
消费者太多!RocketMQ又炸了!
共 3002字,需浏览 7分钟
·
2024-04-10 14:17

去年写过一篇《Topic数量太多!RocketMQ炸了!》,大家评价还不错。
结果,2024年的开头,我们的RocketMQ又炸了!
1、问题现象
先说明下RocketMQ版本, 4.6.0的老版本了。
线下环境客户端启动会频繁报错响应超时,导致consumer实例化失败,无法启动应用。
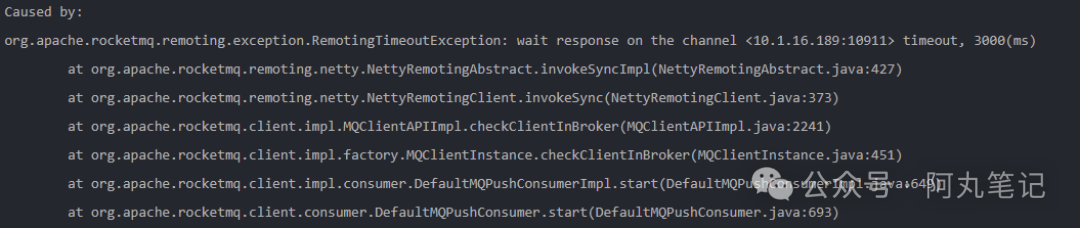
2、排查
确认线下环境RocketMQ集群流量、生产消费数量无异常。
集群gc次数不多,但是耗时高。(原本监控看板异常数据缺失,所以少了前面一段)
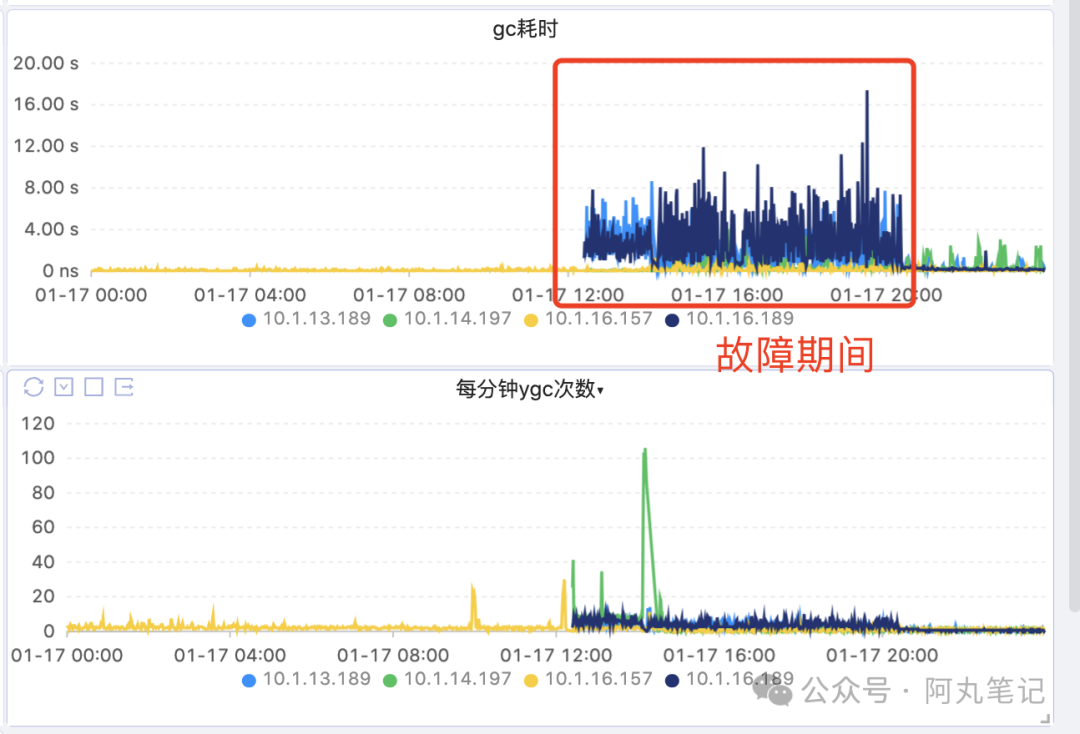
