
ZooKeeper系列文章:ZooKeeper 源码和实践揭秘(三)


导语
ZooKeeper 是个针对大型分布式系统的高可用、高性能且具有一致性的开源协调服务,被广泛的使用。对于开发人员,ZooKeeper 是一个学习和实践分布式组件的不错的选择。本文对 ZooKeeper 的源码进行简析,也会介绍 ZooKeeper 实践经验,希望能帮助到 ZooKeeper 初学者 。文章部分内容参考了一些网络文章,已标注在末尾参考文献中。

ZooKeeper简介
1. 初衷
2.目标读者
本文是介绍 ZooKeeper 基础知识和源码分析的入门级材料,适合用于初步进入分布式系统的开发人员,以及使用 ZooKeeper 进行生产经营的应用程序运维人员。
Zookeeper系列文章介绍
第 1 篇:主要介绍 ZooKeeper 使命、地位、基础的概念和基本组成模块,以及 ZooKeeper 内部运行原理,此部分主要从书籍《ZooKeeper 分布式过程协同技术详解》摘录,对于有 ZooKeeper 基础的可以略过。坚持主要目的,不先陷入解析源码的繁琐的实现上,而是从系统和底层看 ZooKeeper 如何运行,通过从高层次介绍其所使用的协议,以及 ZooKeeper 所采用的在提高性能的同时还具备容错能力的机制。
服务端的线程
客户端
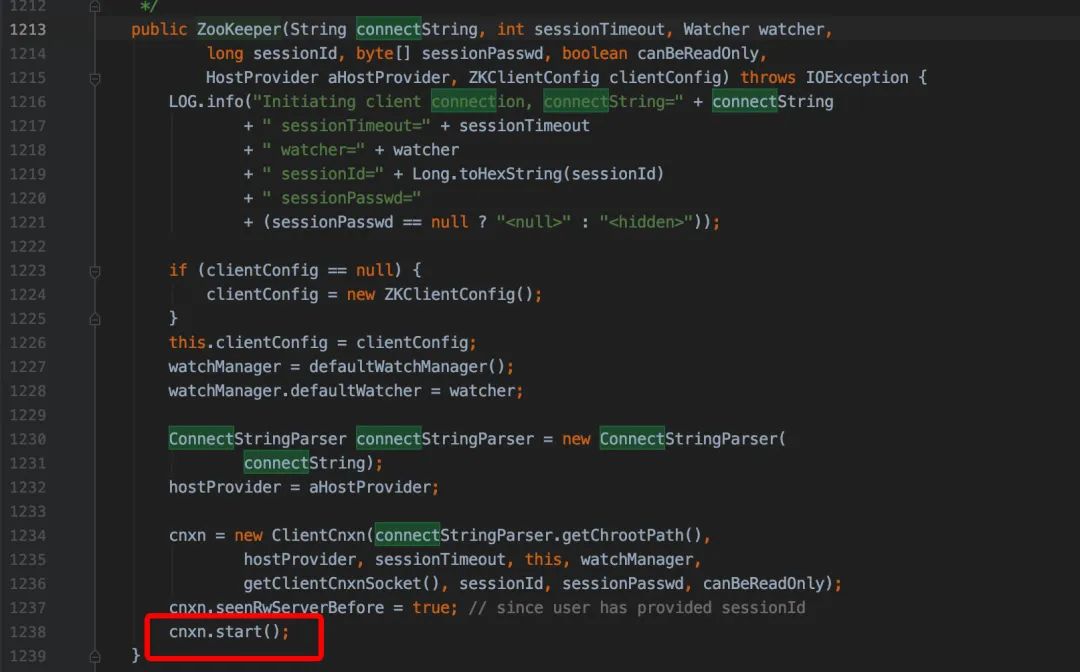
从整体看,客户端启动的入口时 ZooKeeperMain,在 ZooKeeperMain 的 run()中,创建出控制台输入对象(jline.console.ConsoleReader),然后它进入 while 循环,等待用户的输入。同时也调用 connectToZK 连接服务器并建立会话(session),在 connect 时创建 ZooKeeper 对象,在 ZooKeeper 的构造函数中会创建客户端使用的 NIO socket,并启动两个工作线程 sendThread 和 eventThread,两个线程被初始化为守护线程。
sendThread 的 run()是一个无限循环,除非运到了 close 的条件,否则他就会一直循环下去,比如向服务端发送心跳,或者向服务端发送我们在控制台输入的数据以及接受服务端发送过来的响应。
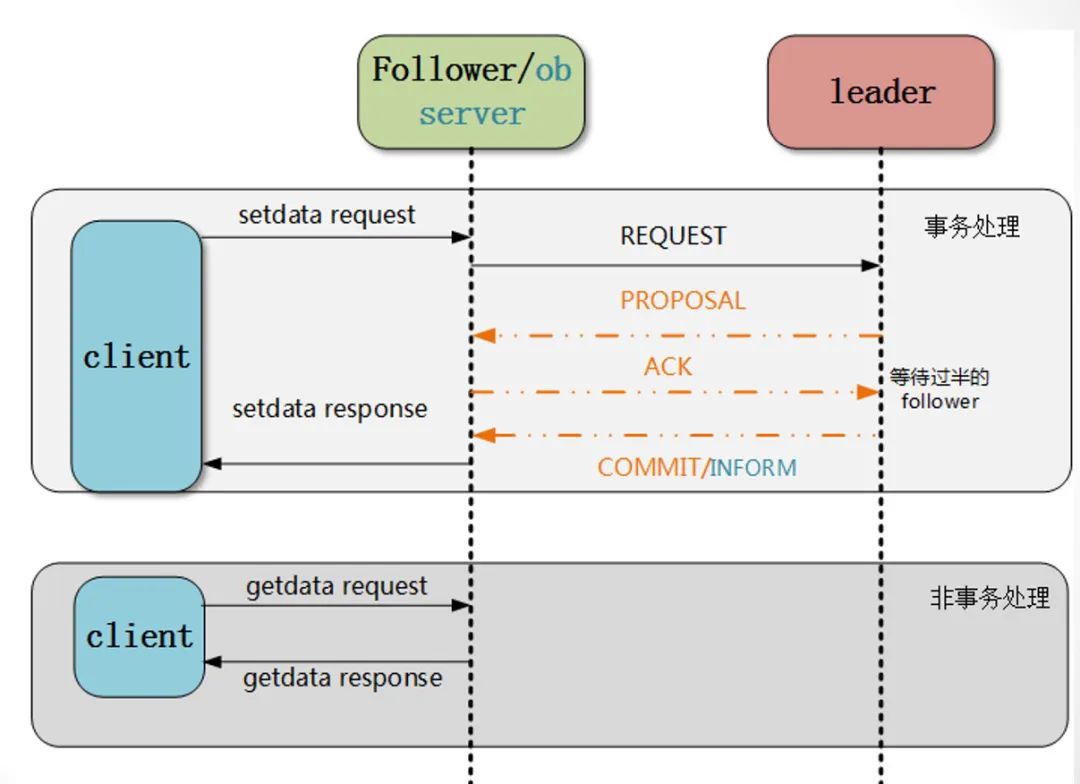
客户端的场景说明(事务、非事务请求类型)。
客户端源码解析
ZooKeeperMain 初始化
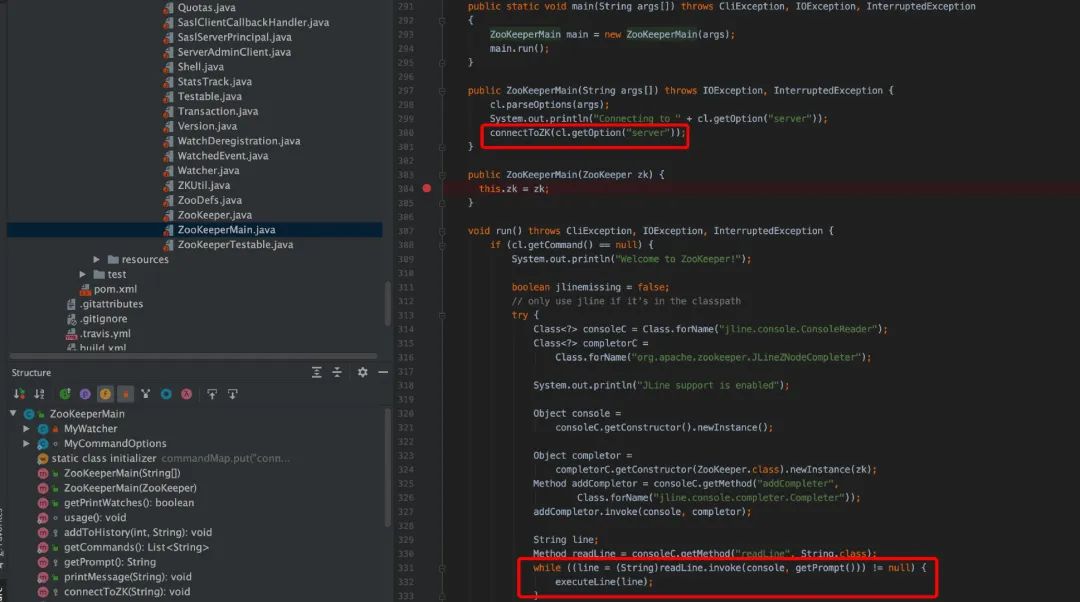
ZooKeeper 的构造函数,cnxn.start()会创建 sendThread 和 eventThread 守护线程。
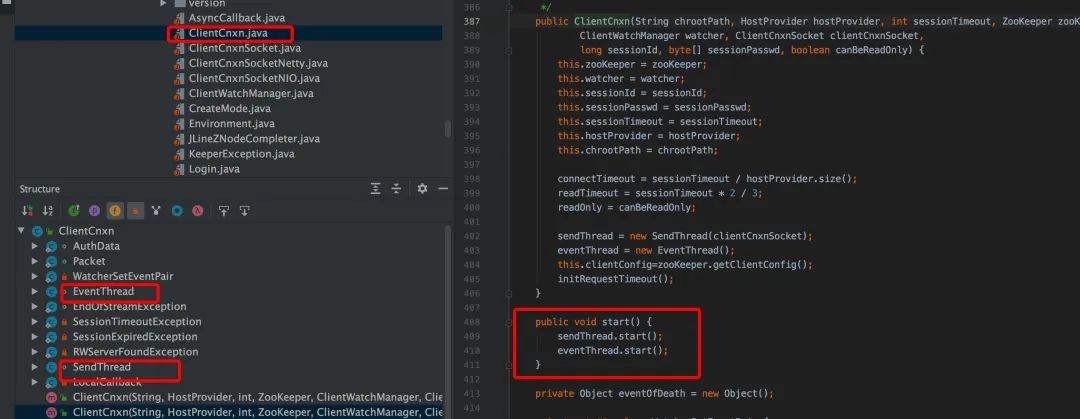
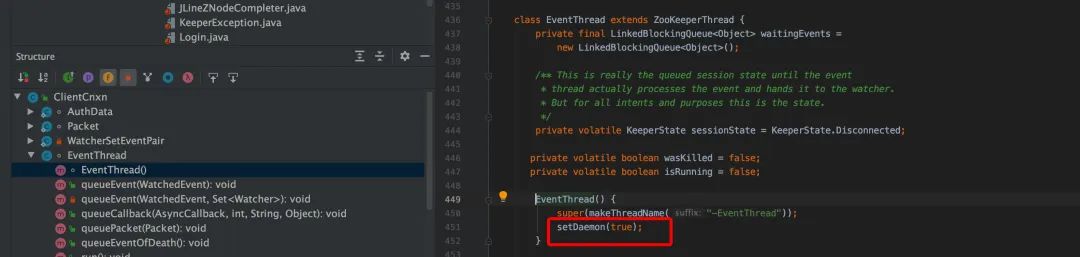

在 ClientCnxn.java 中,有两个重要的数据结构。
/**
* These are the packets that have been sent and are waiting for a response.
