
用Python爬取芒果TV、腾讯视频、B站、爱奇艺、知乎、微博这几大平台的弹幕、评论,看这一篇就够了!


本文爬取一共六个平台,十个爬虫案例,如果只对个别案例感兴趣的可以根据:芒果TV、腾讯视频、B站、爱奇艺、知乎、微博这一顺序进行拉取观看。完整的实战源码已在文中,我们废话不多说,下面开始操作!
芒果TV
本文以爬取电影《悬崖之上》为例,讲解如何爬取芒果TV视频的弹幕和评论!
网页地址:
https://www.mgtv.com/b/335313/12281642.html?fpa=15800&fpos=8&lastp=ch_movie
弹幕
分析网页
弹幕数据所在的文件是动态加载的,需要进入浏览器的开发者工具进行抓包,得到弹幕数据所在的真实url。当视频播放一分钟它就会更新一个json数据包,里面包含我们需要的弹幕数据。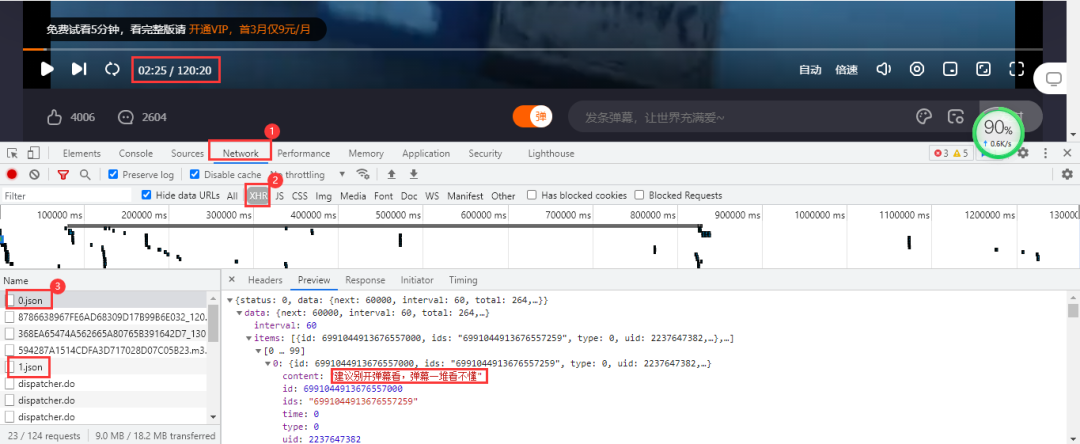 得到的真实url:
得到的真实url:
https://bullet-ali.hitv.com/bullet/2021/08/14/005323/12281642/0.json
https://bullet-ali.hitv.com/bullet/2021/08/14/005323/12281642/1.json
可以发现,每条url的差别在于后面的数字,首条url为0,后面的逐步递增。视频一共120:20分钟,向上取整,也就是121条数据包。
实战代码
import requests
import pandas as pd
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
df = pd.DataFrame()
for e in range(0, 121):
print(f'正在爬取第{e}页')
resposen = requests.get(f'https://bullet-ali.hitv.com/bullet/2021/08/3/004902/12281642/{e}.json', headers=headers)
# 直接用json提取数据
for i in resposen.json()['data']['items']:
ids = i['ids'] # 用户id
content = i['content'] # 弹幕内容
time = i['time'] # 弹幕发生时间
# 有些文件中不存在点赞数
try:
v2_up_count = i['v2_up_count']
except:
v2_up_count = ''
text = pd.DataFrame({'ids': [ids], '弹幕': [content], '发生时间': [time]})
df = pd.concat([df, text])
df.to_csv('悬崖之上.csv', encoding='utf-8', index=False)
结果展示: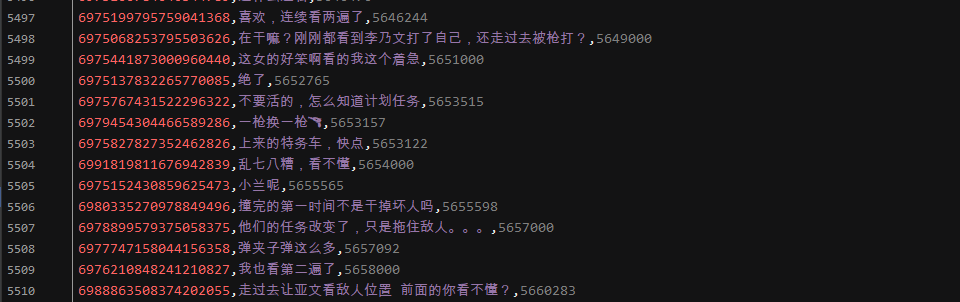
评论
分析网页
芒果TV视频的评论需要拉取到网页下面进行查看。评论数据所在的文件依然是动态加载的,进入开发者工具,按下列步骤进行抓包:Network→js,最后点击查看更多评论。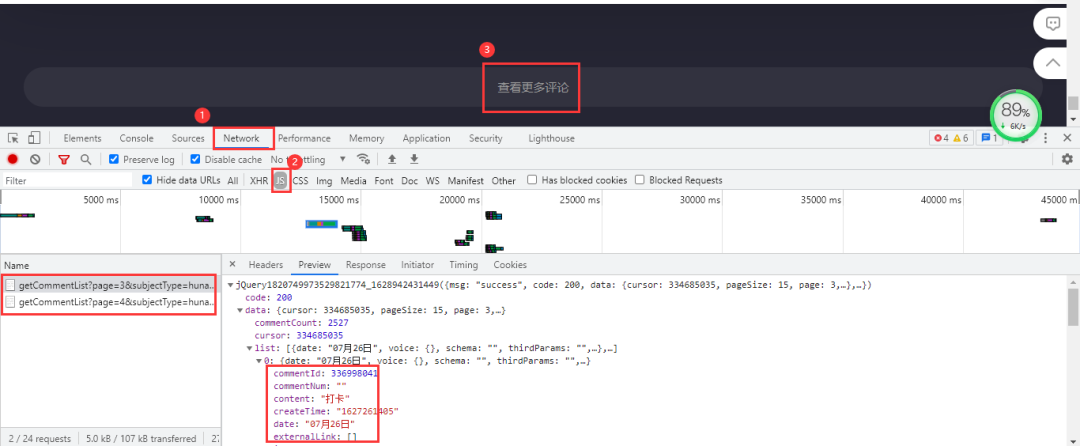 加载出来的依然是js文件,里面包含评论数据。得到的真实url:
加载出来的依然是js文件,里面包含评论数据。得到的真实url:
https://comment.mgtv.com/v4/comment/getCommentList?page=1&subjectType=hunantv2014&subjectId=12281642&callback=jQuery1820749973529821774_1628942431449&_support=10000000&_=1628943290494
https://comment.mgtv.com/v4/comment/getCommentList?page=2&subjectType=hunantv2014&subjectId=12281642&callback=jQuery1820749973529821774_1628942431449&_support=10000000&_=1628943296653
其中有差别的参数有page和_,page是页数,_是时间戳;url中的时间戳删除后不影响数据完整性,但里面的callback参数会干扰数据解析,所以进行删除。最后得到url:
https://comment.mgtv.com/v4/comment/getCommentList?page=1&subjectType=hunantv2014&subjectId=12281642&_support=10000000
数据包中每页包含15条评论数据,评论总数是2527,得到最大页为169。
实战代码
import requests
import pandas as pd
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
df = pd.DataFrame()
for o in range(1, 170):
url = f'https://comment.mgtv.com/v4/comment/getCommentList?page={o}&subjectType=hunantv2014&subjectId=12281642&_support=10000000'
res = requests.get(url, headers=headers).json()
for i in res['data']['list']:
nickName = i['user']['nickName'] # 用户昵称
praiseNum = i['praiseNum'] # 被点赞数
date = i['date'] # 发送日期
content = i['content'] # 评论内容
text = pd.DataFrame({'nickName': [nickName], 'praiseNum': [praiseNum], 'date': [date], 'content': [content]})
df = pd.concat([df, text])
df.to_csv('悬崖之上.csv', encoding='utf-8', index=False)
结果展示:
腾讯视频
本文以爬取电影《革命者》为例,讲解如何爬取腾讯视频的弹幕和评论!
