
【时间序列】时间序列建模的时间戳与时序特征衍生思路
共 5045字,需浏览 11分钟
·
2022-02-26 18:05
特征锦囊:时间序列建模的时间戳与时序特征衍生思路
时间序列模型在我们日常工作中应用的场景还是会很多的,比如我们去预测未来的销售单量、预测股票价格、预测期货走势、预测酒店入住等等,这也是我们必须要掌握时序建模的原因。而关于时间戳以及时序值的特征衍生,在建模过程中起到的作用是十分巨大的!之前写过一篇关于日期特征操作的文章——《关于日期特征,你想知道操作都在这儿~》,可以先回顾下,里面有关于日期特征的基础操作手法。
🚅 Index
01 时间序列数据类别简介
02 时间戳的衍生思路
03 时间戳的衍生代码分享
04 时序值的衍生思路
05 时序值的衍生代码分享
🏆 01 时间序列数据类别简介
我们就拿经典的时间序列模型来说一下,一般来说数据集里的数据,可以分为3大类。
1)Y值:我们也称之为时序值。如下表中的销量字段;
2)时间戳:标记本条记录发生时间的字段,如下表中的统计日期字段。oh,对了如果不是单时间序列的,比如数据集中记录的是多家店铺的时序数据,需要结合序列属性信息,比如店铺名称、店铺所在城市;
3)其他字段:顾名思义。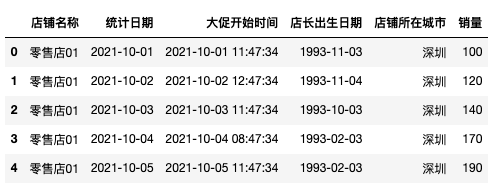 而我们今天关注的是时间戳和时序值的特征衍生。
而我们今天关注的是时间戳和时序值的特征衍生。
🏆 02 时间戳的衍生思路
虽然时间戳就只有1个字段,但里面其实包含的信息量还是很多的,一般来说我们可以从下面几个角度来拆解,衍生出一系列的变量。
1)时间戳本身特征
直接使用Pandas的series提取时间戳特征,比如说哪年、哪季度、哪月、哪周、哪日、哪时、哪分、哪秒、年里的第几天、月里的第几天、周里的第几天。
2)0-1特征
一般是与真实场景结合来用,比如说工作日、周末、公众假日(春节、端午节、中秋节等)、X初、X中、X末(X代表年、季度、月、周)、特殊节日(如运营暂停、服务暂停)、日常习惯叫法(如清晨、上午、中午、下午、傍晚、夜晚、深夜、凌晨),从而可以衍生出:
是否工作日 是否春节 是否月初 是否服务期外 是否凌晨 等等等等
3)时间差特征
一般也是与真实场景结合来用,比如说工作日、周末等等,比如:
距离春节还有N天 距离周末还有N天 举例下月初还有N天 等等等等
🏆 03 时间戳的衍生代码分享
首先我们捏造一些数据,用来测试代码。
# 导入相关库包
import pandas as pd
import numpy as np
import datetime
import time
import random
from calendar import monthrange
# 捏造数据
df = pd.DataFrame(
[['零售店01', '2021-10-01', '2021-10-01 11:47:34', '1993-11-03', '深圳', 100],
['零售店01', '2021-10-02', '2021-10-02 12:47:34', '1993-11-04', '深圳', 120],
['零售店01', '2021-10-03', '2021-10-03 11:47:34', '1993-10-03', '深圳', 140],
['零售店01', '2021-10-04', '2021-10-04 08:47:34', '1993-02-03', '深圳', 170],
['零售店01', '2021-10-05', '2021-10-05 11:47:34', '1993-02-03', '深圳', 190],
['零售店01', '2021-10-06', '2021-10-06 15:47:34', '1993-04-03', '深圳', 10],
['零售店01', '2021-10-07', '2021-10-07 17:47:34', '1993-02-03', '深圳', 20],
['零售店01', '2021-10-08', '2021-10-08 19:47:34', '1993-06-03', '深圳', 420],
['零售店01', '2021-10-09', '2021-10-09 11:47:34', '1993-03-03', '深圳', 230],
['零售店01', '2021-10-10', '2021-10-10 20:47:34', '1993-02-20', '深圳', 80]
]
,columns=['店铺名称', '统计日期', '大促开始时间', '店长出生日期', '店铺所在城市', '销量'])
df.head()
1)时间戳本身特征
这个就是提取datetime本身的实体特征,利用Pandas的Series方法即可。
# 原先属于字符串,转datetime
df['datetime64'] = pd.to_datetime(df['统计日期'])
df['year'] = df['datetime64'].dt.year
df['quarter'] = df['datetime64'].dt.quarter
df['month'] = df['datetime64'].dt.month
df['week'] = df['datetime64'].dt.week
df['day'] = df['datetime64'].dt.day
df['hour'] = df['datetime64'].dt.hour
df['minute'] = df['datetime64'].dt.minute
df['second'] = df['datetime64'].dt.second
df['weekday'] = df['datetime64'].dt.weekday
df['weekofyear'] = df['datetime64'].dt.weekofyear
df['dayofyear'] = df['datetime64'].dt.dayofyear