*/
private final LinkedList pendingQueue = new LinkedList();
/**
* These are the packets that need to be sent.
*/
private final LinkedBlockingDeque
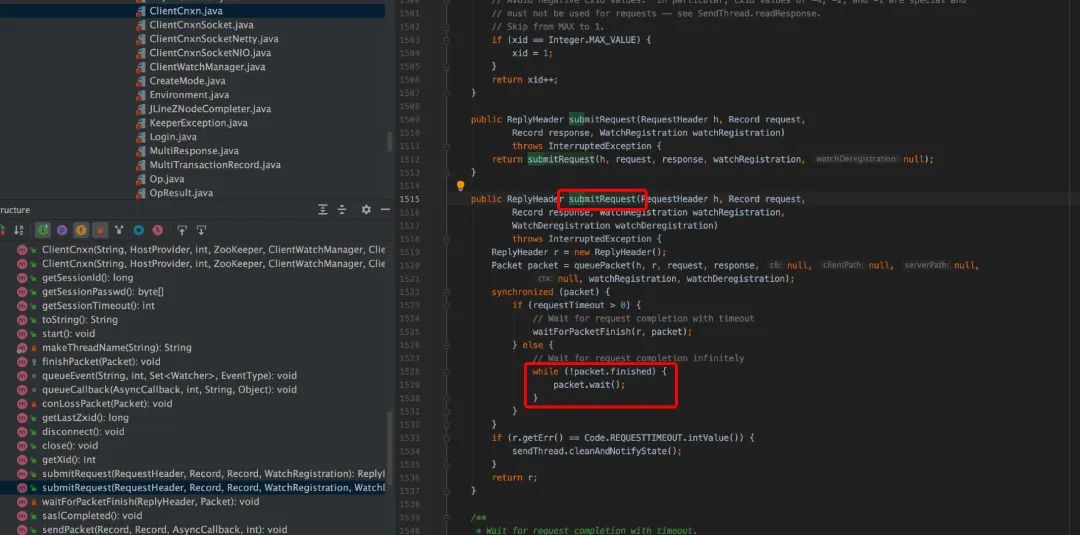
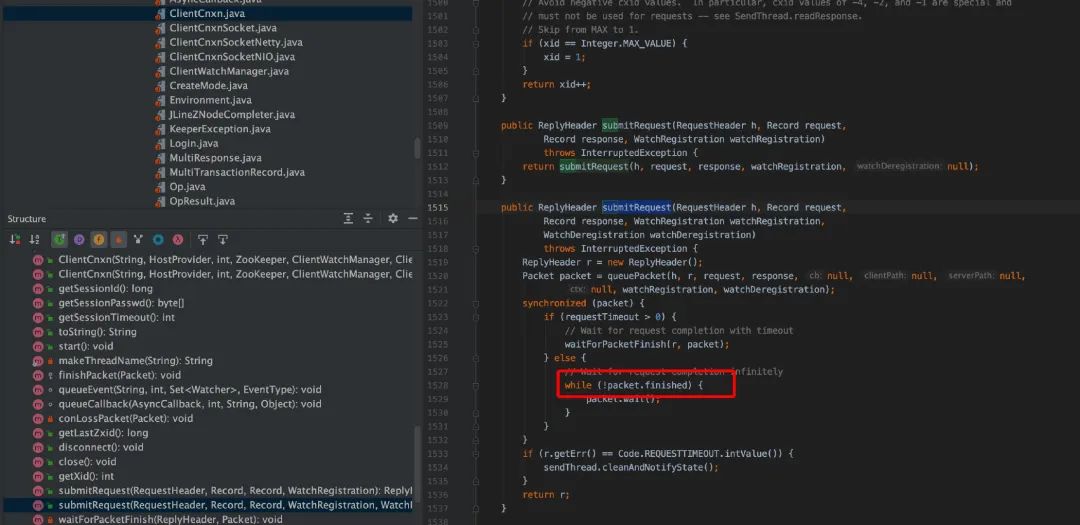
ZooKeeper 类中的对用户的输入参数转换为对 ZK 操作,会调用 cnxn.submitRequest()提交请求,在 ClientCnxn.java 中会把请求封装为 Packet 并写入 outgoingQueue,待 sendThread 线程消费发送给服务端,对于同步接口,调用 cnxn.submitRequest()会阻塞,其中客户端等待是自旋锁。
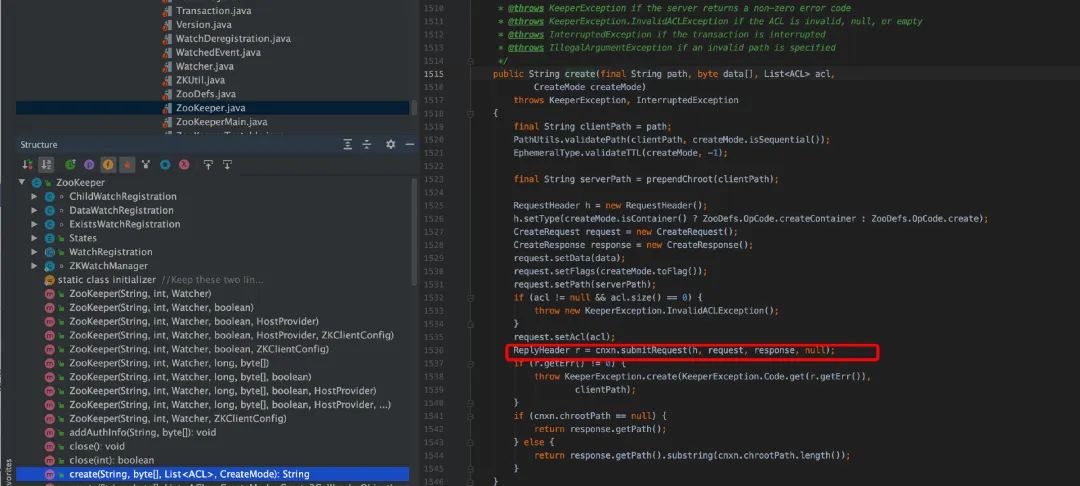
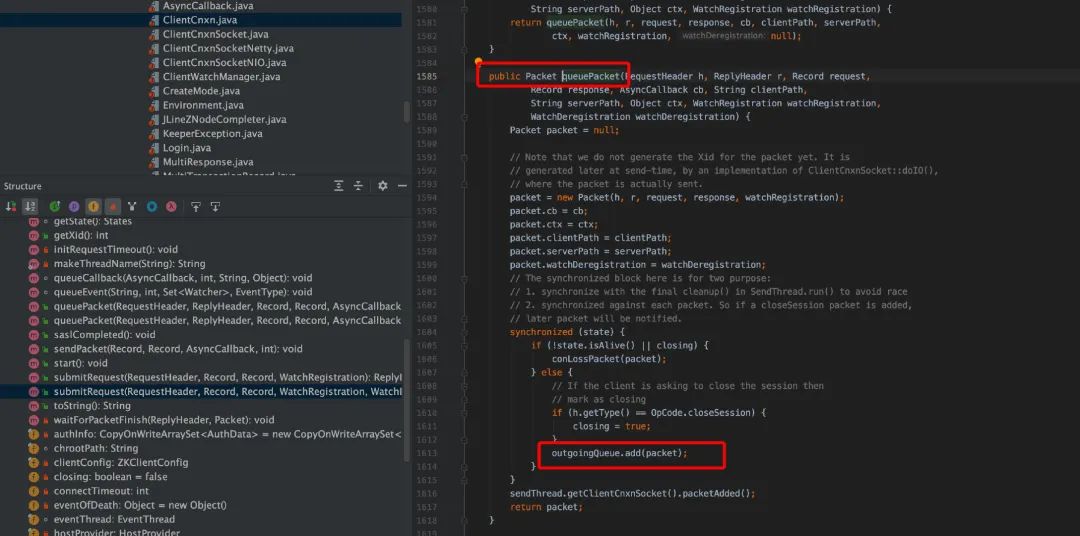
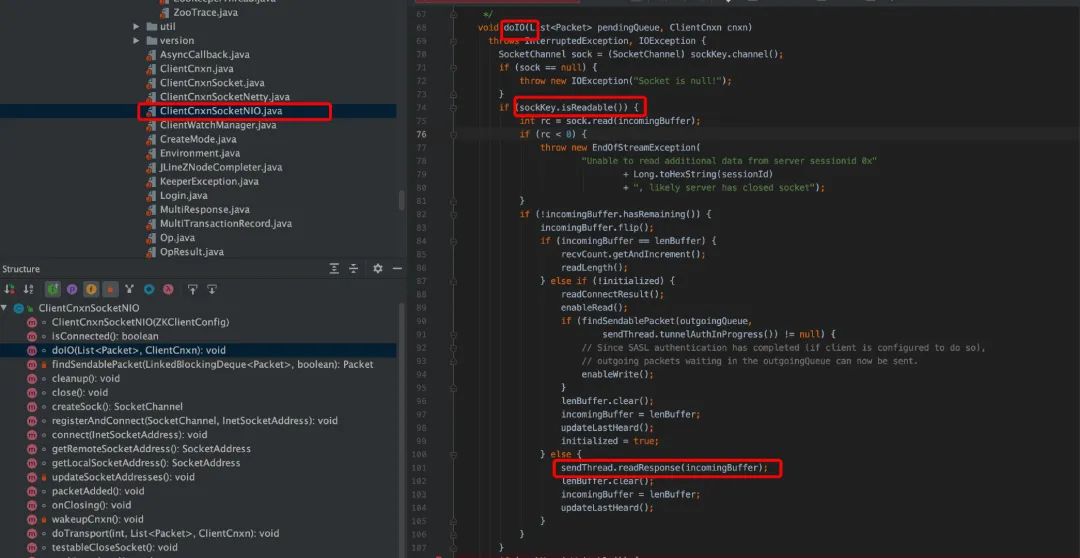
ClientCnxnSocketNIO.java 主要是调用 dcIO(), 其中读就绪,读取服务端发送过来的数据,写就绪, 往客户端发送用户在控制台输入的命令。
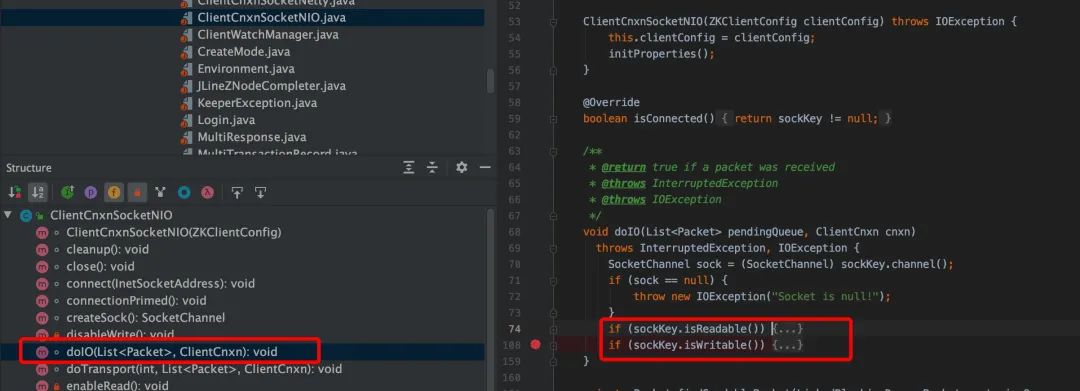
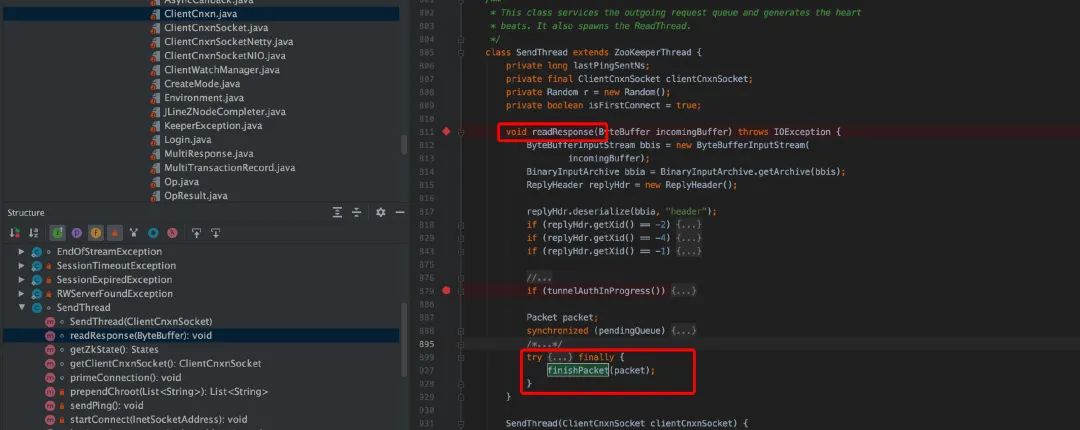
从上面源码看,客户端在 cnxn.submitRequest(),会自旋等待服务端的结果,直到 Packet 的 finished 被设置为 true。ClientCnxnSocketNIO.java 调用 dcIO(),read 逻辑中,会调用 sendThread.readResponse(), 在 sendThread.readResponse()函数中的 finally 中调用 finshPacket()设置 finished 为 true,进而客户端阻塞解除,返回结果。
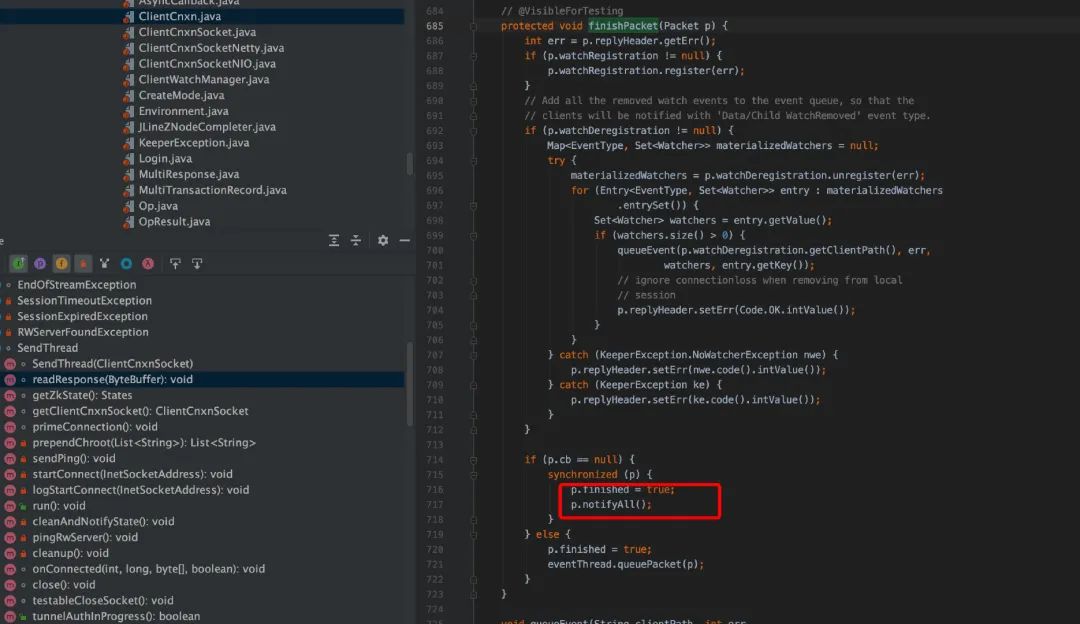
扩展阅读:
https://www.cnblogs.com/ZhuChangwu/p/11587615.html
服务端和客户端结合部分
会话(Session)
服务端启动,客户端启动; 客户端发起 socket 连接; 服务端 accept socket 连接,socket 连接建立; 客户端发送 ConnectRequest 给 server; server 收到后初始化 ServerCnxn,代表一个和客户端的连接,即 session,server 发送 ConnectResponse 给 client; client 处理 ConnectResponse,session 建立完成。
