
QQ浏览器是如何提升搜索相关性的?
云加社区
共 12028字,需浏览 25分钟
·
2023-01-13 02:57
 导言 | 搜索相关性主要指衡量Query和Doc的匹配程度,是信息检索的核心基础任务之一,也是商业搜索引擎的体验优劣最朴素的评价维度之一。本文作者刘杰主要介绍QQ浏览器搜索相关性团队在相关性系统及算法方面的实践经历。值得一提的是,本文会特别分享在QQ浏览器搜索、搜狗搜索两个大型系统融合过程中,在系统融合、算法融合、算法突破方面的实践经验。希望对搜索算法以及相关领域内的同学有帮助。
导言 | 搜索相关性主要指衡量Query和Doc的匹配程度,是信息检索的核心基础任务之一,也是商业搜索引擎的体验优劣最朴素的评价维度之一。本文作者刘杰主要介绍QQ浏览器搜索相关性团队在相关性系统及算法方面的实践经历。值得一提的是,本文会特别分享在QQ浏览器搜索、搜狗搜索两个大型系统融合过程中,在系统融合、算法融合、算法突破方面的实践经验。希望对搜索算法以及相关领域内的同学有帮助。 业务介绍
业务介绍
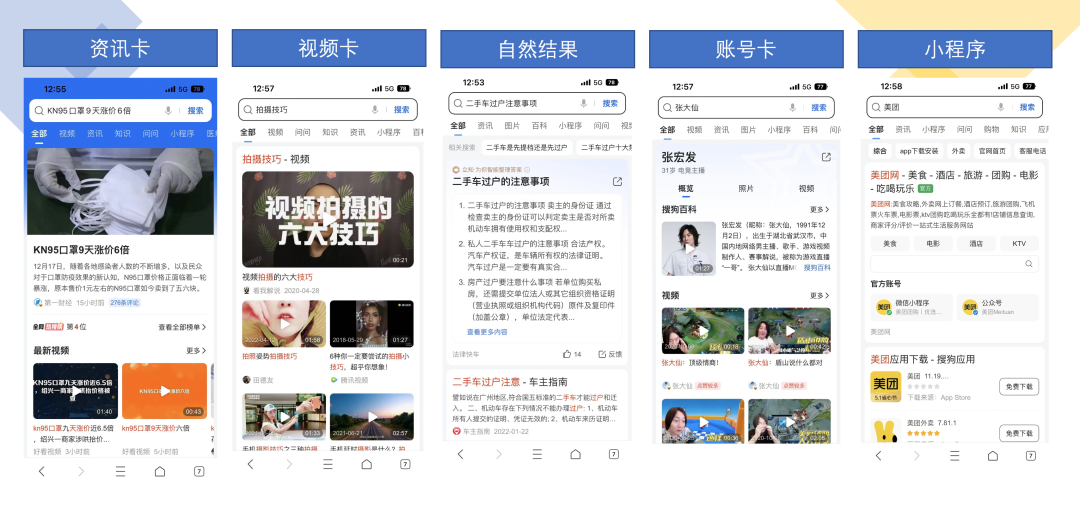

 搜索相关性介绍
搜索相关性介绍
1)搜索主体框架
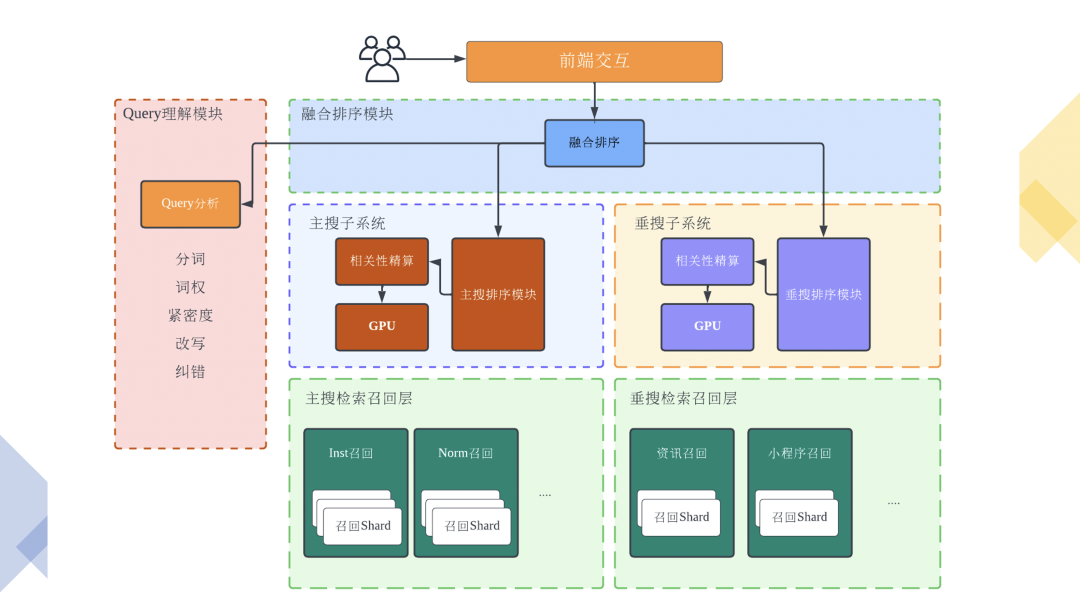
