
超详细:从认识链表到学会反转链表
来源:码海
作者:码海
如果说数据结构是算法的基础,那么数组和链表就是数据结构的基础。因为像堆,栈,树,图等比较复杂的数组结基本上都可以由数组和链表来表示,所以掌握数组和链表的基本操作十分重要。
链表的知识点蛮多的,所以分成上下两篇,这篇主要讲解链表翻转的解题技巧,下篇主要讲关于链表快慢指针的知识点,干货很多,建议先收藏再看。认真看完保证收获满满!
今天就来看看链表的基本操作及其在面试中的常见解题思路,本文将从以下几个点来讲解链表的核心知识
- 什么是链表,链表的优缺点
- 链表的表示及基本操作
- 面试中链表的常见解题思路---翻转
什么是链表
相信大家已经开始迫不及待地想用链表解题了,不过在开始之前我们还是要先来温习下链表的定义,以及它的优势与劣势,磨刀不误砍柴功!
链表的定义
链表是物理存储单元上非连续的、非顺序的存储结构,它是由一个个结点,通过指针来联系起来的,其中每个结点包括数据和指针。

链表的非连续,非顺序,对应数组的连续,顺序,我们来看看整型数组 1,2,3,4 在内存中是如何表示的
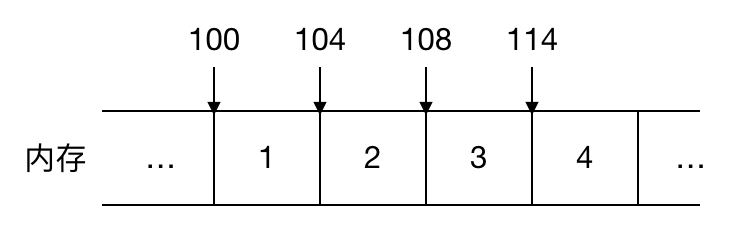 可以看到数组的每个元素都是连续紧邻分配的,这叫连续性,同时由于数组的元素占用的大小是一样的,在 Java 中 int 型大小固定为 4 个字节,所以如果数组的起始地址是 100, 由于这些元素在内存中都是连续紧邻分配的,大小也一样,可以很容易地找出数组中任意一个元素的位置,比如数组中的第三个元素起始地址为 100 + 2 * 4 = 108,这就叫顺序性。查找的时间复杂度是O(1),效率很高!
可以看到数组的每个元素都是连续紧邻分配的,这叫连续性,同时由于数组的元素占用的大小是一样的,在 Java 中 int 型大小固定为 4 个字节,所以如果数组的起始地址是 100, 由于这些元素在内存中都是连续紧邻分配的,大小也一样,可以很容易地找出数组中任意一个元素的位置,比如数组中的第三个元素起始地址为 100 + 2 * 4 = 108,这就叫顺序性。查找的时间复杂度是O(1),效率很高!
那链表在内存中是怎么表示的呢

可以看到每个结点都分配在非连续的位置,结点与结点之间通过指针连在了一起,所以如果我们要找比如值为 3 的结点时,只能通过结点 1 从头到尾遍历寻找,如果元素少还好,如果元素太多(比如超过一万个),每个元素的查找都要从头开始查找,时间复杂度是O(n),比起数组的 O(1),差距不小。
除了查找性能链表不如数组外,还有一个优势让数组的性能高于链表,这里引入程序局部性原理,啥叫程序局部性原理。
我们知道 CPU 运行速度是非常快的,如果 CPU 每次运算都要到内存里去取数据无疑是很耗时的,所以在 CPU 与内存之间往往集成了挺多层级的缓存,这些缓存越接近CPU,速度越快,所以如果能提前把内存中的数据加载到如下图中的 L1, L2, L3 缓存中,那么下一次 CPU 取数的话直接从这些缓存里取即可,能让CPU执行速度加快,那什么情况下内存中的数据会被提前加载到 L1,L2,L3 缓存中呢,答案是当某个元素被用到的时候,那么这个元素地址附近的的元素会被提前加载到缓存中
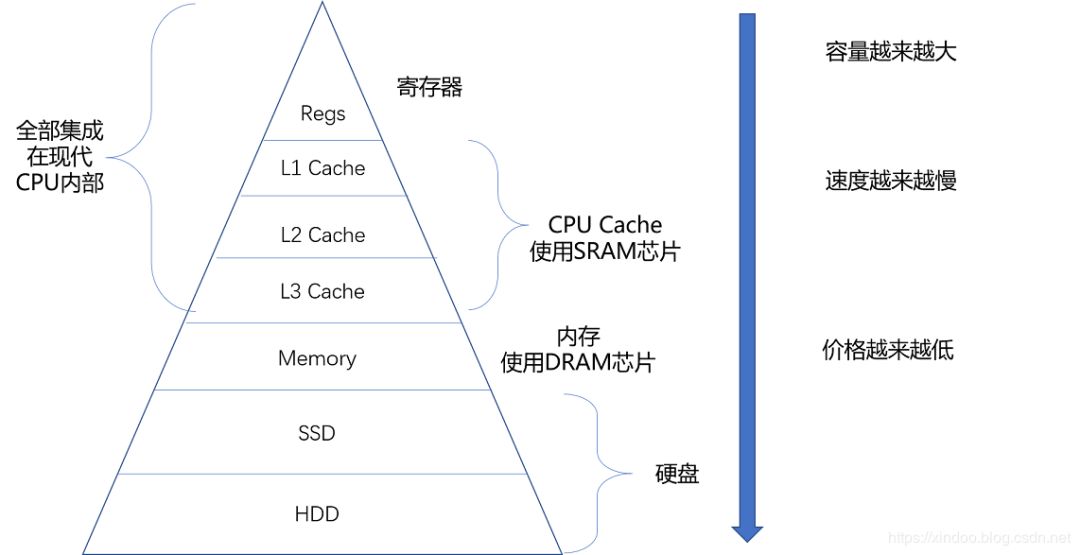
以上文整型数组 1,2,3,4为例,当程序用到了数组中的第一个元素(即 1)时,由于 CPU 认为既然 1 被用到了,那么紧邻它的元素 2,3,4 被用到的概率会很大,所以会提前把 2,3,4 加到 L1,L2,L3 缓存中去,这样 CPU 再次执行的时候如果用到 2,3,4,直接从 L1,L2,L3 缓存里取就行了,能提升不少性能
画外音:如果把 CPU 的一个时种看成一秒,则从 L1 读取数据需要 3 秒,从 L2 读取需要 11 秒,L3读取需要 25秒,而从内存读取呢,需要 1 分 40 秒,所以程序局部性原理能对 CPU 执行性能有很大的提升
而链表呢,由于链表的每个结点在内存里都是随机分布的,只是通过指针联系在一起,所以这些结点的地址并不相邻,自然无法利用 程序局部性原理 来提前加载到 L1,L2,L3 缓存中来提升程序性能。
画外音:程序局部性原理是计算机中非常重要的原理,这里不做展开,建议大家查阅相关资料详细了解一下
如上所述,相比数组,链表的非连续,非顺序确实让它在性能上处于劣势,那什么情况下该使用链表呢?考虑以下情况
- 大内存空间分配
由于数组空间的连续性,如果要为数组分配 500M 的空间,这 500M 的空间必须是连续的,未使用的,所以在内存空间的分配上数组的要求会比较严格,如果内存碎片太多,分配连续的大空间很可能导致失败。而链表由于是非连续的,所以这种情况下选择链表更合适。
- 元素频繁删除和插入