网页地址:
https://v.qq.com/x/cover/mzc00200m72fcup.html
弹幕
分析网页
依然进入浏览器的开发者工具进行抓包,当视频播放30秒它就会更新一个json数据包,里面包含我们需要的弹幕数据。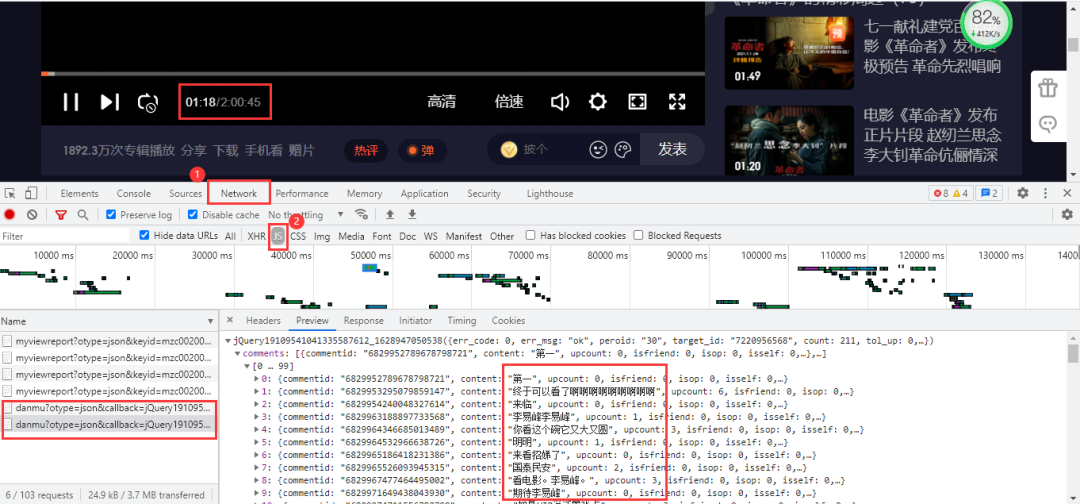 得到真实url:
得到真实url:
https://mfm.video.qq.com/danmu?otype=json&callback=jQuery19109541041335587612_1628947050538&target_id=7220956568%26vid%3Dt0040z3o3la&session_key=0%2C32%2C1628947057×tamp=15&_=1628947050569
https://mfm.video.qq.com/danmu?otype=json&callback=jQuery19109541041335587612_1628947050538&target_id=7220956568%26vid%3Dt0040z3o3la&session_key=0%2C32%2C1628947057×tamp=45&_=1628947050572
其中有差别的参数有timestamp和_。_是时间戳。timestamp是页数,首条url为15,后面以公差为30递增,公差是以数据包更新时长为基准,而最大页数为视频时长7245秒。依然删除不必要参数,得到url:
https://mfm.video.qq.com/danmu?otype=json&target_id=7220956568%26vid%3Dt0040z3o3la&session_key=0%2C18%2C1628418094×tamp=15&_=1628418086509
实战代码
import pandas as pd
import time
import requests
headers = {
'User-Agent': 'Googlebot'
}
# 初始为15,7245 为视频秒长,链接以三十秒递增
df = pd.DataFrame()
for i in range(15, 7245, 30):
url = "https://mfm.video.qq.com/danmu?otype=json&target_id=7220956568%26vid%3Dt0040z3o3la&session_key=0%2C18%2C1628418094×tamp={}&_=1628418086509".format(i)
html = requests.get(url, headers=headers).json()
time.sleep(1)
for i in html['comments']:
content = i['content']
print(content)
text = pd.DataFrame({'弹幕': [content]})
df = pd.concat([df, text])
df.to_csv('革命者_弹幕.csv', encoding='utf-8', index=False)
结果展示:
评论
分析网页
腾讯视频评论数据在网页底部,依然是动态加载的,需要按下列步骤进入开发者工具进行抓包: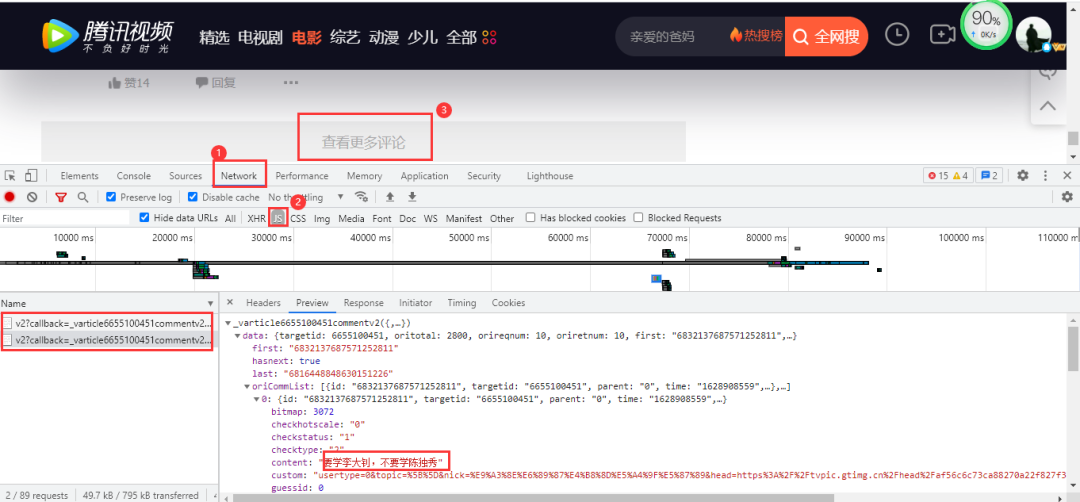 点击查看更多评论后,得到的数据包含有我们需要的评论数据,得到的真实url:
点击查看更多评论后,得到的数据包含有我们需要的评论数据,得到的真实url:
https://video.coral.qq.com/varticle/6655100451/comment/v2?callback=_varticle6655100451commentv2&orinum=10&oriorder=o&pageflag=1&cursor=0&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1628948867522
https://video.coral.qq.com/varticle/6655100451/comment/v2?callback=_varticle6655100451commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6786869637356389636&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1628948867523
url中的参数callback以及_删除即可。重要的是参数cursor,第一条url参数cursor是等于0的,第二条url才出现,所以要查找cursor参数是怎么出现的。经过我的观察,cursor参数其实是上一条url的last参数: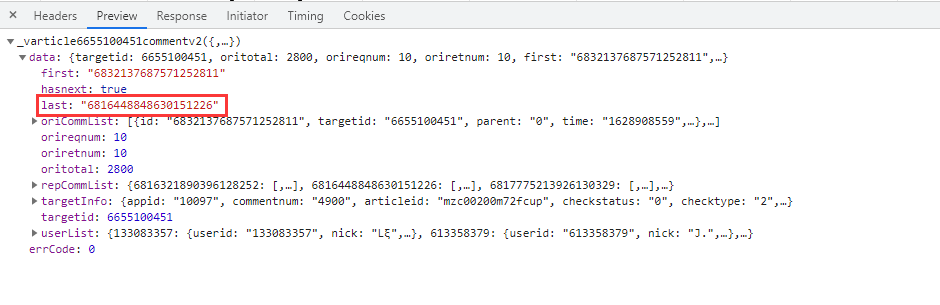
实战代码
import requests
import pandas as pd
import time
import random
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
df = pd.DataFrame()
a = 1
# 此处必须设定循环次数,否则会无限重复爬取
# 281为参照数据包中的oritotal,数据包中一共10条数据,循环280次得到2800条数据,但不包括底下回复的评论
# 数据包中的commentnum,是包括回复的评论数据的总数,而数据包都包含10条评论数据和底下的回复的评论数据,所以只需要把2800除以10取整数+1即可!
while a < 281:
if a == 1:
url = 'https://video.coral.qq.com/varticle/6655100451/comment/v2?orinum=10&oriorder=o&pageflag=1&cursor=0&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132'
else:
url = f'https://video.coral.qq.com/varticle/6655100451/comment/v2?orinum=10&oriorder=o&pageflag=1&cursor={cursor}&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132'
res = requests.get(url, headers=headers).json()
cursor = res['data']['last']
for i in res['data']['oriCommList']:
ids = i['id']
times = i['time']
up = i['up']
content = i['content'].replace('\n', '')
text = pd.DataFrame({'ids': [ids], 'times': [times], 'up': [up], 'content': [content]})
df = pd.concat([df, text])
a += 1
time.sleep(random.uniform(2, 3))
df.to_csv('革命者_评论.csv', encoding='utf-8', index=False)
效果展示: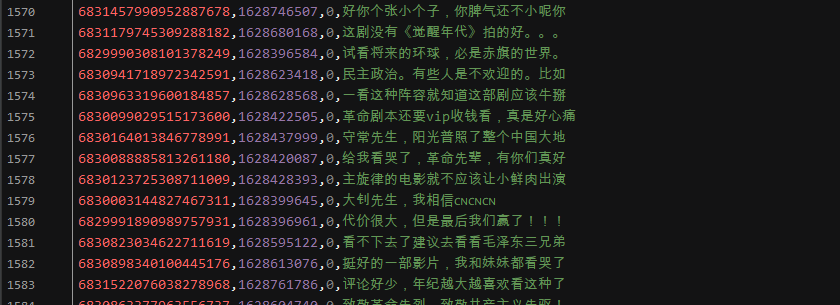
B站
本文以爬取视频《“ 这是我见过最拽的一届中国队奥运冠军”》为例,讲解如何爬取B站视频的弹幕和评论!