master节点cpu使用率、load极高。
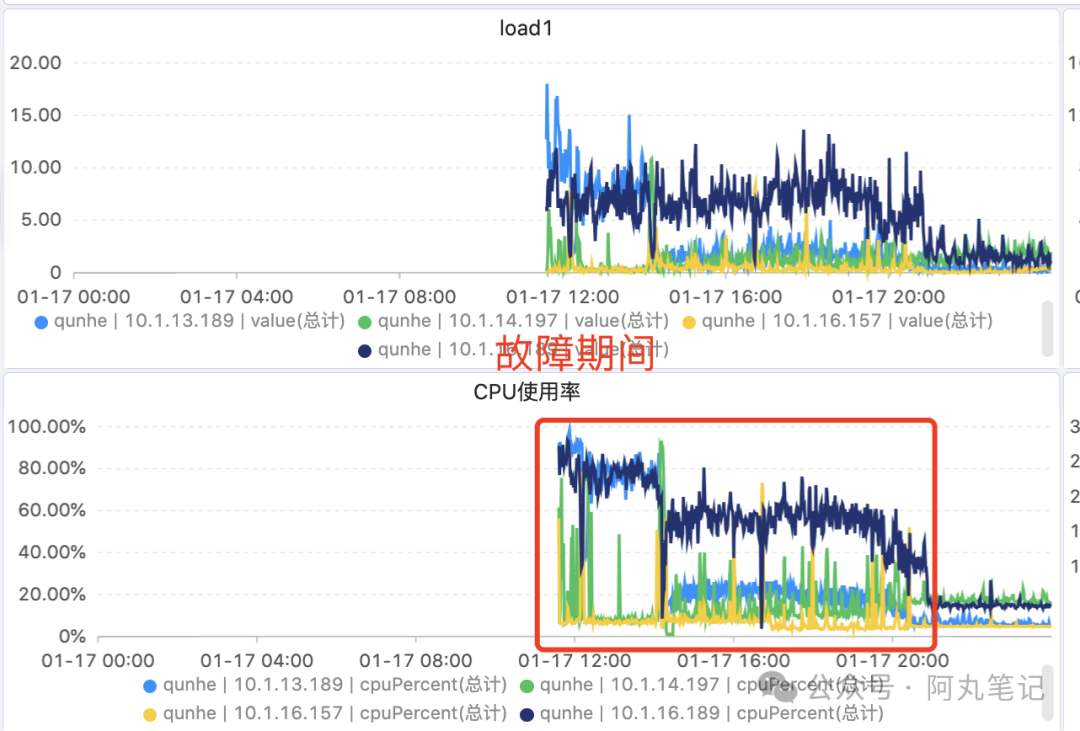
升配,4c8g升级8c32g,扩大jvm内存。
系统指标略有下降,但是客户端异常没有明显改善。
只能进一步排查根因,还得上arthas。
thread -n 3
查看cpu高的线程在做什么。
发现两个异常线程。
1)一个线程 在执行 AdminBrokerProcessor.queryTopicConsumerByWho() 。
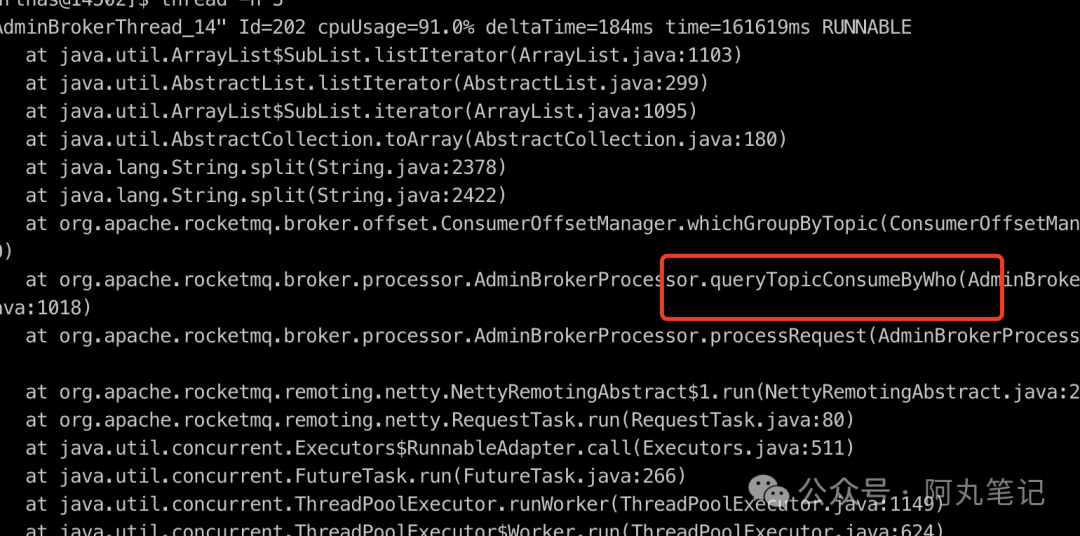
这个是查询Topic的conusmerGroup信息。