在 clientCnxn.java 中,run 是一个 while 循环,只要 client 没有被关闭会一直循环,每次循环判断当前 client 是否连接到 server,如果没有则发起连接,发起连接调用了 startConnect。
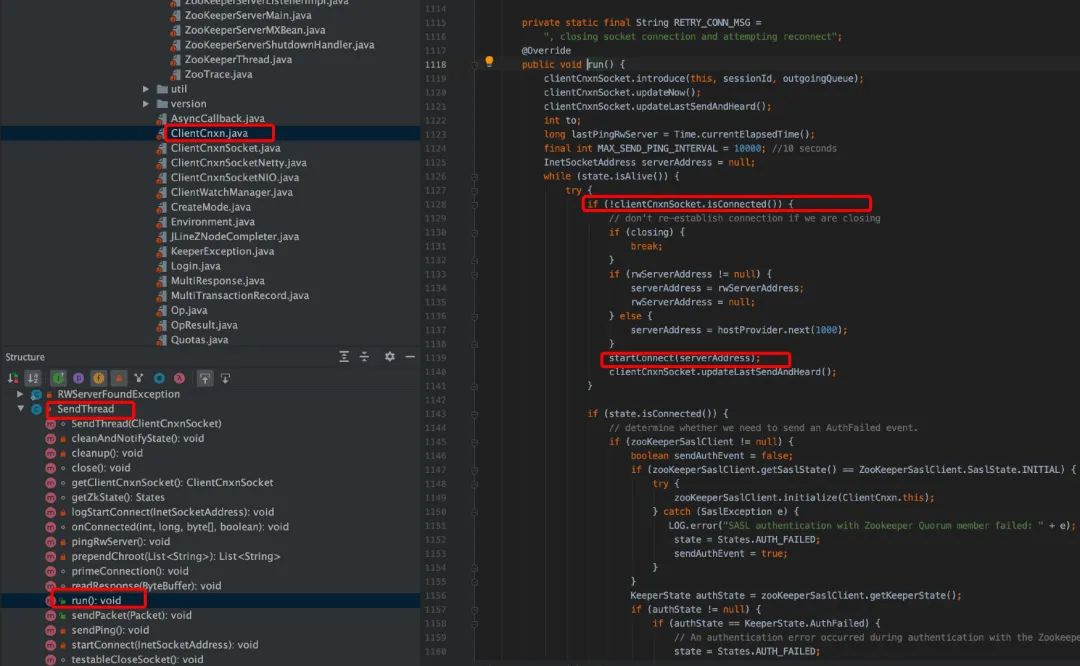
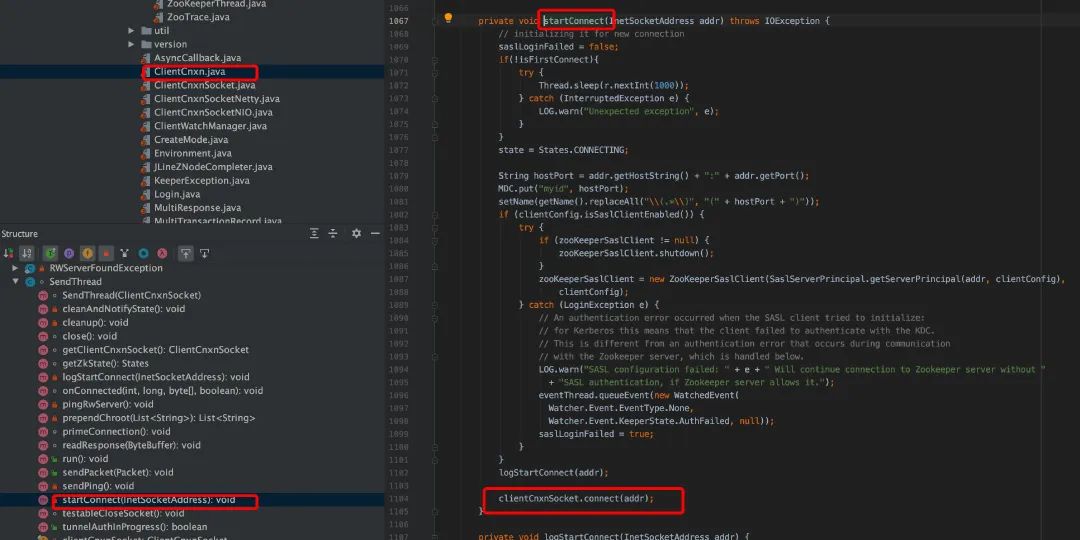
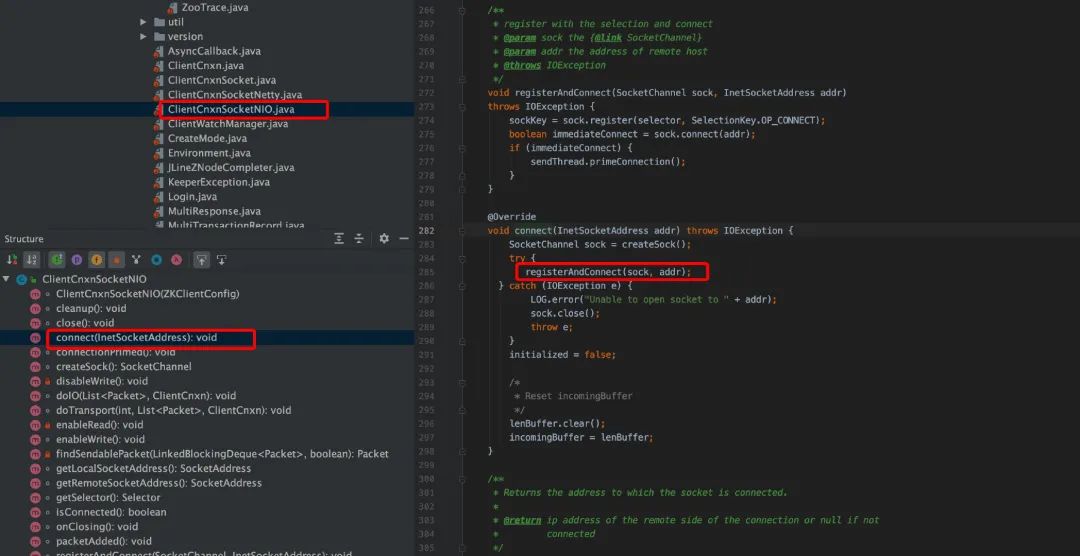
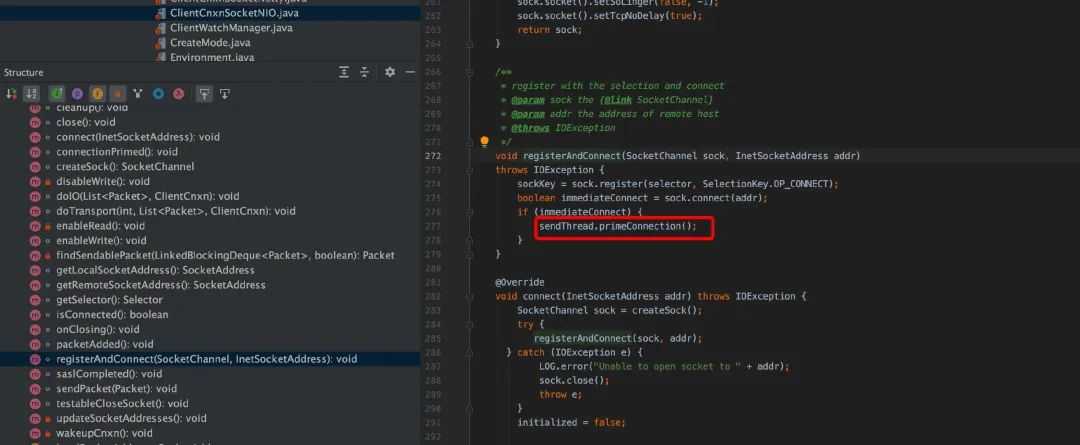
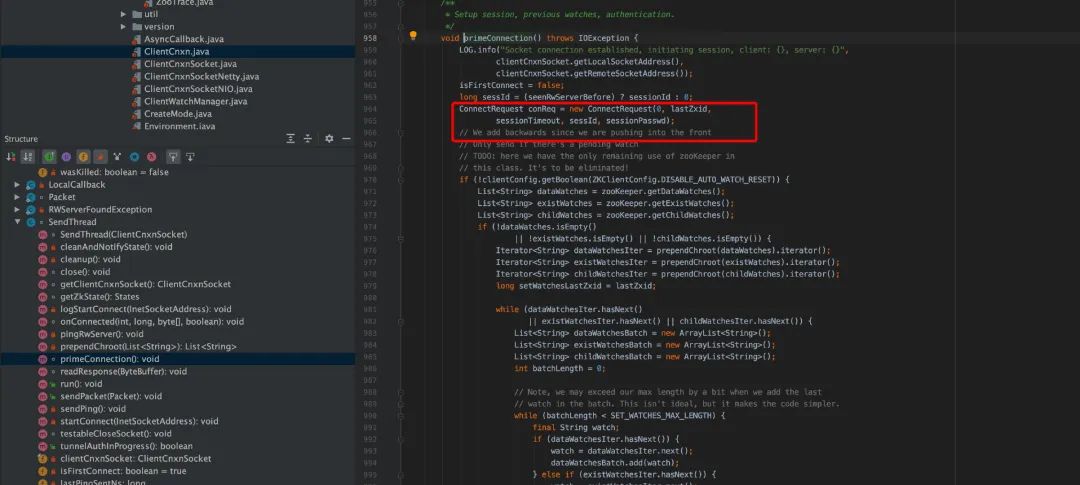
在 connect 是,传递了如下参数,
lastZxid:上一个事务的 id; sessionTimeout:client 端配置的 sessionTimeout; sessId:sessionId,如果之前建立过连接取的是上一次连接的 sessionId sessionPasswd:session 的密码;
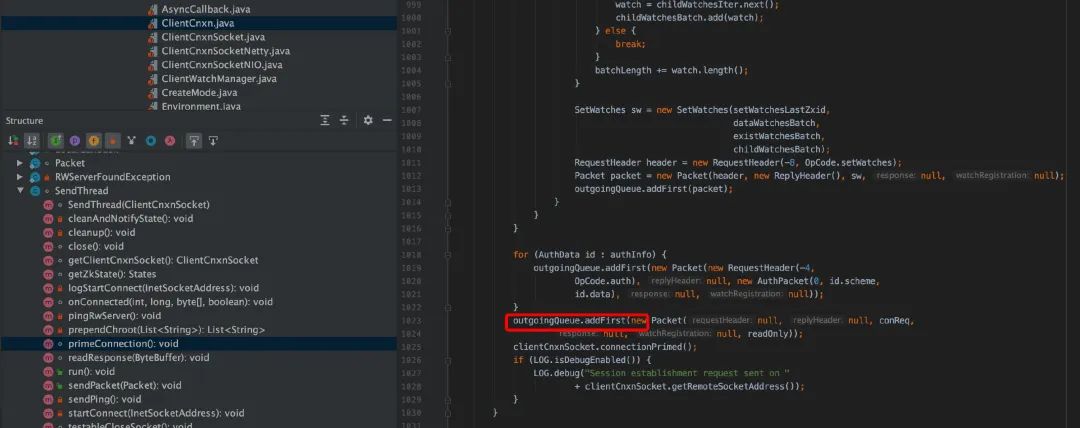
服务端源码分析
server 在启动后,会暴露给客户端连接的地址和端口以提供服务。我们先看一下NIOServerCnxnFactory,主要是启动三个线程。
AcceptThread:用于接收 client 的连接请求,建立连接后交给 SelectorThread 线程处理
SelectorThread:用于处理读写请求
ConnectionExpirerThread:检查 session 连接是否过期
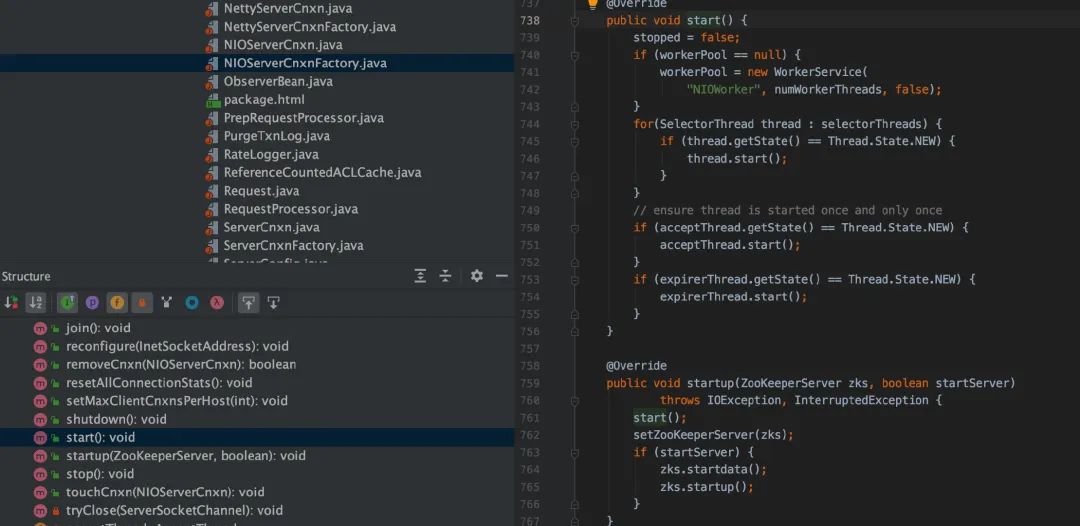
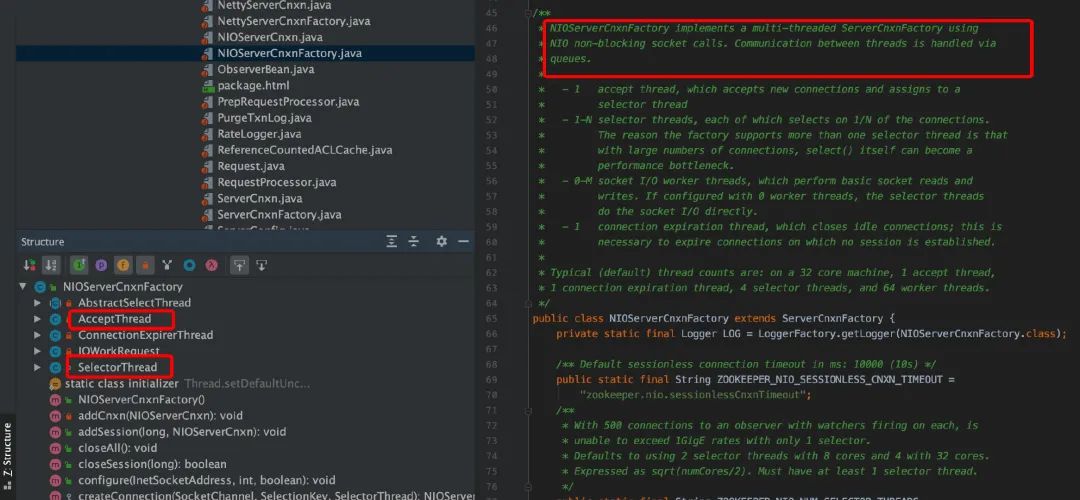
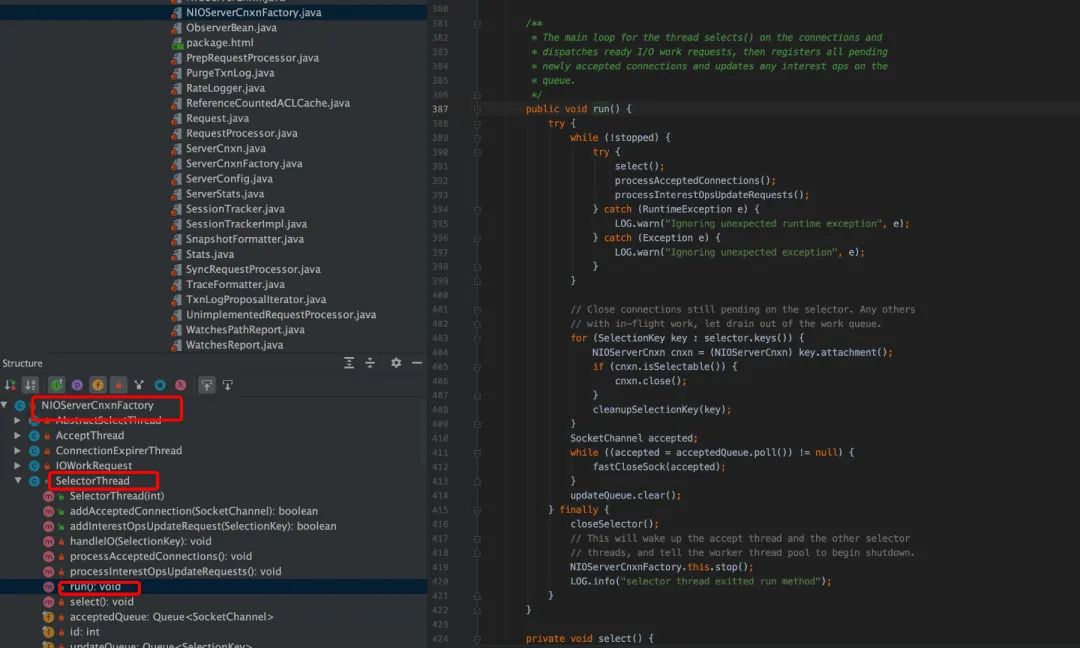
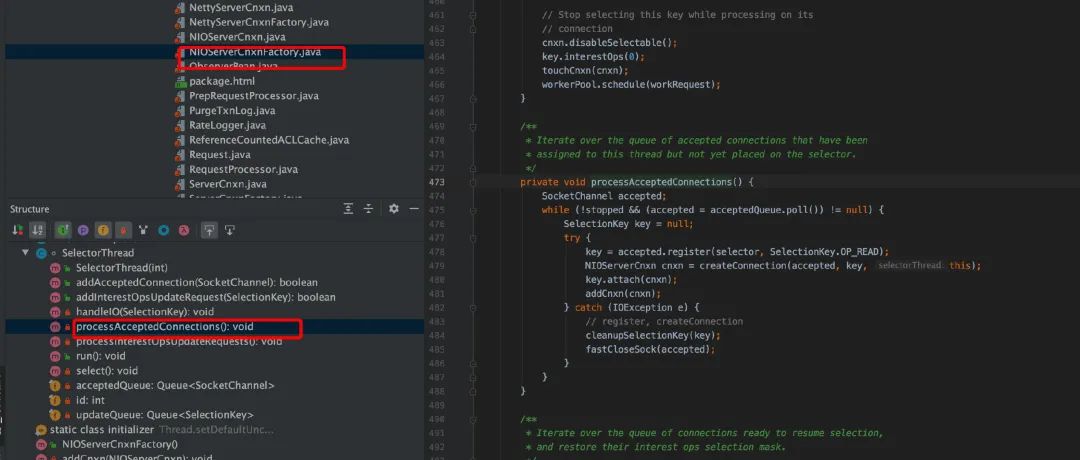
client 发起 socket 连接的时候,server 监听了该端口,接收到 client 的连接请求,然后把建立练级的 SocketChannel 放入队列里面,交给 SelectorThread 处理。
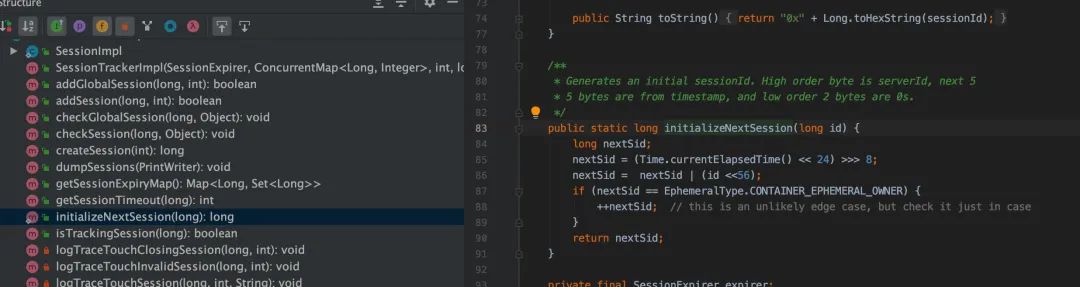
session 生成算法
监视(Watch)
本小节主要看看 ZooKeeper 怎么设置监视和监控点的通知。ZooKeeper 可以定义不同类型的通知,如监控 znode 的数据变化,监控 znode 子节点的变化,监控 znode 的创建或者删除。ZooKeeper 的服务端实现了监视点管理器(watch manager)。