2)算法架构
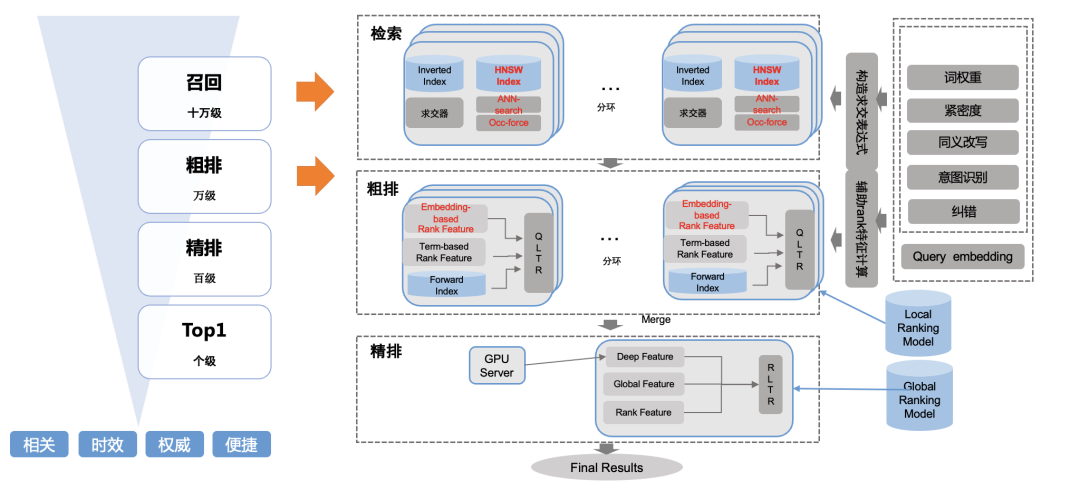
3)评估体系
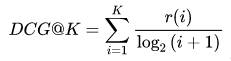
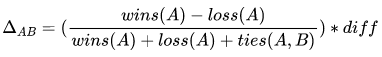
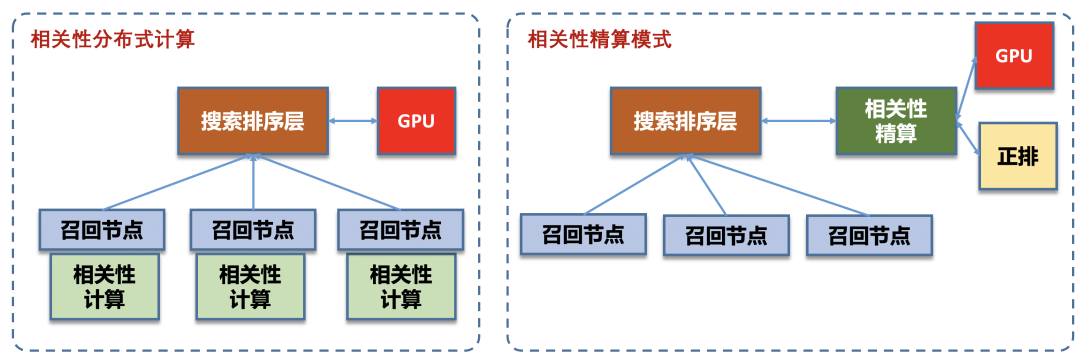
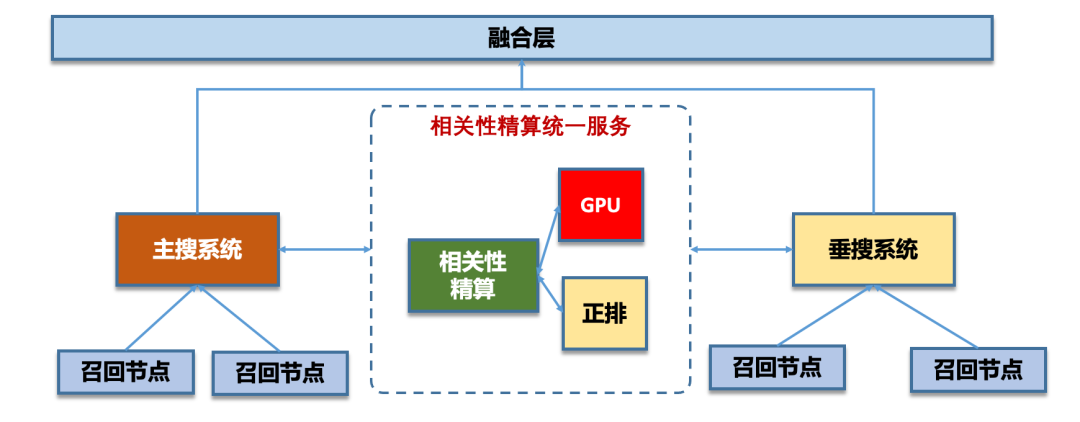
 相关性精算的系统演进
相关性精算的系统演进
1)1.0时代,群雄割据->三国争霸