如果涉及到元素的频繁删除和插入,用链表就会高效很多,对于数组来说,如果要在元素间插入一个元素,需要把其余元素一个个往后移(如图示),以为新元素腾空间(同理,如果是删除则需要把被删除元素之后的元素一个个往前移),效率上无疑是比较低的。
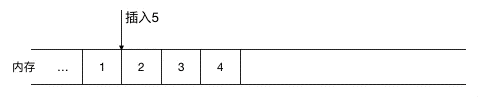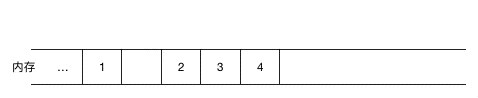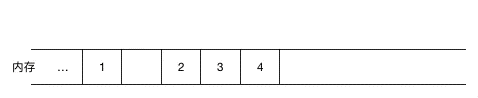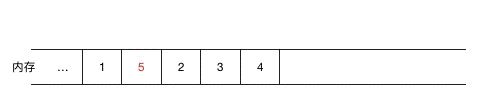 (在 1,2 间插入 5,需要把2,3,4 同时往后移一位)
(在 1,2 间插入 5,需要把2,3,4 同时往后移一位)
而链表的插入删除相对来说就比较简单了,修改指针位置即可,其他元素无需做任何移动操作(如图示:以插入为例)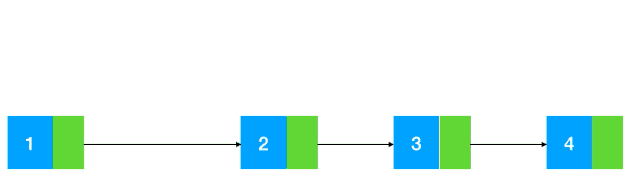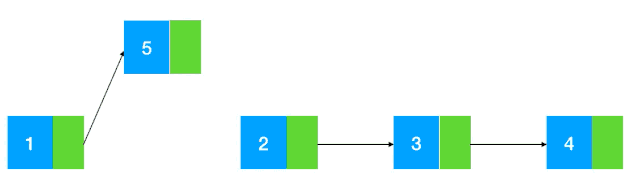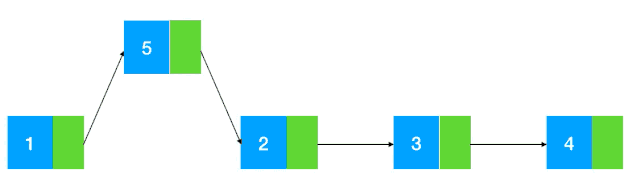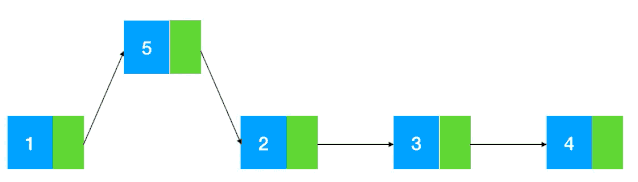
综上所述:如果数据以查为主,很少涉及到增和删,选择数组,如果数据涉及到频繁的插入和删除,或元素所需分配空间过大,倾向于选择链表。
说了这么多理论,相信读者对数组和链表的区别应该有了更深刻地认识了,尤其是 程序局部性原理,是不是开了不少眼界^_^,如果面试中问到数组和链表的区别能回答到程序局部性原理,会是一个非常大的亮点!
接下来我们来看看链表的表现形式和解题技巧
需要说明的是有些代码像打印链表等限于篇幅的关系没有在文中展示,我把文中所有相关代码都放到 github 中了,大家如果需要,可以访问我的 github 地址: https://github.com/allentofight/algorithm 下载运行(微信不支持外链,建议大家 copy 之后浏览器打开再下载运行),文中所有代码均已用 Java 实现并运行通过
链表的表示
由于链表的特点(查询或删除元素都要从头结点开始),所以我们只要在链表中定义头结点即可,另外如果要频繁用到链表的长度,还可以额外定义一个变量来表示。
需要注意的是这个头结点的定义是有讲究的,一般来说头结点有两种定义形式,一种是直接以某个元素结点为头结点,如下

一种是以一个虚拟的节点作为头结点,即我们常说的哨兵,如下

定义这个哨兵有啥好处呢,假设我们不定义这个哨兵,来看看链表及添加元素的基本操作怎么定义的
/**
* 链表中的结点,data代表节点的值,next是指向下一个节点的引用
*/
class Node {
int data;// 结点的数组域,值
Node next = null;// 节点的引用,指向下一个节点
public Node(int data) {
this.data = data;
}
}
/**
* 链表
*/
public class LinkedList {
int length = 0; // 链表长度,非必须,可不加
Node head = null; // 头结点
public void addNode(int val) {
if (head == null) {
head = new Node(val);
} else {
Node tmp = head;
while (tmp.next != null) {
tmp = tmp.next;
}
tmp.next = new Node(val);
}
}
}
发现问题了吗,注意看下面代码
有两个问题:
- 每插入一个元素都要对头结点进行判空比较,如果一个链表有很多元素需要插入,就需要进行很多次的判空处理,不是那么高效
- 头结点与其他结点插入逻辑不统一(一个需要判空后再插入,一个不需要判空直接插入),从程序逻辑性来说不是那么合理(因为结点与结点是平级,添加逻辑理应相同)
如果定义了哨兵结点,以上两个问题都可解决,来看下使用哨兵结点的链表定义
public class LinkedList {
int length = 0; // 链表长度,非必须,可不加
Node head = new Node(0); // 哨兵结点
public void addNode(int val) {
Node tmp = head;
while (tmp.next != null) {
tmp = tmp.next;
}
tmp.next = new Node(val);
}
}
可以看到,定义了哨兵结点的链表逻辑上清楚了很多,不用每次插入元素都对头结点进行判空,也统一了每一个结点的添加逻辑。
所以之后的习题讲解中我们使用的链表都是使用定义了哨兵结点的形式。
做了这么多前期的准备工作,终于要开始我们的正餐了:链表解题常用套路--翻转!