一个 WatchManager 类的实例负责管理当前已经注册的监视点列表,并负责触发他们,监视点只会存在内存且为本地服务端的概念,所有类型的服务器都是使用同样的方式处理监控点。
DataTree 类中持有一个监视点管理器来负责子节点监控和数据的监控。
在服务端触发一个监视点,最终会传播到客户端,负责处理传播的为服务端的 cnxn 对象(ServerCnxn 类),此对象表示客户端和服务端的连接并实现了 Watcher 接口。Watch.process 方法序列化了监视点事件为一定的格式,以便于网络传送。ZooKeeper 客户端接收序列化的监视点事件,并将其反序列化为监控点事件的对象,并传递给应用程序。
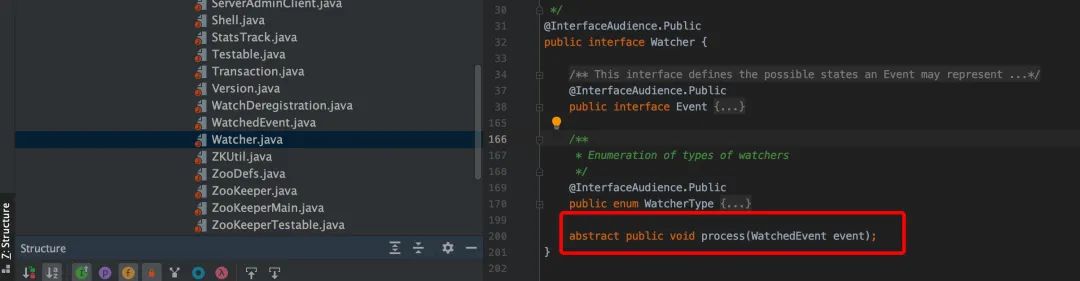
客户端 Watcher 的 process()接口
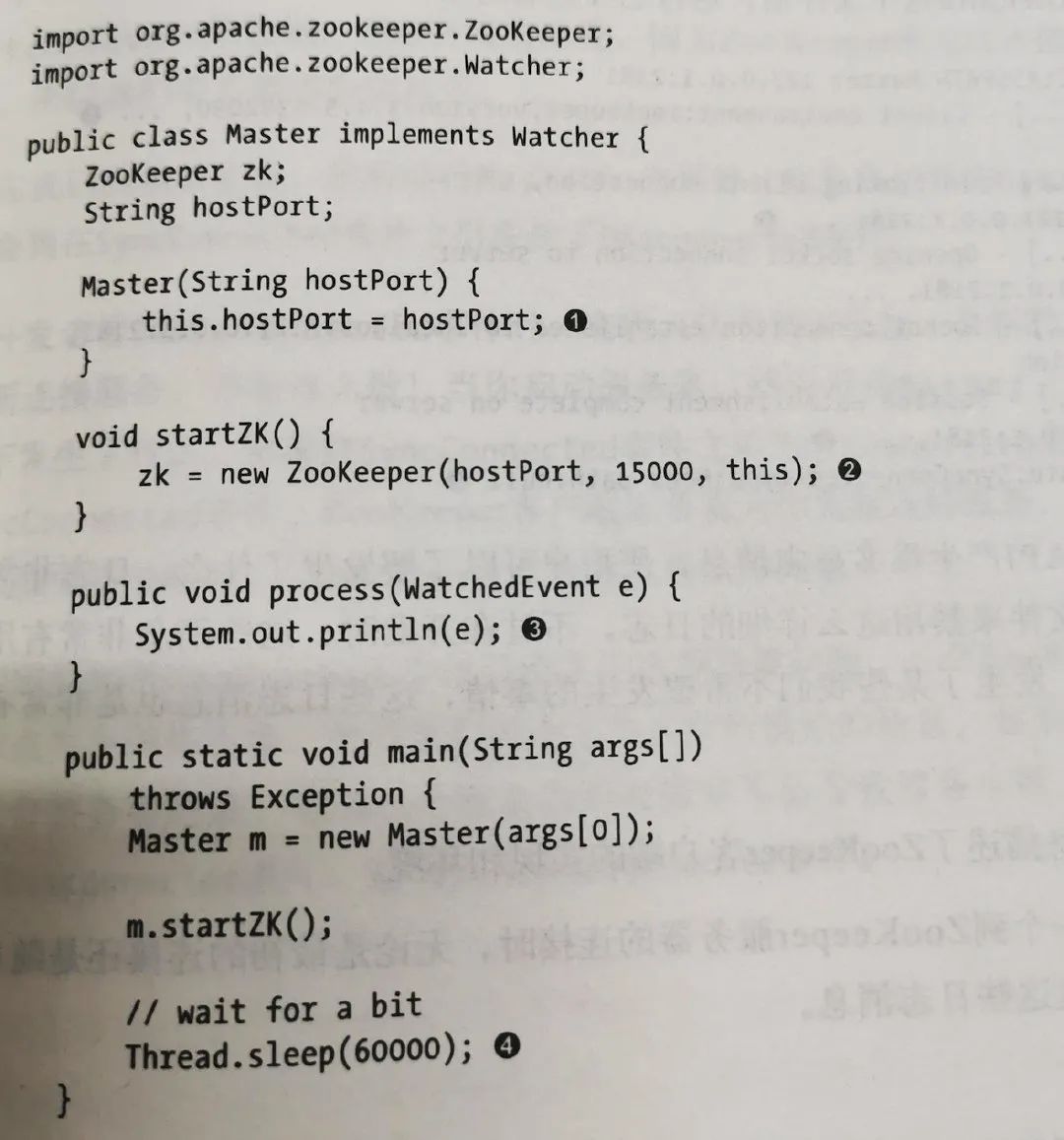
客户端 watcher 实现
创建 WatchRegistration wcb= new DataWatchRegistration(watcher, clientPath),path 和 watch 封装进了一个对象; 创建一个 request,设置 type 为 GetData 对应的数值; request.setWatch(watcher != null),setWatch 参数为一个 bool 值。 调用 ClientCnxn.submitRequest(...) , 将请求包装为 Packet,queuePacket()方法的参数中存在创建的 path+watcher 的封装类 WatchRegistration,请求会被 sendThread 消费发送到服务端。
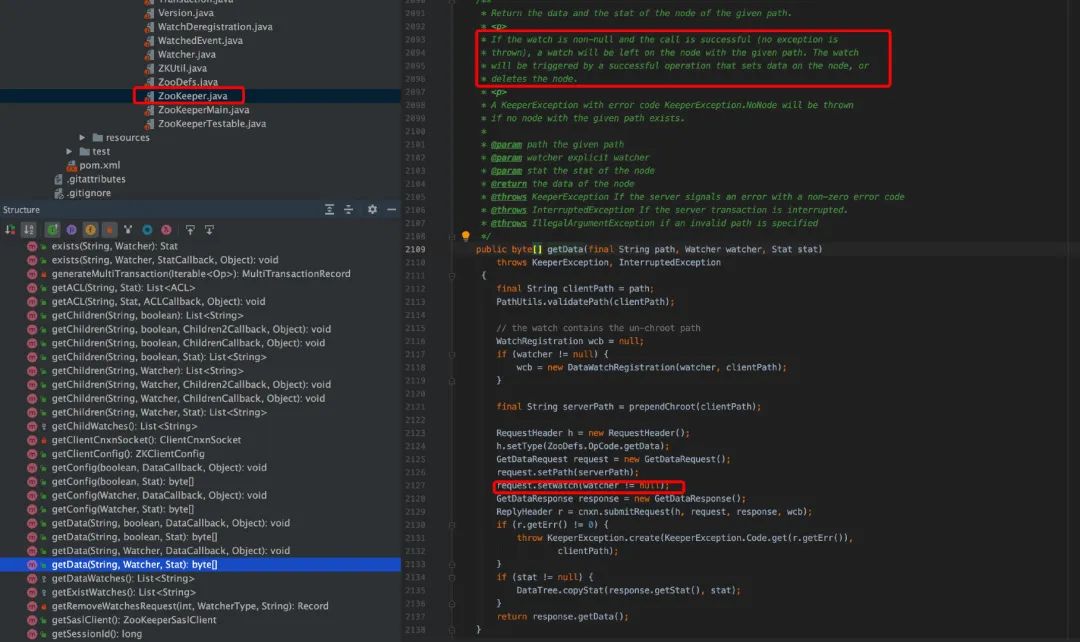
客户端 GetData()
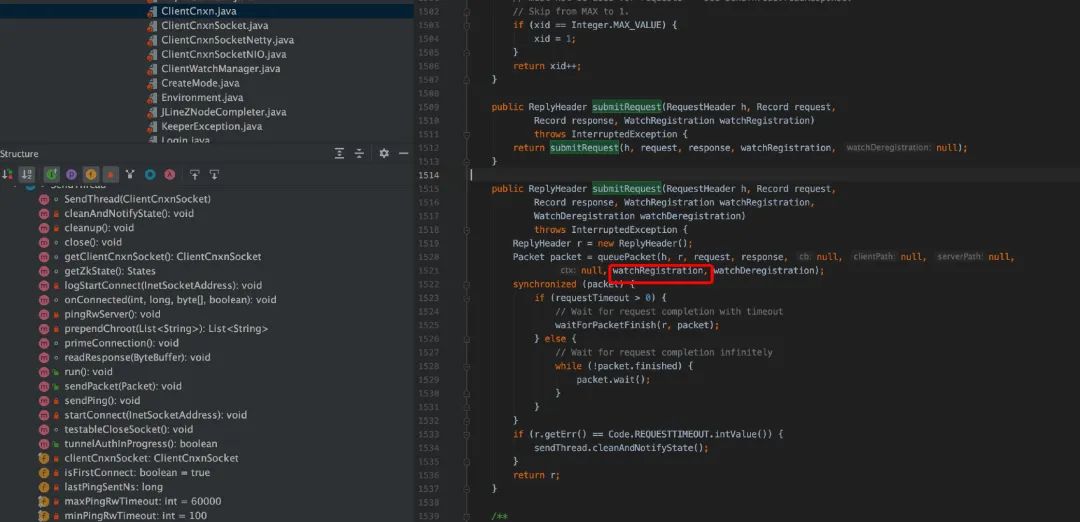
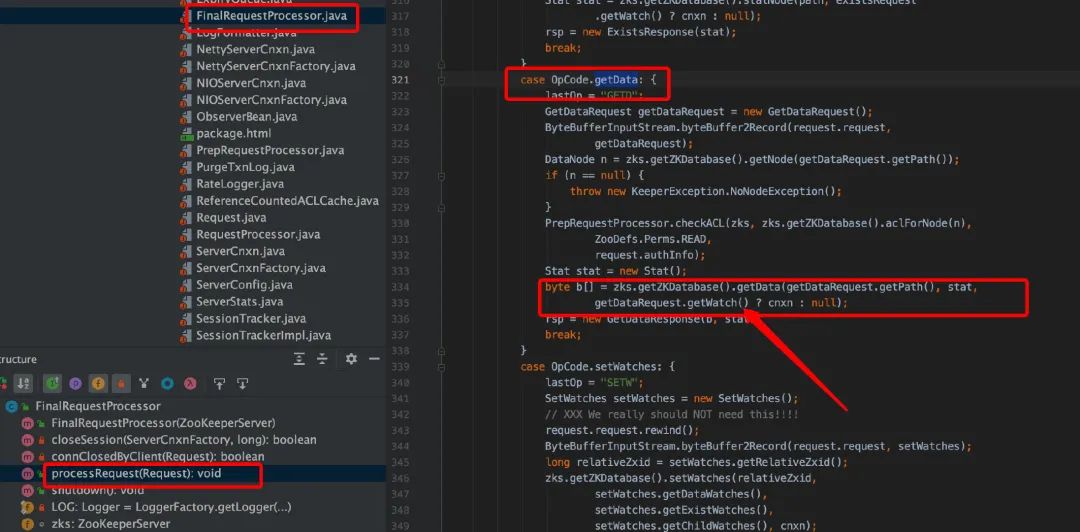
服务端 GetData()
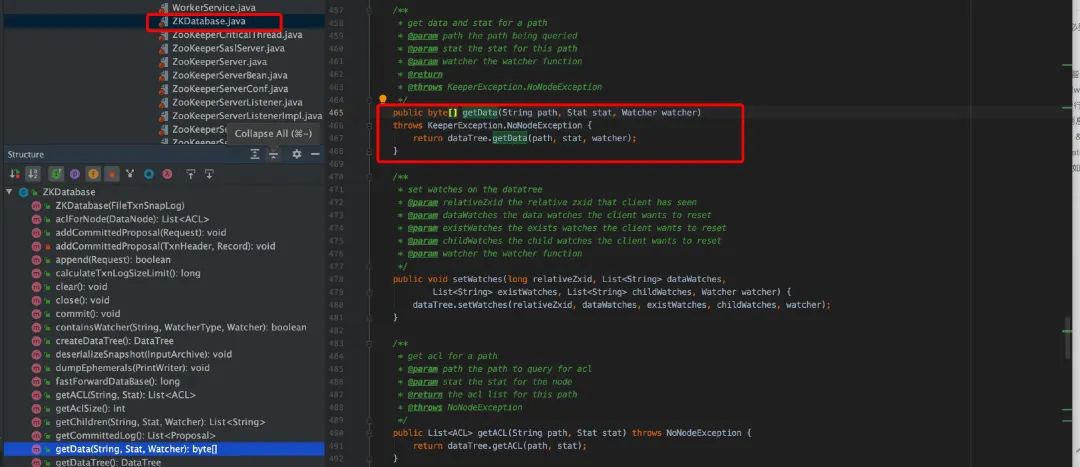
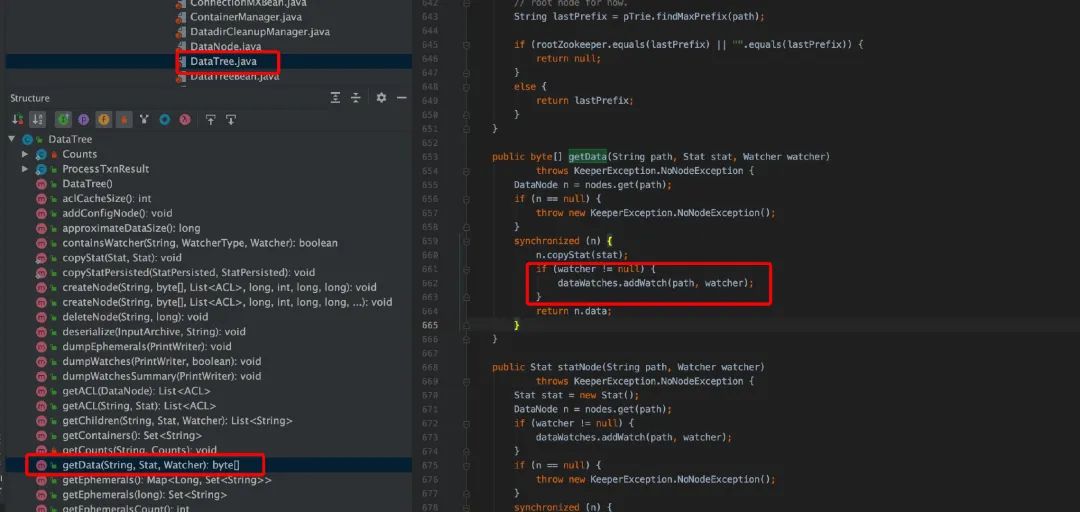
服务端 GetData()
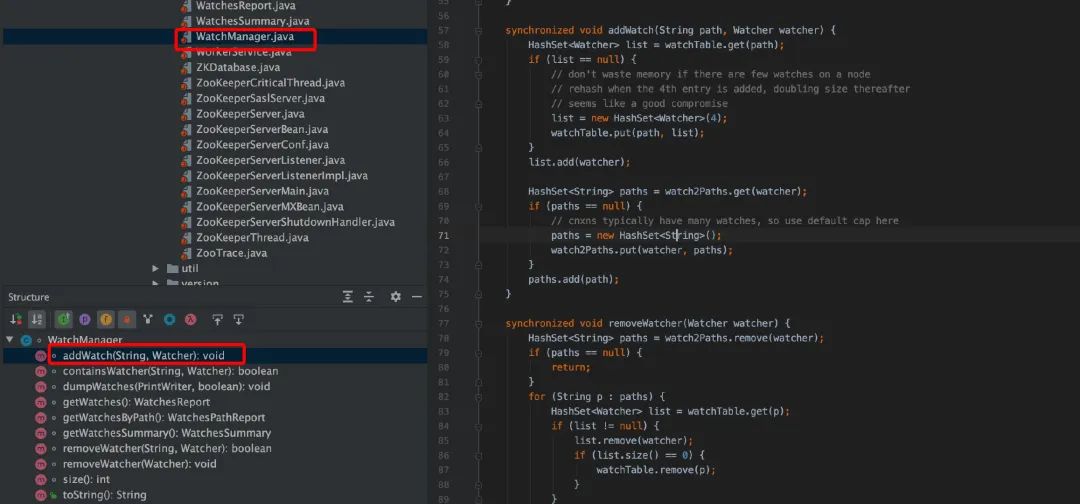
服务端 addWatch ()
为了测试服务端监视通知客户端,我们在客户端本地输入的命令,
set /path newValue
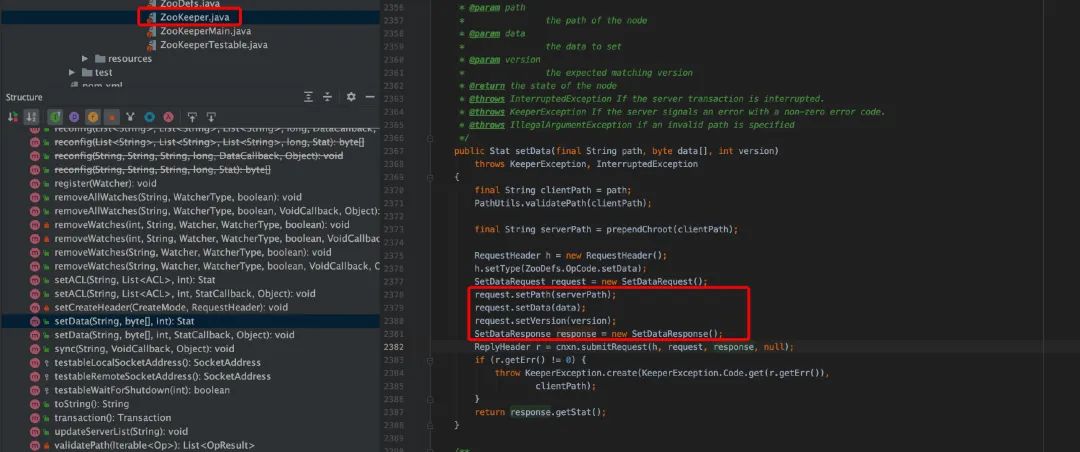
客户端 SetData()
