
硬核图解:YOLACT 解析
大家好,我是 Jack。
近年来的实例分割可以分为两类:
一类是 two-stage 的方法,即“先检测后分割”的方法,首先定位到目标物体的边框,然后在边框内分割目标物体,典型的代表是 Mask R-CNN;
另一类是 one-stage 的方法,这里面又细分为两个流派,一个是 anchor-based,另一个是 anchor-free。
今天个给大家讲解一个,基于 anchor-base 的实力分割算法 YOLACT。
一、论文简介
YOLACT: Real-time Instance Segmentation
1、简介
论文针对实例分割任务提出了一种简单,全卷积模型; 这个模型在COCO数据集用一块Titan Xp完成了29.8mAP和33.5fps的实时分割效果; 将任务分为两个平行的子任务。产生prototype masks和预测mask coefficients; prototype masks
卷积层:在提取空间相关信息上效果显著。mask coefficients
全连接层:在获取语义向量上效果显著。利用矩阵计算对NMS进行加速。
2、模型结构
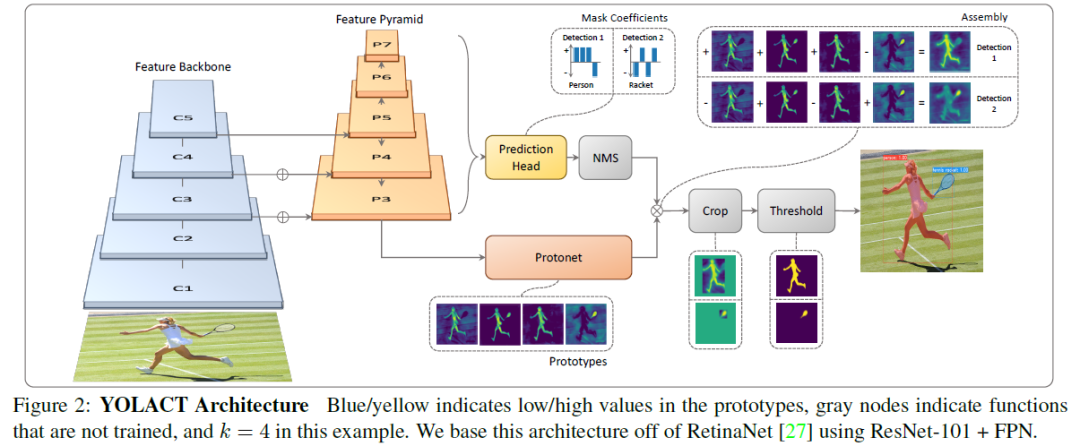
Feature Backbone
此模块主要是利用卷积神经网络做特征提取,然后将提取到的特征输入到特征金字塔网络中。Feature Pyraimd
利用此模块获取深度更深的特征图,且含有多个不同尺度的特征图。Protonet
此模块通过卷积和上采样获得Prototypes,Prototypes是多张mask的,mask中的亮(值大)的区域就是目标区域。最终通过线性组合生成的mask来获取每个实例的mask。Prediction Head
本文在RetinaNet的基础上多回归了一个mask系数,输出预测框Bbox,类别信息conf以及掩码系数。利用此系数与Protonet中的mask线性组合。Yolact利用特征金字塔中的特征图(5个尺度)每个特征图的每个点都生成3个目标框NMS 由于目标框数量较多,利用非极大抑制进行目标框筛选。
Masks Assembly
利用Prediction Head模块的mask系数与Protonet中的多张mask进行线性组合,每个目标得到一张mask。Crop&Threshold