链表常见解题套路
热身赛
既然我们要用链表解题,那我们首先就构造一个链表吧
题目:给定数组 1,2,3,4 构造如下链表 head-->4---->3---->2---->1
看清楚了,是逆序构造链表!顺序构造我们都知道怎么构造,对每个元素持续调用上文代码定义的 addNode 方法即可(即尾插法),与尾插法对应的,是头插法,即把每一个元素插到头节点后面即可,这样就能做到逆序构造链表,如图示(以插入1,2 为例)

头插法比较简单,直接上代码,直接按以上动图的步骤来完成逻辑,如下
public class LinkedList {
int length = 0; // 链表长度,非必须,可不加
Node head = new Node(0); // 哨兵节点
// 头插法
public void headInsert(int val) {
// 1.构造新结点
Node newNode = new Node(val);
// 2.新结点指向头结点之后的结点
newNode.next = head.next;
// 3.头结点指向新结点
head.next = newNode;
}
public static void main(String[] args) {
LinkedList linkedList = new LinkedList();
int[] arr = {1,2,3,4};
// 头插法构造链表
for (int i = 0; i < arr.length; i++) {
linkedList.headInsert(arr[i]);
}
// 打印链表,将打印 4-->3-->2-->1
linkedList.printList();
}
}
小试牛刀
现在我们加大一下难度,来看下曾经的 Google 面试题:给定单向链表的头指针和一个节点指针,定义一个函数在 O(1) 内删除这个节点。
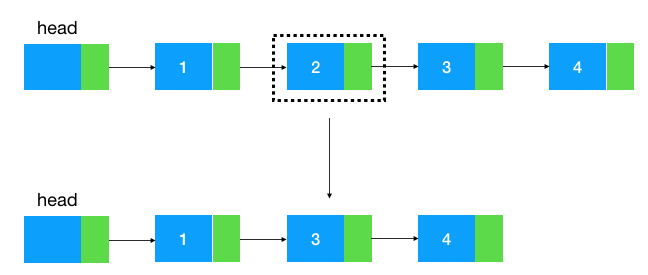 如图示:给定值为 2 的结点,如何把这个结点给删了。
如图示:给定值为 2 的结点,如何把这个结点给删了。
我们知道,如果给定一个结点要删除它的后继结点是很简单的,只要把这个结点的指针指向后继结点的后继结点即可
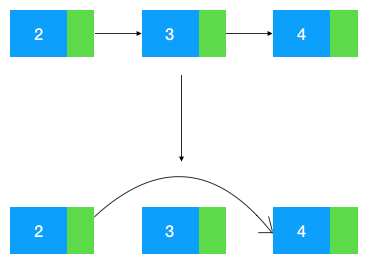
如图示:给定结点 2,删除它的后继结点 3, 把结点 2 的 next 指针指向 3 的后继结点 4 即可。
但给定结点 2,该怎么删除结点 2 本身呢,注意题目没有规定说不能改变结点中的值,所以有一种很巧妙的方法,狸猫换太子!我们先通过结点 2 找到结点 3,再把节点 3 的值赋给结点 2,此时结点 2 的值变成了 3,这时候问题就转化成了上图这种比较简单的需求,即根据结点 2 把结点 3 移除即可,看图
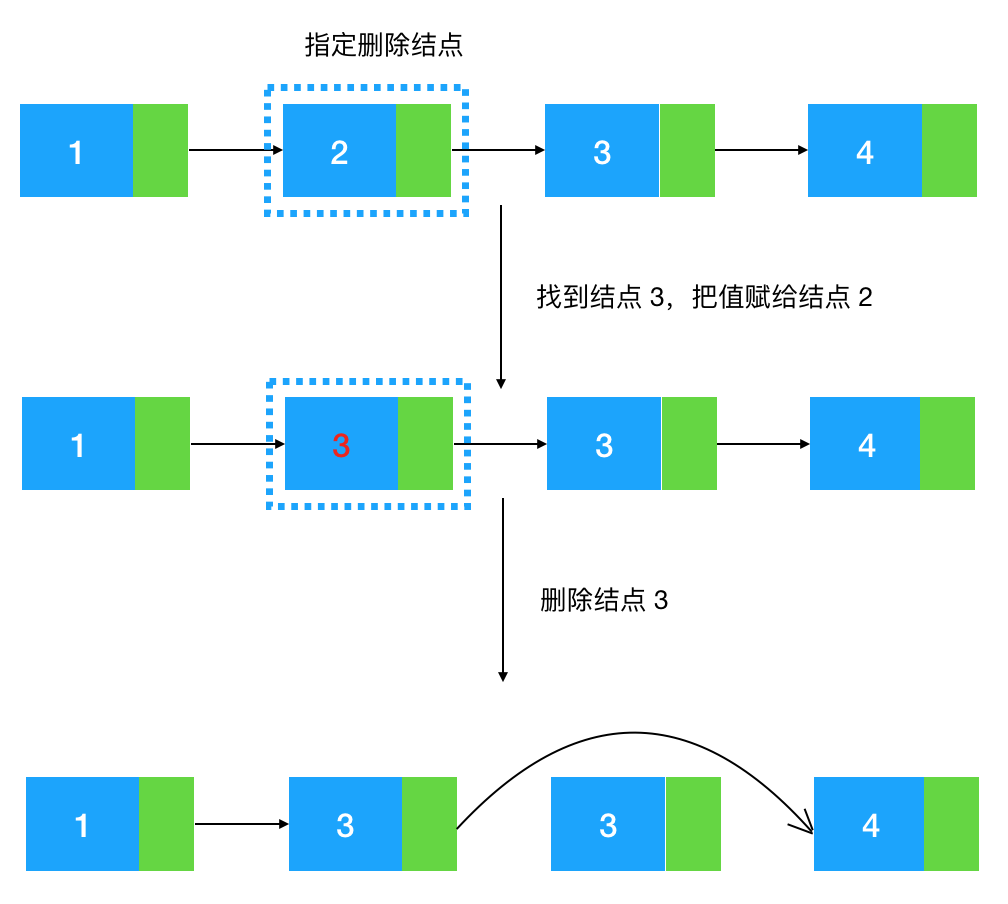
不过需要注意的是这种解题技巧只适用于被删除的指定结点是中间结点的情况,如果指定结点是尾结点,还是要老老实实地找到尾结点的前继结点,再把尾结点删除,代码如下
/**
* 删除指定的结点
* @param deletedNode
*/
public void removeSelectedNode(Node deletedNode) {
// 如果此结点是尾结点我们还是要从头遍历到尾结点的前继结点,再将尾结点删除
if (deletedNode.next == null) {
Node tmp = head;
while (tmp.next != deletedNode) {
tmp = tmp.next;
}
// 找到尾结点的前继结点,把尾结点删除
tmp.next = null;
} else {
Node nextNode = deletedNode.next;
// 将删除结点的后继结点的值赋给被删除结点
deletedNode.data = nextNode.data;
// 将 nextNode 结点删除
deletedNode.next = nextNode.next;
nextNode.next = null;
}
}
入门到进阶:链表翻转
接下来我们会重点看一下链表的翻转,链表的翻转可以衍生出很多的变形,是面试中非常热门的考点,基本上考链表必考翻转!所以掌握链表的翻转是必修课!
