
用中国特色社会主义的方式打开 CenterNet
点击上方“Jack Cui”,选择“设为星标”
第一时间关注技术干货!
大家好,我是 Jack 。
CenterNet 想必做过目标检测的都知道,一个近期很流行的 anchor-free 目标检测算法。
最近,我看到了一个非常不错的开源项目,作者重构了 CenterNet,做了一个支持多模型蒸馏、支持多框架转换的目标检测框架 centerX。
同时将后处理也做到了网络前向当中,对落地非常的友好。
放一个 centerX 多模型蒸馏出来的效果图,在蒸馏时没有用到数据集的标签,只用了两个 teacher 的 model 蒸馏同一个 student 网络。

冰冰镇楼
项目地址:
https://github.com/CPFLAME/centerX
直接看这位作者(CPFLAME)充满中国特色社会主义的介绍吧!
1

由于本人不喜欢写纯技术方面的博客,也不想写成一篇纯 PR 稿(从本科开始就深恶痛觉写实验报告),更不想让人觉得读这篇文章是在学习,所以本篇文章不太正经,也没有捧一踩一的操作,跟别人的宣传稿不太一样。
毕竟代码写的不是打打杀杀,而是人情世故,真学东西还得看其他人的文章,看我的也就图一乐。
2

如果你需要用检测算法快速的落地,需要一个速度快并精度尚可的模型,而且可以无坑转 caffe,onnx,tensorRT,同时基本不用写后处理,那 centerX 会很适合你。(原本 centernet 的后处理需要额外的 3X3 pooling和 topK 的操作,被作者用一个极骚操作放到了网络里面)。
如果你想在检测的任务上体会一下模型蒸馏的快感,在 baseline 上无痛涨点,或者找一些 detection 蒸馏的灵感,可以来 centerX 康康。
如果你同时只有两个单类标注的数据集,但是你懒得去补全这两个数据集各自缺失的类别标注,你可以尝试使用 centerX 训练得到一个可以同时预测两类标注的检测器。
如果你想基于 centernet 做一些学术研究,你同样也可以在 centerX 的 projects 里面重构自己的代码,和 centerX 里面 centernet 的 codebase 并不冲突,可以快速定位 bug。
如果你是苦逼的学生或者悲催的工具人,你可以用 centerX 来向上管理你的老师或者领导,因为 centerX 里面的 mAP 点不高,稍微调一下或者加点东西就可以超越本人的 baseline,到时候汇报的时候可以拍着胸脯说你跑出的东西比作者高了好几个点,然后你的 KPI 就可以稍微有点保障了。(文章后面会给几个方向怎么跑的比作者更高)

centerX 的底层框架白嫖自优秀检测框架 detectron2 ,如果之前有跑过 detectron2 的经验,相信可以和马大师的闪电连五鞭一样,无缝衔接的使用。
如果没有 detectron2 的使用经验,那也没有关系,我专门写了懒人傻瓜式 run.sh ,只需要改改 config 和运行指令就可以愉快地跑起来了。
3
代码 cv 大法:拿来主义
模型蒸馏:富带动后富
多模型蒸馏,两个单类检测模型融合成为一个多类检测模型:圣人无常师
共产主义 loss,解决模型对 lr 太过敏感问题:马克思主义
把后处理放到神经网络中:团结我们真正的朋友,以攻击我们的真正的敌人,分清敌我。《毛选》

4
这个方面没有什么好说的,也没有做到和其他框架的差异化,只是在 detectron2 上对基础的 centernet 进行了复现而已,而且大部分代码都是白嫖自 centernet-better 和 centernet-better-plus ,就直接上在 COCO 上的实验结果吧。
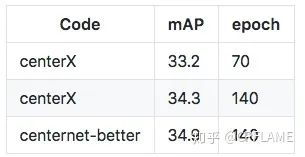
centerX_KD 是用 27.9 的 resnet18 作为学生网络, 33.2 的 resnet50 作为老师网络蒸馏得到的结果,详细过程在在下面的章节会讲。
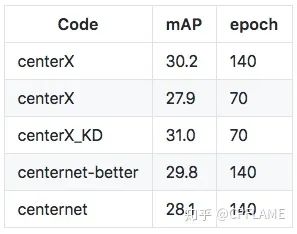
5
大嘎好,我是 detection 。我时常羡慕的看着隔壁村的 classification ,embedding 等玩伴,他们在蒸馏上面都混得风生水起,什么 logits 蒸馏,什么 KL 散度,什么 Overhaul of Feature Distillation 。
每天都有不同的家庭教师来指导他们,凭什么我 detection 的教育资源就很少,我 detection 什么时候才能站起来!

