Python爬取东方财富网资金流向数据并存入MySQL
第一步:程序及应用的准备
首先我们需要安装selenium库,使用命令pip install selenium;然后我们需要下载对应的chromedriver,,安装教程:。我们的chromedriver.exe应该是在C:\Program Files\Google\Chrome\Application中(即让它跟chrome.exe在同一个文件下)。
下载完成后,我们还需要做两件事:1.配置环境变量;
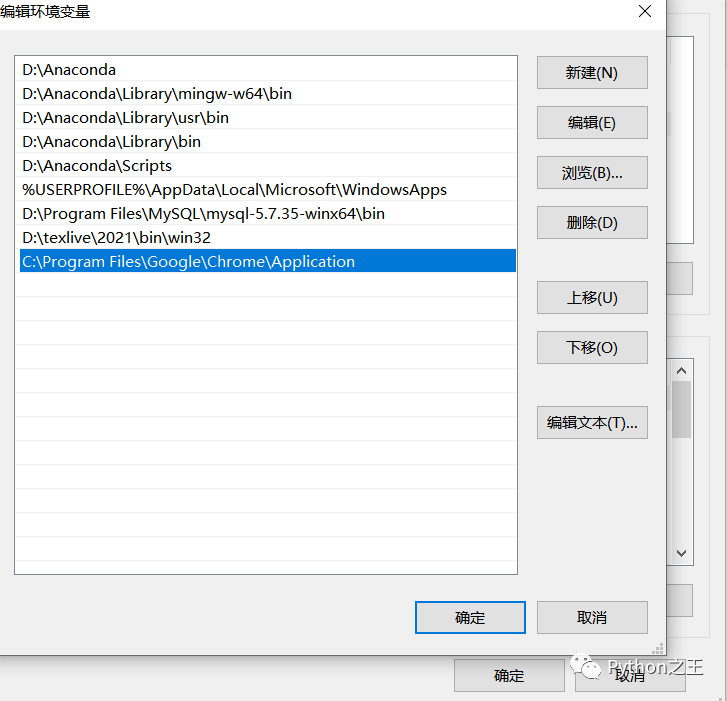
2.将chromedriver.exe拖到python文件夹里,因为我用的是anaconda,所以我直接是放入D:\Anaconda中的。

此时,我们所需的应用已经准备好了。
第二步:进入我们要爬取的网页(),按F12进入调试模式.
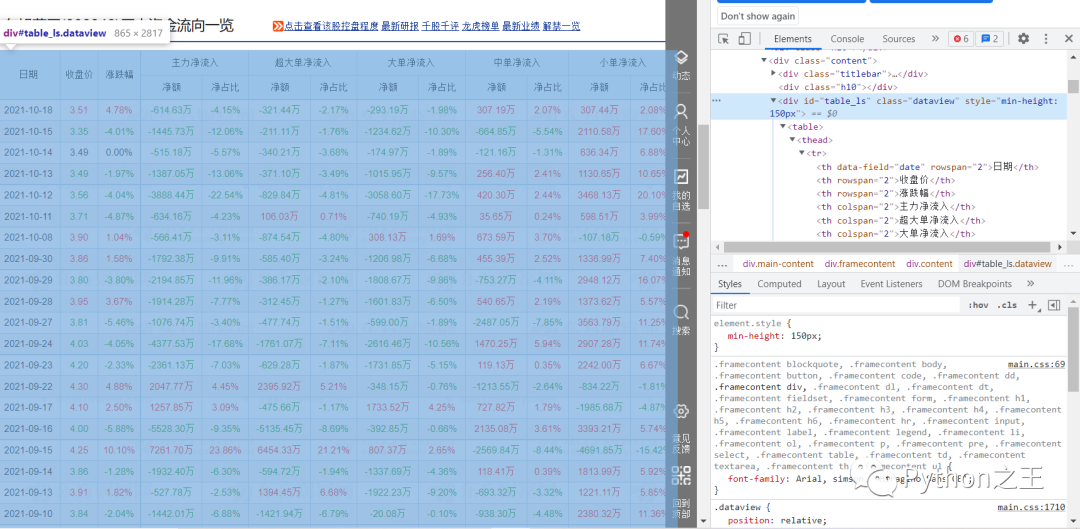
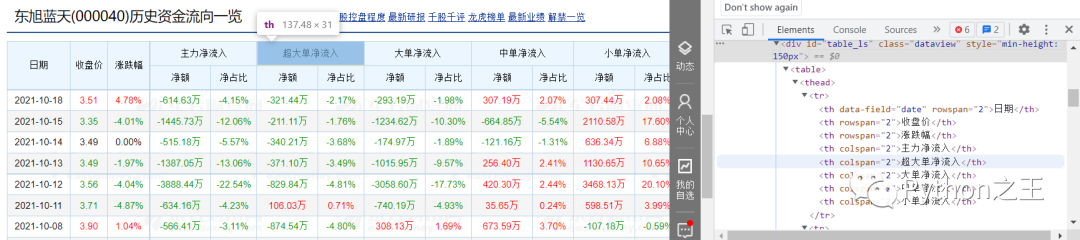
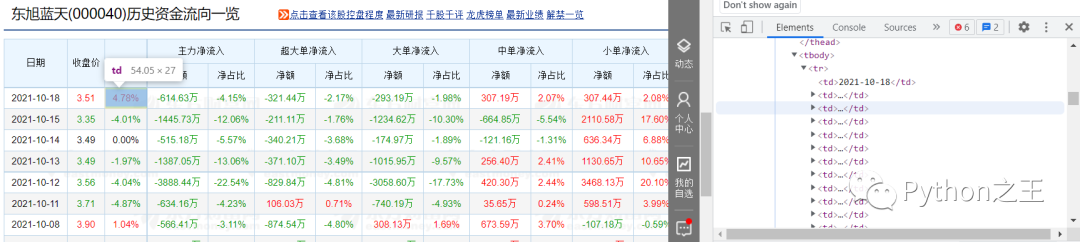
当我们依次点击右侧div时,我们可以发现,我们想要爬取的数据对应的代码为右侧蓝色部分,而下方的
| 开始,以 | 结束的;在 | 开始,以 | 结束的。至此,我们对要爬取的数据的构成有了一个大概的认知。 第三步:编写程序 etree.HTML()可以用来解析字符串格式的HTML文档对象,将传进去的字符串转变成_Element对象。作为_Element对象,可以方便的使用getparent()、remove()、xpath()等方法。 options常用属性及方法为:
div[@class="dataview"表示我们通过class属性的值定位到我们要爬取的表格div,‘/table’则是表示 的下一级 |
|---|