网页地址:
https://www.bilibili.com/video/BV1wq4y1Q7dp
弹幕
分析网页
B站视频的弹幕不像腾讯视频那样,播放视频就会触发弹幕数据包,他需要点击网页右侧的弹幕列表行的展开,然后点击查看历史弹幕获得视频弹幕开始日到截至日链接: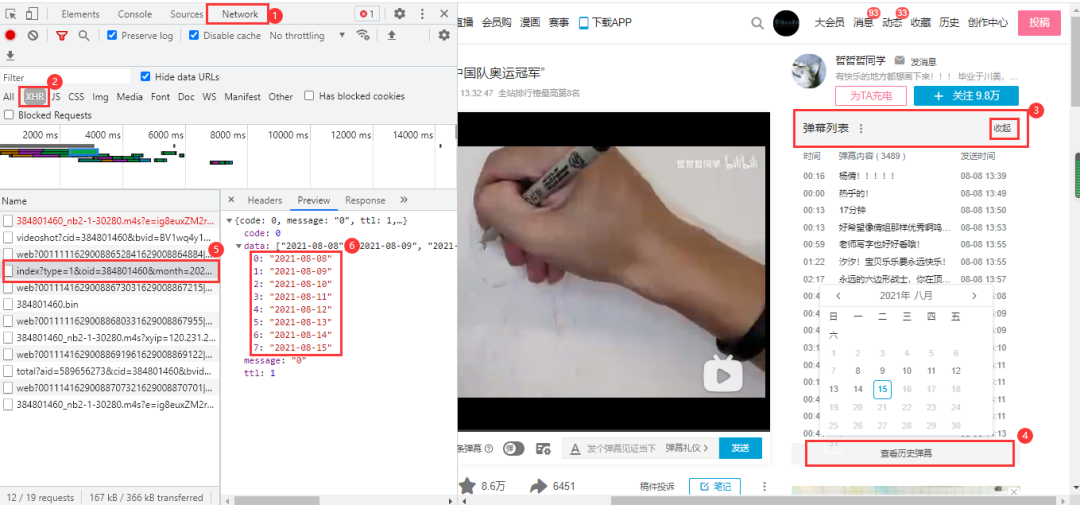 链接末尾以oid以及开始日期来构成弹幕日期url:
链接末尾以oid以及开始日期来构成弹幕日期url:
https://api.bilibili.com/x/v2/dm/history/index?type=1&oid=384801460&month=2021-08
在上面的的基础之上,点击任一有效日期即可获得这一日期的弹幕数据包,里面的内容目前是看不懂的,之所以确定它为弹幕数据包,是因为点击了日期他才加载出来,且链接与前面的链接具有相关性: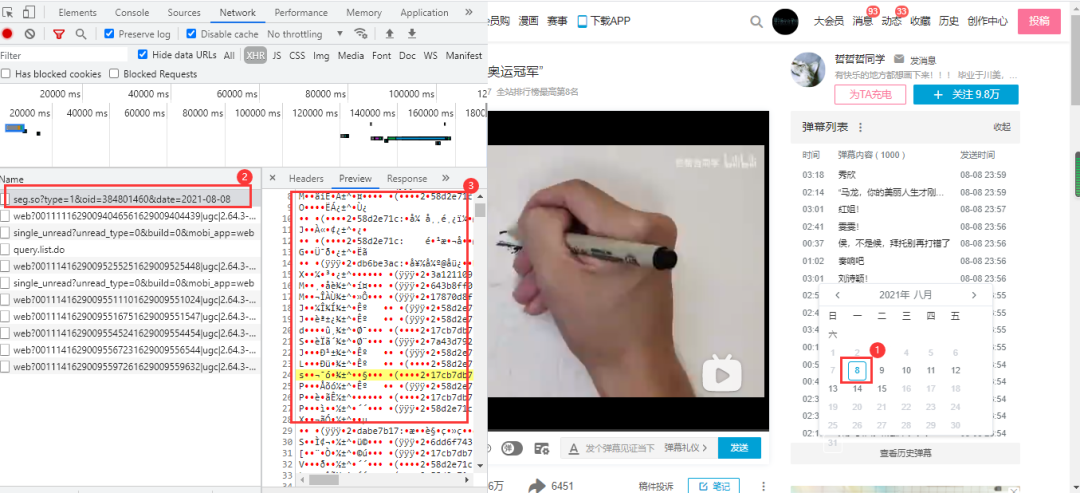 得到的url:
得到的url:
https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid=384801460&date=2021-08-08
url中的oid为视频弹幕链接的id值;data参数为刚才的的日期,而获得该视频全部弹幕内容,只需要更改data参数即可。而data参数可以从上面的弹幕日期url获得,也可以自行构造;网页数据格式为json格式
实战代码
import requests
import pandas as pd
import re
def data_resposen(url):
headers = {
"cookie": "你的cookie",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36"
}
resposen = requests.get(url, headers=headers)
return resposen
def main(oid, month):
df = pd.DataFrame()
url = f'https://api.bilibili.com/x/v2/dm/history/index?type=1&oid={oid}&month={month}'
list_data = data_resposen(url).json()['data'] # 拿到所有日期
print(list_data)
for data in list_data:
urls = f'https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid={oid}&date={data}'
text = re.findall(".*?([\u4E00-\u9FA5]+).*?", data_resposen(urls).text)
for e in text:
print(e)
data = pd.DataFrame({'弹幕': [e]})
df = pd.concat([df, data])
df.to_csv('弹幕.csv', encoding='utf-8', index=False, mode='a+')
if __name__ == '__main__':
oid = '384801460' # 视频弹幕链接的id值
month = '2021-08' # 开始日期
main(oid, month)
结果展示:
评论
分析网页
B站视频的评论内容在网页下方,进入浏览器的开发者工具后,只需要向下拉取即可加载出数据包: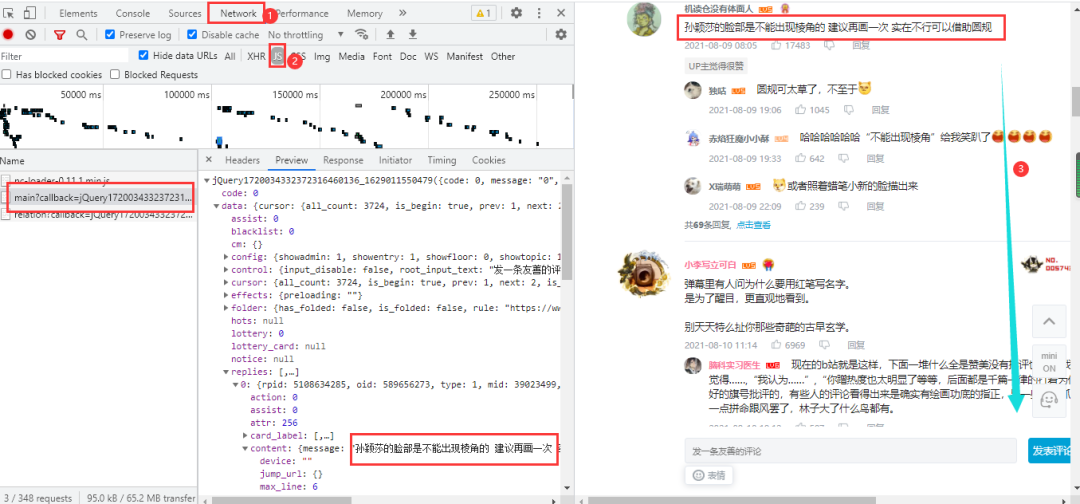 得到真实url:
得到真实url:
https://api.bilibili.com/x/v2/reply/main?callback=jQuery1720034332372316460136_1629011550479&jsonp=jsonp&next=0&type=1&oid=589656273&mode=3&plat=1&_=1629012090500
https://api.bilibili.com/x/v2/reply/main?callback=jQuery1720034332372316460136_1629011550483&jsonp=jsonp&next=2&type=1&oid=589656273&mode=3&plat=1&_=1629012513080