从 SetData 的源码看,本次的 submitRequest 参数中,WatchRegistration==null,可以推断,服务端在 FinalRequestProcessor 中再处理时取出的 watcher==null,也就不会将 path+watcher 保存进 maptable 中,其他的处理过程和上面 GetData 类似。
服务端在满足触发监控点时,并通过 cnxn 的 process()方法处理(NIOServerCnxn 类)通知到客户端。在服务端处理的 SetData()函数看,Set 数值后,会触发 watch 回调,即 triggerWatch()。
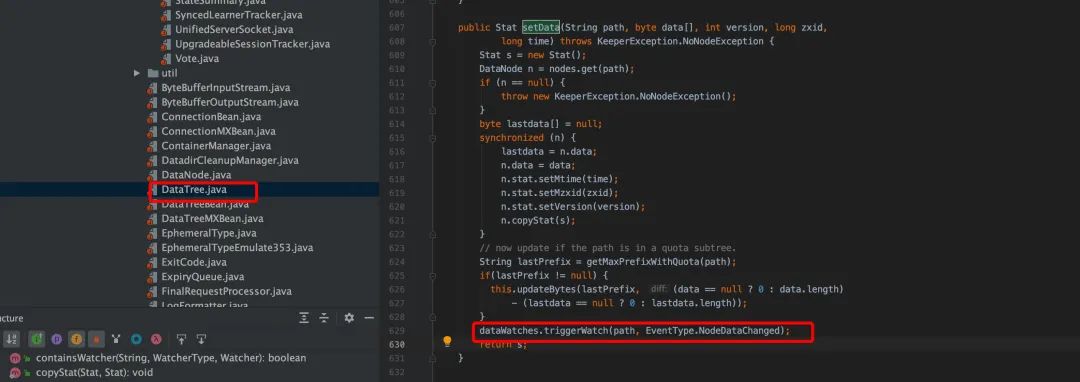
服务端 SetData()
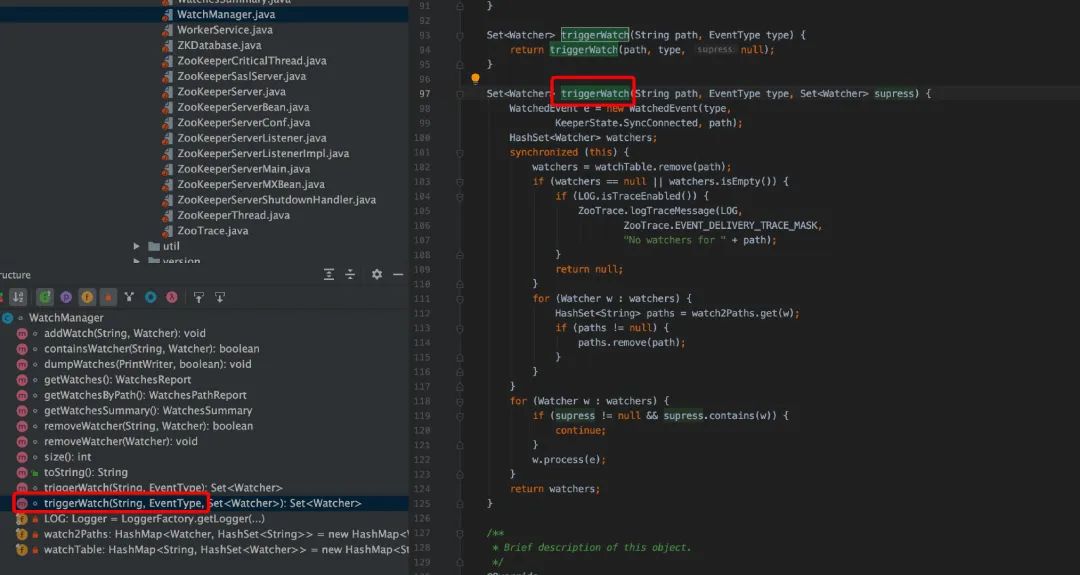
服务端 triggerWatch ()
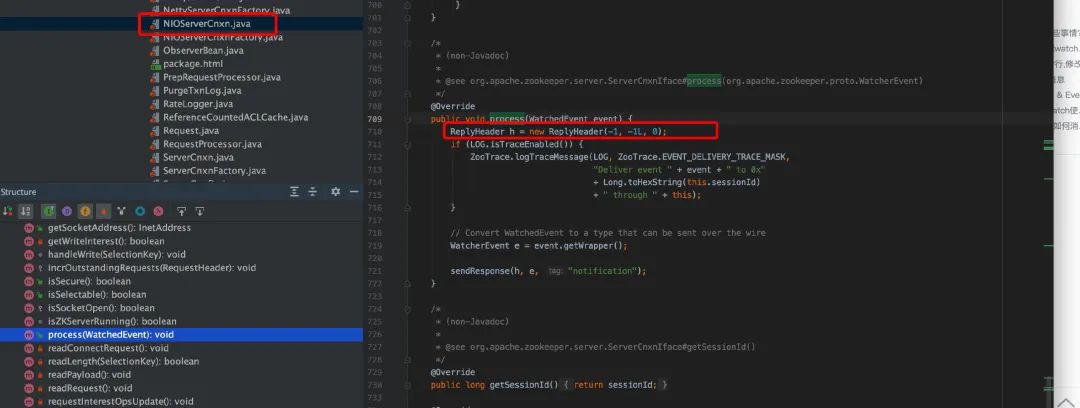
服务端 NIOServerCnxn 的 process()
从上面看服务端在往客户端发送事务型消息, 并且 new ReplyHeader(-1, -1L,0)第一个位置上的参数是-1。
在客户端的 SendThread 读就绪源码部分(readResponse),在 readResponse 函数中会判断 xid==-1 时然后调用 eventThread.queueEvent(we ),把响应交给 EventThread 处理。
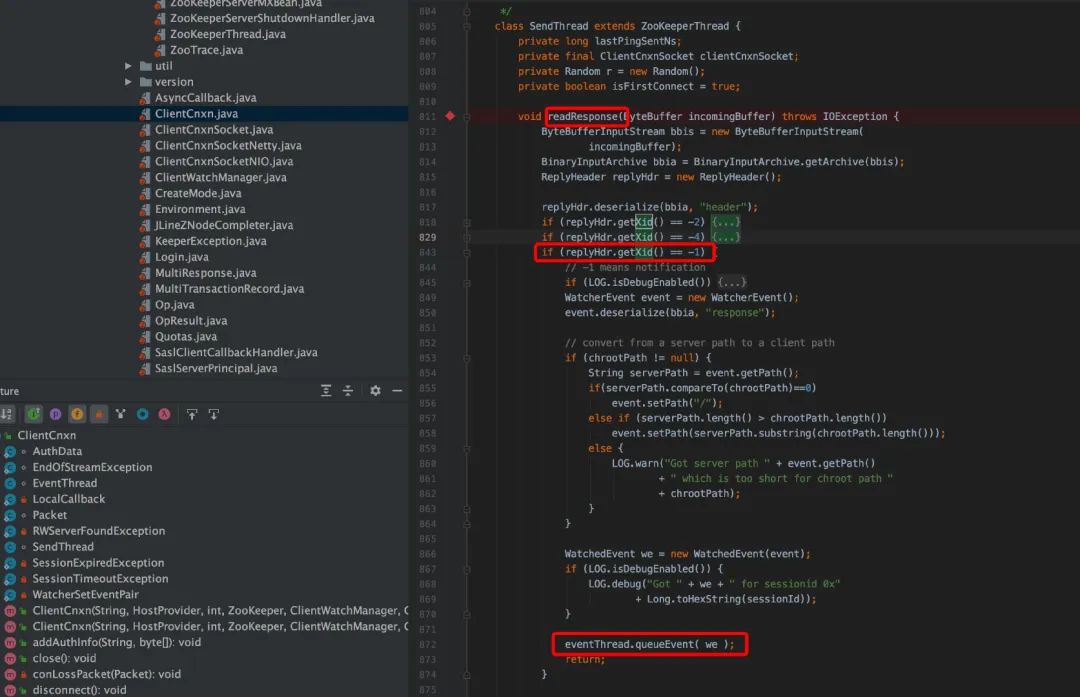
其 eventThread 是一个守护线程,run()函数在 while(true)去消费 waitingEvents,最终调用会 watcher.process(pair.event),其中 process 是 watcher 的 process 的接口的实现,从而完成 wacher 回调处理。
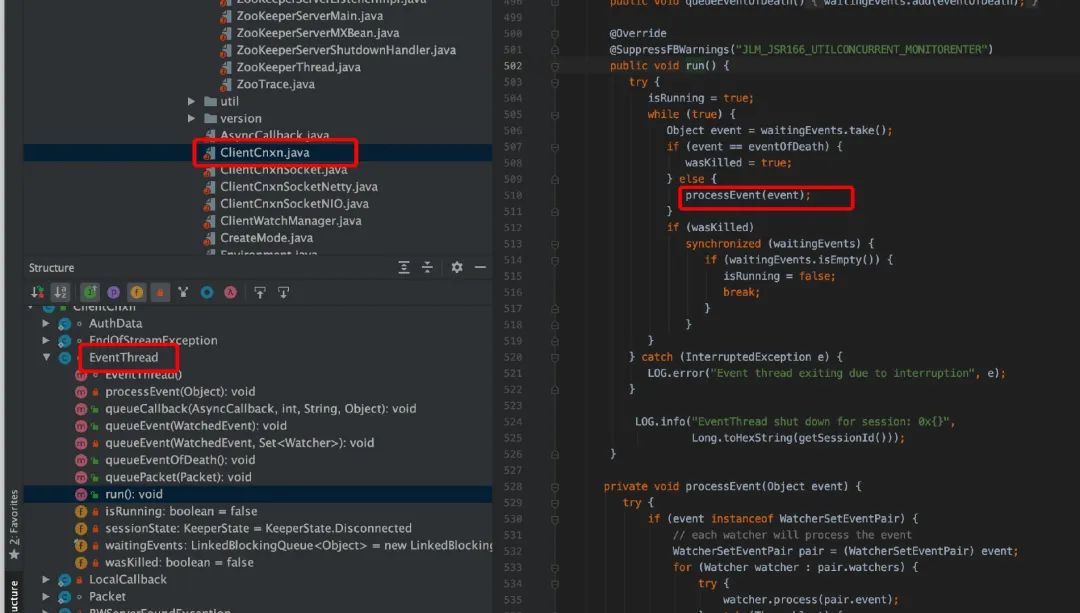
客户端 eventThread 的 run()
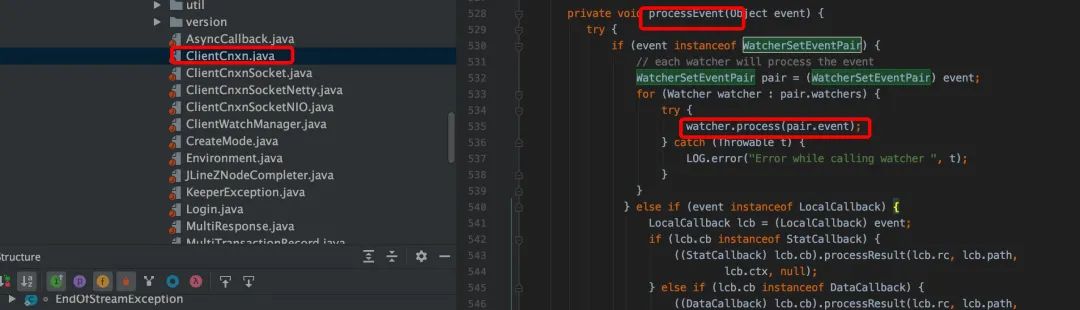
客户端 processEvent()
客户端接口 watch process()
ZooKeeper 实践经验
业务的控制面架构
ZooKeeper 集群的特点
ZooKeeper 集群规模,以地域级集群举例(2020 前)
| 地域 | 集群规模(设备数目) | 备注 |
|---|---|---|
| 上海 | 168 | |
| 广州 | 95 | |
| 北京 | 41 | |
| 其他 | 4 ~ 12 |
ZooKeeper 集群的 Znode 数目
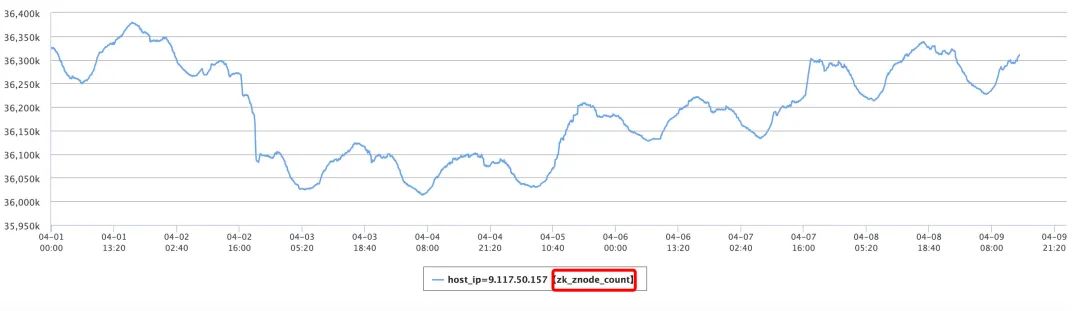
ZooKeeper 集群的 Watch 数目
选择单台设备看
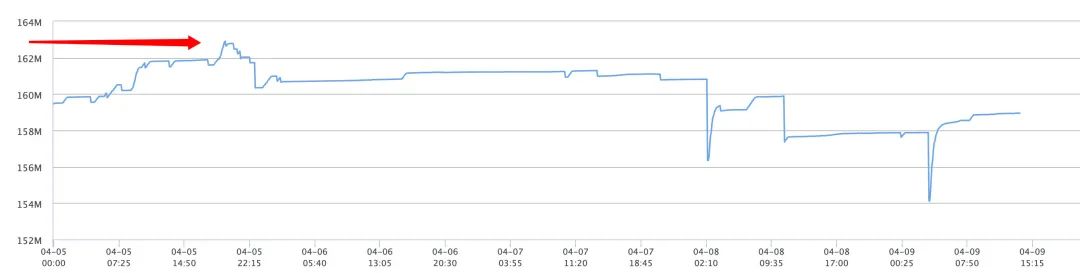
