
中国人民志愿军抗美援朝出国作战70周年,我用 Python 为英雄们送上祝福

文 | 豆豆
来源:Python 技术「ID: pythonall」

今年是中国人民志愿军抗美援朝出国作战 70 周年,刚好上个月上映了同题材的电影「金刚川」。该影片主要讲的是抗美援朝战争最终阶段,志愿军准备在金城发动最后一场大型战役。为在指定时间到达,向金城前线投放更多战力,志愿军战士们在物资匮乏、武器装备相差悬殊的情况下,不断抵御敌机狂轰滥炸,以血肉之躯一次次修补战火中的木桥。
今天我们就用 Python 来分析一下「金刚川」这部电影,看看网友们对该剧的评论如何。
要想分析该剧,首先则需要获取数据源,豆瓣作为国内最大的文艺青年聚居地,其电影影评评分一直是比较客观的,所以这次我们选取豆瓣电影作为数据来源。
数据获取
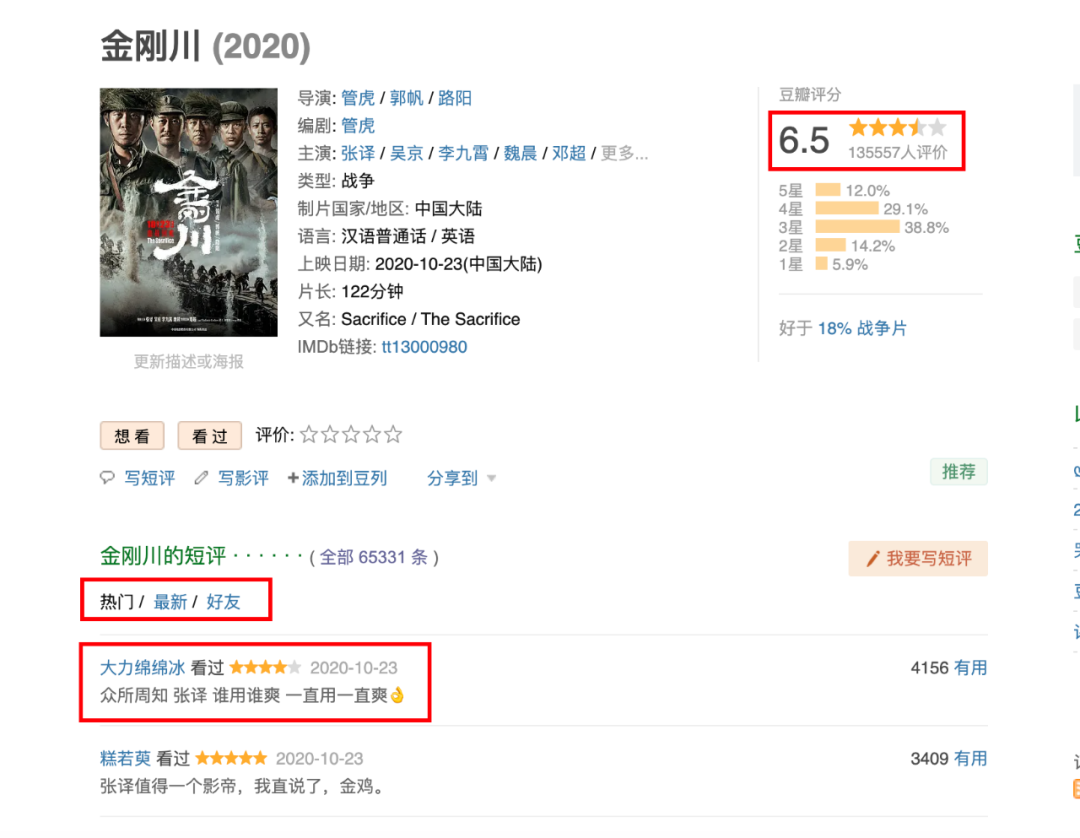
从豆瓣电影我们可以看出,该剧共有十三万多人进行评分,最终评分 6.5,不算低,共有短评六万多条,因为豆瓣的限制,游客身份只可以查看前 200 条短评,而登录之后可以查看前 500 条短评,同时我们还看到,影评有根据不同的维度分为热门、最新和好友,为了获取更多的数据样本,我们将热门和最新的评论都抓取下来。