什么是链表的翻转:给定链表 head-->4--->3-->2-->1,将其翻转成 head-->1-->2-->3-->4 ,由于翻转链表是如此常见,如此重要,所以我们分别详细讲解下如何用递归和非递归这两种方式来解题
- 递归翻转
关于递归的文章之前写了三篇,如果之前没读过的,强烈建议点击这里查看,总结了递归的常见解题套路,给出了递归解题的常见四步曲,如果看完对以下递归的解题套路会更加深刻,这里不做赘述了,我们直接套递归的解题思路:
首先我们要查看翻转链表是否符合递归规律:问题可以分解成具有相同解决思路的子问题,子子问题...,直到最终的子问题再也无法分解。
要翻转 head--->4--->3-->2-->1 链表,不考虑 head 结点,分析 4--->3-->2-->1,仔细观察我们发现只要先把 3-->2-->1 翻转成 3<----2<----1,之后再把 3 指向 4 即可(如下图示)
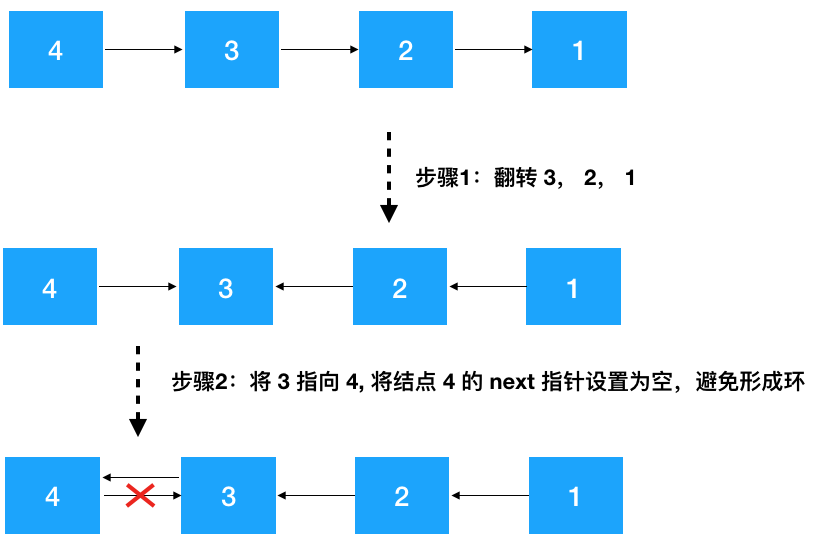
图:翻转链表主要三步骤
只要按以上步骤定义好这个翻转函数的功能即可, 这样由于子问题与最初的问题具有相同的解决思路,拆分后的子问题持续调用这个翻转函数即可达到目的。
注意看上面的步骤1,问题的规模是不是缩小了(如下图),从翻转整个链表变成了只翻转部分链表!问题与子问题都是从某个结点开始翻转,具有相同的解决思路,另外当缩小到只翻转一个结点时,显然是终止条件,符合递归的条件!之后的翻转 3-->2-->1, 2-->1 持续调用这个定义好的递归函数即可!
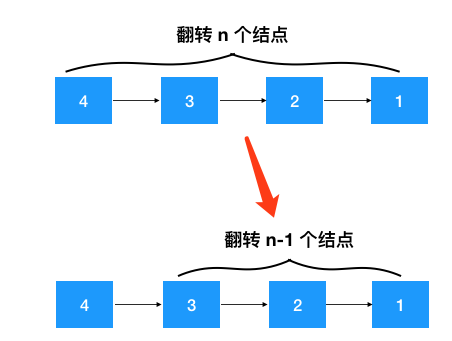
既然符合递归的条件,那我们就可以套用递归四步曲来解题了(注意翻转之后 head 的后继节点变了,需要重新设置!别忘了这一步)
1、定义递归函数,明确函数的功能 根据以上分析,这个递归函数的功能显然是翻转某个节点开始的链表,然后返回新的头结点
/**
* 翻转结点 node 开始的链表
*/
public Node invertLinkedList(Node node) {
}
2、寻找递推公式 上文中已经详细画出了翻转链表的步骤,简单总结一下递推步骤如下
- 针对结点 node (值为 4), 先翻转 node 之后的结点 invert(node->next) ,翻转之后 4--->3--->2--->1 变成了 4--->3<---2<---1
- 再把 node 节点的下个节点(3)指向 node,node 的后继节点设置为空(避免形成环),此时变成了 4<---3<---2<---1
- 返回新的头结点,因为此时新的头节点从原来的 4 变成了 1,需要重新设置一下 head
3、将递推公式代入第一步定义好的函数中,如下 (invertLinkedList)
/**
* 递归翻转结点 node 开始的链表
*/
public Node invertLinkedList(Node node) {
if (node.next == null) {
return node;
}
// 步骤 1: 先翻转 node 之后的链表
Node newHead = invertLinkedList(node.next);
// 步骤 2: 再把原 node 节点后继结点的后继结点指向 node,node 的后继节点设置为空(防止形成环)
node.next.next = node;
node.next = null;
// 步骤 3: 返回翻转后的头结点
return newHead;
}
public static void main(String[] args) {
LinkedList linkedList = new LinkedList();
int[] arr = {4,3,2,1};
for (int i = 0; i < arr.length; i++) {
linkedList.addNode(arr[i]);
}
Node newHead = linkedList.invertLinkedList(linkedList.head.next);
// 翻转后别忘了设置头结点的后继结点!
linkedList.head.next = newHead;
linkedList.printList(); // 打印 1,2,3,4
}
画外音:翻转后由于 head 的后继结点变了,别忘了重新设置哦!
