
CV圈对决:谷歌提出ViTGAN,用视觉Transformer训练GAN

新智元报道
新智元报道
来源:arXiv
编辑:Priscilla LQ
【新智元导读】CNN地位不稳。加州大学圣地亚哥分校联合谷歌进行研究:用视觉Transformer训练GAN,结果表明,ViTGAN性能可以与卷积GAN媲美。
卷积神经网络(convoluitonal neural networks,CNN)凭借强大的卷积和池化(pooling)能力,在计算机视觉领域占领主导地位。
而最近Transformer架构的兴起,开始在图像和视频识别任务中与CNN「掰头」。特别是视觉Transformer(ViT)。
Dosovitskiy等人的研究已经展示了将图像解释为一系列类似于自然语言中的单词的标记(token)。在ImageNet基准测试中,以较小的FLOP实现可比的分类精度。

现在尽管ViT及其变体仍然处于起步阶段,但鉴于ViT在图像识别方面表现出对竞争性,以及需要较少的视觉特定归纳偏差,ViT能不能扩展应用到图像生成呢?
由谷歌和加州大学圣地亚哥分校组成的研究团队对这个问题进行了研究,并发表了论文:ViTGAN:用视觉Transformer训练生成对抗网络(GAN)。

△ https://arxiv.org/pdf/2107.04589.pdf
论文研究的问题是:ViT是否可以在不使用卷积或池化的情况下完成图像生成任务,即ViT是否能用具有竞争质量的GAN训练出基于CNN的GAN。
研究团队将ViT架构集成到中GAN中,发现现有的GAN正则化方法与自我注意机制的交互很差,导致训练过程中严重的不稳定。
因此,团队引入了新的正则化技术来训练带有ViT的GAN,得出以下研究结果:
1. ViTGAN模型远优于基于Transformer的GAN模型,在不使用卷积或池化的情况下,性能与基于CNN的GAN(如Style-GAN2)相当。
2. ViTGAN模型是首个在GAN中利用视觉Transformer的模型之一。
3. ViTGAN模型展示了在标准图像生成基准(包括CIFAR、CelebA和LSUN bedroom数据集)中,这种Transformer与最先进的卷积架构具有可比性的方法。
实验方法
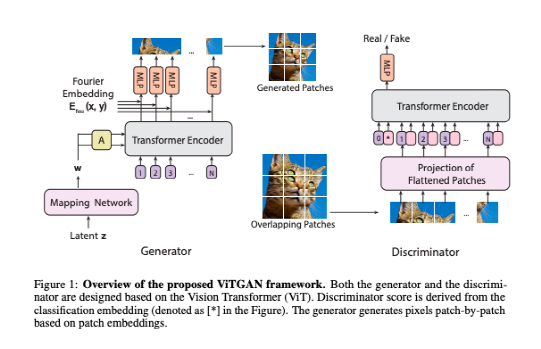
上图说明了ViTGAN的架构,包括一个ViT鉴别器和一个基于ViT的生成器。
实验发现,直接使用ViT作为鉴别器会使训练变得不稳定。作者对生成器和鉴别器都引入了新的技术,用来稳定训练动态并促进收敛。(1)ViT鉴别器的正则化;(2)生成器的新架构。
由于现有的 GAN 正则化方法与 self-attention 的交互很差,在训练过程中导致严重的不稳定。
为了解决这个问题,作者引入了新颖的「正则化」技术来训练带有 ViT 的 GAN数据集上实现了与最先进的基于CNN 的 StyleGAN2 相当的性能。
利普希茨连续(Lipschitz continuity)在GAN鉴别器中很重要,首先它作为WGAN中近似Wasserstein距离的一个条件而引入注意力,后来在其他GAN设置中被证实超出了 Wasserstein损失。特别是,证明了Lipschitz鉴别器保证了最优鉴别函数的存在以及唯一纳什均衡的存在。