2)2.0时代,统一复用

 搜索相关性技术实践
搜索相关性技术实践
1)相关性标准

2)相关性的技术架构
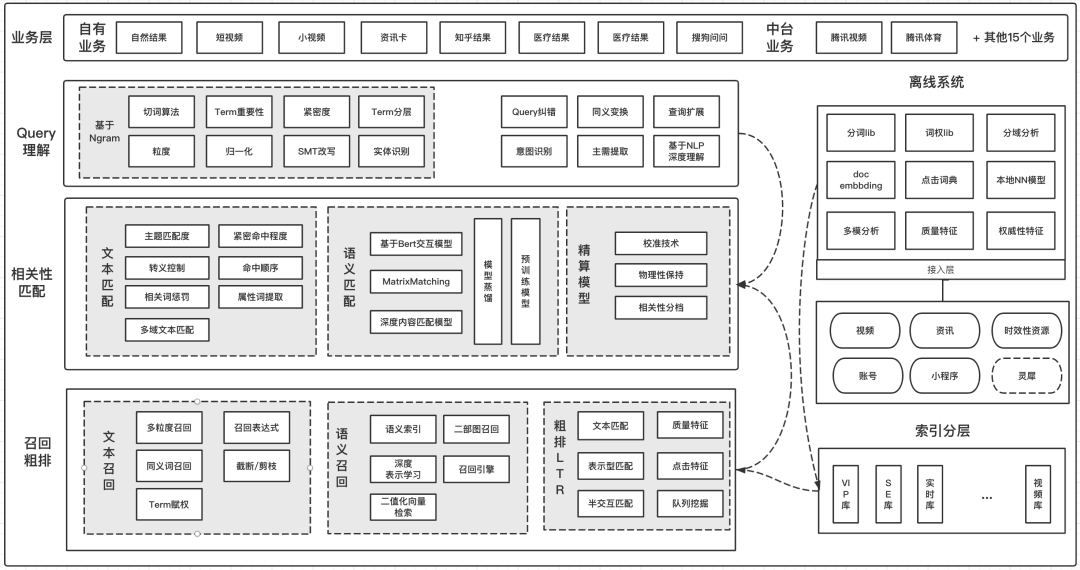
3)深度语义匹配实践
QQ浏览器搜索相关性的困难与挑战

深度语义的现状
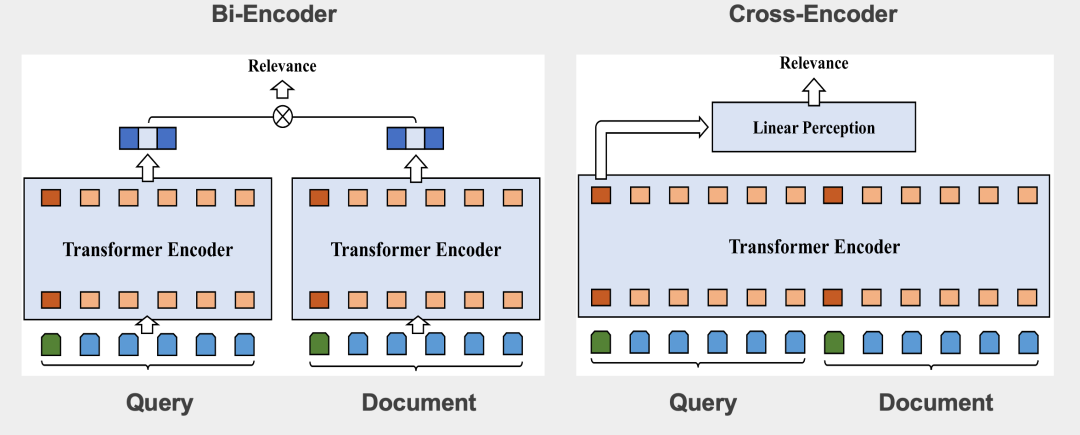
QQ浏览器搜索相关性深度语义实践
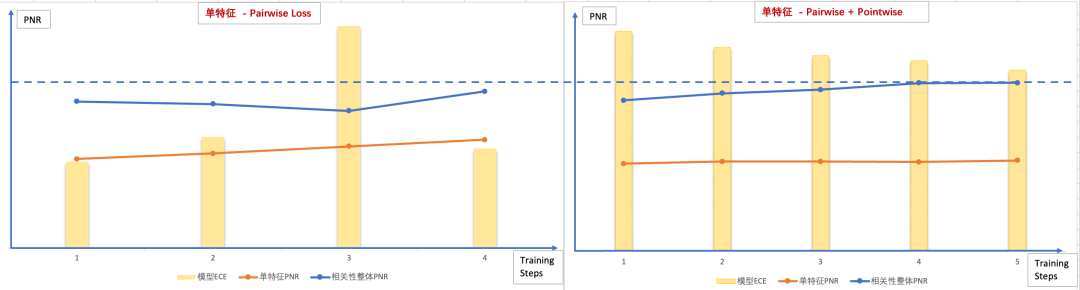