实践场景分析和优化措施
灾备集群搭建
在现网运营中,出现过半个小时以上,服务不可用的情况,灾备集群的搭建显得十分重要。
ZooKeeper 数据存储的一个优点是,数据的存储方式是一样的,通过事务日志和快照的合并可以得到正确的数据视图,可以拷贝日志文件和快照文件到另外的新集群。
目前我们切换新旧集群还是人工参与,不过可以大幅度降低服务不可用的整体时间。在搭建灾备集群时,也会遇到环境,配置,机型等问题,需要在实践中摸索,并能熟练的切换。
Observer 单核高负载时 Observer 数据落地慢
触发点
ZK 数据有突发写入时,子树数据量大。
故障现象
客户端感知数据变化慢,下发配置不及时,导致用户业务受影响。
故障过程
ZooKeeper 数据有突发写入时;
客户端从 Observer 拉取大子树(children 很多的节点的 children 列表);
触发 Observer 发生单核高负载,高负载 CPU 主要处理 getChildren 时的数据序列化去了;
4.客户端看见从 Observer getChildren 回来的数据是很旧的数据,而此时 ZooKeeper 数据早就写入主集群了;
5.客户端一次不能看见的数据变化特别慢,导致客户端花了很长时间才感知并在本地处理完这些突发写入。
故障原因分析
写子树时,触发客户端的 Children 事件,由于 ZooKeepeer 实现的机制不能单独通知哪个 Children 节点变化,客户端必须自己去 getChildren 获得全量的 Children 节点(例如 Children 层机有 10w 节点,在新增一个节点,客户端需要下拉 10w+的数据到本地),如果 Children 数量很大,会极大消耗 Observer 的性能,在 Observer 高负载后处理不及时,导致下发配置延时。
优化措施
服务器 Full GC 导致会话异常
触发点
ZooKeeper 的服务端机器发生了 gc,gc 时间过长,gc 结束后发生会话超时处理。
故障现象
长时间的 gc 后,会话超时,客户端再请求服务器时,遇到异常,客户端会重启。服务端断开大量的客户端时,会带来连接冲击。
机房网络中断,大量连接冲击 Observer
触发点
客户端,Observer,主集群跨区部署,某区机房网络短暂中断。
连接冲击现象
集群有连接冲击发生时,closeSession 事务导致所有 Observer 无法快速处理新建的连接和其他请求,从而客户端主动断连,又出现更多的 closeSession。几乎无法自行恢复。
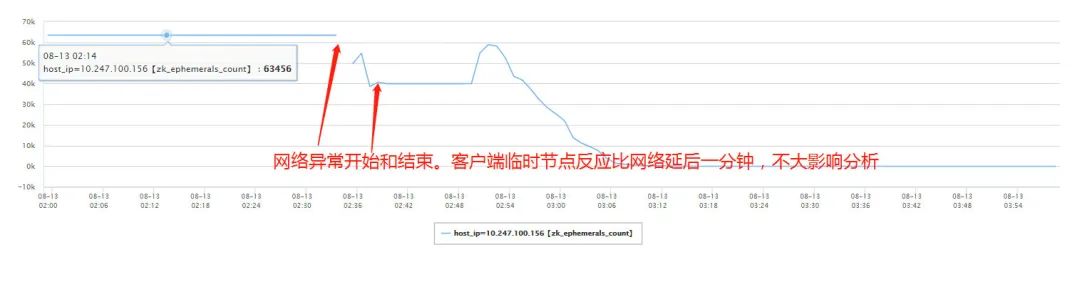
单台 Observer 临时节点的数量变化
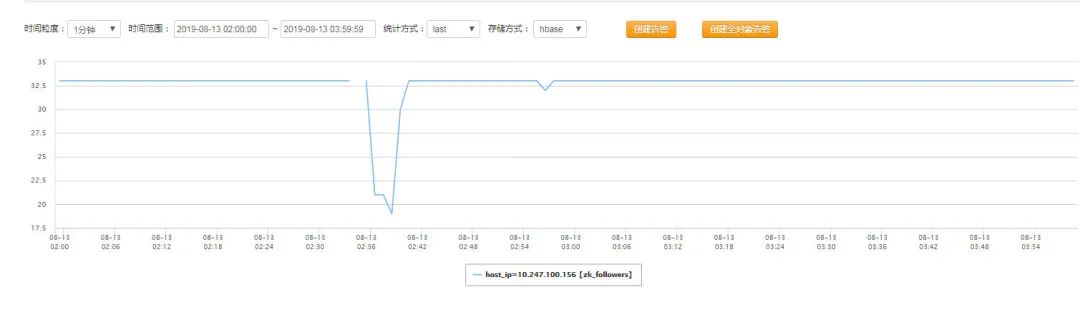
集群中 Fellower 数量变化
故障过程