造成上述的原因主要是因为 detection 的范式比较复杂,并不像隔壁村的classification embedding 等任务,开局一张图,输出一个 vector :
two stage的网络本身由于rpn输出的不确定性,导致teacher和student的proposal对齐是个大问题。
笔者尝试过在中间层feature上进行蒸馏,这样就可以偷懒不用写最后的logits蒸馏部分的代码了,结果没有卵用,还是得在logits上蒸馏比较稳。
我编不下去了
我们再来回头看看centernet的范式,哦,我的上帝,多么简单明了的范式:
网络输出三个头,一个预测中心点,一个预测宽高,一个预测中心点的偏移量
没有复杂的正负样本采样,只有物体的中心点是正样本,其他都是负样本
这让笔者看到了在detection上安排家庭教师的希望,于是我们仿照了centernet本来的loss的写法,仿照了一个蒸馏的loss。具体的实现可以去code里面看,这里就说一下简单的思想。
对于输出中心点的head,把teacher和student输出的head feature map过一个relu层,把负数去掉,然后做一个mse的loss,就OK了。
对于输出宽高和中心点的head,按照原centernet的实现是只学习正样本,在这里笔者拍脑袋想了一个实现方式:我们用teacher输出中心点的head过了relu之后的feature作为系数,在宽高和中心点的head上所有像素点都做L1 loss后和前面的系数相乘。
在蒸馏时,三个head的蒸馏loss差异很大,需要手动调一下各自的loss weight,一般在300次迭代后各个蒸馏loss在0~3之间会比较好。
所以在之前我都是300次epoch之后直接停掉,然后根据当前loss 预估一个loss weight重新开始训练。这个愚蠢的操作在我拍了另外一次脑袋想出共产主义loss之后得以丢弃。
在模型蒸馏时我们既可以在有标签的数据上联合label的loss进行训练,也可以直接用老师网络的输出在无标签的数据集上蒸馏训练。基于这个特性我们有很多妙用
当在有标签的数据上联合label的loss进行训练时,老师训N个epoch,学生训N个epoch,然后老师教学生,并保留原本的label loss再训练N个epoch,这样学生的mAP是训出来最高的。
当在无标签的数据集上蒸馏训练时,我们就跳出了数据集的限制,先在有标签的数据集上老师训N个epoch,然后老师在无标签的数据集上蒸馏学生模型训练N个epoch,可以使得学生模型的精度比baseline要高,并且泛化性能更好。
之前在centernet的source code上还跑过一个实验,相同的网络,自己蒸馏自己也是可以涨点的。在centerX上我忘记加进去了。
结构相同的teacher和student可以涨点,不一样结构可能会掉点。
我们拉到实验的部分,上述的瞎比猜想得到验证。

6
看到蒸馏效果还可以,可以在不增加计算量的情况下无痛涨点,笔者高兴了好一阵子,直到笔者在实际项目场景上遇到了一个尴尬地问题:
我有一个数据集A,里面有物体A的标注
我有一个数据集B,里面有物体B的标注
现在由于资源有限,只能跑一个检测网络,我怎么得到可以同时预测物体A和物体B的检测器?
因为数据集A里面可能会有大量的未标注的B,B里面也会有大量的未标注的A,直接放到一起训练肯定不行,网络会学傻。