比较奇怪的是,这个请求很频繁,后来发现是控制台应用dashboard有个定时任务,30s查询一次。
这个请求的耗时主要是在数组的遍历处理上,说明内存中的数据非常大。
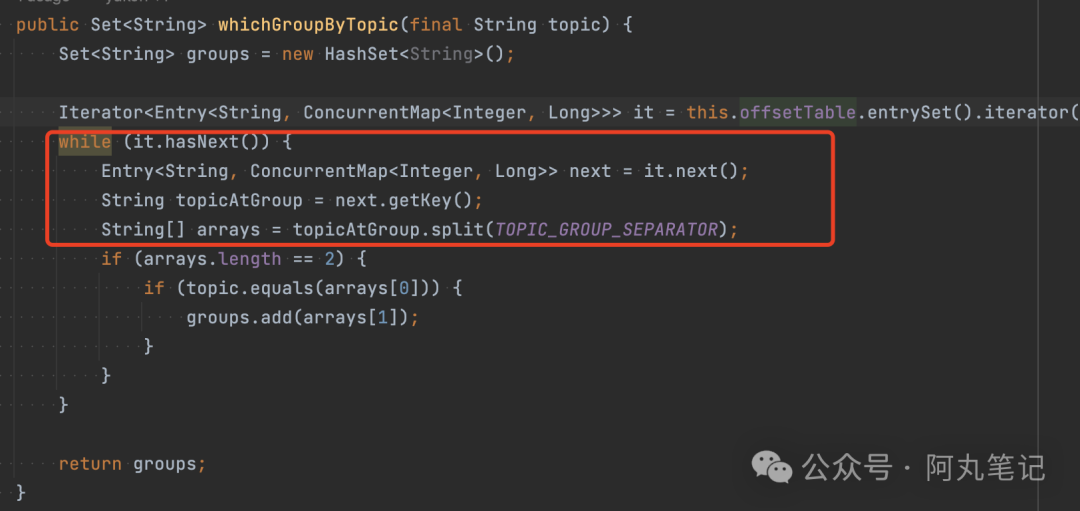
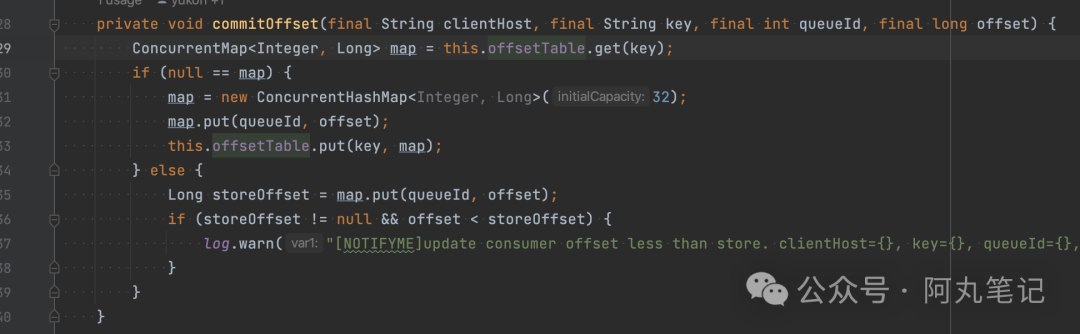
而这个源码中的offsetTable,就是RocketMQ中保存consumerGroup位点信息的对象。它的key是topic@group拼接的。
先临时处理,把dashboard应用关闭了,减少请求。但是效果并不明显。
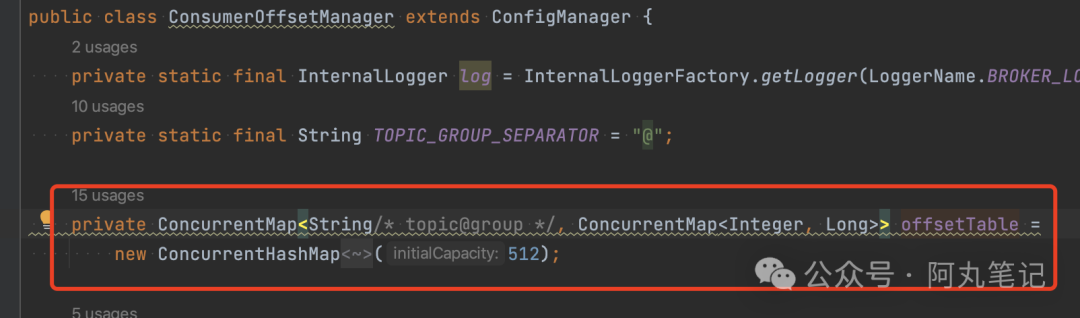
2)另一个线程在执行定时任务 ConsumerOffsetManager.persist() 。