4、计算时间/空间复杂度 由于递归调用了 n 次 invertLinkedList 函数,所以时间复杂度显然是 O(n), 空间复杂度呢,没有用到额外的空间,但是由于递归调用了 n 次 invertLinkedList 函数,压了 n 次栈,所以空间复杂度也是 O(n)。
递归一定要从函数的功能去理解,从函数的功能看,定义的递归函数清晰易懂,定义好了之后,由于问题与被拆分的子问题具有相同的解决思路,所以子问题只要持续调用定义好的功能函数即可,切勿层层展开子问题,此乃递归常见的陷阱!仔细看函数的功能,其实就是按照下图实现的。(对照着代码看,是不是清晰易懂^_^)
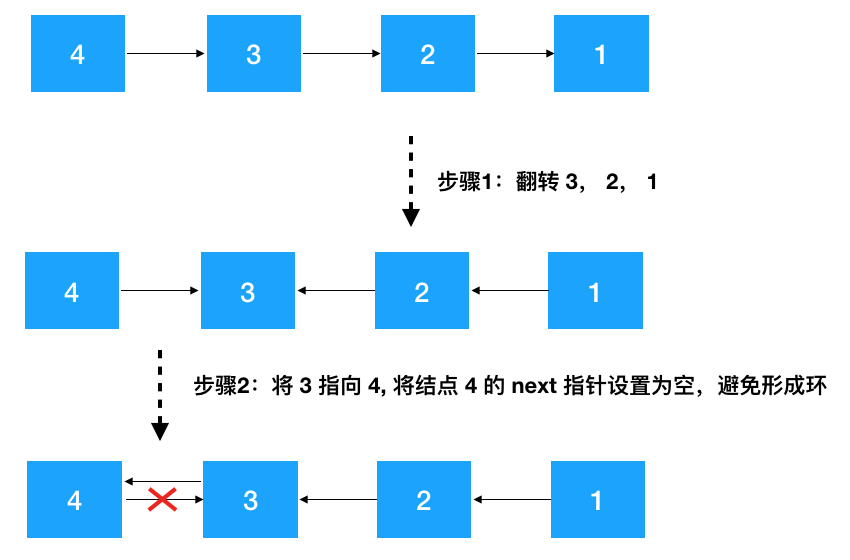
- 非递归翻转链表(迭代解法)
我们知道递归比较容易造成栈溢出,所以如果有其他时间/空间复杂度相近或更好的算法,应该优先选择非递归的解法,那我们看看如何用迭代来翻转链表,主要思路如下
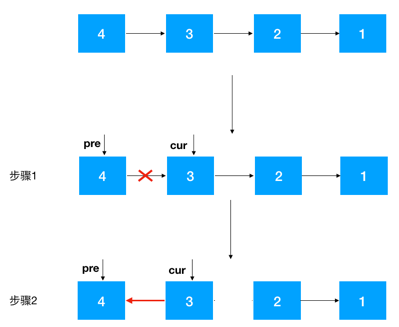
步骤 1:定义两个节点:pre, cur ,其中 cur 是 pre 的后继结点,如果是首次定义, 需要把 pre 指向 cur 的指针去掉,否则由于之后链表翻转,cur 会指向 pre, 就进行了一个环(如下),这一点需要注意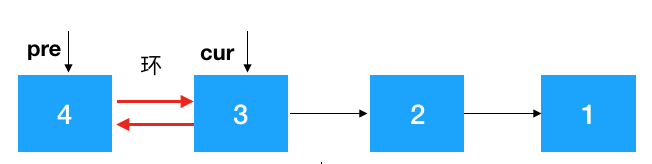
步骤2:知道了 cur 和 pre,翻转就容易了,把 cur 指向 pre 即可,之后把 cur 设置为 pre ,cur 的后继结点设置为 cur 一直往前重复此步骤即可,完整动图如下
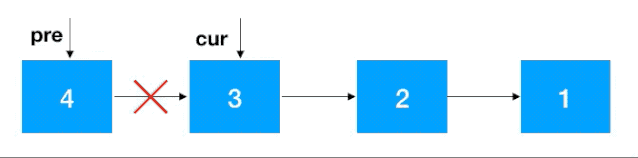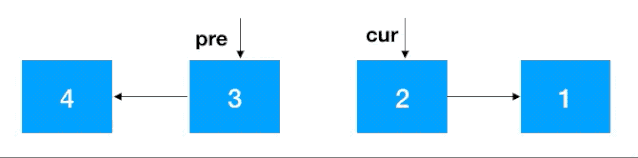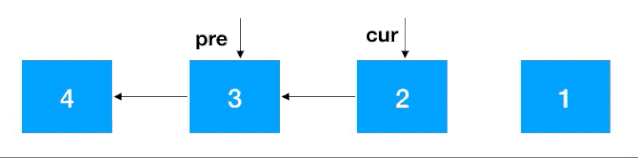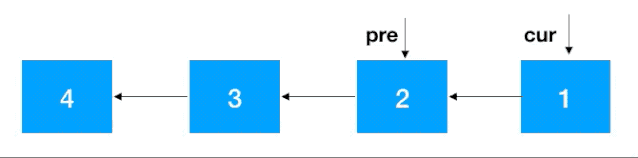
注意:同递归翻转一样,迭代翻转完了之后 head 的后继结点从 4 变成了 1,记得重新设置一下。
知道了解题思路,实现代码就容易多了,直接上代码
/**
* 迭代翻转
*/
public void iterationInvertLinkedList() {
// 步骤 1
Node pre = head;
Node cur = pre.getNext();
pre.setNext(null); // pre 是头结点,避免翻转链表后形成环
// 步骤 2
while (cur != null) {
/**
* 务必注意!!!:在 cur 指向 pre 之前一定要先保留 cur 的后继结点,不然如果 cur 先指向 pre,之后就再也找不到后继结点了
*/
Node next = cur.getNext();
cur.setNext(pre);
pre = cur;
cur = next;
}
// 此时 pre 指向的是原链表的尾结点,翻转后即为链表 head 的后继结点
head.next = pre;
}
用迭代的思路来做由于循环了 n 次,显然时间复杂度为 O(n),另外由于没有额外的空间使用,也未像递归那样调用递归函数不断压栈,所以空间复杂度是 O(1),对比递归,显然应该使用迭代的方式来处理!