其中我们要获取的数据有评论人,评论时间,评论星级以及评论内容,打开电影短评页面然后将开发者工具调取出来。
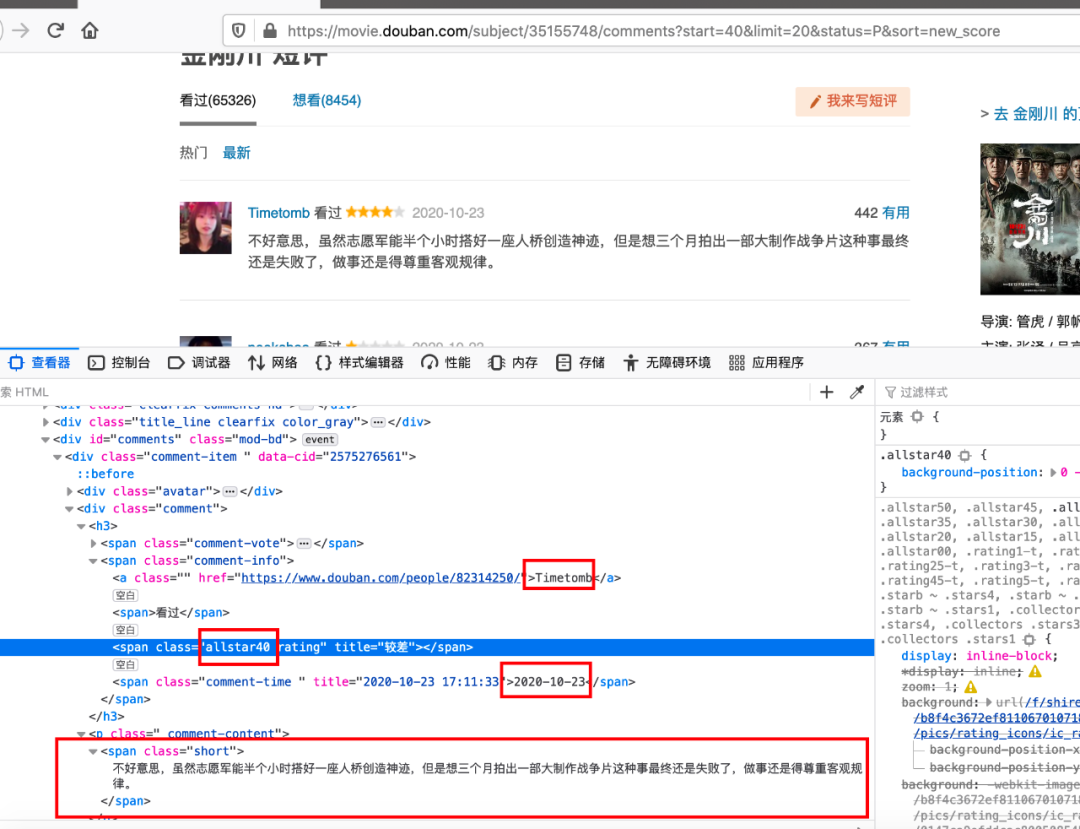
我们发现所有的评论都是在一个 class="comment" 的 div 中的,然后针对每一条评论,其对应的位置都如上图所示,唯一值得说明的是在我爬取数据的过程中,有的评论是获取不到评论时间的,
因此我们可以定义一个获取评论详情的函数,该函数接收一个 URL 作为参数,然后返回评论列表。
因为获取评论信息是需要登录的,所以务必要将自己的 cookid 添加到 headers 中,否则是爬取不到评论的。
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36',
'Referer': 'https://movie.douban.com',
# 注意,这里需要加上你自己的 cookie
'Cookie': '.'