(线程调用信息忘记截图了)
这个是RocketMQ集群持久化consumerGroup的offset信息的定时任务。
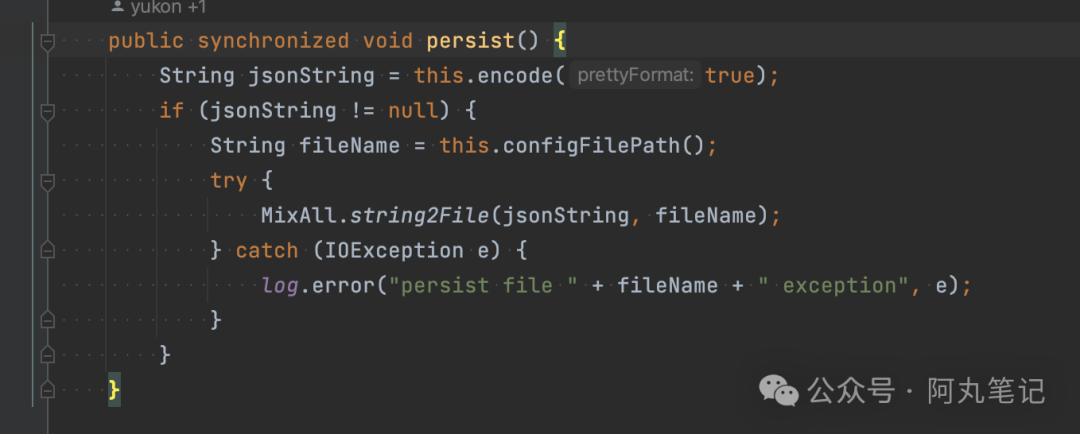
会将整个内存对象转化为jsonString写入磁盘文件中。
这个内存对象就是前面提到的offsetTable,就是RocketMQ中保存consumerGroup位点信息的对象。
这里消耗资源多,还是说明我们的内存对象非常大。
因为是线下环境,可靠性要求不高。所以先临时处理,把定时任务默认配置5s改成50s,减少持久化次数。
效果显著,机器cpu、负载都明显改善。
好了,现在问题的矛头都指向了这个offsetTable,那它到底有多大,为什么这么大?