花了这么大的精力我们总算把翻转链表给搞懂了,如果大家看了之后几道翻转链表的变形,会发现我们花了这么大篇幅讲解翻转链表是值得的。
接下来我们来看看链表翻转的变形
变形题 1:给定一个链表的头结点 head,以及两个整数 from 和 to ,在链表上把第 from 个节点和第 to 个节点这一部分进行翻转。例如:给定如下链表,from = 2, to = 4 head-->5-->4-->3-->2-->1 将其翻转后,链表变成 head-->5--->2-->3-->4-->1
有了之前翻转整个链表的解题思路,现在要翻转部分链表就相对简单多了,主要步骤如下:
- 根据 from 和 to 找到 from-1, from, to, to+1 四个结点(注意临界条件,如果 from 从头结点开始,则 from-1 结点为空, 翻转后需要把 to 设置为头结点的后继结点, from 和 to 结点也可能超过尾结点,这两种情况不符合条件不翻转)。
- 对 from 到 to 的结点进行翻转
- 将 from-1 节点指向 to 结点,将 from 结点指向 to + 1 结点
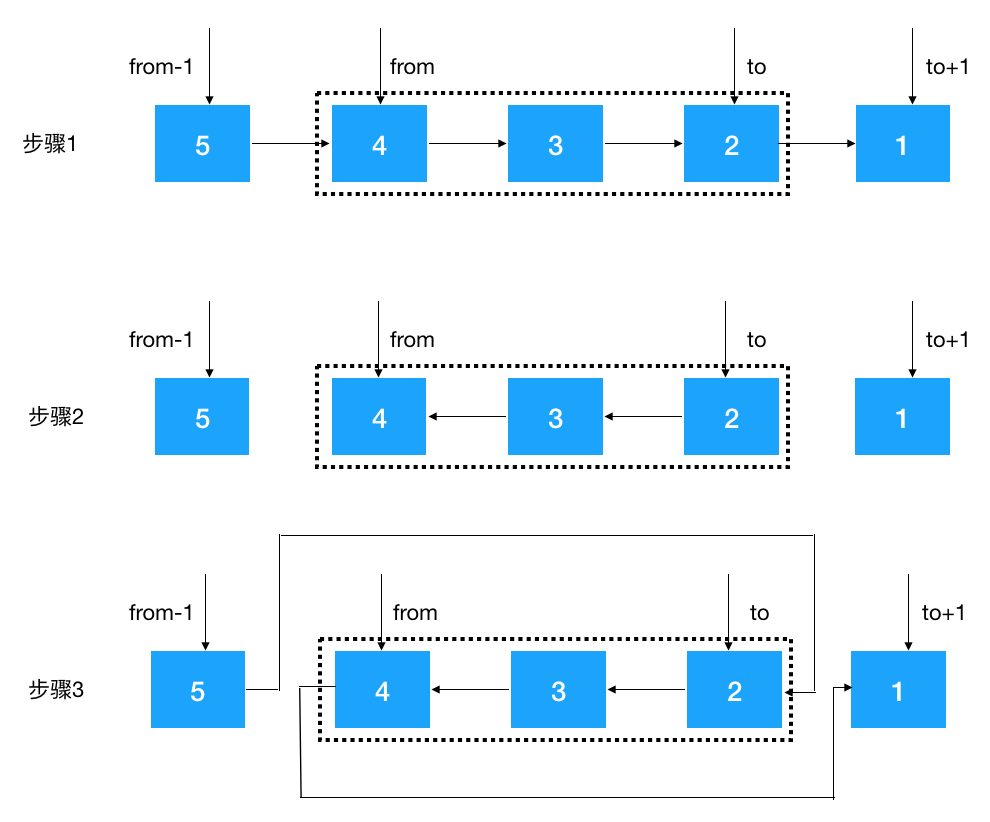
知道了以上的思路,代码就简单了,按上面的步骤1,2,3 实现,注释也写得很详细,看以下代码(对 from 到 to 结点的翻转我们使用迭代翻转,当然使用递归也是可以的,限于篇幅关系不展开,大家可以尝试一下)。
/**
* 迭代翻转 from 到 to 的结点
*/
public void iterationInvertLinkedList(int fromIndex, int toIndex) throws Exception {
Node fromPre = null; // from-1结点
Node from = null; // from 结点
Node to = null; // to 结点
Node toNext = null; // to+1 结点
// 步骤 1:找到 from-1, from, to, to+1 这四个结点
Node tmp = head.next;
int curIndex = 1; // 头结点的index为1
while (tmp != null) {
if (curIndex == fromIndex-1) {
fromPre = tmp;
} else if (curIndex == fromIndex) {
from = tmp;
} else if (curIndex == toIndex) {
to = tmp;
} else if (curIndex == toIndex+1) {
toNext = tmp;
}
tmp = tmp.next;
curIndex++;
}
if (from == null || to == null) {
// from 或 to 都超过尾结点不翻转
throw new Exception("不符合条件");
}
// 步骤2:以下使用循环迭代法翻转从 from 到 to 的结点
Node pre = from;
Node cur = pre.next;
while (cur != toNext) {
Node next = cur.next;
cur.next = pre;
pre = cur;
cur = next;
}
// 步骤3:将 from-1 节点指向 to 结点(如果从 head 的后继结点开始翻转,则需要重新设置 head 的后继结点),将 from 结点指向 to + 1 结点