}
def get_comment_by_url(url):
# 评论人,评论时间,评论星级以及评论内容
users,, times, stars, content_list = [], [], [], []
data = requests.get(url, headers=headers)
selector = etree.HTML(data.text)
comments = selector.xpath('//div[@class="comment"]')
# 遍历所有评论
for comment in comments:
user = comment.xpath('.//h3/span[2]/a/text()')[0]
star = comment.xpath('.//h3/span[2]/span[2]/@class')[0][7:8]
date_time = comment.xpath('.//h3/span[2]/span[3]/text()')
if len(date_time) != 0:
date_time = date_time[0].replace("\n", "").strip()
else:
date_time = None
comment_text = comment.xpath('.//p/span/text()')[0].strip()
users.append(user)
stars.append(star)
times.append(date_time)
content_list.append(comment_text)
return users, stars, times, content_list
接下来我们来分析下评论页面的 URL,如下所示:
https://movie.douban.com/subject/35155748/comments?start=40&limit=20&status=P&sort=new_score
每翻页一次,start 都会增加 20,最大值为 480,其中最后的参数 sort, 当 sort=new_score 表示按照热门来排序,也即是最热维度,当 sort=time 则表示根据时间来排序,也就是最新维度。
所以,我们可以使用以下函数来获取所有评论。
def get_comments():
user_list, star_list, time_list, comment_list = [], [], [], []
for sort in ['time', 'new_score']:
sort_name = "最热" if sort == 'new_score' else '最新'
for start in range(25):
print('准备抓取第 {} 页数据, 排序方式:{}'.format(start + 1, sort_name))
users, stars, times, comments = get_comment_by_url(base_url.format(start * 20, sort))
