
入门爬虫?一文搞定!

文章分三个个部分
两个爬虫库requests和selenium如何使用 html解析库BeautifulSoup如何使用 动态加载的网页数据用requests怎么抓
两个爬虫库
requests
假设windows下安装好了python和pip。
下面用pip安装爬虫库requests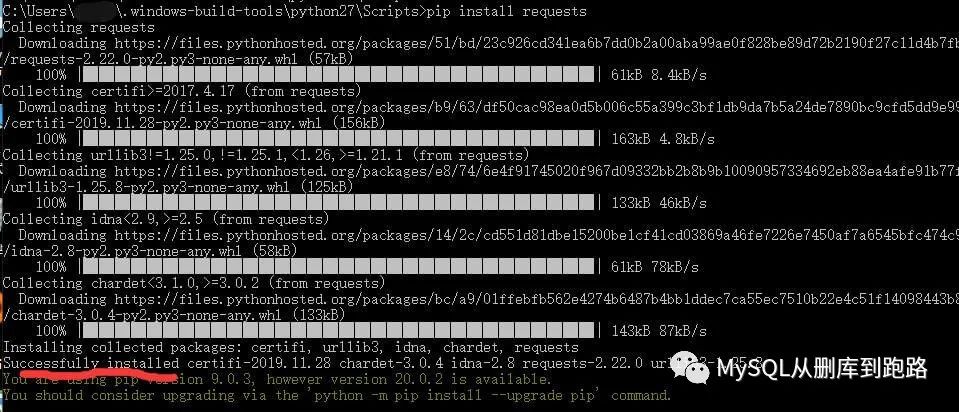
★如果提示pip版本低,不建议升级,升级后可能python本身版本低,导致pip指令报错。
”
进入Python命令行验证requests库是否能够使用
看到import requests和requests.get函数都没有报错,说明安装成功可以开发我们的第一个爬虫程序了!
将代码文件命名为test.py,用IDEL打开。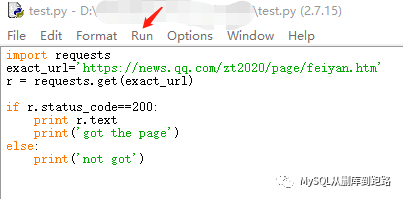
最简单的爬虫就这么几行!
引入requests库, 用get函数访问对应地址, 判定是否抓取成功的状态,r.text打印出抓取的数据。
然后菜单栏点击Run->Run Module 会弹出Python的命令行窗口,并且返回结果。我们访问的是腾讯发布新冠肺炎疫情的地址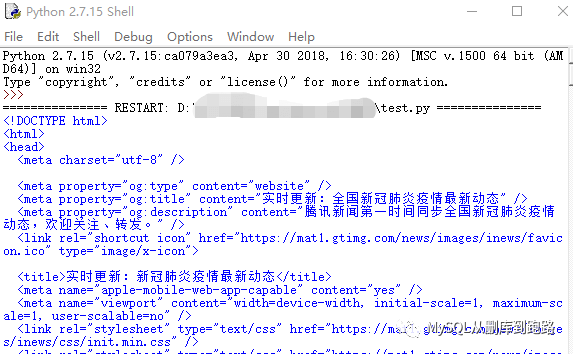
如果没有IDEL,直接cmd命令行运行按照下面执行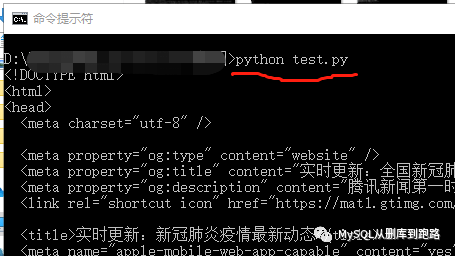
selenium
selenium库会启动浏览器,用浏览器访问地址获取数据。下面我们演示用selenium抓取网页,并解析爬取的html数据中的信息。先安装selenium
接下来安装解析html需要的bs4和lxml。
安装bs4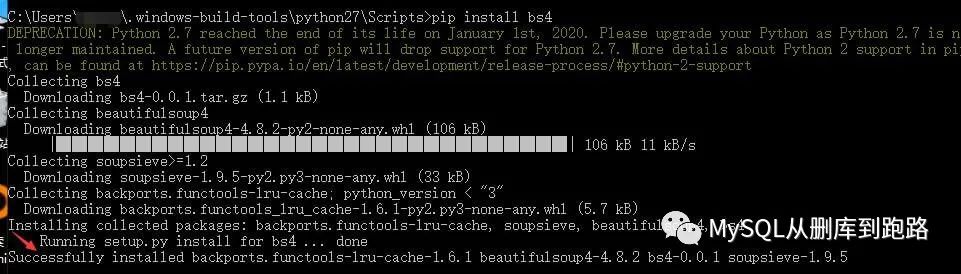
安装lxml
要确保windows环境变量path的目录下有chromedriver
