
为什么list.sort()比Stream().sorted()更快?
你知道的越多,不知道的就越多,业余的像一棵小草!
你来,我们一起精进!你不来,我和你的竞争对手一起精进!
编辑:业余草
来源:juejin.cn/post/7262274383287500860
推荐:https://t.zsxq.com/10kIjsBVG
自律才能自由
看到一个评论,里面提到了list.sort()和list.strem().sorted()排序的差异。
说到list.sort()排序比stream().sorted()排序性能更好。
但没说到为什么。

有朋友也提到了这一点。
本文重新开始,先问是不是,再问为什么。
真的更好吗?
先简单写个 demo。
List<Integer> userList = new ArrayList<>();
Random rand = new Random();
for (int i = 0; i < 10000 ; i++) {
userList.add(rand.nextInt(1000));
}
List<Integer> userList2 = new ArrayList<>();
userList2.addAll(userList);
Long startTime1 = System.currentTimeMillis();
userList2.stream().sorted(Comparator.comparing(Integer::intValue)).collect(Collectors.toList());
System.out.println("stream.sort耗时:"+(System.currentTimeMillis() - startTime1)+"ms");
Long startTime = System.currentTimeMillis();
userList.sort(Comparator.comparing(Integer::intValue));
System.out.println("List.sort()耗时:"+(System.currentTimeMillis()-startTime)+"ms");
输出
stream.sort耗时:62ms
List.sort()耗时:7ms
由此可见 list 原生排序性能更好。
能证明吗?
不一定吧。
再把 demo 变换一下,先输出stream.sort。
List<Integer> userList = new ArrayList<>();
Random rand = new Random();
for (int i = 0; i < 10000 ; i++) {
userList.add(rand.nextInt(1000));
}
List<Integer> userList2 = new ArrayList<>();
userList2.addAll(userList);
Long startTime = System.currentTimeMillis();
userList.sort(Comparator.comparing(Integer::intValue));
System.out.println("List.sort()耗时:"+(System.currentTimeMillis()-startTime)+"ms");
Long startTime1 = System.currentTimeMillis();
userList2.stream().sorted(Comparator.comparing(Integer::intValue)).collect(Collectors.toList());
System.out.println("stream.sort耗时:"+(System.currentTimeMillis() - startTime1)+"ms");
此时输出变成了。
List.sort()耗时:68ms
stream.sort耗时:13ms
这能证明上面的结论错误了吗?
都不能。
两种方式都不能证明到底谁更快。
使用这种方式在很多场景下是不够的,某些场景下,JVM 会对代码进行 JIT 编译和内联优化。
Long startTime = System.currentTimeMillis();
...
System.currentTimeMillis() - startTime