相关性Ranking Loss:目前我们的相关性标注标准共分为五个档位,最直接的建模方式,其实是进行N=5的N分类任务,即使用Pointwise的方式建模。搜索场景下,我们其实并不关心分类能力的好坏,而更关心不同样本之前的偏序关系,例如对于同一个Query的两个相关结果DocA和DocB,Pointwise模型只能判断出两者都与Query相关,无法区分DocA和DocB相关性程度。因此搜索领域的任务,更多更广泛的建模思路是将其视为一个文档排序场景,广泛使用Leaning To Rank思想进行业务场景建模。
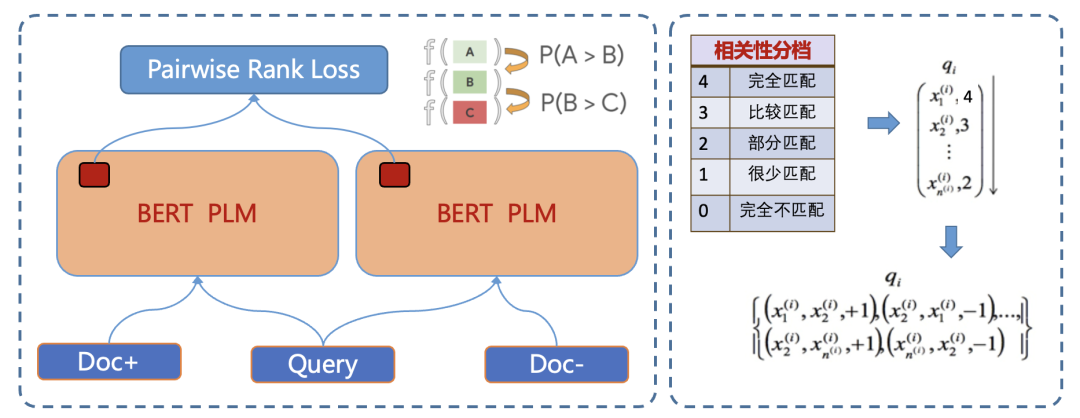