阶段 1:网络异常,Observer 和主集群的通信中断,Leader 把 Observer 踢出集群(从上图的Fellower 的数量变化可以看出),大量客户端开始断连(从上图的临时节点的数量变化可以看出);
阶段 2: 网络恢复后 Observer 感知到了被踢出,进入自恢复逻辑;
阶段 3: Observer 同步完新事务,并进入 Serving 状态;
阶段 4: 大量客户端开始重连 Observer,Observer 没有限制住连接冲击导致卡死。
故障原因
在阶段 4,观察分析 Observer 的 pps 不是很高,不过处理事务非常慢,线程栈发现有两个线程互相卡慢,使得 closeSession 事务无法在 Observer 上有效执行,也使 NIO 连接接入层线程无法处理连接的数据接收和数据回复和建立新连接。
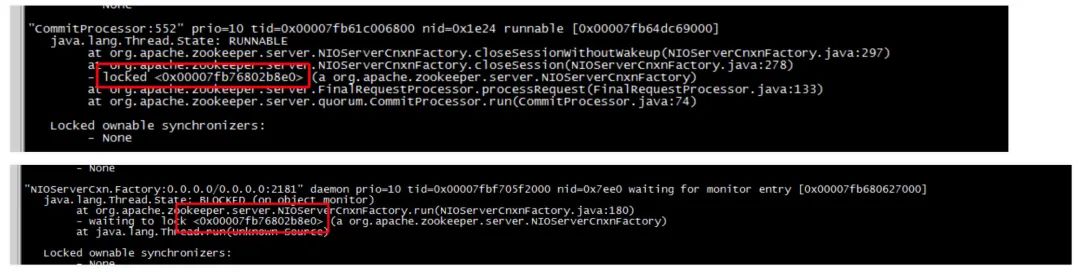
优化措施
限制或者抑制连接冲击。在故障时,根据 tcp 状态为 established 的连接数量动态限制连接,不过 established 的连接数量其未过阀值,但是观察到 fd 仍是满的,大部分连接处于 tcp 的 close-wait 状态,其中 fd 消耗过多,如果 Observer 落地日志的话,也会造成写 binlog 或 snapshot 失败导致进程异常退出。
initlimit 和 syncLimit 参数配置对集群和会话的影响
initLimit 参数
initLimit 是追随者最初连接到群首时的超时值,单位为 tick 值的倍数。当某个追随者最初与群首建立连接时,它们之间会传输相当多的数据,尤其是追随者落后整体很多时。配置 initLimit 参数值取决于群首与追随者之间的网络传输速度情况,以及传输的数据量大小。如果 ZooKeeper 中保存的数据量特别大时或者网络非常缓慢时,就需要增大 initLimit。
故障场景:在相同数据量的情况下,对于一个正常运行中的 3 节点主集群,如果一台 follower 重启或一台 observer 想要加入集群:initLimit 过小,会使这台机器无法加入主集群。
原因分析
ZooKeeper 的 3.4.4 版本的 observer/follower 启动时会读取一次 snapshot,在选举逻辑知道 leader 信息后,与 leader quorum 端口(2001、2888)交互前,还会再读取一次 snapshot。
另外,initLimit 影响 leader 对 observer/follower 的 newLeaderAck(ZooKeeper3.4.4 或 3.4.6 版本),成员加入集群前,成员机器上会进行一次 snapshot 刷出,耗时如果过长,会使 leader 对 observer 或 follower 的的 newLeaderAck 读取超时(tickTime*initLimit)。如果此时正处理 leader 刚选举完要给一个 follower 同步数据的时候,还会导致 leader 不能及时收到足够数量的 newLeaderAck 而导致集群组建失败。