此时,代码优化前后执行的结果就会非常大。
❝基准测试是指通过设计科学的测试方法、测试工具和测试系统,实现对一类测试对象的某项性能指标进行定量的和可对比的测试。
❞
基准测试使得被测试代码获得足够预热,让被测试代码得到充分的 JIT 编译和优化。
下面是通过 JMH 做一下基准测试,分别测试集合大小在 100,10000,100000 时两种排序方式的性能差异。
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.infra.Blackhole;
import org.openjdk.jmh.results.format.ResultFormatType;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.*;
import java.util.concurrent.ThreadLocalRandom;
import java.util.concurrent.TimeUnit;
import java.util.stream.Collectors;
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
@Warmup(iterations = 2, time = 1)
@Measurement(iterations = 5, time = 5)
@Fork(1)
@State(Scope.Thread)
public class SortBenchmark {
@Param(value = {"100", "10000", "100000"})
private int operationSize;
private static List<Integer> arrayList;
public static void main(String[] args) throws RunnerException {
// 启动基准测试
Options opt = new OptionsBuilder()
.include(SortBenchmark.class.getSimpleName())
.result("SortBenchmark.json")
.mode(Mode.All)
.resultFormat(ResultFormatType.JSON)
.build();
new Runner(opt).run();
}
@Setup
public void init() {
arrayList = new ArrayList<>();
Random random = new Random();
for (int i = 0; i < operationSize; i++) {
arrayList.add(random.nextInt(10000));
}
}
@Benchmark
public void sort(Blackhole blackhole) {
arrayList.sort(Comparator.comparing(e -> e));
blackhole.consume(arrayList);
}
@Benchmark
public void streamSorted(Blackhole blackhole) {
arrayList = arrayList.stream().sorted(Comparator.comparing(e -> e)).collect(Collectors.toList());
blackhole.consume(arrayList);
}
}
性能测试结果:
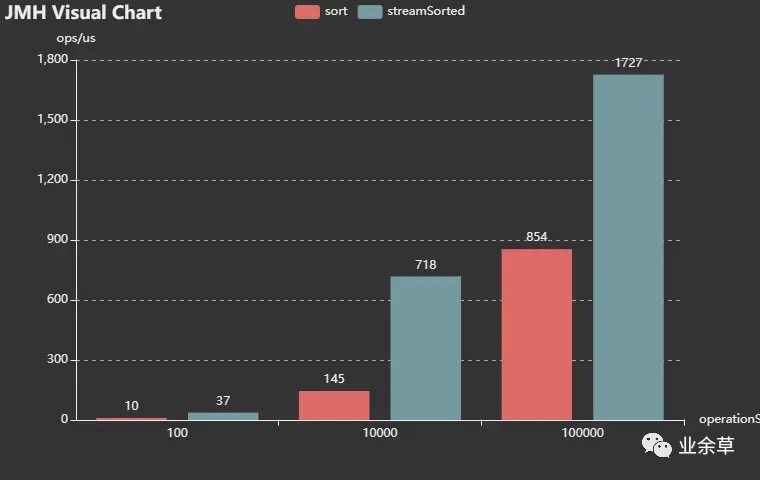
可以看到,list.sort()效率确实比stream().sorted()要好。
为什么更好?
流本身的损耗
java 的 stream 让我们可以在应用层就可以高效地实现类似数据库 SQL 的聚合操作了,它可以让代码更加简洁优雅。
但是,假设我们要对一个 list 排序,得先把 list 转成 stream 流,排序完成后需要将数据收集起来重新形成 list,这部份额外的开销有多大呢?
我们可以通过以下代码来进行基准测试。
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.infra.Blackhole;