if not users:
break
user_list += users
star_list += stars
time_list += times
comment_list += comments
# 每次获取数据之后暂停 5 秒
time.sleep(5)
result = {'users': user_list, 'times': time_list, 'stars': star_list, 'comments': comment_list}
return result
来看看我们获取到的数据,因为我们是获取的热门和最新两个维度的数据,而最新维度数据不足 500 条,所以总的数据量也就是 600 条左右。

数据分析
如上,我们获取到了最终的数据,接下来就可以做数据分析了。
评论量
首先来看看评论和日期的关系,也就是统计下每一天的评论量,以下代我是在 Jupyter Notebook 中运行的。
bar = Bar()
bar.add_xaxis(index)
bar.add_yaxis("数量 & 时间", values)
bar.set_global_opts(xaxis_opts=opts.AxisOpts(name="评论日期", axislabel_opts={"rotate": 30}))
bar.render_notebook()
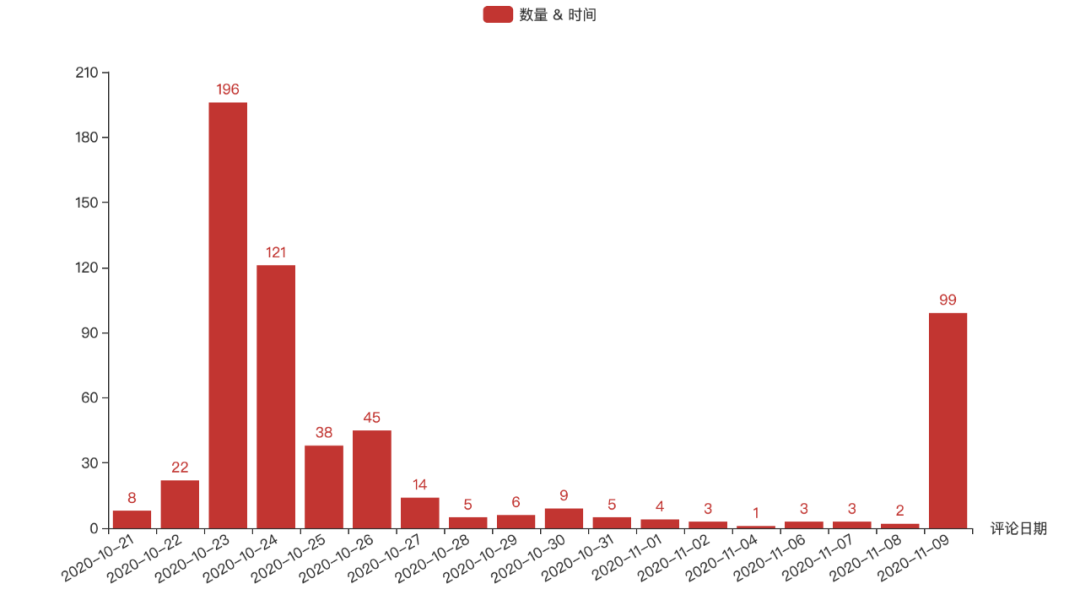
由上图可以看出,10.23 和 10.24 评论数量爆表,原因是该剧是 10.23 上映的,之后评论数量逐级递减,不过令人匪夷所思的是电影还未开始就已经有人开始刷评论了,难道这就是传说中的水军么。
评论星级
在来统计下评分和日期的关系,为了方便统计,我们取每天的平均评论星级。
# 星级
df_time = df.groupby(['times']).size()
dic = {}
for k in df_time.index:
stars = df.loc[df['times'] == str(k), 'stars']
stars = list(map(int, stars))
dic[k] = round(sum(stars) / len(stars), 2)
bar_star = Bar()
bar_star.add_xaxis([x for x in dic.keys()])
bar_star.add_yaxis("星级 & 时间", [x for x in dic.values()])
bar_star.set_global_opts(xaxis_opts=opts.AxisOpts(name="评论日期", axislabel_opts={"rotate": 30}))
bar_star.render_notebook()
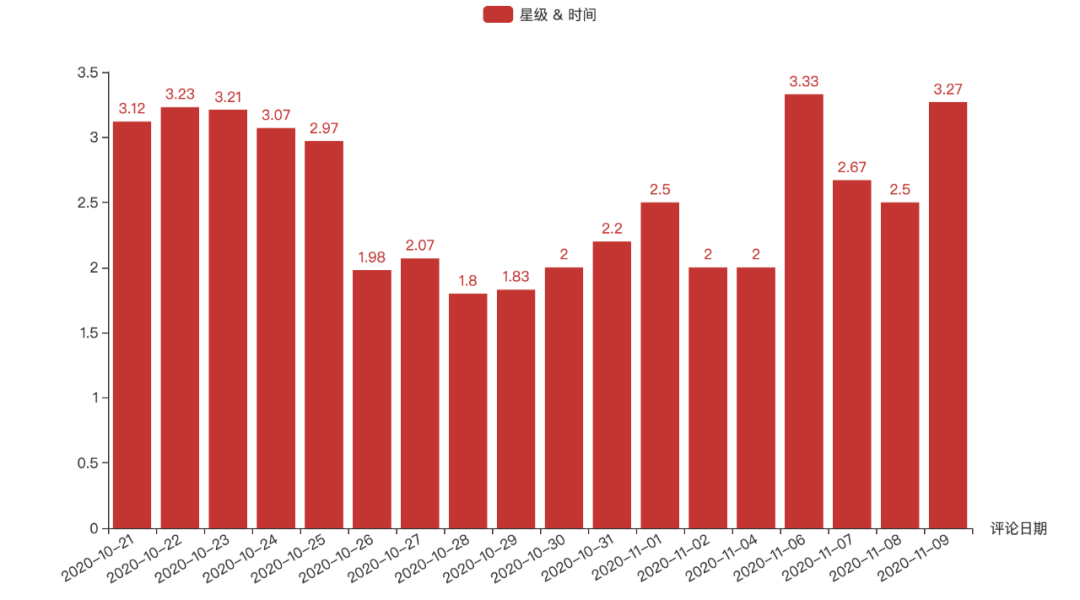