利用Prediction Head中未被过滤掉目标的预测框Bbox以及类别信息对Masks Assembly中输出的mask进行截取Crop操作,再经阈值处理得到最终的mask。
二、COCO数据集解析
COCO的官网 : https://cocodataset.org/
COCO API : https://github.com/cocodataset/cocoapi
1、简介
图像包括91类目标, 328,000影像和2,500,000个label。目前为止有语义分割的最大数据集,提供的类别有80 类, 有超过33 万张图片,其中20 万张有标注,整个数据集中个体的数目超过150 万个。

2、 pycocotools工具
COCO官方给的数据集解析工具
三、FPN
原文:feature pyramid networks for object detection
1、特征金字塔
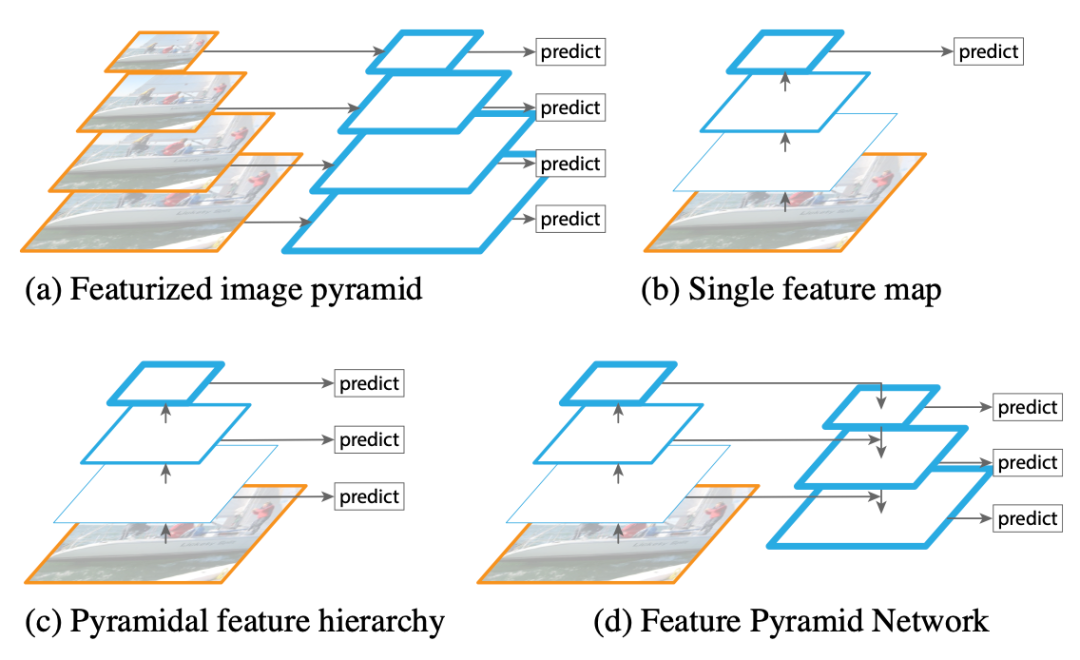
图像金字塔(图像处理) 将图像做成不同的scale -> 测试增强(TTA) 基础CNN结构(单层特征图) 可做分类器 多尺度特征融合 从不同层抽取不同尺度特征做预测 --> SSD(single shot detector) 特征金字塔网络 与3相比,增加了通过高层特征进行上采样和底层特征进行自顶向下的连接,然后再预测,大幅提升了对小物体的检测效果 --> Retinanet
2、组成
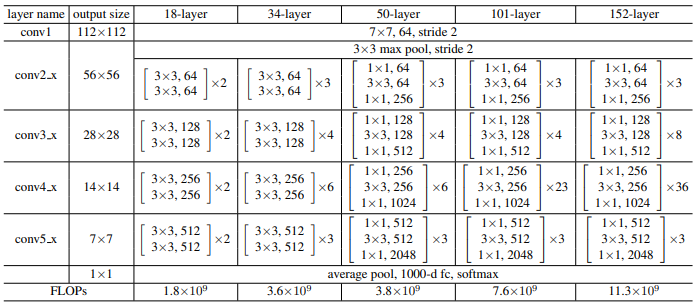
backbone(以resnet为例):
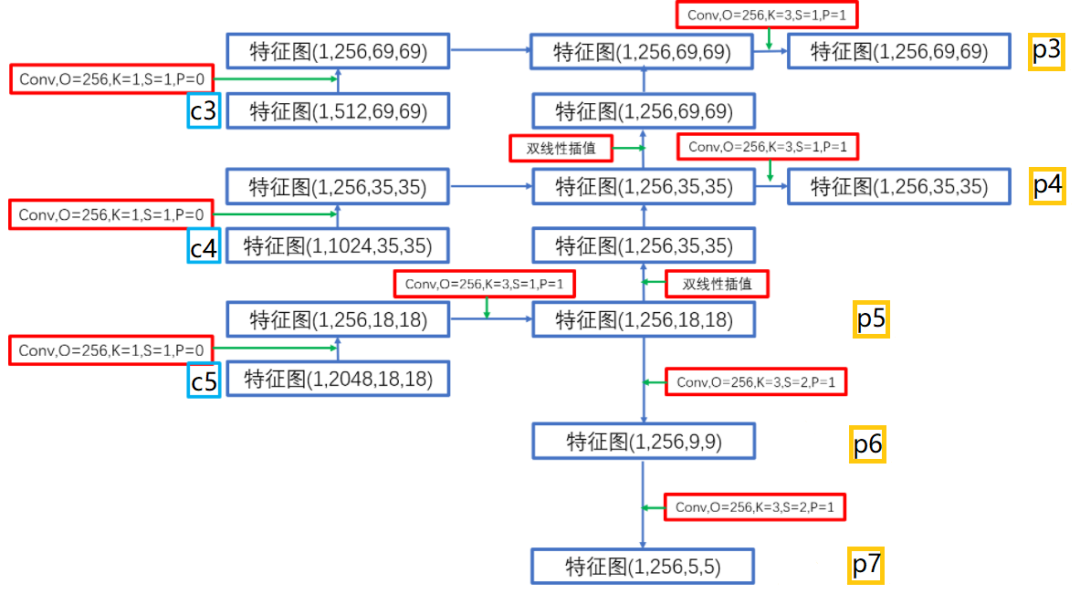
输入:batchsize,3,550,550
conv1 -> batchsize,64,275,275
c2:-> batchsize,64,138,138 -> batchsize,256,138,138
c3:->batchsize,128,69,69 -> batchsize,512,69,69
c4:->batchsize,256,35,35 -> batchsize,1024,35,35
c5:->batchsize,512,18,18 -> batchsize,2048,18,18
FPN:
上采样:双线性插值 下采样:卷积(步长为2) p7(256,5,5) :通过p6下采样
p6(256,9,9) :通过p5下采样
p5(256,18,18) : c5通过两次卷积通道数变为256
p4(256,35,35) : c4通过两次卷积通道数变为256 + c5上采样
p3(256,69,69) : c3通过两次卷积通道数变为256 + c4上采样
四、Prototype
protonet:预测k个prototype masks(通过FCN生成k个通道的)如下图protonet:

越深的backbone features获得更鲁棒的masks。->利用特征金字塔网络(FPN)作为backbone 高分辨率的prototypes结果有更好的masks且在较小的对象上表现出更好的性能。->上采样到原图的1/4增高分辨率 此处用FPN的p3作为protonet输入通过卷积和双线性插值获得一个mask热度图(bs, 138, 138, 32)
五、mask coefficients
1、Head Architecture
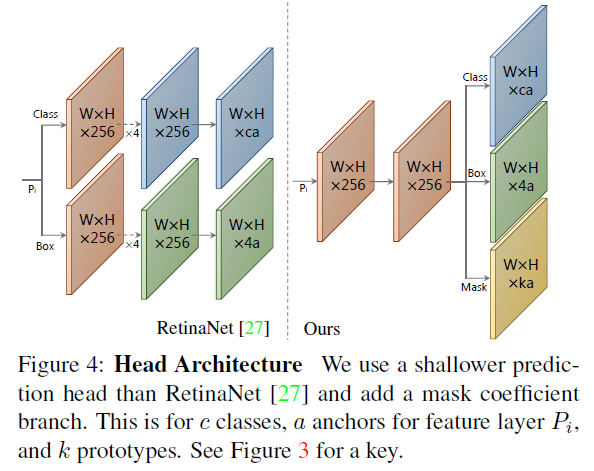
FPN得到了5种不同尺度的特征图,分别预测dict_keys(['loc', 'conf', 'mask', 'priors'])
'loc':每个anchorbox的预测偏移量,形状为(1,19248,)
'conf':每个anchorbox的类别预测,形状为(1,19248,num_class)
'mask':就是论文中指出的mask系数,形状为(1,9248,2)
'priors':预设的anchorbox的坐标,形状为(19248,4)
2、fast_NMS
非极大抑制

利用conf降序排序(移除conf太小且IoU太大的检测框)
fast_NMS:利用矩阵进行加速
六、Masks Assembly
线性组合protonet -> 每个目标(item)都有mask(热图形式), confident(包含类别信息和概率), bbox(通过loc和priors获得
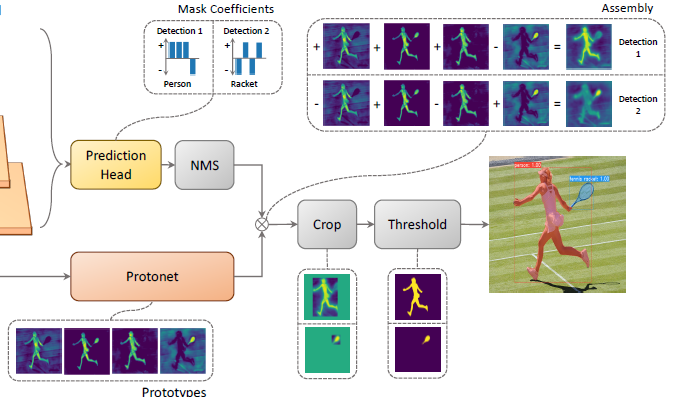
然后根据回归出的检测框(bbox)对mask进行截取,根据所在目标框的mask进行阈值处理转化为掩码形式(是,否)。