df['dayofweek'] = df['datetime64'].dt.dayofweek
2)0-1特征
这里我们需要引入一些关于真实场景的日期来结合着判断是否。
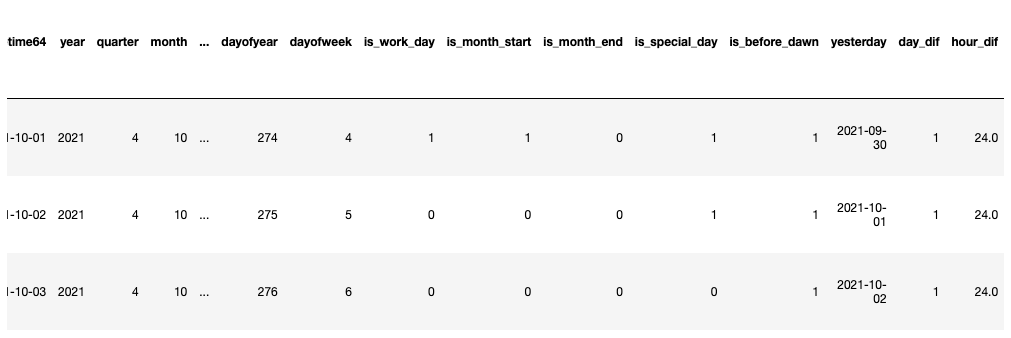
df['is_work_day'] = np.where(df['dayofweek'].isin([5,6]), 0, 1) # 是否工作日
df['is_month_start'] = np.where(df['datetime64'].dt.is_month_start, 1, 0)
df['is_month_end'] = np.where(df['datetime64'].dt.is_month_end, 1, 0)
# 特殊日子/公众假日
special_day = ['2021-10-01','2021-10-02']
df['is_special_day'] = np.where(df['统计日期'].isin(special_day), 1, 0)
# 是否凌晨
df['is_before_dawn'] = np.where(df['hour'].isin([0,1,2,3]), 1, 0)
3)时间差特征
# 获取前一天日期
df['yesterday'] = df['datetime64'] - datetime.timedelta(days=1)
# 日期差计算(天)
df['day_dif'] = (df['datetime64'] - df['yesterday']).dt.days
# 日期差计算(小时)
df['hour_dif'] = (df['datetime64'] - df['yesterday']).values/np.timedelta64(1, 'h') # 换成 D 则为 天
🏆 04 时序值的衍生思路
本例中的时序值是销量字段,一般我们在对时序值进行操作前,需要对数据的时序进行排序和补全,然后才开始操作,时序值的特征衍生主要有几个角度。
1)时间滑动窗口统计
基于某段时间窗,统计数据情况,也叫做Rolling Window Statistics,统计的方式一般有min/max/mean/median/std/sum等,比如我们选择滑动窗口为7天,那么可以衍生的变量分别是:过去7天内销量最小值/最大值/均值/中位数/方差/之和。
在使用此类特征的时候,要注意一下多步预测的问题。
2)lag滞后值
lag可以理解为向前滑动时间,比如lag1表示向前滑动1天,即取T-1的时序值作为当前时序的变量。
🏆 05 时序值的衍生代码分享
1)时间滑动窗口统计
因为方法叫做Rolling Window Statistics,所以代码里关于这块的实现也有1个叫rolling的方法,这个方法在时序建模中很好用,后面单独一篇文章讲下。
df = df.loc[:,['店铺名称', '统计日期','销量']]
df['date'] = pd.to_datetime(df['统计日期'])
# 时序值特征衍生前记得排序
df.sort_values(['店铺名称', '统计日期'], ascending=[True,True], inplace=True)
# 衍生时间滑动窗口统计变量
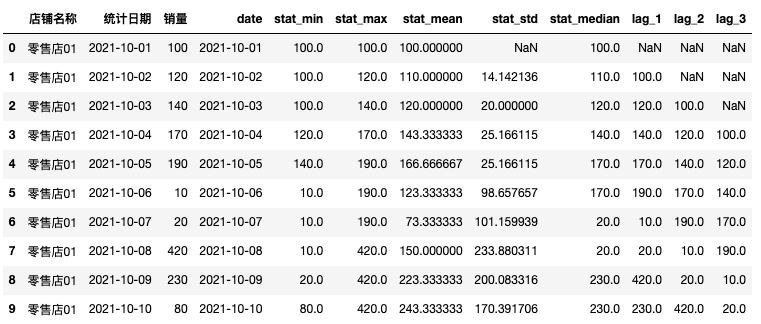
f_min = lambda x: x.rolling(window=3, min_periods=1).min()
f_max = lambda x: x.rolling(window=3, min_periods=1).max()
f_mean = lambda x: x.rolling(window=3, min_periods=1).mean()
f_std = lambda x: x.rolling(window=3, min_periods=1).std()
f_median=lambda x: x.rolling(window=3, min_periods=1).median()
function_list = [f_min, f_max, f_mean, f_std,f_median]
function_name = ['min', 'max', 'mean', 'std','median']
for i in range(len(function_list)):
df[('stat_%s' % function_name[i])] = df.sort_values('统计日期', ascending=True).groupby(['店铺名称'])['销量'].apply(function_list[i])
2)lag滞后值
# 衍生lag变量
for i in [1,2,3]:
df["lag_{}".format(i)] = df['销量'].shift(i)
📚 Reference
[1] 一度让我怀疑人生的时间戳特征处理技巧。
https://mp.weixin.qq.com/s/dUdGhWY8l77f1TiPsnjMQA
[2] 时间序列树模型特征工程汇总
https://blog.csdn.net/fitzgerald0/article/details/104029842
[3] 时间序列的多步预测方法总结
https://zhuanlan.zhihu.com/p/390093091
[4] 时间序列数据的特征工程总结
https://zhuanlan.zhihu.com/p/388551117
[5] Pandas Series dt
https://pandas.pydata.org/docs/reference/api/pandas.Series.dt.date.html
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 AI基础下载 机器学习交流qq群955171419,加入微信群请扫码: