
TorchMetrics:PyTorch的指标度量库
共 3832字,需浏览 8分钟
·
2021-04-09 22:45
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


作者:PyTorch Lightning team
编译:ronghuaiyang
非常简单实用的PyTorch模型的分布式指标度量库,配合PyTorch Lighting实用更加方便。
找出你需要评估的指标是深度学习的关键。有各种各样的指标,我们可以评估ML算法的性能。TorchMetrics是一个PyTorch度量的实现的集合,是PyTorch Lightning高性能深度学习的框架的一部分。在本文中,我们将介绍如何使用TorchMetrics评估你的深度学习模型,甚至使用一个简单易用的API创建你自己的度量。
什么是TorchMetrics?
TorchMetrics是一个开源的PyTorch原生的函数和度量模块的集合,用于简单的性能评估。你可以使用开箱即用的实现来实现常见的指标,如准确性,召回率,精度,AUROC, RMSE, R²等,或者创建你自己的指标。我们目前支持超过25个指标,并不断增加更多的通用任务和特定领域的标准(目标检测,NLP等)。
TorchMetrics最初是作为Pytorch Lightning (PL)的一部分创建的,被设计为分布式硬件兼容,并在默认情况下与DistributedDataParalel(DDP)一起工作。所有指标都在cpu和gpu上经过严格测试。
使用TorchMetrics
安装
这个包可以通过以下方式从PyPI简单安装:
pip install torchmetrics
或者直接从GitHub仓库的源代码安装:
# with git
pip install git+https://github.com/PytorchLightning/metrics.git@master
函数形式的metrics
类似于torch.nn,大多数度量指标都有基于模块和函数的版本。函数版本实现了计算每个度量所需的基本操作。它们是作为输入的简单的python函数。并返回相应的torch.tensor的指标。下面的代码片段展示了一个使用函数接口计算精度的简单示例:

模块形式的metrics
几乎所有函数metrics都有一个对应的基于模块的metrics,该度量将其称为底层的函数等价模块。基于模块的度量的特点是有一个或多个内部度量状态(类似于PyTorch模块的参数),允许它们提供额外的功能:
多批次积累 多台设备间自动同步 度量算法
下面的代码展示了如何使用基于模块的接口:
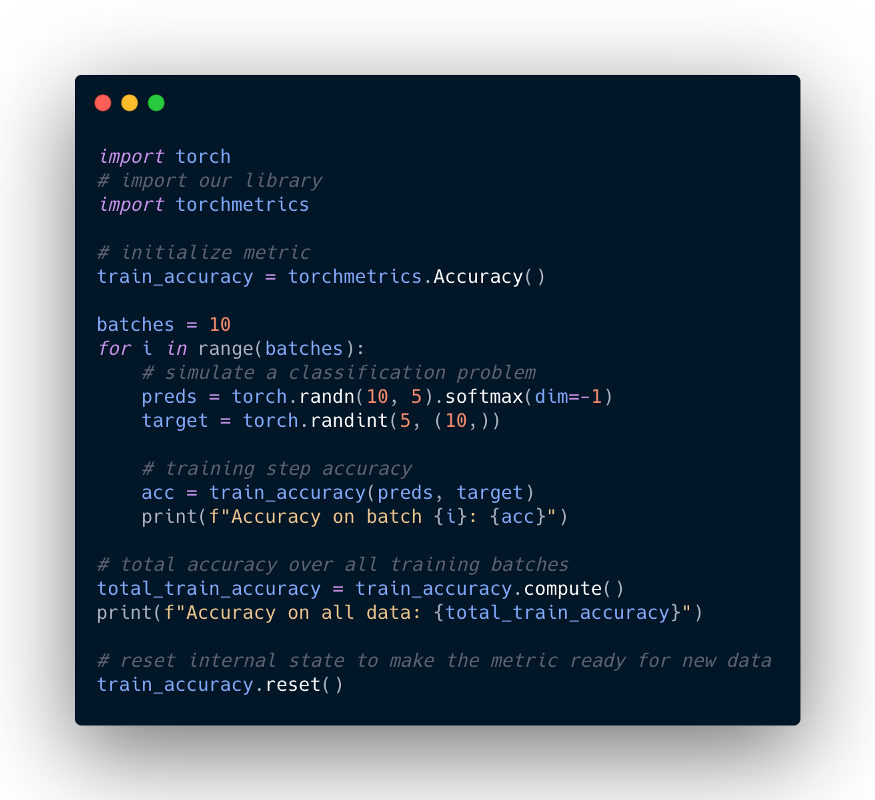
每次调用度量的forward函数时,我们同时计算当前看到的一批数据上的度量值,并更新内部度量状态,以跟踪到目前为止看到的所有数据。内部状态需要在不同时期之间重置,不应该在训练、验证和测试之间混合。因此我们强烈建议按如下方式重新初始化度量:

Lightning中使用TorchMetrics
下面的例子展示了如何在你的LightningModule中使用metric :
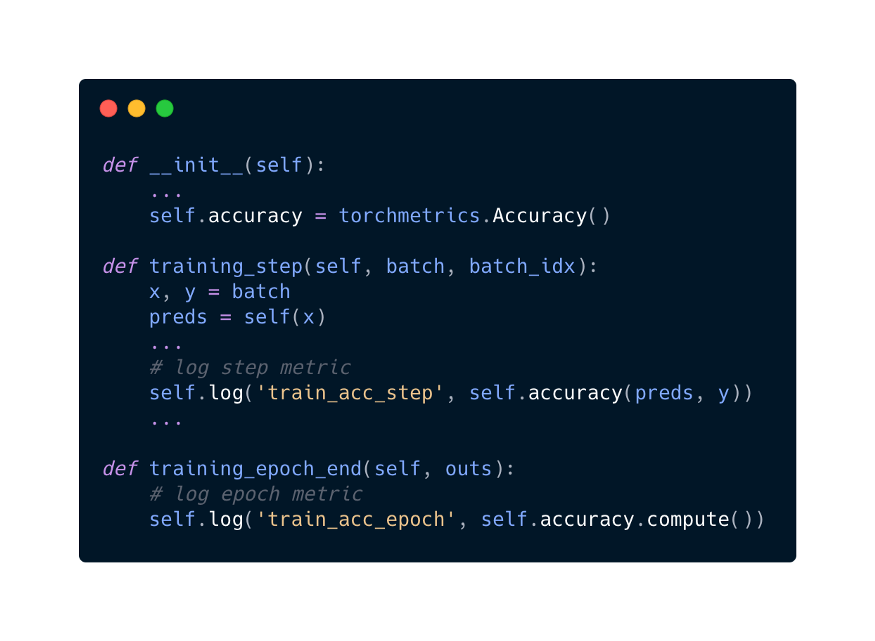
虽然TorchMetrics被构建为与原生的PyTorch一起使用,但TorchMetrics与Lightning一起使用提供了额外的好处:
当在LightningModule中正确定义模块metrics 时,模块metrics会自动放置在正确的设备上。这意味着你的数据将始终与你的metrics 放在相同的设备上。 在Lightning中支持使用原生的 self.log,Lightning会根据on_step和on_epoch标志来记录metric,如果on_epoch=True,logger 会在epoch结束的时候自动调用.compute()。metric 的 .reset()方法的度量在一个epoch结束后自动被调用。

Lightning的转换
已经熟悉Lightning的metric接口的用户应该能够轻松地适应TorchMetrics。简单地替换:
from pytorchlightning import metrics
with:
import torchmetrics
注意,在1.3版本之前,metrics将是PyTorchLightning的一部分,但不再接收任何更新。我们强烈建议用户切换到TorchMetrics,以得到我们可能实现的所有的bug修复和增强。
实现自己的metrics
如果你想使用一个还不被支持的指标,你可以使用TorchMetrics的API来实现你自己的自定义指标,只需子类化torchmetrics.Metric并实现以下方法:
__init__():每个状态变量都应该使用self.add_state(…)调用。update():任何需要更新内部度量状态的代码。compute():从度量值的状态计算一个最终值。
例子:均方根误差
均方根误差是一个很好的例子,说明了为什么许多度量计算需要划分为两个函数。定义为:
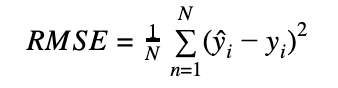
为了正确地计算RMSE,我们需要两个度量状态:sum_squared_error来跟踪目标y和预测y之间的平方误差,以及n_observations来知道我们有多少观测结果。
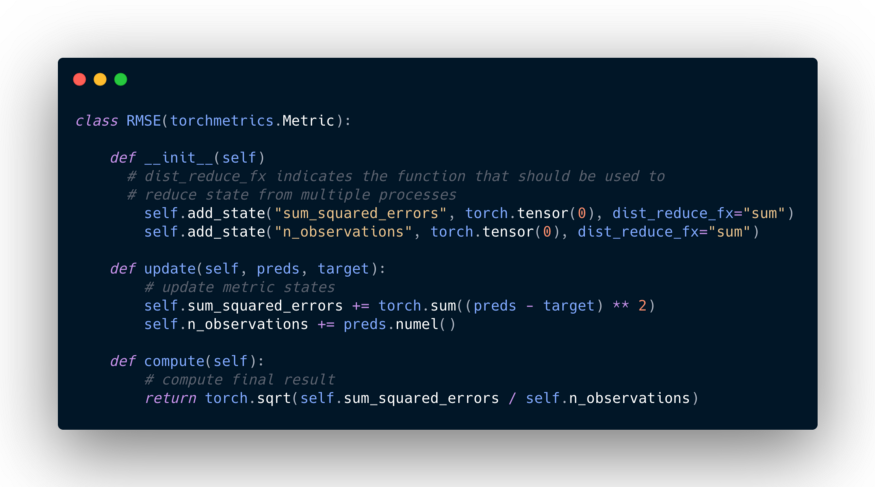
因为sqrt(a+b) != sqrt(a) + sqrt(b),我们不能把这个度量实现为每个batch计算的RMSE分数的简单平均值,而是需要实现更新步骤中需要在平方根之前发生的所有逻辑,以及在compute步骤中需要实现剩余的逻辑。
为你的模型选择正确的度量
选择正确的度量对于确定你的模型是否按照应该的方式运行,或者是否有什么地方出了问题非常重要。
预测冠状病毒
假设你的任务是建立一个分类网络,可以通过一套非侵入性测量来确定患者是否是冠状病毒阳性。你会得到数千份观察报告,并使用你最喜欢的网络架构,优化以正确识别哪些患者感染了冠状病毒。这种模式可用于确保检测呈阳性的患者被隔离,以避免传播病毒并迅速得到治疗。
为了评估你的模型,你计算了4个指标:准确性、混淆矩阵、精确度和召回率。你得到了以下结果:
准确率: 99.9%
混淆矩阵:

精确率: 1.0
召回率:0.28
评估得分
你怎么看?这个模型足够好吗?让我们更深入地了解这些指标的含义。在分类中,准确率是指我们的模型得到正确预测的比例。

我们的模型得到了非常高的准确率:99.9%。看来网络正在做你要求它做的事情,你可以准确地检测到患者是否感染了冠状病毒。
对于二元分类,另一个有用的度量是混淆矩阵,这给了我们下面的真、假阳性和阴性的组合。
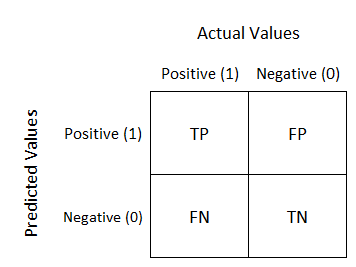
我们可以从混淆矩阵中快速确定两件事:
阴性患者的数量远远少于阳性患者的数量 —> 这意味着你的数据集是高度不平衡的。 有5名患者检测失败
从准确性来看,这个模型似乎表现得很好,但考虑到混淆矩阵,我们发现这个模型过于专注于预测阴性患者,而未能预测阳性患者。在这种设置下,它应该清楚正确识别新冠患者和正确识别非新冠患者之间的巨大的区别,正确识别患者将确保患者得到早期治疗,最重要的是隔离,不要传染给别人。
为什么准确率指标没有显示出模型有什么问题?准确率捕获了整体性能,以正确地预测所有类,在这种情况下,我们感兴趣的是捕获我们预测的ground truth的情况有多好。因此,你可以将注意力转向精确率和召回率。
精确率定义为实际正确的正样本的比例。
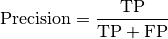
其中TP和FP分别表示true p positive个数,false positive个数。一个有0个误报的模型的精确率为1.0,而一个模型输出的结果都是阳性,而实际上都是假的模型的精度分数为0。
Recall定义为真实的阳性被正确识别的比例。
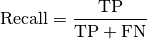
其中TP和FN分别表示true positives数,false negatives数。类似地,如果没有错误否定,一个模型的召回分数将为1.0。从定义上我们可以得出结论,精确率聚焦于在不能识别所有假阳性的“成本”上,而召回率聚焦在不能识别所有假阴性的“成本”上。因为我们在这里感兴趣的是假阴性,所以我们应该在recall metric下重新评估我们的模型,现在我们得到了0.28的分数。现在,你已经量化了模型的性能不佳,并且在训练机器学习算法时可能需要处理数据集中存在的巨大类不平衡。
这个小例子展示了选择正确度量来评估机器学习算法的重要性。通常,建议使用一组度量标准来评估算法,因为它们都关注数据和模型预测的不同方面。

英文原文:https://pytorch-lightning.medium.com/torchmetrics-pytorch-metrics-built-to-scale-7091b1bec919
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!