然而,最近的一项工作表明,标准dot product self-attention(即Equation 5)层的Lipschitz常数可以是无界的,使Lipschitz连续在ViTs中被违反。
如Equation 7所示,实验用欧氏距离代替点积相似度,query 和 key的投影矩阵的权重也是一样的。
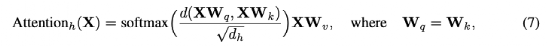
实验发现,在初始化时将每层的归一化权重矩阵与spectral norm相乘就足以解决这个问题。实验用以下的更新规则来实现spectral norm,其中σ计算权重矩阵的标准spectral norm.
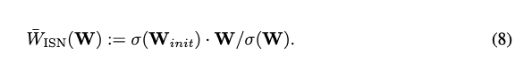
设计生成器
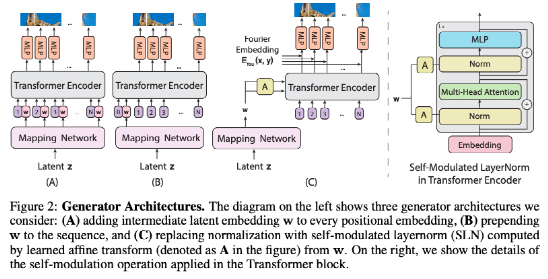
设计一个基于ViT架构的生成器并不简单。一个挑战是将ViT从预测一组类别标签转换为在一个空间区域内生成像素点。
在介绍实验模型之前,作者先讨论两个可信的基线模型,如Fig. 2 (A)和2 (B)所示。这两个模型交换ViT的输入和输出,从嵌入物中生成像素,特别是从潜伏向量 w,即w=MLP(z)(Fig. 2中称为映射网络),由MLP从高斯噪声向量z中导出。
这两个基线生成器在输入序列上有所不同。Fig. 2(A)将一个位置嵌入序列作为输入位置嵌入序列,并在每个位置嵌入中加入中间特征向量w.
实验结果
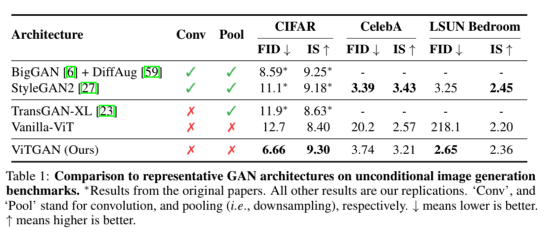
△ ViTGAN与基线架构关于图像合成的主要结果对比
TransGAN是现有唯一一个完全建立在 Transformer 架构上的无卷积GAN,其最佳变体是TransGAN-XL。
Vanilla-ViT是一种基于ViT的GAN,它使用图2(A)中所示的生成器和一个vanilla ViT鉴别器。
为公平比较,该基线使用了R1 penalty和bCR + DiffAug。
此外,BigGAN和StyleGAN2也作为最先进的基于CNN的GAN模型加入对比。
从上述表格可以看出,ViTGAN模型大大优于其他基于Transformer的GAN模型。这是在 Transformer架构上改进的稳定GAN训练的结果。它实现了与最先进的基于 CNN 的模型相当的性能。
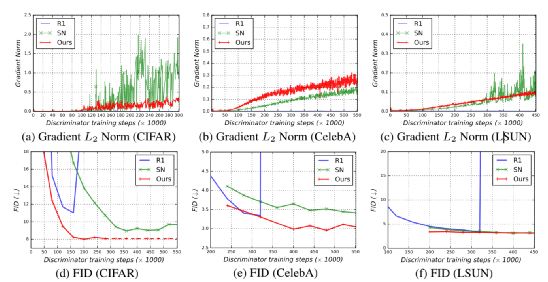
这一结果提供了一个经验证据:Transformer架构可以在生成对抗训练中与卷积网络相媲美。



如上图所示,ViTGAN模型(最后一列)显着提高了最佳 Transformer 基线(中间列)的图像保真度。即使与StyleGAN2相比,ViTGAN生成的图像质量和多样性也相当。
总结
这篇论文介绍了ViTGAN,利用GAN中的视觉Transformer(ViTs),并提出了确保其训练稳定性和提高收敛性的基本技术。
在标准基准(CIFAR-10、CelebA和LSUN bedroom)上的实验表明,提出的模型实现了与最先进的基于CNN的GAN相媲美的性能。
至于限制,ViTGAN是一个建立在普通ViT架构上的新的通用GAN模型。它仍然无法击败最好的基于CNN的GAN模型。
这可以通过将先进的训练技术纳入ViTGAN框架得到改善。希望ViTGAN能够促进这一领域未来的研究,并可以扩展到其他图像和视频合成任务。
参考资料:
-往期精彩-