在 ZooKeePeer 的 3.5 版本后,初始化加载 snapshot 只会加载一次,不过需要同步的数据量比较大时,initLimit 还是要调大一些。
syncLimit 参数
syncLimit 是追随者与群首进行 sync 操作时的超时值,单位为 tick 值的倍数。
追随者总是会稍微落后于群首,但是因为服务器负载或者网络问题,就会导致追随者落后群首太多,甚至需要放弃该追随者,如果群首与追随者无法进行 sync 操作,而且超过了 syncLimit 的 tick 时间,就会放弃该追随者。
测试追随者与群首的网络情况,进行规划配置,并实时监控集群数据量的变化。
提高服务端的性能,网卡性能。

目前,腾讯云微服务引擎(Tencent Cloud Service Engine,简称TSE)已上线,并发布子产品服务注册、配置中心(ZooKeeper/Nacos/Eureka/Apollo)、治理中心(PolarisMesh)。支持一键创建、免运维、高可用、开源增强的组件托管服务,欢迎点击文末的「阅读原文」了解详情并使用!
TSE官网地址:
https://cloud.tencent.com/product/tse
参考文献
ZooKeeper-选举实现分析: https://juejin.im/post/5cc2af405188252da4250047 Apache ZooKeeper 官网: https://zookeeper.apache.org/ ZooKeeper github: https://github.com/apache/zookeeper 《zookeeper-分布式过程协同技术详解》【美】里德,【美】Flavio Junqueira 著 ZooKeeper 源码分析: https://blog.reactor.top/tags/Zookeeper/ ZooKeeper-选举实现分析: https://juejin.im/post/5cc2af405188252da4250047 ZooKeeper 源码分析: https://www.cnblogs.com/sunshine-2015/tag/zookeeper/
往期
推荐
《腾讯云消息队列 TDMQ Pulsar 版商业化首发|持续提供高性能、强一致的消息服务》
《Kratos技术系列|从Kratos设计看Go微服务工程实践》
《Pulsar技术系列 - 深度解读Pulsar Schema》
《Apache Pulsar事务机制原理解析|Apache Pulsar 技术系列》

扫描下方二维码关注本公众号,
了解更多微服务、消息队列的相关信息!
解锁超多鹅厂周边!


点个在看你最好看