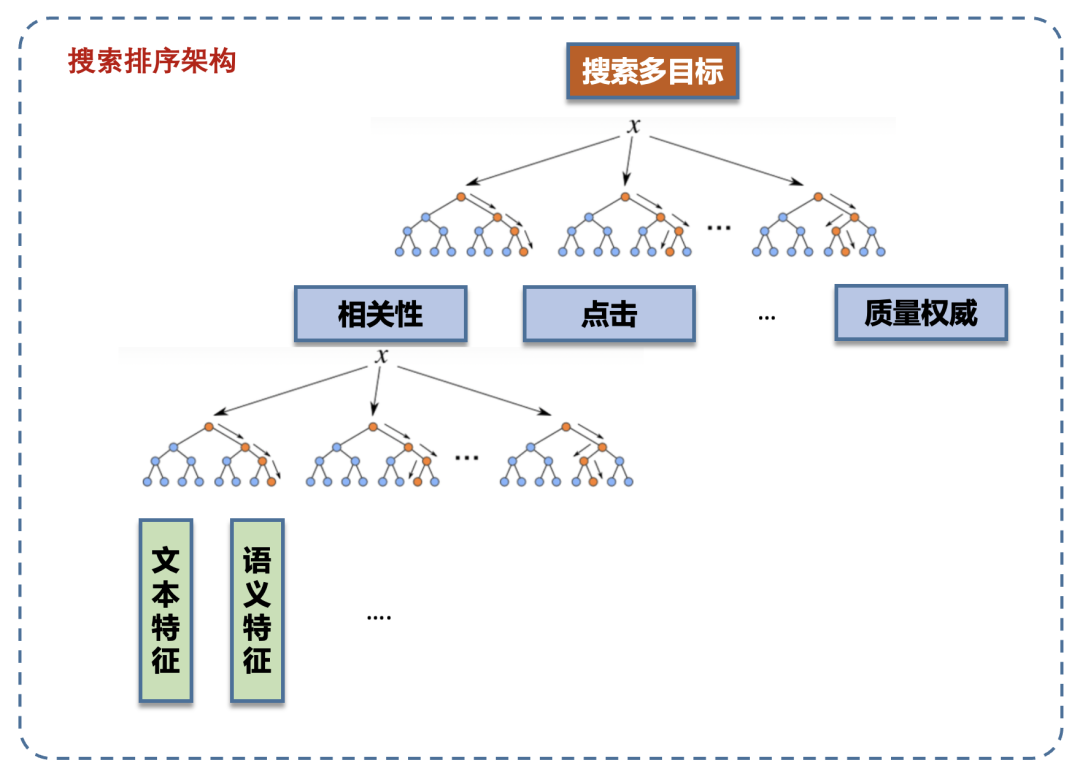
深度语义特征的校准问题——Ranking Loss的问题:相关性是搜索排序的基础能力,在整个计算流程的视角看,相关性计算不是最后一个阶段,所以当相关性内部子特征的目标如果直接使用RankingLoss,要特别注意与上下游的配合应用,特别要关注单特征的RankingLoss持续减少,是否与整体任务的提升一致。同时,RankLoss由于不具有全局的物理含义,即不同Query下的DocA和DocB的得分是不具有可比性,这直接导致了其作为特征值应用到下游模型时,如果我们使用例如决策树这种基于全局分裂增益来划分阈值的模型,会有一定的损失。