https://api.bilibili.com/x/v2/reply/main?callback=jQuery1720034332372316460136_1629011550484&jsonp=jsonp&next=3&type=1&oid=589656273&mode=3&plat=1&_=1629012803039
两条urlnext参数,以及_和callback参数。_和callback一个是时间戳,一个是干扰参数,删除即可。next参数第一条为0,第二条为2,第三条为3,所以第一条next参数固定为0,第二条开始递增;网页数据格式为json格式。
实战代码
import requests
import pandas as pd
df = pd.DataFrame()
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'}
try:
a = 1
while True:
if a == 1:
# 删除不必要参数得到的第一条url
url = f'https://api.bilibili.com/x/v2/reply/main?&jsonp=jsonp&next=0&type=1&oid=589656273&mode=3&plat=1'
else:
url = f'https://api.bilibili.com/x/v2/reply/main?&jsonp=jsonp&next={a}&type=1&oid=589656273&mode=3&plat=1'
print(url)
html = requests.get(url, headers=headers).json()
for i in html['data']['replies']:
uname = i['member']['uname'] # 用户名称
sex = i['member']['sex'] # 用户性别
mid = i['mid'] # 用户id
current_level = i['member']['level_info']['current_level'] # vip等级
message = i['content']['message'].replace('\n', '') # 用户评论
like = i['like'] # 评论点赞次数
ctime = i['ctime'] # 评论时间
data = pd.DataFrame({'用户名称': [uname], '用户性别': [sex], '用户id': [mid],
'vip等级': [current_level], '用户评论': [message], '评论点赞次数': [like],
'评论时间': [ctime]})
df = pd.concat([df, data])
a += 1
except Exception as e:
print(e)
df.to_csv('奥运会.csv', encoding='utf-8')
print(df.shape)
结果展示,获取的内容不包括二级评论,如果需要,可自行爬取,操作步骤差不多: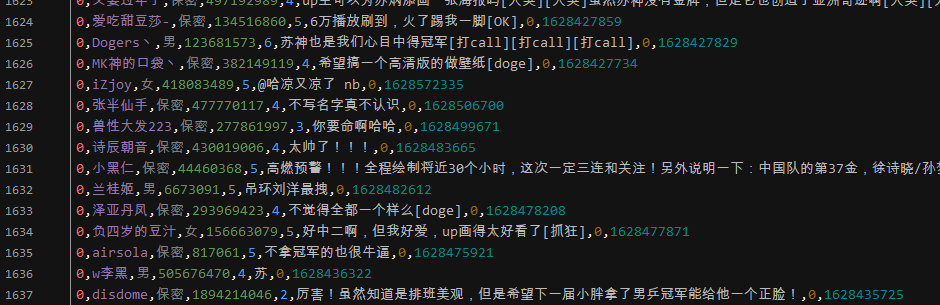
爱奇艺
本文以爬取电影《哥斯拉大战金刚》为例,讲解如何爬爱奇艺视频的弹幕和评论!
网页地址:
https://www.iqiyi.com/v_19rr0m845o.html
弹幕
分析网页
爱奇艺视频的弹幕依然是要进入开发者工具进行抓包,得到一个br压缩文件,点击可以直接下载,里面的内容是二进制数据,视频每播放一分钟,就加载一条数据包: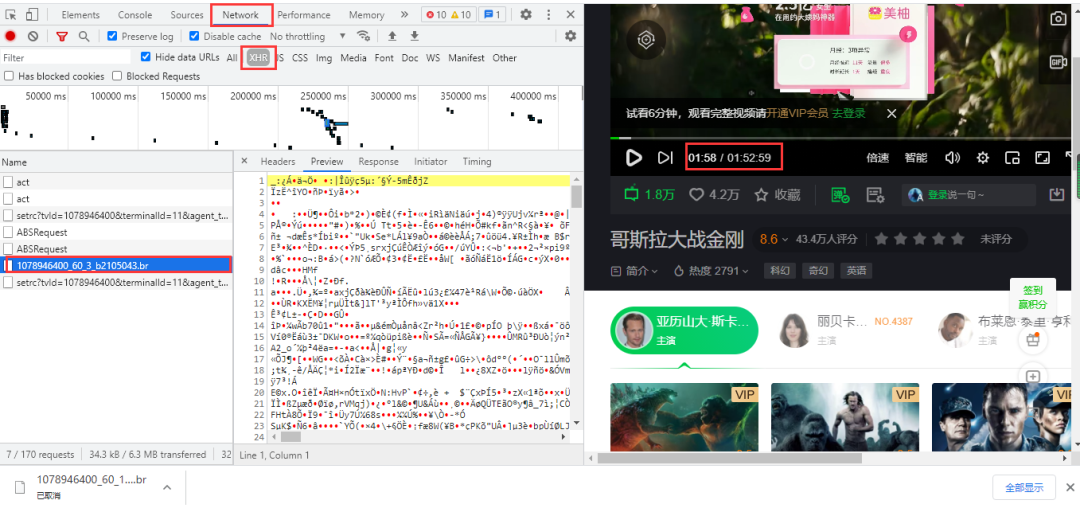 得到url,两条url差别在于递增的数字,60为视频每60秒更新一次数据包:
得到url,两条url差别在于递增的数字,60为视频每60秒更新一次数据包:
https://cmts.iqiyi.com/bullet/64/00/1078946400_60_1_b2105043.br
https://cmts.iqiyi.com/bullet/64/00/1078946400_60_2_b2105043.br
br文件可以用brotli库进行解压,但实际操作起来很难,特别是编码等问题,难以解决;在直接使用utf-8进行解码时,会报以下错误:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x91 in position 52: invalid start byte
在解码中加入ignore,中文不会乱码,但html格式出现乱码,数据提取依然很难:
decode("utf-8", "ignore")
 小刀被编码弄到头疼,如果有兴趣的小伙伴可以对上面的内容继续研究,本文就不在进行深入。所以本文采用另一个方法,对得到url进行修改成以下链接而获得.z压缩文件:
小刀被编码弄到头疼,如果有兴趣的小伙伴可以对上面的内容继续研究,本文就不在进行深入。所以本文采用另一个方法,对得到url进行修改成以下链接而获得.z压缩文件:
https://cmts.iqiyi.com/bullet/64/00/1078946400_300_1.z
之所以如此更改,是因为这是爱奇艺以前的弹幕接口链接,他还未删除或修改,目前还可以使用。该接口链接中1078946400是视频id;300是以前爱奇艺的弹幕每5分钟会加载出新的弹幕数据包,5分钟就是300秒,《哥斯拉大战金刚》时长112.59分钟,除以5向上取整就是23;1是页数;64为id值的第7为和第8为数。
实战代码
import requests
import pandas as pd
from lxml import etree
from zlib import decompress # 解压
df = pd.DataFrame()
for i in range(1, 23):
url = f'https://cmts.iqiyi.com/bullet/64/00/1078946400_300_{i}.z'
bulletold = requests.get(url).content # 得到二进制数据
decode = decompress(bulletold).decode('utf-8') # 解压解码
with open(f'{i}.html', 'a+', encoding='utf-8') as f: # 保存为静态的html文件
f.write(decode)
html = open(f'./{i}.html', 'rb').read() # 读取html文件
html = etree.HTML(html) # 用xpath语法进行解析网页
ul = html.xpath('/html/body/danmu/data/entry/list/bulletinfo')
for i in ul:
contentid = ''.join(i.xpath('./contentid/text()'))
content = ''.join(i.xpath('./content/text()'))
likeCount = ''.join(i.xpath('./likecount/text()'))
print(contentid, content, likeCount)
text = pd.DataFrame({'contentid': [contentid], 'content': [content], 'likeCount': [likeCount]})
df = pd.concat([df, text])
df.to_csv('哥斯拉大战金刚.csv', encoding='utf-8', index=False)
结果展示: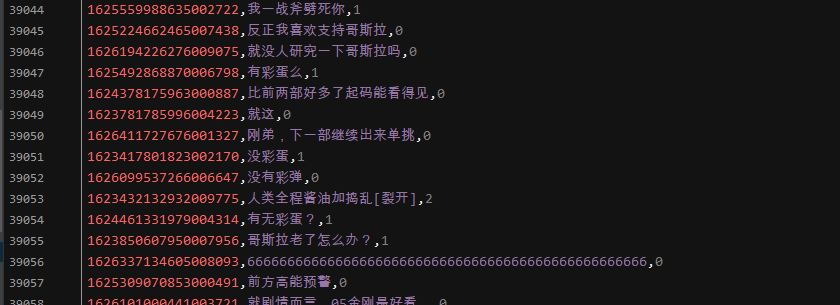
评论
分析网页
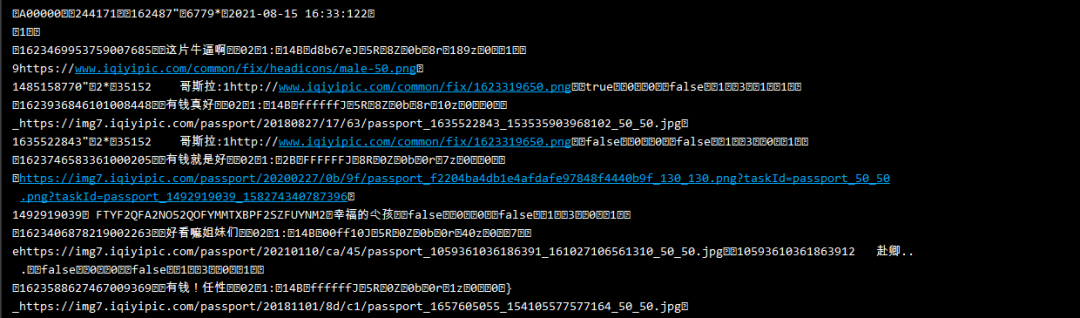
爱奇艺视频的评论在网页下方,依然是动态加载的内容,需要进入浏览器的开发者工具进行抓包,当网页下拉取时,会加载一条数据包,里面包含评论数据: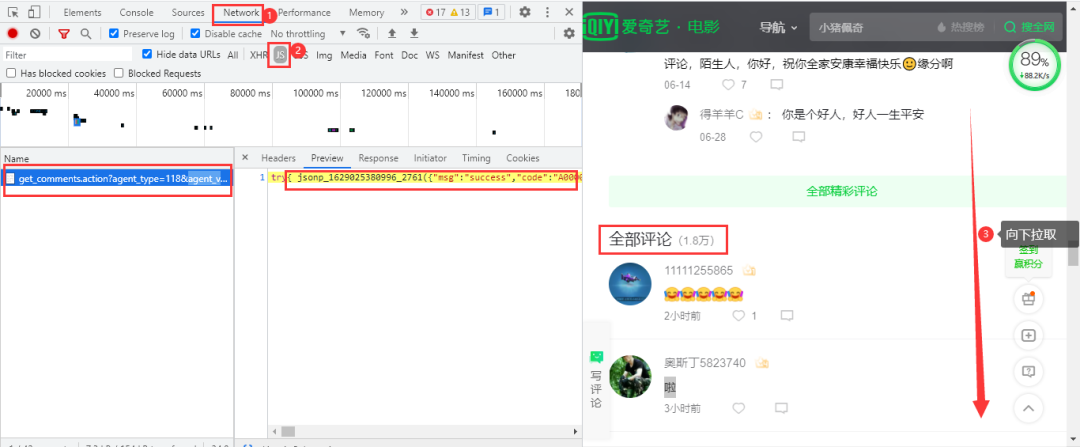 得到的真实url:
得到的真实url:
https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&authcookie=null&business_type=17&channel_id=1&content_id=1078946400&hot_size=10&last_id=&page=&page_size=10&types=hot,time&callback=jsonp_1629025964363_15405
https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&authcookie=null&business_type=17&channel_id=1&content_id=1078946400&hot_size=0&last_id=7963601726142521&page=&page_size=20&types=time&callback=jsonp_1629026041287_28685