if (fromPre != null) {
fromPre.next = to;
} else {
head.next = to;
}
from.next = toNext;
}
变形题 2:给出一个链表,每 k 个节点一组进行翻转,并返回翻转后的链表。k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么将最后剩余节点保持原有顺序。
示例 : 给定这个链表:head-->1->2->3->4->5 当 k = 2 时,应当返回: head-->2->1->4->3->5 当 k = 3 时,应当返回: head-->3->2->1->4->5 说明 :
- 你的算法只能使用常数的额外空间。
- 你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。
这道题是 LeetCode 的原题,属于 hard 级别,如果这一题你懂了,那对链表的翻转应该基本没问题了,有了之前的翻转链表基础,相信这题不难。
只要我们能找到翻一组 k 个结点的方法,问题就解决了(之后只要重复对 k 个结点一组的链表进行翻转即可)。
接下来,我们以以下链表为例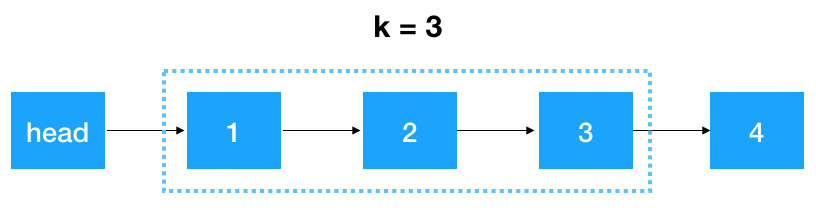 来看看怎么翻转 3 个一组的链表(此例中 k = 3)
来看看怎么翻转 3 个一组的链表(此例中 k = 3)
首先,我们要记录 3 个一组这一段链表的前继结点,定义为 startKPre,然后再定义一个 step, 从这一段的头结点 (1)开始遍历 2 次,找出这段链表的起始和终止结点,如下图示
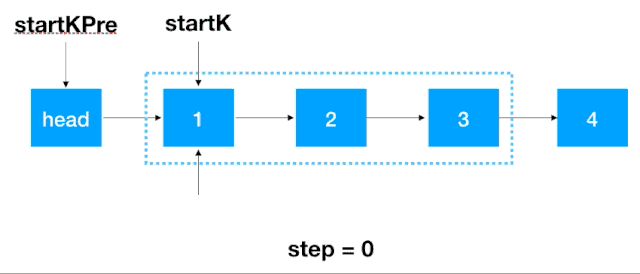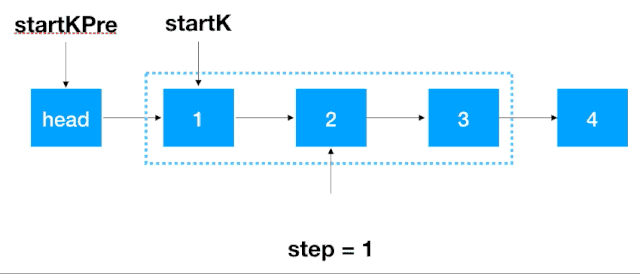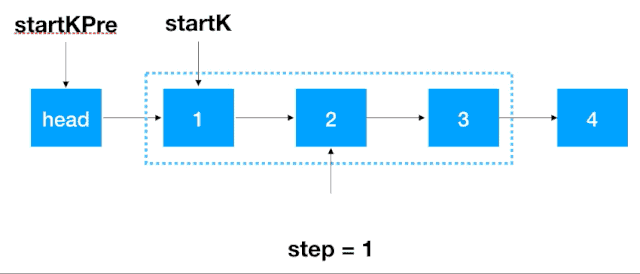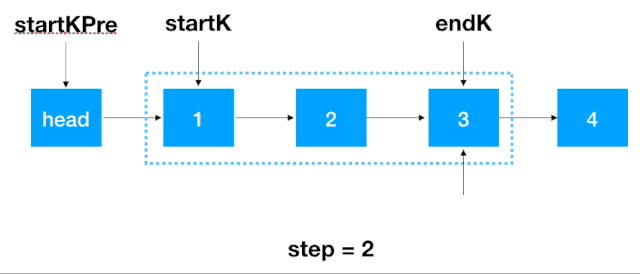
找到 startK 和 endK 之后,根据之前的迭代翻转法对 startK 和 endK 的这段链表进行翻转
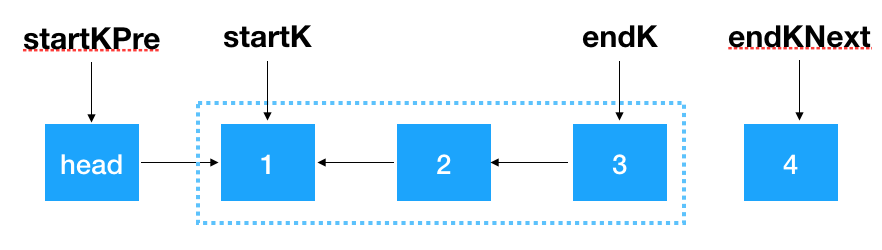
然后将 startKPre 指向 endK,将 startK 指向 endKNext,即完成了对 k 个一组结点的翻转。
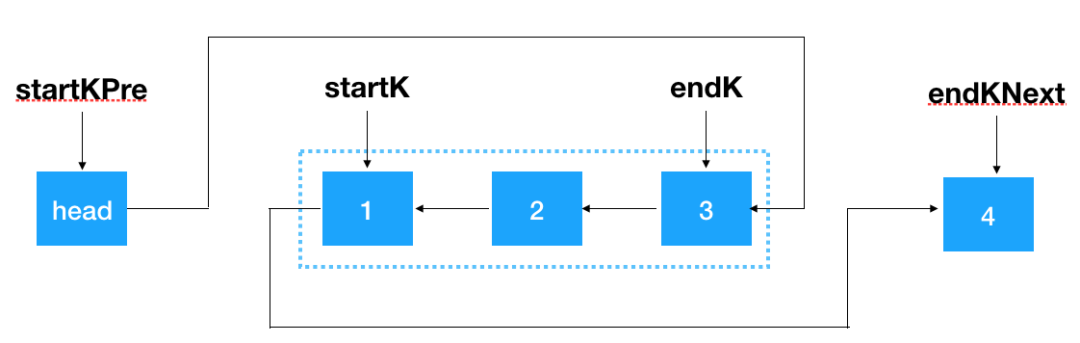
知道了一组 k 个怎么翻转,之后只要重复对 k 个结点一组的链表进行翻转即可,对照图示看如下代码应该还是比较容易理解的
/**
* 每 k 个一组翻转链表
* @param k
*/
public void iterationInvertLinkedListEveryK(int k) {
Node tmp = head.next;
int step = 0; // 计数,用来找出首结点和尾结点
Node startK = null; // k个一组链表中的头结点
Node startKPre = head; // k个一组链表头结点的前置结点
Node endK; // k个一组链表中的尾结点
while (tmp != null) {
// tmp 的下一个节点,因为由于翻转,tmp 的后继结点会变,要提前保存
Node tmpNext = tmp.next;
if (step == 0) {
// k 个一组链表区间的头结点
startK = tmp;
step++;
} else if (step == k-1) {
