时 react 通过 VDOM 以及 diff 算法能够只更新必要的 DOM。react 将 VDOM 与 diff 算法结合起来并对其进行优化,提供了高性能的 React Diff 算法,通过一系列的策略,将传统的 diff 算法复杂度 O(n^3)优化为 O(n)的复杂度,极大的提升了渲染性能。
这里不展开探究 React Diff 的具体实现原理,而先了解下它到底的基于什么策略来实现的。
-
Web UI 中 DOM 节点跨层级的移动操作特别少,可以忽略不计。 -
拥有相同类的两个组件将会生成相似的树形结构,拥有不同类的两个组件将会生成不同的树形结构。 -
对于同一层级的一组子节点,它们可以通过唯一 id 进行区分。
基于这三个策略,react 在 tree diff 和 component diff 中,两棵树只会对同层次的节点进行比较。如果同层级的树发生了更新,则会将该节点及其子节点同时进行更新,这样避免了递归遍历更加深入的节点的操作。在后面渲染性能优化部分,对于同一类型的组件如果能够准确的知道 VDOM 是否变化,使用shouldComponentUpdate来判断该组件是否需要 diff,能够节省大量的 diff 运算时间。
当 react 进行 element diff 操作中,在元素中添加唯一的key来进行区分,对其进行算法优化。所以像大数据量的列表之类的组件中最好添加key属性,能够带来一定的性能提升。
交流讨论
欢迎关注公众号「前端试炼」,公众号平时会分享一些实用或者有意思的东西,发现代码之美。专注深度和最佳实践,希望打造一个高质量的公众号。
公众号后台回复「加群」,拉你进交流划水聊天群,有看到好文章/代码都会发在群里。
如果你不想加群,只是想加我也是可以。
如果觉得这篇文章还不错,来个【转发、收藏、在看】三连吧,让更多的人也看到~
❤️ 顺手点个在看呗 ↓?