
2021年B站-主站技术中心-算法开发岗面试题5道!
文 | 七月在线
编 | 小七


目录
FIGHTING
问题1:介绍word2vec,负采样的细节
问题2:fasttext的改进,特征hash的作用
问题3:用rand2实现rand5
问题4:介绍一下Bert以及三个下游任务
问题5:除了Bert其他预训练模型的拓展
问题1:介绍word2vec,负采样的细节
word2vec是google于2013年开源推出的一个词向量表示的工具包,其具体是通过学习文本来用词向量的方式表征词的语义信息,即通过一个低维嵌入空间使得语义上相似的单词在该空间内的距离很近。有两种模型:CBOW和skip-Gram,其中CBOW模型的输入是某一个特征词的上下文固定窗口的词对应的词向量,而输出就是该特定词的词向量;Skip-Gram模型的输入是特定的一个词的词向量,输出就是特定词对应的上下文固定窗口的词向量。
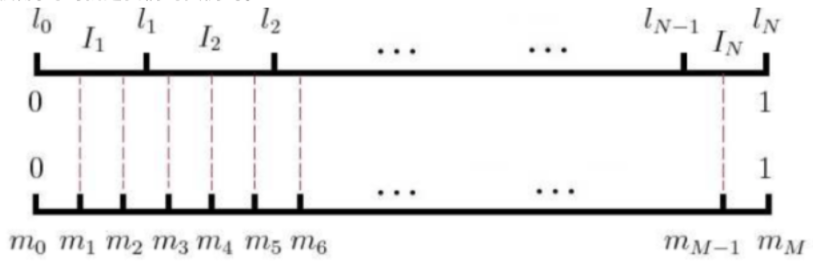
现在我们看下Word2vec如何通过Negative Sampling负采样方法得到neg个负例;如果词汇表的大小为V,那么我们就将一段长度为1的线段分成V份,每份对应词汇表中的一个词。当然每个词对应的线段长度是不一样的,高频词对应的线段长,低频词对应的线段短。
每个词w的线段长度由下式决定︰
在word2vec中,分子和分母都取了3/4次幂如下:
在采样前,我们将这段长度为1的线段划分成M等份,这里M>>V,这样可以保证每个词对应的线段都会划分成对应的小块。而M份中的每一份都会落在某一个词对应的线段上。在采样的时候,我们只需要从M个位置中采样出neg个位置就行,此时采样到的每一个位置对应到的线段所属的词就是我们的负例词。
在word2vec中,M取值默认为10^8。
问题2:fasttext的改进,特征hash的作用
fastText模型架构和word2vec中的CBOW很相似,不同之处是fastText预测标签而CBOW预测的是中间词,即模型架构类似但是模型的任务不同。
对于word2vec来说,词向量的加和求平均会丢失词顺序的信息,为了弥补这一点Fasttext增加了N-gram特征,将n-gram当成一个词,也用embedding来表示,所以look-up矩阵为[vocab+n_gram_num, dim]。由于n-gram的数量远大于word的数量,完全存储不现实,所以fasttext采用hash桶的方式,将所有n-gram都哈希到buckets桶中,哈希到同一个桶中的n-gram共享embedding vector,潜在的问题是存在哈希冲突,当然如果桶buckets取足够大时,可以避免这个问题。
问题3:用rand2实现rand5
该题为leetocde470.用 Rand7()实现Rand10(),下面给出解法。
首先需要找到两个规律,规律—︰
已知rand_N()可以等概率的生成[1, N]范围的随机数
那么∶
(rand_X()- 1)×Y + rand_Y()==>可以等概率的生成[1,X* Y]范围的随机数
即实现了rand_XY()
规律二:
要实现rand10(),就需要先实现rand_N(),并且保证N大于10且是10的倍数。这样再通过rand_N()%10+1就可以得到[1,10]范围的随机数了。
最后,由于生成的49不是10的倍数,故需要采用'拒绝采样',也就是说如果某个采样结果不在范围内就要丢弃它,如代码如下:
时间复杂度:O(1)
空间复杂度:o(1)
参考: https:/leetcode-cn.com/problems/implement-rand10-using-rand7/solution/cong-zui-ji-chu-de-jiang-qi-ru-he-zuo-dao-jun-yun-/
问题4:介绍一下Bert以及三个下游任务
Bert模型是一种自编码语言模型,其主要结构是transformer的encoder层,其主要包含两个训练阶段,预训练与fine-tuning,其中预训练阶段的任务是Masked Language Model(完形填空)和Next Sentence Prediction。
下游任务︰句子对分类任务,单句子分类任务,问答任务,单句子标注任务。
问题5:除了Bert其他预训练模型的拓展
RoBERTa模型在Bert模型基础上的调整︰
训练时间更长,Batch_size更大,(Bert 256,RoBERTa 8K)–训练数据更多(Bert 16G,RoBERTa 160G)
移除了NPL (next predict loss)
动态调整Masking机制
Token Encoding:使用基于bytes-level 的BPE




— 今日学习推荐 —

七月【图像分类与图像搜索】 卷积神经实践解决车辆识别问题,价值千元课程,限时1分秒杀!
课程链接:https://www.julyedu.com/course/getDetail/256
本课程是CV高级小班的前期预习课之一,主要内容包含卷积神经网络基础知识、卷积网络结构、反向传播、图像特征提取、三元组损失等理论,以及目标检测和图像搜索实战项目,理论和实战结合,打好计算机视觉基础。
戳↓↓“阅读原文” 1分秒杀【图像分类与图像搜索】课程!