常规的操作是去数据集A里面标B,然后去数据集B里面标A,这样在加起来的数据集上就可以训练了。但是标注成本又很贵,这让洒家如何是好?
稍微骚一点的操作是在A和B上训练两个网络,然后在缺失的标注数据集上预测伪标签,然后在补全的数据集上训练
novelty更高的操作是在没有标注的数据集上屏蔽网络对应的输出,(该操作仅在C个二分类输出的检测器下可用)
有没有一种方法,也不用标数据,也不用像伪标签那么粗糙,直接躺平,同时novelty也比较高,比较好跟领导说KPI的一个方法?
在笔者再次拍了拍脑袋后,发挥了我最擅长的技能:白嫖。想到了这样一个方案:
我先在数据A上训练个老师模型A,然后在数据B上训练老师模型B,然后我把老师模型A和B的功力全部传给学生模型C,岂不美哉?
我们再来看看centernet的范式,我再次吹爆这个作者的工作,不仅简单易懂的支持了centerPose,centertrack,center3Ddetection,还可以输出可旋转的物体检测。
无独有偶,可能是为了方便复用focal loss,作者在分类时使用了C个二分类的分类器,而不是softmax分类,这给了笔者白嫖的灵感:既然是C个二分类的分类器,那么对于每一个类别,那么我们可以给学生网络分别找一个家庭教师,这样就可以拥有多倍的快乐。
理论上来说可以有很多个老师,并且每个老师教的类别都可以是多个。
那么我们的多模型蒸馏就可以用现有的方案拼凑起来了。这相当于我同时白嫖了自己的代码,以及不完整标注的数据集,白嫖是真的让人快乐啊。和上述提到的操作进行一番比♂较,果然用了的多模型蒸馏的效果要好一些。又一个瞎比猜想被验证了。
笔者分别在人体和车,以及人体和人脸上做了实验。
数据集为coco_car,crowd_human,widerface。
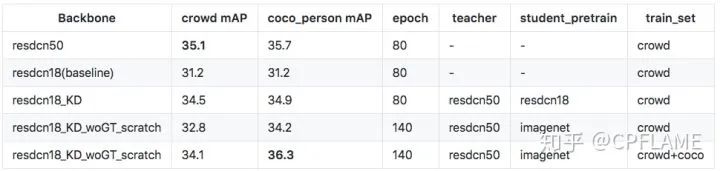

7
笔者在训练centerX时,出现过这样一个问题,设置合适的lr时,训练的一切都那么自然又和谐,而当我lr设置大了以后,有时候会训到一半,网络直接loss飞涨然后mAP归零又重新开始往上爬,导致最后模型的mAP很拉胯。对于这种情况脾气暴躁的我直接爆了句粗口。

骂完了爽归爽,问题还是要解决的,为了解决这个问题,笔者首先想到笔者的代码是不是哪里有bug,但是找了半天都没找到,笔者还尝试了如下的方式:
加入clip gradients,不work
自己加了个skip loss,当本次iter的loss是上次loss的k=1.1倍以上时,这次loss全部置0,不更新网络,不work
换lr_scheduler, 换optimalizer,不work
看来这个bug油盐不进,软硬不吃。训练期间总会出现某个时间段loss突然增大,然后网络全部从头开始训练的情况。
这让我想到了内卷加速,资本主义泡沫破裂,经济大危机后一切推倒重来。这个时候才想起共产主义的好,毛主席真是永远滴神。
既然如此,咱们一不做二不休,直接把蛋糕给loss们分好,让共产主义无产阶级的光照耀到它们身上,笔者一气之下把loss的大小给各个兔崽子head们给规定死,具体操作如下:
给每个loss设置一个可变化的loss weight,让loss一直保持在一个固定的值。
考虑到固定的loss值比较硬核,笔者把lr设置为cosine的lr,让lr比较平滑的下降,来模拟正常情况下网络学习到的梯度分布。
其实本loss可以改名叫adaptive loss,但是为了纪念这次的气急败坏和思维升华,笔者依然任性的把它称之为共产主义loss。
接下来就是实验部分看看管不管用了,于是笔者尝试了一下之前崩溃的lr,得益于共产主义的好处,换了几个数据集跑实验都没有出现mAP拉胯的情况了,期间有几次出现了loss飞涨的情况,但是在共产主义loss强大的调控能力之下迅速恢复到正常状态,看来社会主义确实优越。同时笔者也尝试了用合适的lr,跑baseline和共产主义loss的实验,发现两者在±0.3的mAP左右,影响不大。
笔者又为此高兴了好一段时间,并且发现了共产主义loss可以用在蒸馏当中,并且表现也比较稳定,在±0.2个mAP左右。这下蒸馏可以end2end训练了,再也不用人眼去看loss、算loss weight、停掉从头训了。
8
这个部分的代码都在code的projects/speedup中,注意网络中不能包含DCN,不然转码很难。
centerX中提供了转caffe,转onnx的代码,onnx转tensorRT只要装好环境后一行指令就可以转换了,笔者还提供了转换后不同框架的前向代码。
其中笔者还找到了centernet的tensorRT前向版本(后续笔者把它称为centerRT),在里面用cuda写了centernet的后处理(包括3X3 max pool和topK后处理)。笔者在转完了tensorRT之后想直接把centerRT白嫖过来,结果发现还是有些麻烦,centerRT有点像是为了centernet原始实现定制化去写的。这就有了以下的问题。
不仅是tensorRT版本,所有的框架上我都不想写麻烦的后处理,我想把麻烦的操作都写到网络里面去,这样我就什么都不用干了,直接躺平
在centernet cls head的输出后面再加一层3X3的max pooling,可以减少一部分后处理的代码
有没有办法使得最后中心点head的输出满足以下条件:1.除了中心点之外,其他的像素值全是0,(相当于已经做过了pseudo nms);2.后处理只需要在这个feature上遍历>thresh的像素点位置就可以了。
如果x1表示centernet的中心点输出,x2表示经过了3X3 maxpool之后的输出,那么在python里面其实只需要写上一行代码就得到上述的条件:y = x1[x1==x2]。但是笔者在使用转换时,onnx不支持==的操作。得另谋他路。