我d盘的instantclient_12_2已经加到path里了。所以chromedriver解压到这个目录。chromedriver不同的版本对应Chrome浏览器的不同版本,开始我下载的chromedriver对应Chrome浏览器的版本是71-75(图中最下面的),我的浏览器版本是80所以重新下载了一个才好使。
代码如下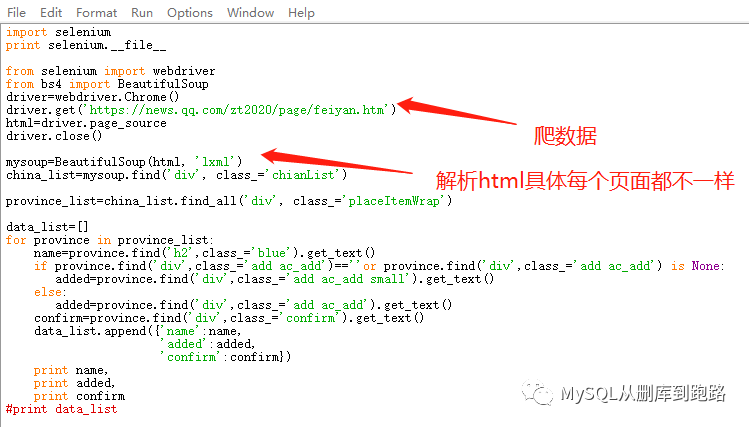
Python执行过程中会弹出
浏览器也自动启动,访问目标地址
IDEL打印结果如下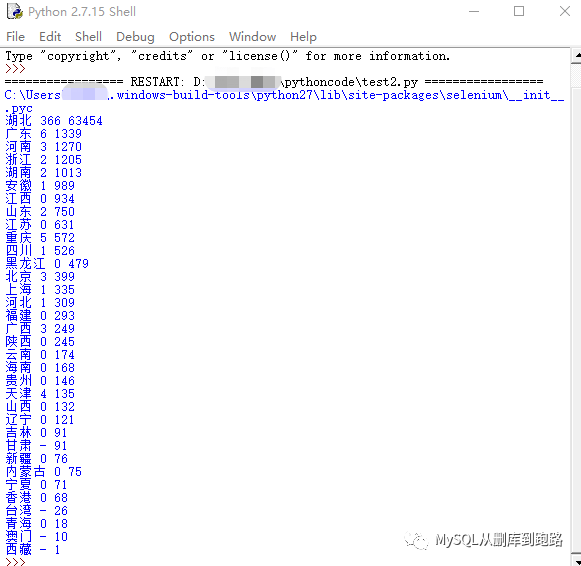
HTML解析库BeautifulSoup
selenium例子中爬取数据后使用BeautifulSoup库对html进行解析,提取了感兴趣的部分。如果不解析,抓取的就是一整个html数据,有时也是xml数据,xml数据对标签的解析和html是一样的道理,两者都是来区分数据的。这种格式的数据结构一个页面一个样子,解析起来很麻烦。BeautifulSoup提供了强大的解析功能,可以帮助我们省去不少麻烦。
使用之前安装BeautifulSoup和lxml。首先代码要引入这个库(参考上面selenium库代码)
from bs4 import BeautifulSoup
然后,抓取
r = request.get(url)
r.encoding='utf8'
html=r.read() #urlopen获取的内容都在html中
mysoup=BeautifulSoup(html, 'lxml') #html的信息都在mysoup中了
假设我们对html中的如下部分数据感兴趣
20200214
1
11
张三
20200214
4
17
李斯