3、定位根因
3.1 直接原因
大对象的定位,一般来说需要dump看看,不过这个对象有点特殊,刚刚也提到了它会被持久化到文件中,所以直接看文件大小和内容就行了。
持久化文件的配置路径,可以看下启动的conf.properties
storePathRootDir=/usr/local/rocketmq/store1
storePathCommitLog=/usr/local/rocketmq/store1/commitlog
storePathConsumerQueue=/usr/local/rocketmq/store1/consumequeue
storePathIndex=/usr/local/rocketmq/store1/index
在/usr/local/rocketmq/store1目录下找到config文件夹的consummerOffset.json文件,44M,amazing~
对一个几十M的对象频繁序列化和持久化,加上内网磁盘比较差,难怪负载如此高。
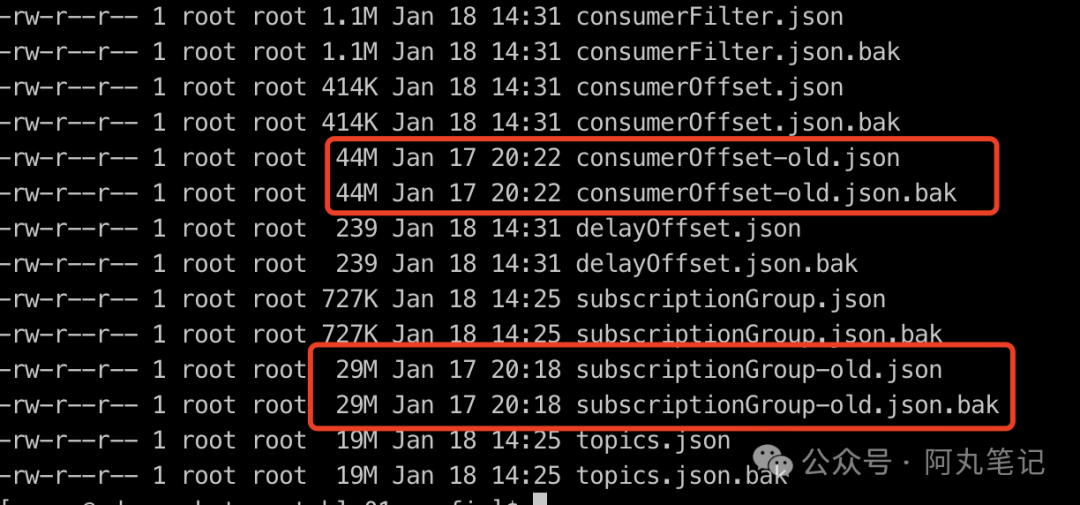
(这里截图是当时应急时备份的文件,新的文件目前是414K)
3.2 根本原因
为什么这个内存对象这么大呢?