这次笔者拍碎了脑袋都没想到怎么白嫖,于是在献祭了几根珍贵的头发之后,强行发动了甩锅技能,把后处理操作都扔给神经网络,具体操作如下:
x2是x1的max pool,我们需要的是x1[x1==x2]的feature map
那么我们只需要得到x1==x2,也就是一张二值化的mask,然后用mask*x1就可以了。
由于x2是x1的max pool,所以x1-x2 <= 0, 我们在x1-x2上加一个很小的数,使得等于0的像素点变成正数,小于0的像素点仍然为负数。然后在加个relu,乘以一个系数使得正数缩放到1,就可以得到我们想要的东西了。
代码如下:
def centerX_forward(self, x):x = self.normalizer(x / 255.)y = self._forward(x)fmap_max = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)(y['cls'])keep = (y['cls'] - fmap_max).float() + 1e-9keep = nn.ReLU()(keep)keep = keep * 1e9result = y['cls'] * keepret = [result,y['reg'],y['wh']] ## change dict to listreturn ret
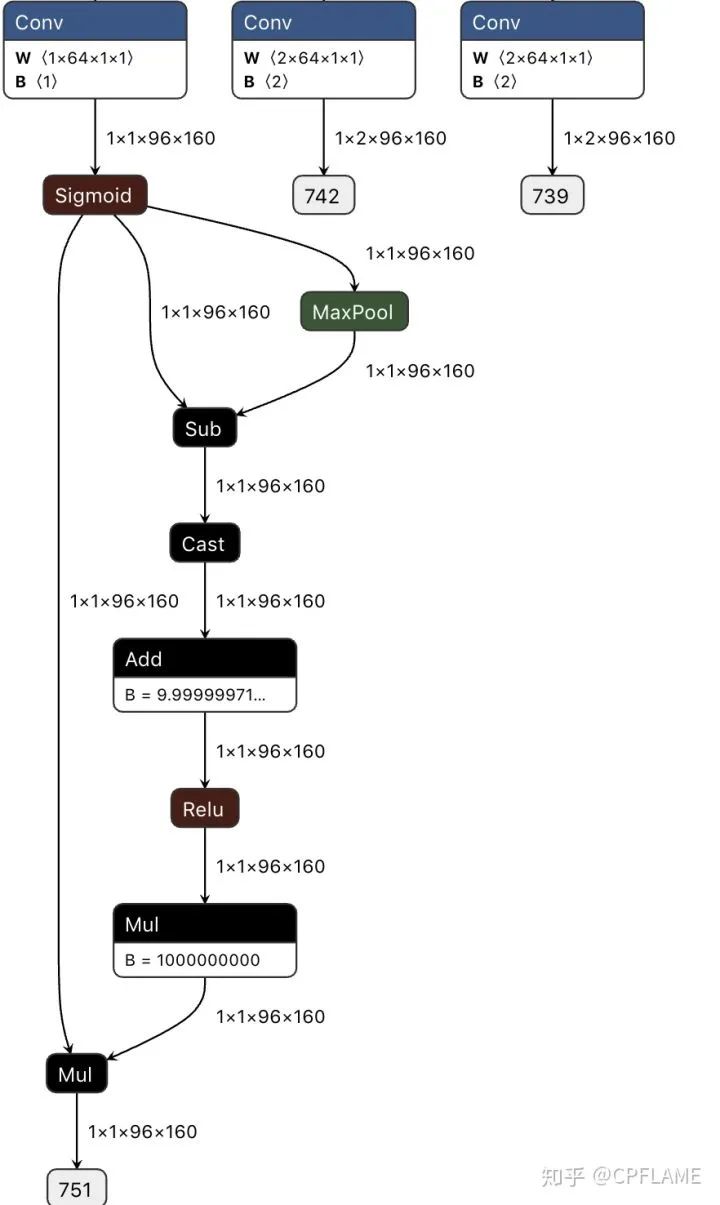
def postprocess(self, result, ratios, thresh=0.3):clses, regs, whs = result# clses: (b,c,h,w)# regs: (b,2,h,w)bboxes = []for cls, reg, wh, ratio in zip(clses, regs, whs, ratios):index = np.where(cls >= thresh)ratio = 4 / ratioscore = np.array(cls[index])cat = np.array(index[0])ctx, cty = index[-1], index[-2]w, h = wh[0, cty, ctx], wh[1, cty, ctx]off_x, off_y = reg[0, cty, ctx], reg[1, cty, ctx]ctx = np.array(ctx) + np.array(off_x)cty = np.array(cty) + np.array(off_y)x1, x2 = ctx - np.array(w) / 2, ctx + np.array(w) / 2y1, y2 = cty - np.array(h) / 2, cty + np.array(h) / 2x1, y1, x2, y2 = x1 * ratio, y1 * ratio, x2 * ratio, y2 * ratiobbox = np.stack((cat, score, x1, y1, x2, y2), axis=1).tolist()bbox = sorted(bbox, key=lambda x: x[1], reverse=True)bboxes.append(bbox)return bboxes
9
考虑到大家需要向上管理,笔者写几个可以涨点的东西。
在centernet作者本来的issue里面提到,centernet很依赖于网络最后一层的特征,所以加上dlaup会涨点特别明显,但是由于feature的channel太多,会有一些时间损耗。笔者实测在某个backbone+deconv上加上dlaup之后,batchsize=8时间由32ms->44ms左右,有一些代价,所以笔者没有加。后续应该可以把dlaup里面的卷积全部改为depthwise的,找到一个速度和精度的平衡
想想办法看看能不能把Generalized Focal Loss,Giou loss等等剽窃过来,稍微改一下加到centernet里面
调参,lr,lossweight,或者共产主义loss里面各个固定loss值,不同数据集上不同backbone的参数都可以优化
用一个牛逼的pretrain model
把隔壁fast reid的自动超参搜索白嫖过来
除了以上的在精度方面的优化之外,其实笔者还想到很多可以做的东西,咱们不在精度这个地方跟别人卷,因为卷不过别人,检测这个领域真是神仙打架,打不过打不过。我们想着把蛋糕做大,大家一起有肉吃。
蒸馏不仅适用于centernet,笔者再提一个瞎比猜想:所有的one-stage detector和anchor-free的检测器都可以蒸馏,而且最后的检测头的cls层全部改为C个2分类以后,应该也可以实现多模型蒸馏
centerPose,其实本来作者的centerpose就已经做到一个网络里面去了,但是笔者觉得可以把白嫖发挥到极致,把只在pose数据集上训过的simplebaseline网络蒸馏到centernet里面去,这样的好处是:1.检测的标注和pose的标注可以分开,作为两个单独的数据集去标注,这样的话可以白嫖的数据集就更多了。2:并且做到一个网络里面速度会更快。
centerPoint,直接输出矩形框四个角点相对于中心点的偏移量,而不是矩形框的宽高,这样的话相当于检测的输出是个任意四边形,好处为:1.我们在训练的时候可以加入任何旋转的数据增强而不用担心gt标注框变大的问题,同时说不定我们用已有的检测数据集+旋转数据增强训练出来的网络就具备了预测旋转物体的能力。2.这个网络在检测车牌,或者身份证以及发票等具有天然的优势,直接预测四个角点,不用做任何的仿射变换,也不用换成笨重的分割网络了。
10

本文已由原作者授权,不得擅自二次转载
https://zhuanlan.zhihu.com/p/323814368

推荐阅读
• 带你「周游世界」的 MODNet 算法• 2020年的最后一个月• 「修炼开始」一文带你入门深度学习• 「完美复刻」的人物肖像画生成• 为艺术而生的惊艳算法