https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&authcookie=null&business_type=17&channel_id=1&content_id=1078946400&hot_size=0&last_id=4933019153543021&page=&page_size=20&types=time&callback=jsonp_1629026394325_81937
第一条url加载的是精彩评论的内容,第二条url开始加载的是全部评论的内容。经过删减不必要参数得到以下url:
https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&business_type=17&content_id=1078946400&last_id=&page_size=10
https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&business_type=17&content_id=1078946400&last_id=7963601726142521&page_size=20
https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&business_type=17&content_id=1078946400&last_id=4933019153543021&page_size=20
区别在于参数last_id和page_size。page_size在第一条url中的值为10,从第二条url开始固定为20。last_id在首条url中值为空,从第二条开始会不断发生变化,经过我的研究,last_id的值就是从前一条url中的最后一条评论内容的用户id(应该是用户id);网页数据格式为json格式。
实战代码
import requests
import pandas as pd
import time
import random
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
df = pd.DataFrame()
try:
a = 0
while True:
if a == 0:
url = 'https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&business_type=17&content_id=1078946400&page_size=10'
else:
# 从id_list中得到上一条页内容中的最后一个id值
url = f'https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&business_type=17&content_id=1078946400&last_id={id_list[-1]}&page_size=20'
print(url)
res = requests.get(url, headers=headers).json()
id_list = [] # 建立一个列表保存id值
for i in res['data']['comments']:
ids = i['id']
id_list.append(ids)
uname = i['userInfo']['uname']
addTime = i['addTime']
content = i.get('content', '不存在') # 用get提取是为了防止键值不存在而发生报错,第一个参数为匹配的key值,第二个为缺少时输出
text = pd.DataFrame({'ids': [ids], 'uname': [uname], 'addTime': [addTime], 'content': [content]})
df = pd.concat([df, text])
a += 1
time.sleep(random.uniform(2, 3))
except Exception as e:
print(e)
df.to_csv('哥斯拉大战金刚_评论.csv', mode='a+', encoding='utf-8', index=False)
结果展示: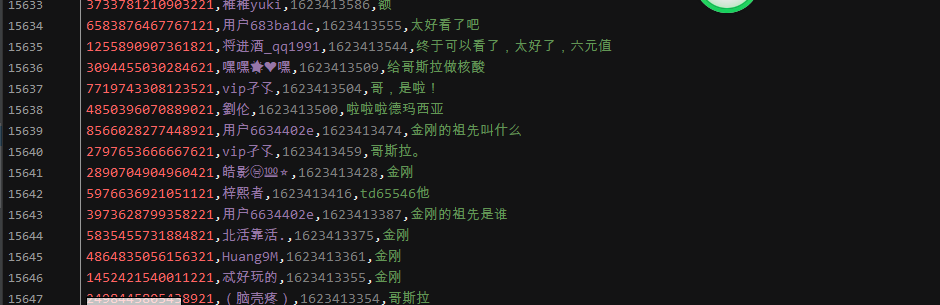
知乎
本文以爬取知乎热点话题《如何看待网传腾讯实习生向腾讯高层提出建议颁布拒绝陪酒相关条令?》为例,讲解如爬取知乎回答!