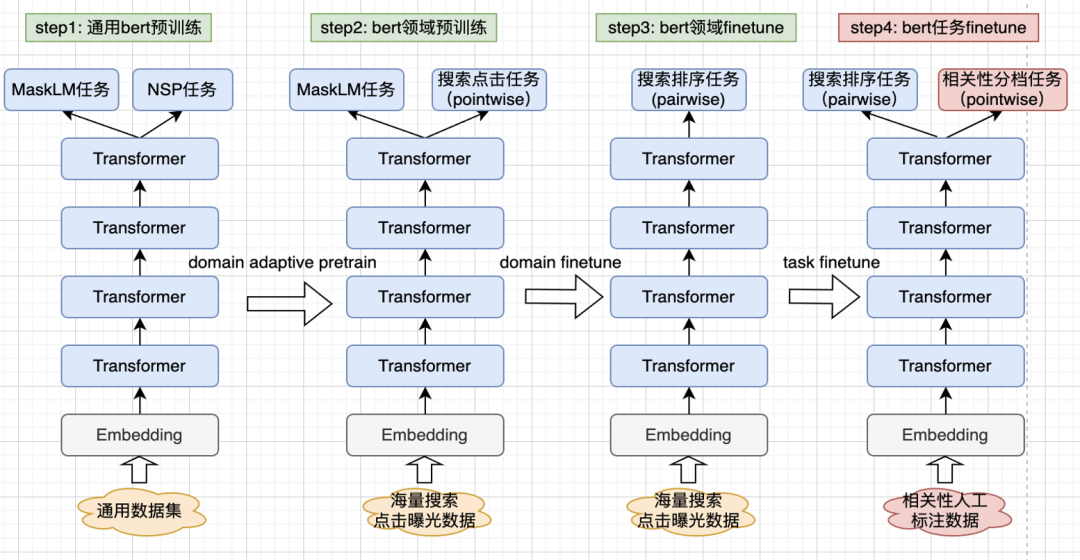
领域自适应:最近几年的NLP领域,预训练方向可以称得上AI方向的掌上明珠,从模型的参数规模、预训练的方法、多语言多模态等几个方向持续发展,不断地刷新着领域Benchmark。预训练通过自监督学习,从大规模数据中获得与具体任务无关的预训练模型。那么,在搜索领域下,如何将预训练语言模型,与搜索语料更好的结合,是我们团队一直在探索的方向。
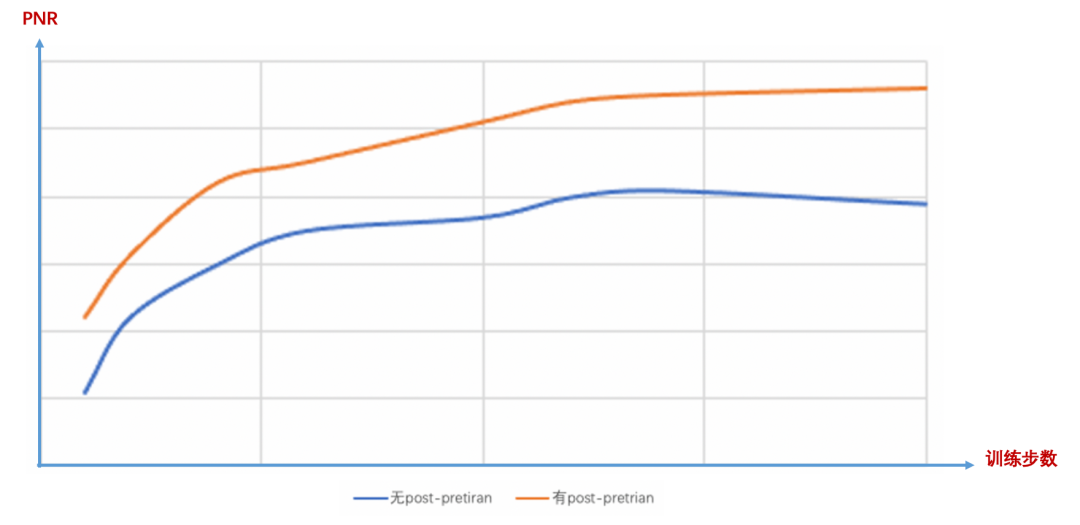
