
亿级用户中心的设计与实践
点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达

- 前言 -
用户中心是互联网最为基础的核心系统,随着业务和用户的增长,势必会带来不断的挑战。如何在亿级的情况下保证系统的高可用,高性能以及高安全,本文能够给你一套实践方案。
- 服务架构 -
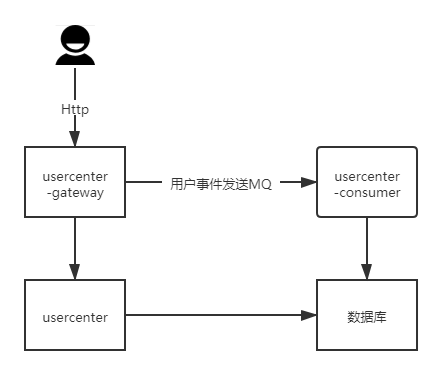
- 接口设计 -
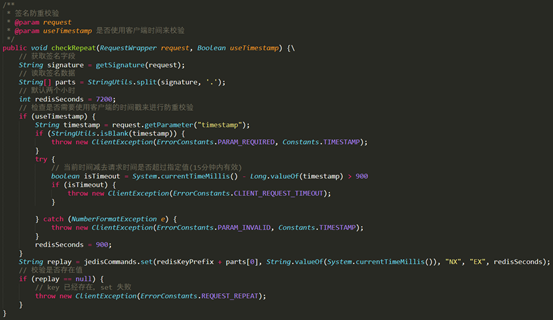
- 分库分表 -
用户注册时,根据用户的手机号码,利用函数生成N bit的基因mobile_gen,使得mobile_gen=f(mobile); 生成M bit全局唯一的id,作为用户标识; 拼接M和N,作为UID赋给用户; 根据N bit来取余来插入到特定数据库; 查找用户数据的时候,将用户UID的后N bit取余来落到最终的库中。
- Token 之柔性降级 -
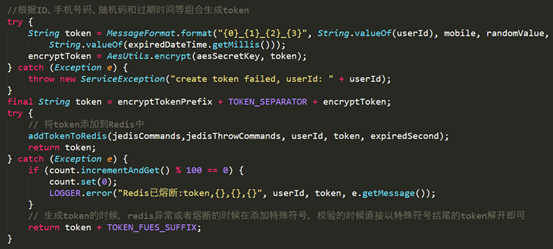
- 数据安全 -
- 异步消费设计 -
- 灵活多样的监控 -
- 总结 -
作者:vivo互联网技术
加锋哥微信: java1239 围观锋哥朋友圈,每天推送Java干货!

评论