查看了下文件内容,是RocketMQ中保存consumerGroup位点信息的对象,它的key是topic@group拼接的。
我们发现大量奇怪的consumerGroup name,跟一个topic联合产生了几千个key。
查看了下内部封装的客户端代码,找到了罪魁祸首。
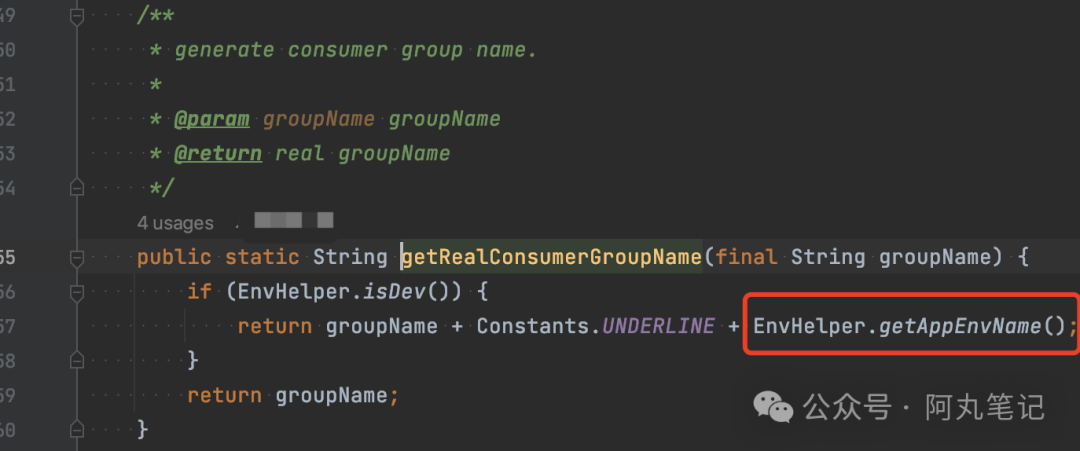
线下环境会根据小环境(比如自己起的测试、单测环境、CI测试环境等)拼接一个独立的consumerGroup name。
在线下,每次CI的测试环境名字会变化,所以导致consumerGroup name数量急剧膨胀。
4、优化
问题找到了,直接的解决方式是删除文件中无用的consumerGroup name,重启broker进行加载。
由于是线下环境,不需要担心位点丢失的问题,同时当客户端请求时会自动创建新的位点信息,所以可以考虑直接删除。
先停止broker进程(否则会自动落盘内存数据,创建新的文件),然后重命名相关文件(用于备份回滚),重新启动broker进程,读取空文件加载空对象。
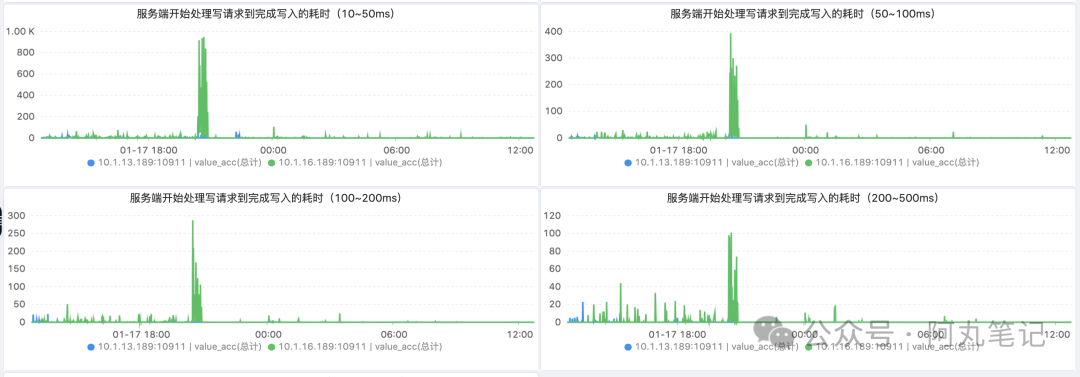
重启后,各个客户端在请求集群时,会自动创建订阅关系和消费位点记录,负载略有升高,然后就恢复到较低的负载水位了。
24h的监控显示,优化效果显著,整个机器负载降低,请求读写耗时也显著降低。
注意:
保存订阅关系的subscriptionGroup.json也存在同样consumerGroup过多导致膨胀的问题,同样的原因和优化方式。默认订阅关系也是会自动创建的。
这里就不展开赘述了。
5、扩展一下
如果类似的问题出在线上怎么办?
事后来看,类似问题是能够提前避免的,主要考虑两个措施:
-
要做好持久化文件(对应内存对象)大小监控,避免出现内存大对象。如果发现异常增长,必须提前排查处理。
-
磁盘要足够好,使用SSD是基本要求,避免频繁刷盘导致负载升高。
往期热门笔记合集推荐:
原创:阿丸笔记(微信公众号:aone_note),欢迎 分享 ,转载请保留出处。
没有留言功能的悲伤,扫描下方二维码「加我」聊些有的没的吧~
觉得不错,就点个 再看 吧👇