
Pandas的26个统计汇总函数实战案例。
统计汇总函数中的26个函数。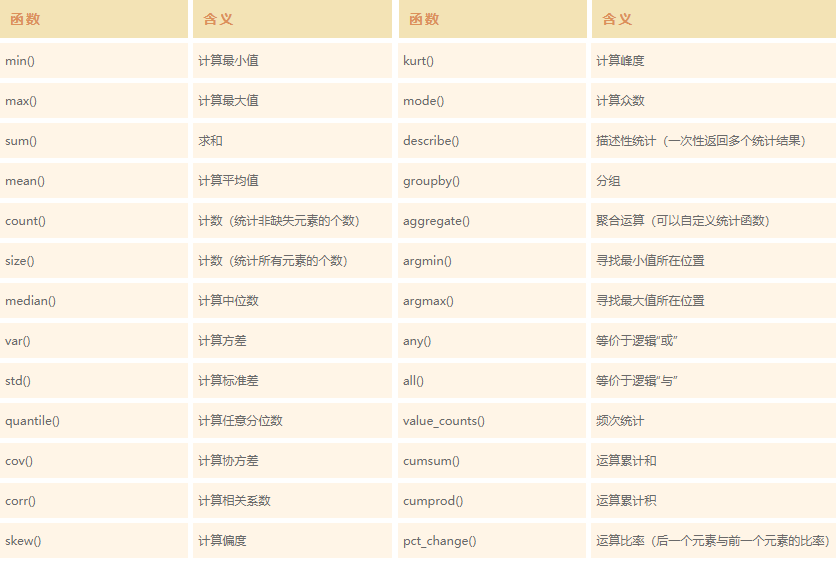
import numpy as np
import pandas as pd
data = [[1, 2, np.nan], [2, np.nan, 3], [7, 8, 9], [3, 4, 5]]
date_range = pd.date_range(start="20180701", periods=4)
df1 = pd.DataFrame(data=data, index=date_range,
columns=['a', 'b', 'c'])
df1
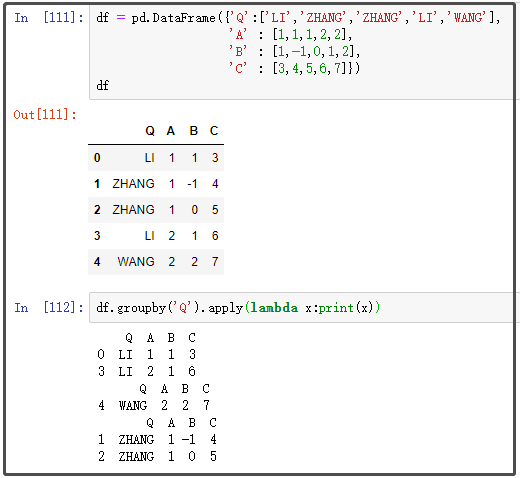
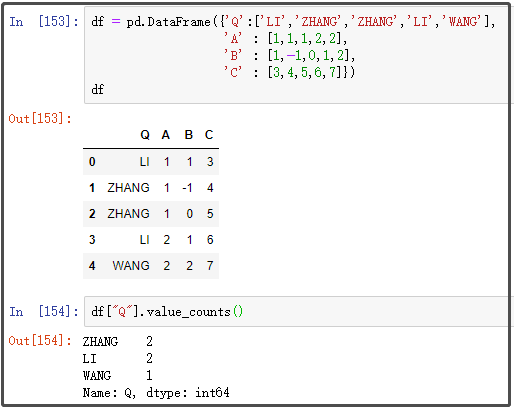
df2 = pd.DataFrame({'Q':['LI','ZHANG','ZHANG','LI','WANG'],
'A' : [1,1,1,2,2],
'B' : [1,-1,0,1,2],
'C' : [3,4,5,6,7]})
df2
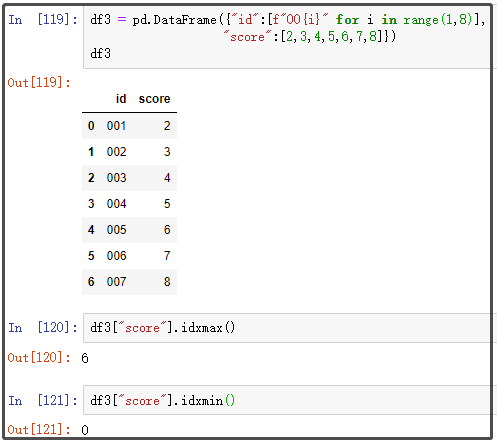
df3 = pd.DataFrame({"id":[f"00{i}" for i in range(1,8)],
"score":[2,3,4,5,6,7,8]})
df3
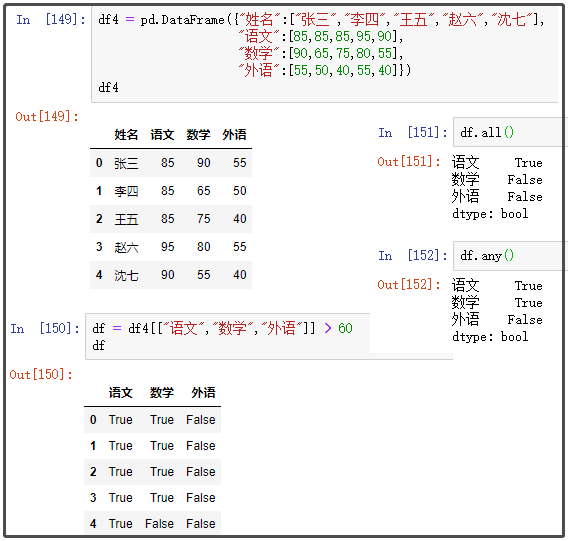
df4 = pd.DataFrame({"姓名":["张三","李四","王五","赵六","沈七"],
"语文":[85,85,85,95,90],
"数学":[90,65,75,80,55],
"外语":[55,50,40,55,40]})
df4
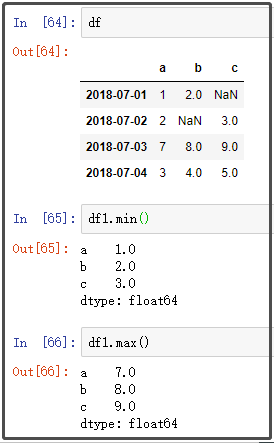
1. max和min
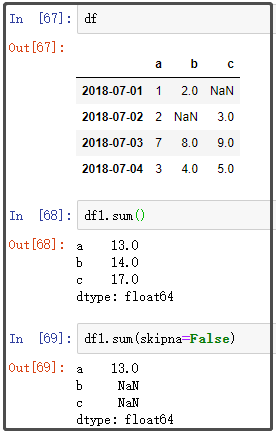
2. sum
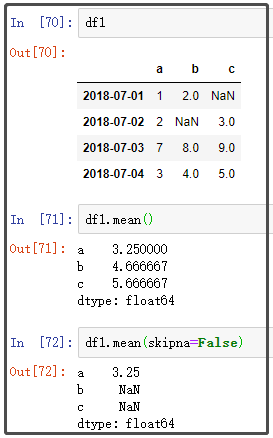
3. mean
4. count
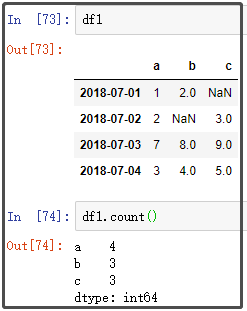
5. size
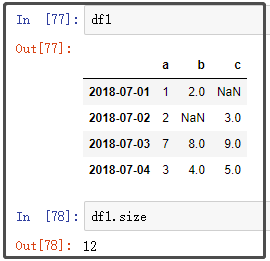
6. median
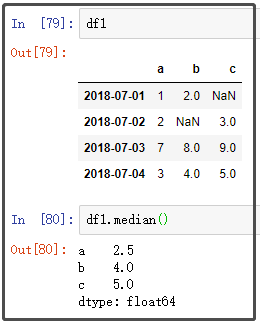
7. var
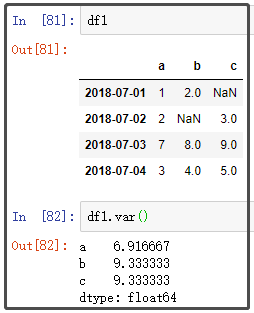
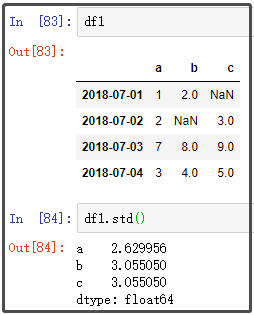
8. std
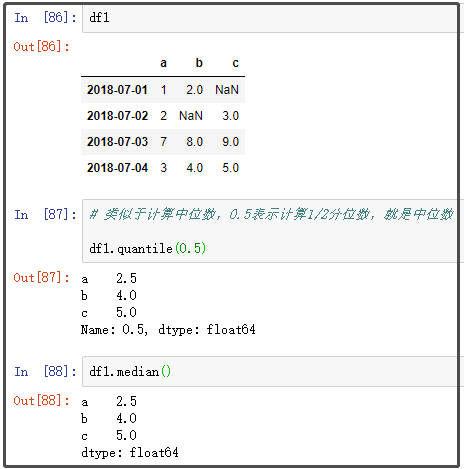
9. quantile
10. mode

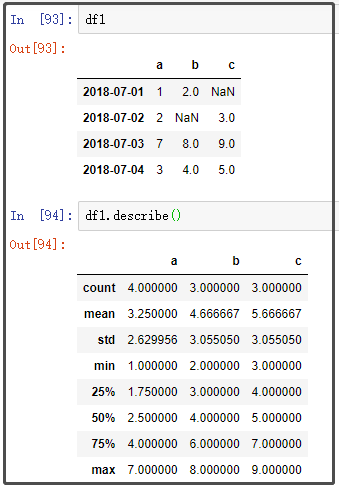
11. describe
12. groupby、aggregate

13. argmin、argmax
14. any、all
15. value_counts
16. cumsum、cumprod

17. pct_change






评论