网页地址:
https://www.zhihu.com/question/478781972
分析网页
经过查看网页源代码等方式,确定该网页回答内容为动态加载的,需要进入浏览器的开发者工具进行抓包。进入Noetwork→XHR,用鼠标在网页向下拉取,得到我们需要的数据包: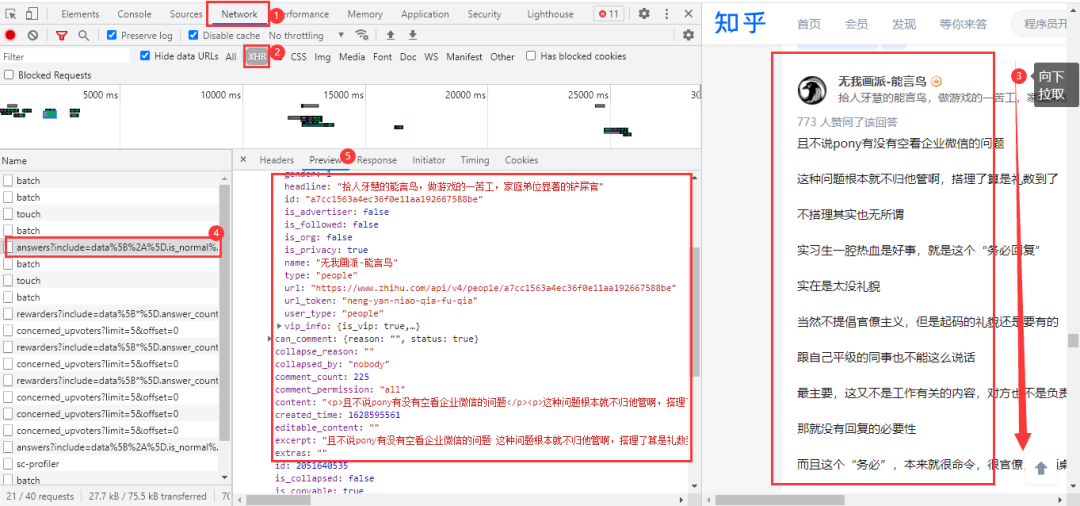 得到的真实url:
得到的真实url:
https://www.zhihu.com/api/v4/questions/478781972/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cvip_info%2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled&limit=5&offset=0&platform=desktop&sort_by=default
https://www.zhihu.com/api/v4/questions/478781972/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cvip_info%2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled&limit=5&offset=5&platform=desktop&sort_by=default
url有很多不必要的参数,大家可以在浏览器中自行删减。两条url的区别在于后面的offset参数,首条url的offset参数为0,第二条为5,offset是以公差为5递增;网页数据格式为json格式。
实战代码
import requests
import pandas as pd
import re
import time
import random
df = pd.DataFrame()
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
for page in range(0, 1360, 5):
url = f'https://www.zhihu.com/api/v4/questions/478781972/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cvip_info%2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled&limit=5&offset={page}&platform=desktop&sort_by=default'
response = requests.get(url=url, headers=headers).json()
data = response['data']
for list_ in data:
name = list_['author']['name'] # 知乎作者
id_ = list_['author']['id'] # 作者id
created_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(list_['created_time'] )) # 回答时间
voteup_count = list_['voteup_count'] # 赞同数
comment_count = list_['comment_count'] # 底下评论数
content = list_['content'] # 回答内容
content = ''.join(re.findall("[\u3002\uff1b\uff0c\uff1a\u201c\u201d\uff08\uff09\u3001\uff1f\u300a\u300b\u4e00-\u9fa5]", content)) # 正则表达式提取
print(name, id_, created_time, comment_count, content, sep='|')
dataFrame = pd.DataFrame(
{'知乎作者': [name], '作者id': [id_], '回答时间': [created_time], '赞同数': [voteup_count], '底下评论数': [comment_count],
'回答内容': [content]})
df = pd.concat([df, dataFrame])
time.sleep(random.uniform(2, 3))
df.to_csv('知乎回答.csv', encoding='utf-8', index=False)
print(df.shape)
结果展示:
微博
本文以爬取微博热搜《霍尊手写道歉信》为例,讲解如何爬取微博评论!
