
Hadoop存储成本管理的具体方法
共 2117字,需浏览 5分钟
·
2020-09-05 14:06
Hadoop存储成本管理的具体方法
|0x00 数据压缩
数据压缩是在以Hadoop为主要构架的数据仓库中常见的数据处理方式,一方面适当的压缩数据,能够有效的提高MR计算任务时数据传输的效率,另一方面由于HDFS自身的三备份策略,导致数据存在比较大的冗余,通过压缩能够降低存储的成本。
在进行数据压缩前,需要考虑如下几方面的事情:
所采用的的压缩算法是否支持文件的分片读取,是否支持MR的并行读取;
压缩算法的I/O性能,是否能够提高磁盘的I/O读取效率;
压缩算法的读取性能,例如RCFile的读取速度明显快于写入速度,更适合频繁查询的数据场景;
算法是否具备共同性,HDFS主要以Writable为序列化格式,只支持Java、Avro、Thtift等格式。
目前Hadoop主要支持以下的数据类型:
1. SequenceFile:SequenceFile是基于文件的以二进制键值对形式存储的数据;
序列化格式:主要包括Facebook开发的Thrift框架、Hadoop创始人开发的Avro框架;
列式存储:以Google的Parquet格式和RCFile为主,弥补了HDFS系统查询速度较低的缺陷,通过只返回相关的查询列,以减少I/O消耗并提升查询性能。
目前Hadoop中常见的压缩算法有:
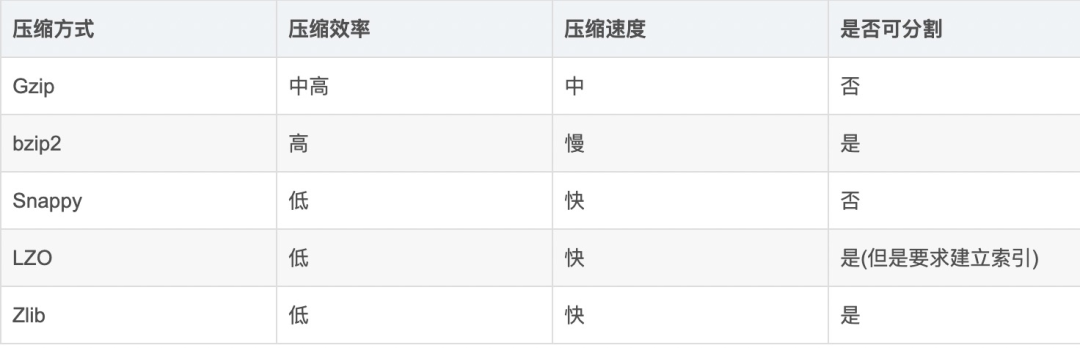
Snappy:Google开发的高速压缩算法,不支持分片,需要与SequenceFile等容器一起使用;
LZO:最常见的压缩算法,压缩速率与Snappy相近,支持分片,但需要建立索引;
Gzip:Linux自带的压缩算法,压缩速率是Snappy的2.5倍左右,但写入相对较慢,同样不支持分片;
4. bzip2:压缩性能更优秀,需要花费较长的时间读取,因为支持数据分片,因而也经常使用。
以上四种压缩算法的对比如下:
|0x01 数据的生命周期管理
数据仓库的存储成本管理主要基于元数据平台负责的生命周期管理,从数据的使用价值、查询性能、更新频率等方向综合考虑,以最大程度上减少数据的存储成本。目前常见的数据生命周期管理策略有如下几种:
周期性删除:绝大部分的数据都是以数据表的形式进行存储,并且通过日期分区的方式加以区分,因而针对一些日期过早的存储分区,例如存储时间超过一年,如果已经没有特别大的使用价值,建议设定定时删除脚本以节约存储效率;
彻底删除:对于一些因为ETL过程或者是临时查询等形式的数据表,可以统一建立在Tmp或Test分区下,定期清空分区数据;
冷热数据区分:冷数据是指时间较早且不常使用的数据,热数据是指经常查询和使用的数据,对于一些重要且不常使用的数据,建议通过标记冷分区的方式,采用极限压缩算法进行存储,尽管再次计算需要花费比较长的时间,但整体看下来依旧比较划算;
永久保留:尽管数据是无限增长的,但高业务价值的数据仍然需要永久保留,假设数据量非常大,可以设置冷热数据分区的方式,将不常用的分区数据用极限压缩算法进行存储;
增量表合并全量表:对于特定业务的数据,可以将保存每天新增数据的增量表,与历史累积的全量表进行合并,以节省存储空间。
|0x02 数据存储专项优化
设定数据评价等级:一般数据可以通过业务重要程度及计算关联范围两个维度,设定多个评价等级,例如最高等级为业务重要及关联广泛,最低等级为业务不重要且无关联;
数据表类型划分:以阿里系的数据仓库体系为例,数据表可以划分为事件型流水表(增量表)、事件型镜像表(增量表)、维表、Merge全量表、ETL临时表、TT临时数据及普通全量表,根据表类型的不同,配合数据评价等级,就能够设定不同的历史数据处理策略;
元数据平台经常性扫描:包括标记没有管理员的表、空表、最近长时间未访问表、数据无更新表、数据无配属任务表、数据量过大表等,根据系统自动扫描的结果,通知对应的数据负责人,提高数据管理的效率,同时,元数据平台根据平台整理情况,可以定期生成存储成本统计图,提醒上级Boss目前的成本管理情况;
提倡个人数据管理:在数据地图等平台上,开发及产品创建或使用数据表,都需要申请对应的权限,并根据自己创建的表,来自动计算对应数据的存储成本,如果不是数据开发人员的,当个人名下的数据存储成本过高时,需要及时的提醒删除,能够从人员管理的层面上极大的节省存储成本。
|0xFF 尾声
--end--