import org.openjdk.jmh.results.format.ResultFormatType;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
import java.util.Random;
import java.util.concurrent.TimeUnit;
import java.util.stream.Collectors;
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
@Warmup(iterations = 2, time = 1)
@Measurement(iterations = 5, time = 5)
@Fork(1)
@State(Scope.Thread)
public class SortBenchmark3 {
@Param(value = {"100", "10000"})
private int operationSize; // 操作次数
private static List<Integer> arrayList;
public static void main(String[] args) throws RunnerException {
// 启动基准测试
Options opt = new OptionsBuilder()
.include(SortBenchmark3.class.getSimpleName()) // 要导入的测试类
.result("SortBenchmark3.json")
.mode(Mode.All)
.resultFormat(ResultFormatType.JSON)
.build();
new Runner(opt).run(); // 执行测试
}
@Setup
public void init() {
// 启动执行事件
arrayList = new ArrayList<>();
Random random = new Random();
for (int i = 0; i < operationSize; i++) {
arrayList.add(random.nextInt(10000));
}
}
@Benchmark
public void stream(Blackhole blackhole) {
arrayList.stream().collect(Collectors.toList());
blackhole.consume(arrayList);
}
@Benchmark
public void sort(Blackhole blackhole) {
arrayList.stream().sorted(Comparator.comparing(Integer::intValue)).collect(Collectors.toList());
blackhole.consume(arrayList);
}
}
方法 stream 测试将一个集合转为流再收集回来的耗时。
方法 sort 测试将一个集合转为流再排序再收集回来的全过程耗时。
测试结果如下:
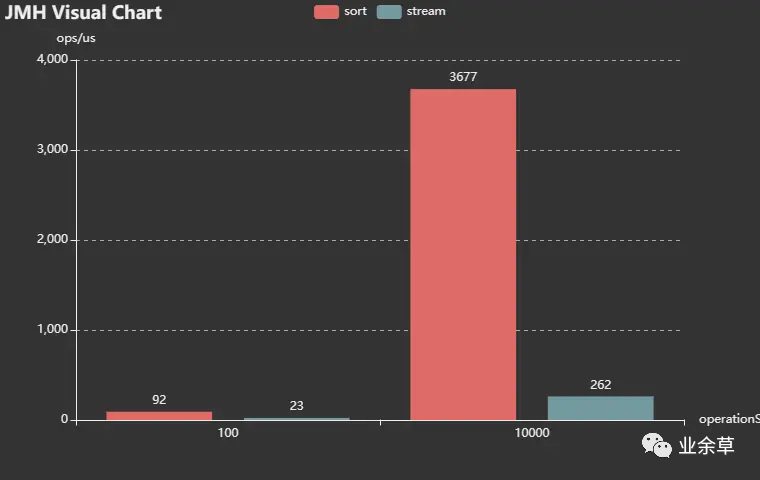
可以发现,集合转为流再收集回来的过程,肯定会耗时,但是它占全过程的比率并不算高。
因此,这部只能说是小部份的原因。
排序过程
我们可以通过以下源码很直观的看到。
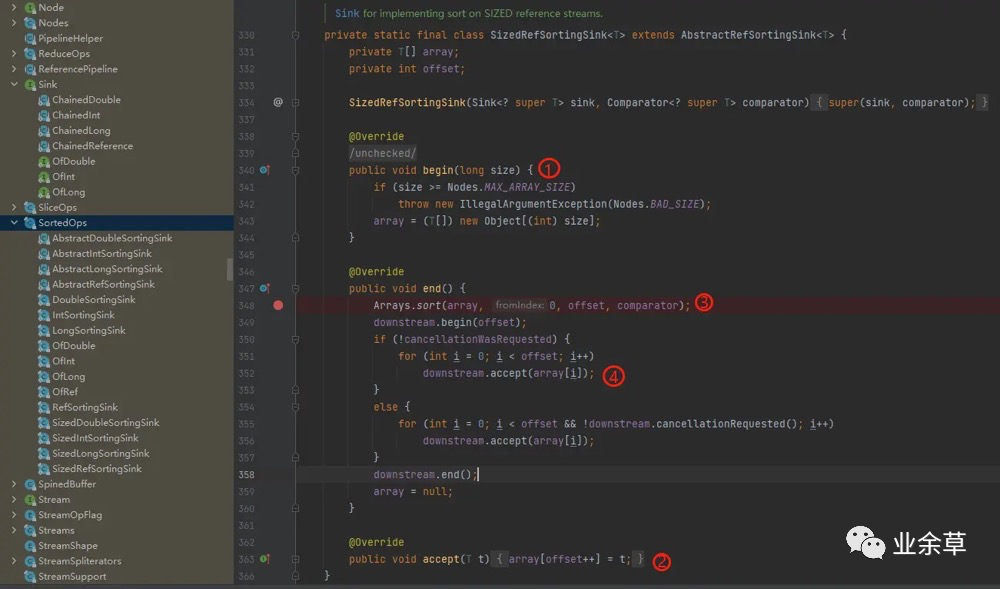
-
1 begin方法初始化一个数组。 -
2 accept 接收上游数据。 -
3 end 方法开始进行排序。
这里第 3 步直接调用了原生的排序方法,完成排序后,第 4 步,遍历向下游发送数据。
所以通过源码,我们也能很明显地看到,stream()排序所需时间肯定是 > 原生排序时间。
只不过,这里要量化地搞明白,到底多出了多少,这里得去编译 jdk 源码,在第 3 步前后将时间打印出来。
这一步我就不做了。
感兴趣的朋友可以去测一下。
不过我觉得这两点也能很好地回答,为什么list.sort()比Stream().sorted()更快。
补充说明:
-
本文说的 stream() 流指的是串行流,而不是并行流。 -
绝大多数场景下,几百几千几万的数据,开心就好,怎么方便怎么用,没有必要去计较这点性能差异。