总体来看,该剧评论星级维持在 2.5~3.3 之间,结合 6.5 的评分来看,是比较吻合的。
演员
接下来我们分析下演员的受欢迎程度,实话讲我是冲着吴京去看的这部剧,来看看最终结果如何。
roles = {'张译':0, '吴京':0, '李九霄':0, '魏晨':0, '邓超':0}
names = list(roles.keys())
for row in df['comments']:
for name in names:
roles[name] += row.count(name)
line = (
Line()
.add_xaxis(list(roles.keys()))
.add_yaxis('', list(roles.values()))
.set_global_opts(title_opts=opts.TitleOpts(title=""))
)
line.render_notebook()
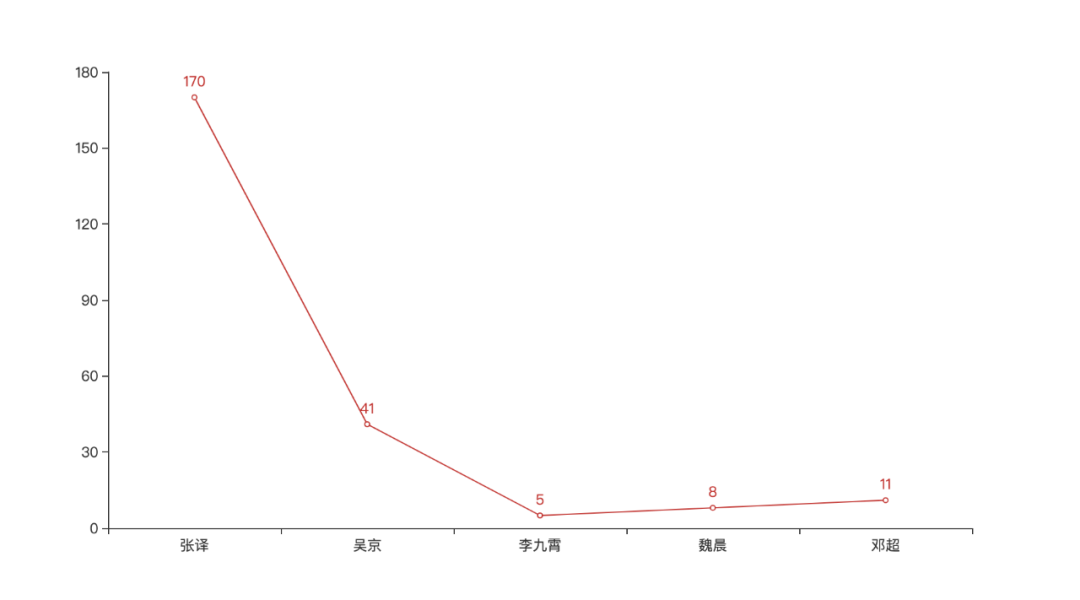
看来张译的受欢迎程度最高,毕竟实力派演员,相反吴京的票数反而不是很高,有点奇怪,得票最少的是李九霄。
词云
词云图可以更直观的看到每个词的出现频率,最后我们为这部剧生成它专属的词云图。
content = "".join(list(df['comments']))
# jieba 分词
words = jieba.cut(content)
word_list = []
for x in words:
word_list.append(x)
cloud_word = ','.join(word_list)
// 设置选项
wc = WordCloud(font_path='/System/Library/Fonts/PingFang.ttc', background_color="white", scale=2.5,
contour_color="lightblue", ).generate(cloud_word)
plt.figure(figsize=(16, 9))
plt.imshow(wc)
plt.axis('off')
plt.show()

果然还是张译出现的频率较高。
总结
本文通过获取「金刚川」的豆瓣影评对该剧做了一个定向分析,从结果可以看出大家评论星级和最终电影评分较吻合,演员张译最受大家欢迎,刚上映时大家的评论热情也最高,往后评论热情越来越低。
虽说该剧最终得分 6.5 实属不高,但这不应该是一部以分数高低来评价其好坏的电影,中国人民做了太多太多的牺牲和努力才换来了今天的和平盛世,甚至很多志愿军都永远的留在了那里,片尾的那段解放军接英雄们回家的片段真是让人感伤至极,愿英雄们都可以落叶归根,魂归故里。
愿山河无恙,家国梦圆!
PS:公号内回复「Python」即可进入Python 新手学习交流群,一起 100 天计划!
老规矩,兄弟们还记得么,右下角的 “在看” 点一下,如果感觉文章内容不错的话,记得分享朋友圈让更多的人知道!


【代码获取方式】