// 此时找到了 k 个一组链表区间的尾结点(endK),对这段链表用迭代进行翻转
endK = tmp;
Node pre = startK;
Node cur = startK.next;
if (cur == null) {
break;
}
Node endKNext = endK.next;
while (cur != endKNext) {
Node next = cur.next;
cur.next = pre;
pre = cur;
cur = next;
}
// 翻转后此时 endK 和 startK 分别是是 k 个一组链表中的首尾结点
startKPre.next = endK;
startK.next = endKNext;
// 当前的 k 个一组翻转完了,开始下一个 k 个一组的翻转
startKPre = startK;
step = 0;
} else {
step++;
}
tmp = tmpNext;
}
}
时间复杂度是多少呢,对链表从头到尾循环了 n 次,同时每 k 个结点翻转一次,可以认为总共翻转了 n 次,所以时间复杂度是O(2n),去掉常数项,即为 O(n)。注:这题时间复杂度比较误认为是O(k * n),实际上并不是每一次链表的循环都会翻转链表,只是在循环链表元素每 k 个结点的时候才会翻转
变形题 3: 变形 2 针对的是顺序的 k 个一组翻转,那如何逆序 k 个一组进行翻转呢
例如:给定如下链表, head-->1-->2-->3-->4-->5 逆序 k 个一组翻转后,链表变成
head-->1--->3-->2-->5-->4 (k = 2 时)
这道题是字节跳动的面试题,确实够变态的,顺序 k 个一组翻转都已经属于 hard 级别了,逆序 k 个一组翻转更是属于 super hard 级别了,不过其实有了之前知识的铺垫,应该不难,只是稍微变形了一下,只要对链表做如下变形即可
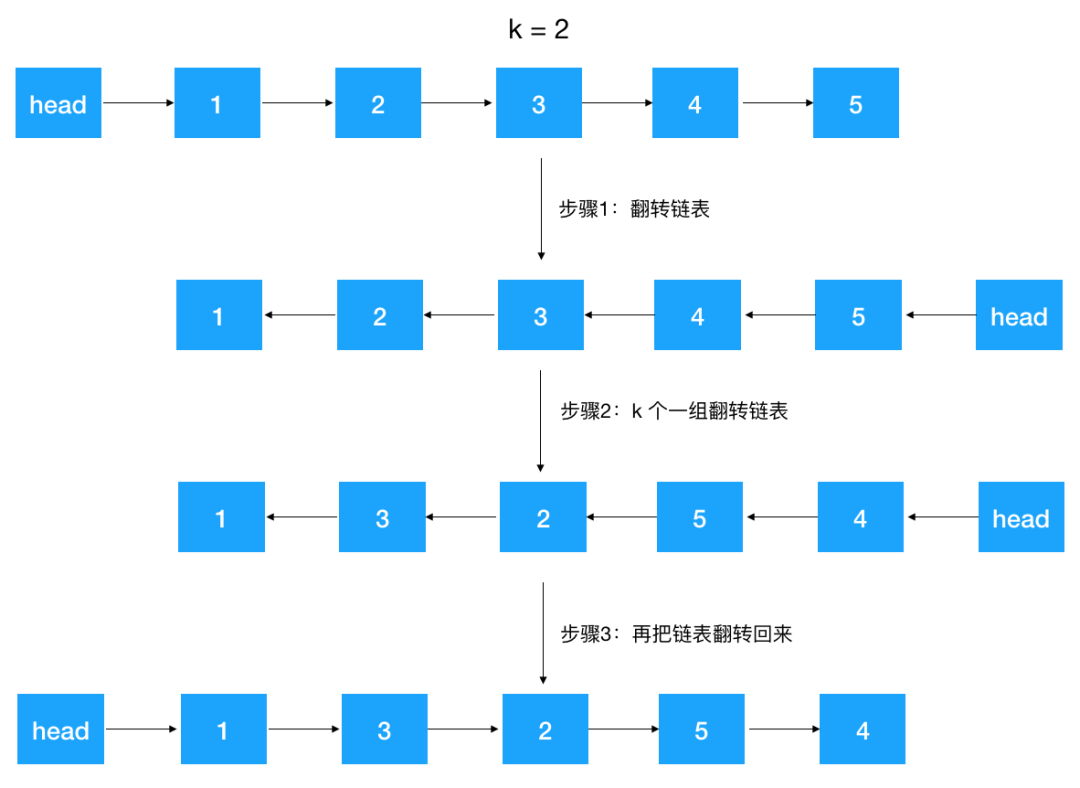
代码的每一步其实都是用了我们之前实现好的函数,所以我们之前做的每一步都是有伏笔的哦!就是为了解决字节跳动这道终极面试题!
/**
* 逆序每 k 个一组翻转链表
* @param k
*/
public void reverseIterationInvertLinkedListEveryK(int k) {
// 先翻转链表
iterationInvertLinkedList();
// k 个一组翻转链表
iterationInvertLinkedListEveryK(k);
// 再次翻转链表
iterationInvertLinkedList();
}
由此可见,掌握基本的链表翻转非常重要!难题多是在此基础了做了相应的变形而已
总结
本文详细讲解了链表与数组的本质区别,相信大家对两者的区别应该有了比较深刻的认识,尤其是程序局部性原理,相信大家看了应该会眼前一亮,之后通过对链表的翻转由浅入深地介绍,相信之后的链表翻转对大家应该不是什么难事了,不过建议大家亲自实现一遍文中的代码哦,这样印象会更深刻一些!有时候看起来思路是这么一回事,但真正操作起来还是会有不少坑,纸上得来终觉浅,绝知此事要躬行!
文中的所有代码均已更新在我的 github 地址上: https://github.com/allentofight/algorithm,大家如果需要,可以下载运行
其他基础数据结构
1、三分钟基础:什么是 2-3-4 树
2、三分钟基础:什么是 2-3 树?
3、三分钟基础:什么是队列?
4、三分钟基础知识:什么是栈?
5、三分钟基础:什么是二叉堆?