首先要找到tag标签为的数据,而这类数据不止一条,我们以两条为例。那么需要用到beautifulsoup的find_all函数,返回的结果应该是两个数据。当处理每一个数据时,里面的等标签都是唯一的,这时使用find函数。
mysoup=BeautifulSoup(html, 'lxml')
data_list=mysoup.find_all('data')
for data in data_list:#list应该有两个元素
day = data.find('day').get_text() #get_text是获取字符串,可以用.string代替
id = data.find('id').get_text()
rank = data.find('rank').get_text()
name = data.find('name').get_text()
#print name 可以print测试解析结果
这是beautifulsoup最简单的用法,find和find_all不仅可以按照标签的名字定位元素,还可以按照class,style等各种属性,以及文本内容text作为条件来查找你感兴趣的内容,非常强大。
requests库如何抓取网页的动态加载数据
还是以新冠肺炎的疫情统计网页为例。本文开头requests例子最后打印的结果里面只有标题、栏目名称之类的,没有累计确诊、累计死亡等等的数据。因为这个页面的数据是动态加载上去的,不是静态的html页面。需要按照我上面写的步骤来获取数据,关键是获得URL和对应参数formdata。下面以火狐浏览器讲讲如何获得这两个数据。
肺炎页面右键,出现的菜单选择检查元素。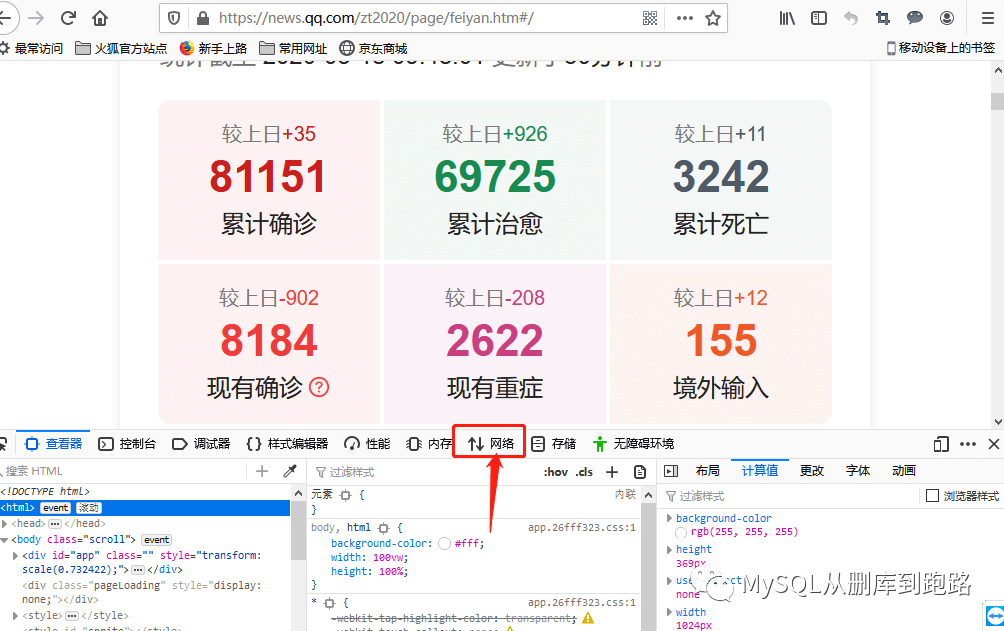
点击上图红色箭头网络选项,然后刷新页面。如下,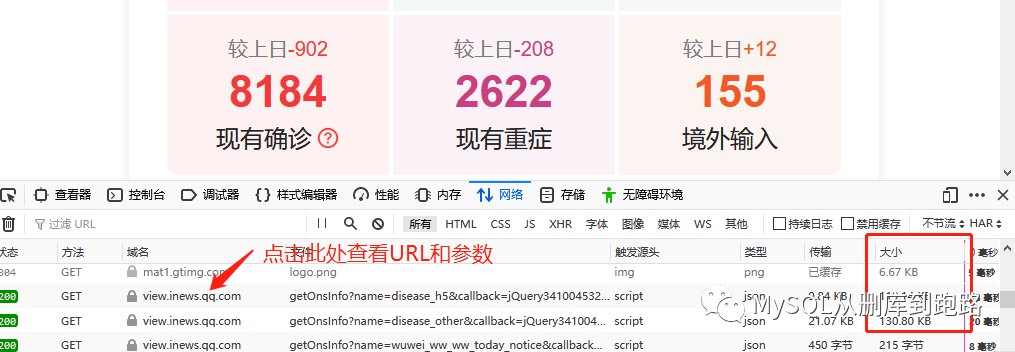