4)相关性语义匹配增强实践
深度语义匹配的鲁棒性问题
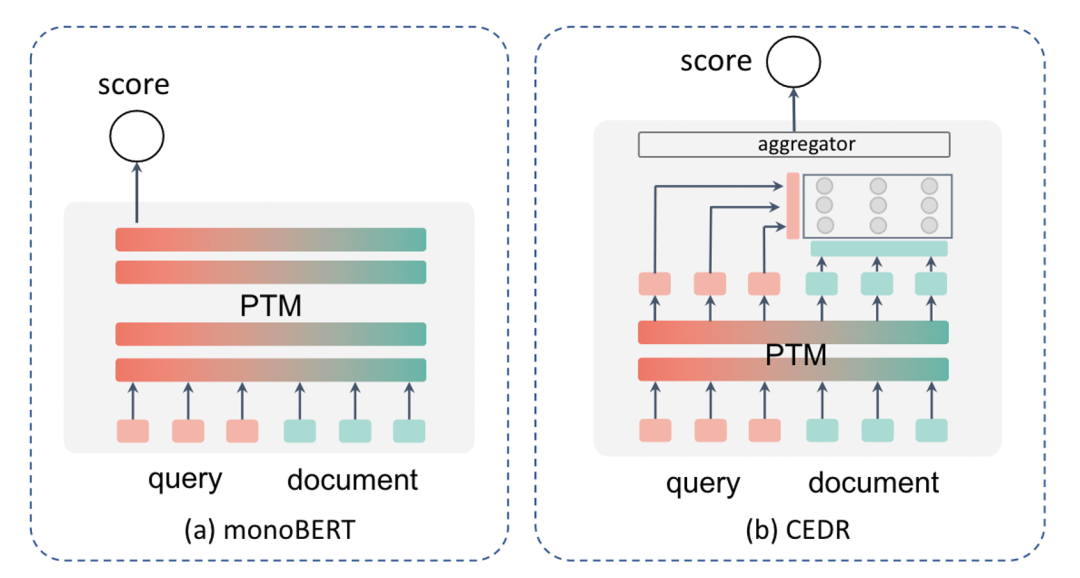
什么是相关性匹配(RelevanceMatching)
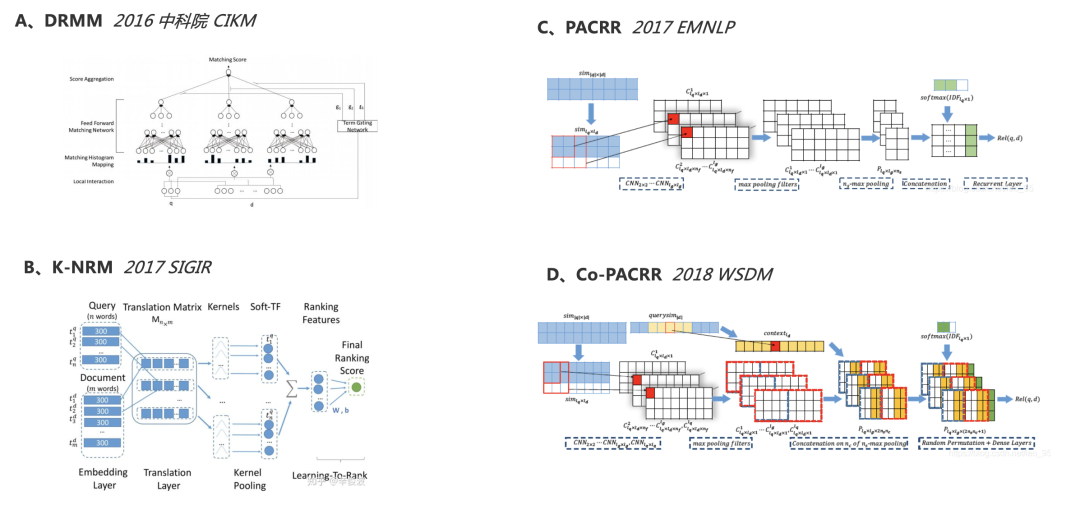
相关性匹配的相关工作
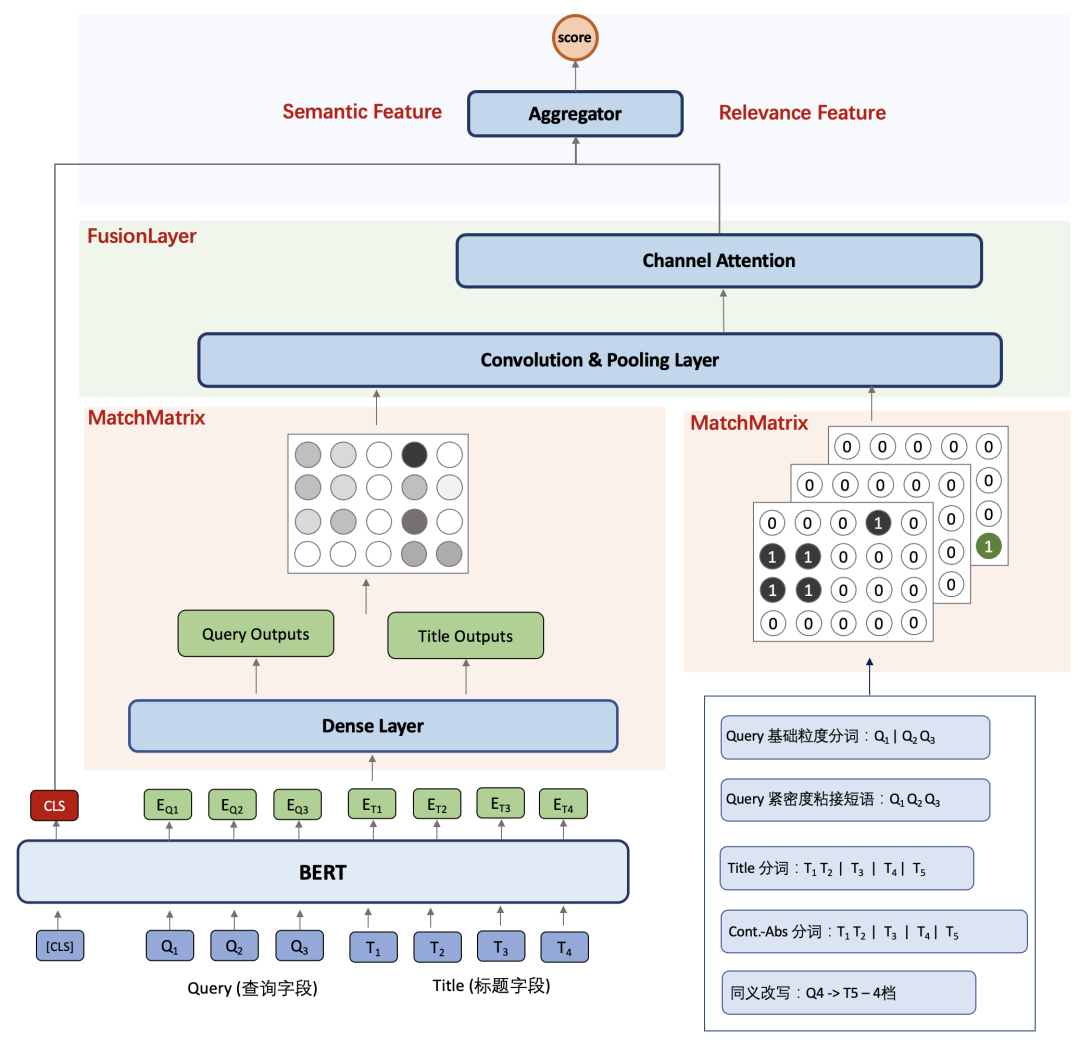
相关性匹配增强
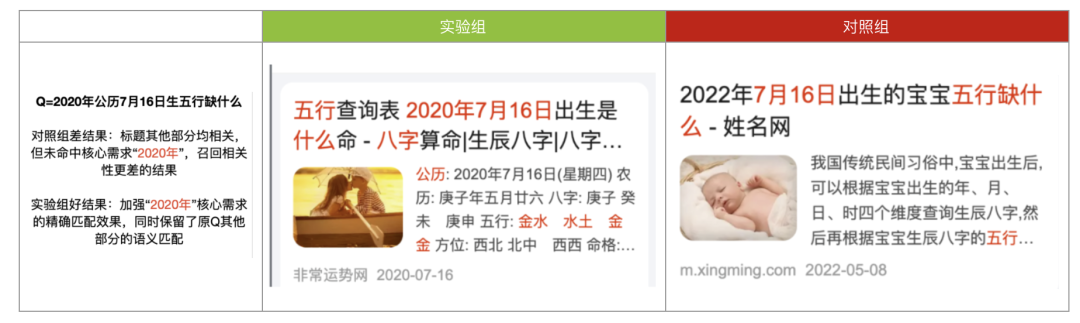
实验&效果

小结



工作日晚8点 看腾讯技术、学专家经验
评论