
何凯明团队又出新论文!北大、上交校友教你用ViT做迁移学习

新智元报道
新智元报道
编辑:LRS 好困 小咸鱼
【新智元导读】何凯明团队又发新论文了!这次他们研究的是如何将预训练好的ViT迁移到检测模型上,使标准ViT模型能够作为Mask R-CNN的骨干使用。结果表明,与有监督和先前的自我监督的预训练方法相比,AP box绝对值增加了4%。




研究方法
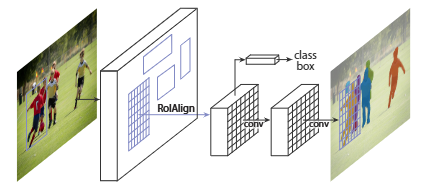
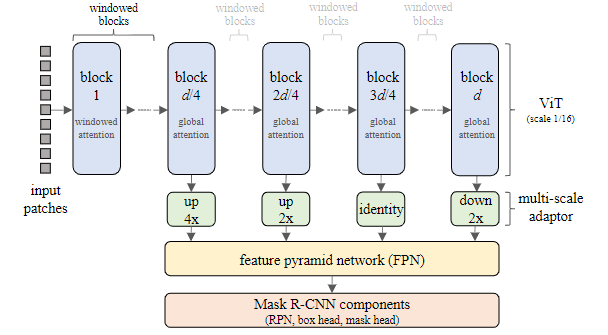
FPN中的卷积后加入Batch Normalization;
在RPN(region proposal network)中使用两个卷积;
采用四个带BN的卷积后接一个全连接用来RoI (reigon-of-interest) 分类与box回归头,而非原始的两层无normalization的MLP;
标准mask头中的卷积后加入BN

对每个初始化,固定dp=0.0,对lr与wd采用grid搜索,固定搜索中心为,以此为中心搜索;
对于ViT-B,从中选择dp(预训练参数时,训练50epoch;从头开始时,则训练100epoch,dp=0.1为最优选择;
对于ViT-L,采用了ViT-B的最优lr与wd,发现dp=0.3是最佳选择。
实验部分
Random:即所有参数均随机初始化,无预训练;
Supervised:即ViT骨干在ImageNet上通过监督方式预训练,分别为300和200epoch;
MoCoV3:即在ImageNet上采用无监督方式预训练ViT-B与ViT-L,300epoch;
BEiT:即采用BEiT方式对ViT-B与ViT-L预训练,800epoch;
MAE:使用MAE 无监督方法在ImageNet-1K上训练后得到ViT-B和ViT-L的权重。

不同的预训练方法采用了不同的epoch;
BEiT采用可学习相对位置bias,而非其他方法中的绝对位置embedding;
BEiT在预训练过程中采用了layer scale,而其他方法没采用;
研究人员尝试对预训练数据标准化,而BEiT额外采用了DALL-E中的discrete VAE,在约2.5亿专有和未公开图像上训练作为图像tokenizer。
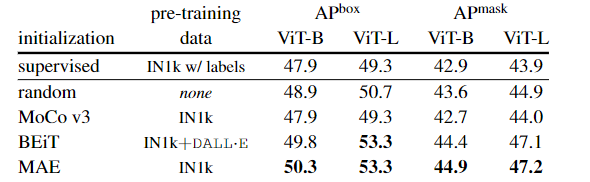
无论初始化过程如何,文中提出的Mask R-CNN训练过程都更加平滑,甚至它都不需要stabilizing的技术手段,如gradient clipping。
相比有监督训练,从头开始训练具有1.4倍的性能提升。实验结果也证明了有监督预训练并不一定比随机初始化更强;
基于对比学习的MoCoV3具有与监督预训练相当的性能;
对于ViT-B来说,BEiT与MAE均优于随机初始化与有监督预训练;
对于ViT-L,BEiT与MAE带来的性能提升进一步扩大。
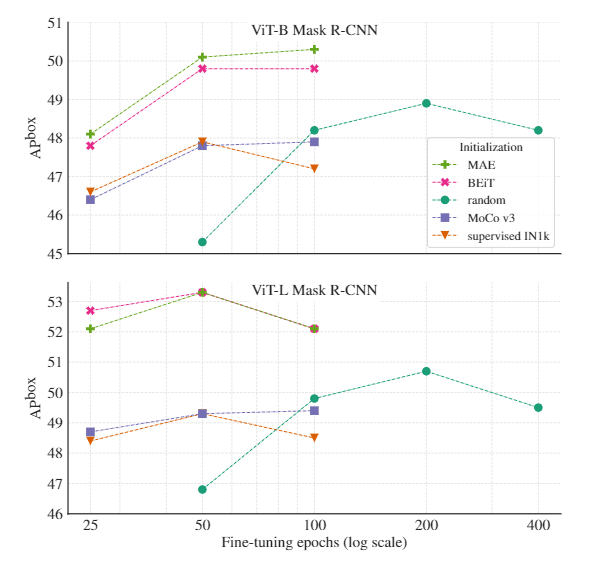
理想情况下,每个训练过程的drop path rate都应进行调整,因为可以观察到,当模型接受更长时间的训练时,最佳dp值可能需要增加。
在所有情况下都可以通过训练来获得更好的结果,例如加长训练时间,使用更复杂的训练流程,使用更好的正则化和更大的数据增强。
结论
参考资料:
https://arxiv.org/abs/2111.11429

评论