这里会出现很多网络传输记录,观察最右侧红框“大小”那列,这列表示这个http请求传输的数据量大小,动态加载的数据一般数据量会比其它页面元素的传输大,119kb相比其它按字节计算的算是很大的数据了,当然网页的装饰图片有的也很大,这个需要按照文件类型那列来甄别。
url带参数
然后点击域名列对应那行,如下
可以在消息头中看见请求网址,url的尾部问号后面已经把参数写上了。
图中url解释,name是disease_h5,callback是页面回调函数,我们不需要有回调动作,所以设置为空,_对应的是时间戳(Python很容易获得时间戳的),因为查询肺炎患者数量和时间是紧密相关的。
我们如果使用带参数的URL,那么就用
url='网址/g2/getOnsInfo?name=disease_h5&callback=&_=%d'%int(stamp*1000)
requests.get(url)
url和参数分离
点击参数可以看见url对应的参数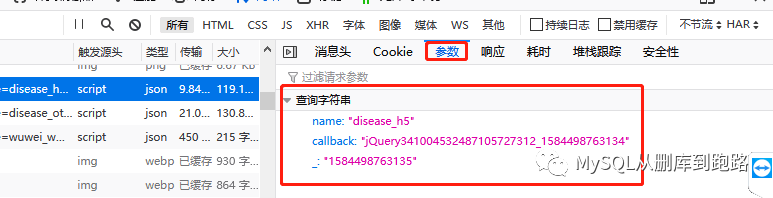
如果使用参数和url分离的形式那么
那么就这样
url="网址/g2/getOnsInfo"
formdata = {'name': 'disease_h5',
'callback': '',
'_': 当前时间戳
}
requests.get(url, formdata)
找url和参数需要耐心分析,才能正确甄别url和参数的含义,进行正确的编程实现。参数是否可以空,是否可以硬编码写死,是否有特殊要求,比较依赖经验。
总结
学完本文,阅读爬虫代码就很容易了,所有代码都是为了成功get到url做的准备以及抓到数据之后的解析而已。
有的url很简单,返回一个.dat文件,里面直接就是json格式的数据。有的需要设置大量参数,才能获得,而且获得的是html格式的,需要解析才能提取数据。
爬到的数据可以存入数据库,写入文件,也可以现抓现展示不存储。

往期推荐


以上三位小伙伴,快来联系小编领取小小红包一份哦!小编微信:Mayyy530