网页地址:
https://m.weibo.cn/detail/4669040301182509
分析网页
微博评论是动态加载的,进入浏览器的开发者工具后,在网页上向下拉取会得到我们需要的数据包: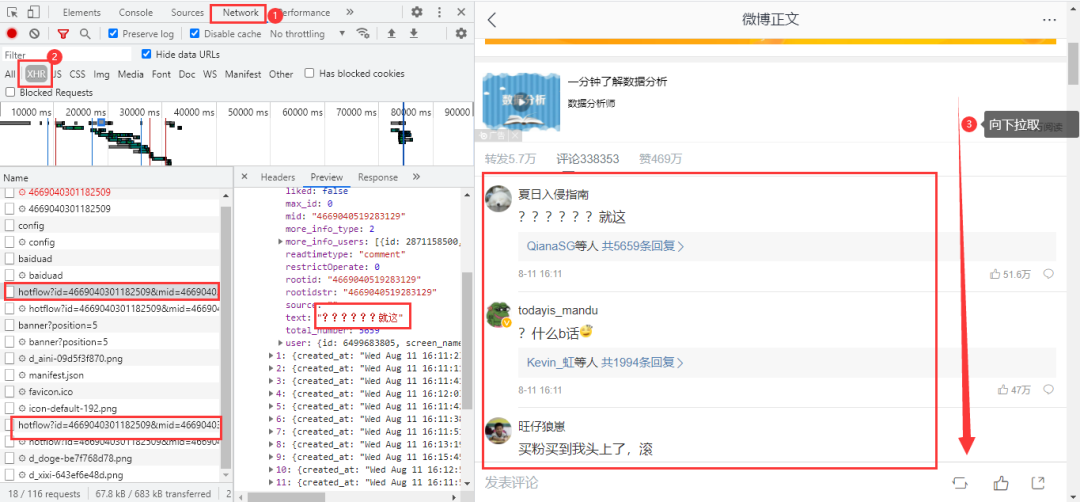 得到真实url:
得到真实url:
https://m.weibo.cn/comments/hotflow?id=4669040301182509&mid=4669040301182509&max_id_type=0
https://m.weibo.cn/comments/hotflow?id=4669040301182509&mid=4669040301182509&max_id=3698934781006193&max_id_type=0
两条url区别很明显,首条url是没有参数max_id的,第二条开始max_id才出现,而max_id其实是前一条数据包中的max_id: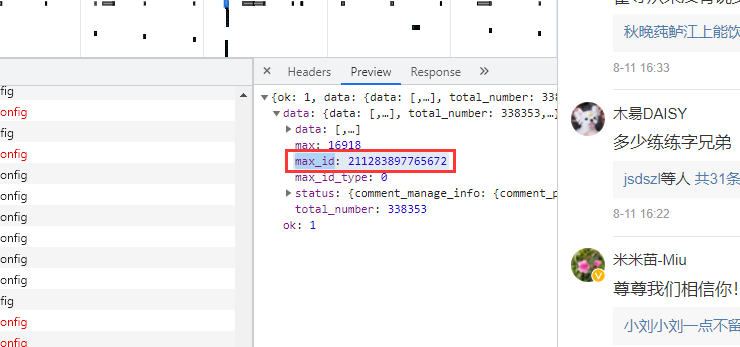 但有个需要注意的是参数
但有个需要注意的是参数max_id_type,它其实也是会变化的,所以我们需要从数据包中获取max_id_type: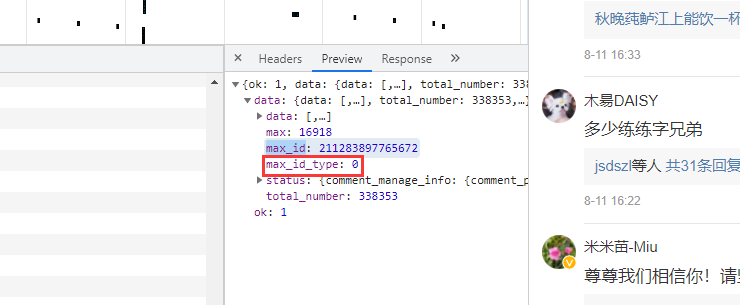
实战代码
import re
import requests
import pandas as pd
import time
import random
df = pd.DataFrame()
try:
a = 1
while True:
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36'
}
resposen = requests.get('https://m.weibo.cn/detail/4669040301182509', headers=header)
# 微博爬取大概几十页会封账号的,而通过不断的更新cookies,会让爬虫更持久点...
cookie = [cookie.value for cookie in resposen.cookies] # 用列表推导式生成cookies部件
headers = {
# 登录后的cookie, SUB用登录后的
'cookie': f'WEIBOCN_FROM={cookie[3]}; SUB=; _T_WM={cookie[4]}; MLOGIN={cookie[1]}; M_WEIBOCN_PARAMS={cookie[2]}; XSRF-TOKEN={cookie[0]}',
'referer': 'https://m.weibo.cn/detail/4669040301182509',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36'
}
if a == 1:
url = 'https://m.weibo.cn/comments/hotflow?id=4669040301182509&mid=4669040301182509&max_id_type=0'
else:
url = f'https://m.weibo.cn/comments/hotflow?id=4669040301182509&mid=4669040301182509&max_id={max_id}&max_id_type={max_id_type}'
html = requests.get(url=url, headers=headers).json()
data = html['data']
max_id = data['max_id'] # 获取max_id和max_id_type返回给下一条url
max_id_type = data['max_id_type']
for i in data['data']:
screen_name = i['user']['screen_name']
i_d = i['user']['id']
like_count = i['like_count'] # 点赞数
created_at = i['created_at'] # 时间
text = re.sub(r'<[^>]*>', '', i['text']) # 评论
print(text)
data_json = pd.DataFrame({'screen_name': [screen_name], 'i_d': [i_d], 'like_count': [like_count], 'created_at': [created_at],'text': [text]})
df = pd.concat([df, data_json])
time.sleep(random.uniform(2, 7))
a += 1
except Exception as e:
print(e)
df.to_csv('微博.csv', encoding='utf-8', mode='a+', index=False)
print(df.shape)
结果展示: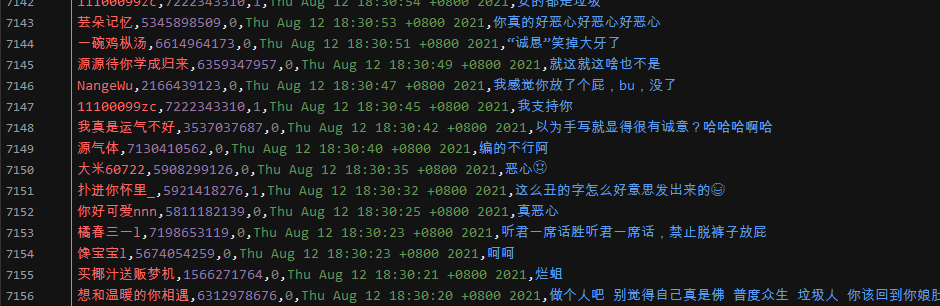
相关阅读: