
有趣的 Python 图片制作,用 QQ 好友头像拼接出里昂
在本篇文章中,我们将实现两个功能:
将所有头像合并为大图
将所有头像以某个模板合成大图
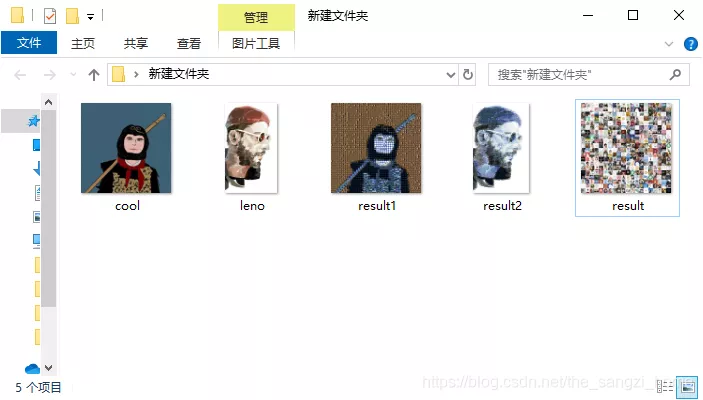
同样,先给上所有运行效果图:
代码实现
1、代码所需库
import requests,codecs,re,urllib,os,random,math
from PIL import Image
import numpy as np
import cv2 as cv
2、代码讲解
2.1、将小头像合并为大图
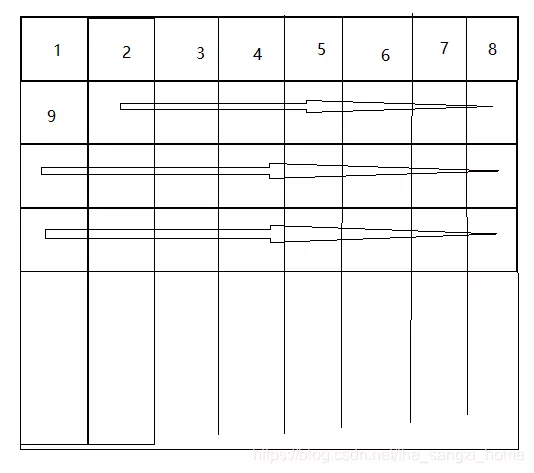
对于这个,就是直接将每个小头像贴在大图上就行了,这个利用Image的paste函数就可以解决。对于贴的顺序就可以直接按照下面图示一个个贴:
所以,直接给出代码:
def simple_split(filepackage,size,littlesize): #简单拼接,参数为图片文件名,每行每列的size,小头像图片的大小
row = size[0]
col = size[1]
bigimg = Image.new('RGBA',(littlesize*row,littlesize*col)) #结果图
number = 0
for i in range(row): #行
for j in range(col): #列
randpic = random.randint(1,friends_count)
img = Image.open(filepackage+str(randpic)+'.png').convert('RGBA')
img = img.resize((littlesize,littlesize))
loc = (i*littlesize,j*littlesize,(i+1)*littlesize,(j+1)*littlesize)
print(loc,number)
number+=1
bigimg.paste(img,loc)
bigimg.save(resultSavePath)
由于好友不多,所以我们每次就随机选择一个好友头像贴上去,所以如果你的密度大的话最后出现的头像有很多重复的头像。
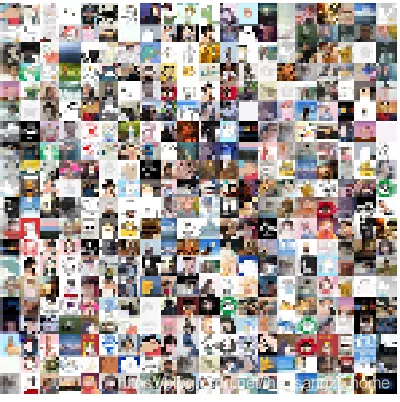
给大家展示下最后我的图片吧:
2.2、以某个图片为模板拼接图片
由于不清楚有没有能够直接做出来的第三方库,所有我就自己造了个小轮子。
思路:
将模板分为A x B的小图,就将它的位置形容为 pic[i][j] 吧,然后获取每个小图的平均RGB值,将 pic[i][j] 的平均RGB值和好友头像的RGB值做对比,找出最接近的头像,然后将该头像插入在图像的 pic[i][j] 处。
思路还是比较简单吧😀
接下来就是实现了:代码很多地方都给出了注释,我就不多讲了,直接给出代码:
import requests,codecs,re,urllib,os,random,math
from PIL import Image
import numpy as np
import cv2 as cv
txtpath = 'C:/Users/11037/Desktop/test/qqfriends.txt' #你从QQ邮箱中粘贴的文件
savepath = 'C:/Users/11037/Desktop/touxiang/' #头像存储位置
resultSavePath = 'C:/Users/11037/Desktop/result2.png' #结果存储位置
modePath = 'C:/Users/11037/Desktop/leno.jpg' #模板存储位置
friends_count = 0 #好友数量
all_mean_rgbs = [] #存储计算出的所有平均rgb值
def meanrbg(img): #计算图片平均rgb
rgb = np.array(img)
r = int(round(np.mean(rgb[:, :, 0])))
g = int(round(np.mean(rgb[:, :, 1])))
b = int(round(np.mean(rgb[:, :, 2])))
return (r,g,b)
def gettouxiang(txtpath):#输入你的txt文件存储位置
file = codecs.open(txtpath,'rb','utf-8')
s = file.read()
pattern = re.compile(r'\d+@qq.com')
all_mail = pattern.findall(s) #正则表达式匹配所有的qq号
all_link = [] #用于存储需要访问的链接
url = 'http://qlogo.store.qq.com/qzone/'
for mail in all_mail:
qq = mail.replace('@qq.com','')
l = url + qq +'/'+qq+'/100'
all_link.append(l)
i = 1
for link in all_link: #遍历链接,下载头像
saveurl = savepath+str(i)+'.png'
savaImg(link,saveurl)
i +=1
print('已下载',i)
friends_count = len(all_link) #获取朋友头像数量
return True
def savaImg(picurl,saveurl): #存储图片函数,picurl是图片的URL,saveurl是本地存储位置
try:
bytes = urllib.request.urlopen(picurl)
file = open(saveurl,'wb')
file.write(bytes.read())
file.flush()
file.close()
return True
except:
print('worry')
savaImg(picurl,saveurl)
def simple_split(filepackage,size,littlesize): #简单拼接,参数为图片文件名,每行每列的size,小头像图片的大小
row = size[0]
col = size[1]
bigimg = Image.new('RGBA',(littlesize*row,littlesize*col))
number = 0
for i in range(row):
for j in range(col):
randpic = random.randint(1,friends_count)
img = Image.open(filepackage+str(randpic)+'.png').convert('RGBA')
img = img.resize((littlesize,littlesize))
loc = (i*littlesize,j*littlesize,(i+1)*littlesize,(j+1)*littlesize)
print(loc,number)
number+=1
bigimg.paste(img,loc)
bigimg.save(resultSavePath)
def mode_split(filepackage,modepath,bigsize,littlesize): #以模板存储头像
row = bigsize[0] #大图每行多少个小头像
col = bigsize[1] #每列
suitSize = (littlesize*row,littlesize*col) #大图最终的像素size
bigImg = Image.open(modepath)
bigImg = bigImg.resize(suitSize)
resultImg = Image.new('RGBA',suitSize)
for i in range(row):
for j in range(col):
cutbox = (i*littlesize,j*littlesize,(i+1)*littlesize,(j+1)*littlesize) #模板剪切用于对比的某个区域
cutImg = bigImg.crop(cutbox) #复制到cutImg中
tmprgb = meanrbg(cutImg)
suitOne = mostSuitImg(tmprgb) + 1 #对比出最合适的头像
img = Image.open(filepackage + str(suitOne) + '.png').convert('RGBA')
img = img.resize((littlesize,littlesize))
resultImg.paste(img,cutbox)
print('已粘贴',cutbox)
resultImg.save(resultSavePath) #存储
def mostSuitImg(tmprgb): #进行对比,找出最合适的头像
global all_mean_rgbs
minRange = 200000
id = 0
for rgb in all_mean_rgbs:
tmp = (rgb[1][0]-tmprgb[2])**2+(rgb[1][1]-tmprgb[1])**2+(rgb[1][2]-tmprgb[1])**2
if tmp<minRange:
minRange = tmp
id = rgb[0]
return id
if __name__ == '__main__':
# gettouxiang(txtpath) #获取头像,如果已经获取就可以给注释掉了
# simple_split(savepath,(20,20),30) #简单拼接
#模板拼接
for i in range(1,friends_count+1):
img = cv.imread(savepath+str(i)+'.png')
rgb = meanrbg(img)
all_mean_rgbs.append(rgb)
all_mean_rgbs = list(enumerate(all_mean_rgbs)) #给列表增加一个索引
mode_split(savepath,modePath,(50,80),20) #模板拼接
给大家看看最终的效果:

这样一看还是都不错是吧。哈哈。
再给出里昂的模板和最终成果:


添加【修改后的Leon】:

我默认将每个头像以数字命名,可以便于后续的操作。
同时,以上代码都进行了封装,很多函数都可以独立使用,用于满足不同的功能。可以自己读完代码进行改写实现自己需要的功能,比如说以上我默认头像图片都是正方形,你如果图片有长方形的改变下代码也可以满足。
理论上来说,你的好友头像越多,制作出来的图片与模板的差异也就越小。以mode_split这个函数为例,你设置的bigsize越大,你的图片也就越清晰。
评论