
JVM:我就想知道我是怎么没的
这可不是什么好事,与 JVM 一起崩溃的,除了服务,还有我们的心态。
所谓的 JVM 崩溃,一般情况下就是指内存溢出,也就是 OutOfMemoryError 和 StackOverflowError。另外还有一种情况就是堆外内存占用过大,这种情况会导致 JVM 所在机器的内存被撑爆,从而导致机器重启等异常情况发生,我们把这种情况叫做内存泄漏。
那什么情况下会造成 JVM 崩溃呢,有哪几种类型的崩溃呢?俗话说,知己知彼,方能百战不殆。了解了发生崩溃的原因,才能更好的解决 JVM 崩溃问题。

首先还是放出 JVM 内存模型图,JVM 要理解起来是很抽象的,借助下面这张图可以具象化的了解 JVM 内存模型,而发生溢出的几个部分都可以在图中找到。在 JDK 8 中,永久代已经不存在了,取而代之的是元空间(metaspace)。
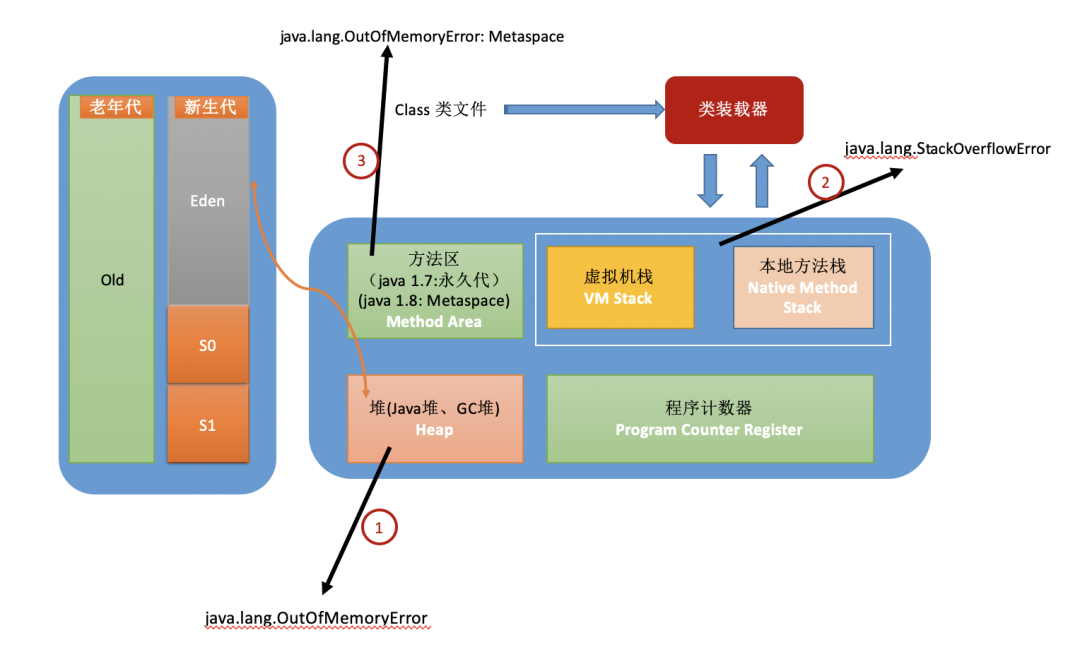
下面就以 Hotspot JDK 8 为背景,看一下 JVM 内存溢出和内存泄漏的几种情况。
首先设置 JVM 启动参数,限制堆空间大小,堆空间设置为 20M,其中新生代10M,元空间10M,并指定垃圾收集算法采用 CMS 算法。之后的例子都会使用这套参数。
-XX:+UseConcMarkSweepGC
-XX:+UseCMSInitiatingOccupancyOnly
-XX:CMSInitiatingOccupancyFraction=70
-XX:+ExplicitGCInvokesConcurrentAndUnloadsClasses
-XX:+CMSClassUnloadingEnabled
-XX:+ParallelRefProcEnabled
-XX:+CMSScavengeBeforeRemark
-verbose:gc
-Xms20M
-Xmx20M
-Xmn10M
-XX:+PrintGCDetails
-XX:SurvivorRatio=8
-XX:+HeapDumpOnOutOfMemoryError
-XX:MetaspaceSize=10M
-XX:MaxMetaspaceSize=10M
-XX:HeapDumpPath=/Users/fengzheng/jvmlog
堆溢出
堆溢出,应该是最常见的一种内存溢出的场景了。JVM 中分配绝大多数对象实例和数组都存在堆上,另外堆内存也是垃圾收集器工作的主要战场。
当我们的 Java 程序启动的时候,会指定堆空间的大小,新建对象和数组的时候会分配到堆上面,当新对象申请空间的时候,如果堆内存不够了,就会发生垃圾收集动作,大多数时候会发生在新生代,叫做 Minor GC。当新生代回收完成,空间仍然不够的话,会发生一次 FullGC。FullGC 后,空间仍然不够,此时就会发生 OOM 错误,也就是堆溢出。
模拟一下这个场景
private final static int _1K = 1024;
public static void main(String[] args){
List<byte[]> byteList = new ArrayList<>();
quietlyWaitingForCrashHeap(byteList);
}
public static void quietlyWaitingForCrashHeap(List<byte[]> byteList) {
try {
while (true) {
byteList.add(new byte[500 * _1K]);
//Thread.sleep(1000);
Thread.sleep(100);
}
} catch (InterruptedException e) {
}
}
上面的方法会持续的向List数组中每次添加500k的元素,整个堆只有20M,可想而知,程序一运行起来,马上就会将对空间填满,导致后面的元素加不进去,而又回收不掉,从而导致堆内存溢出。
下面是程序运行之后的结果,经过垃圾回收最终还是没有多余的空间,从而发生 java.lang.OutOfMemoryError: Java heap space异常。
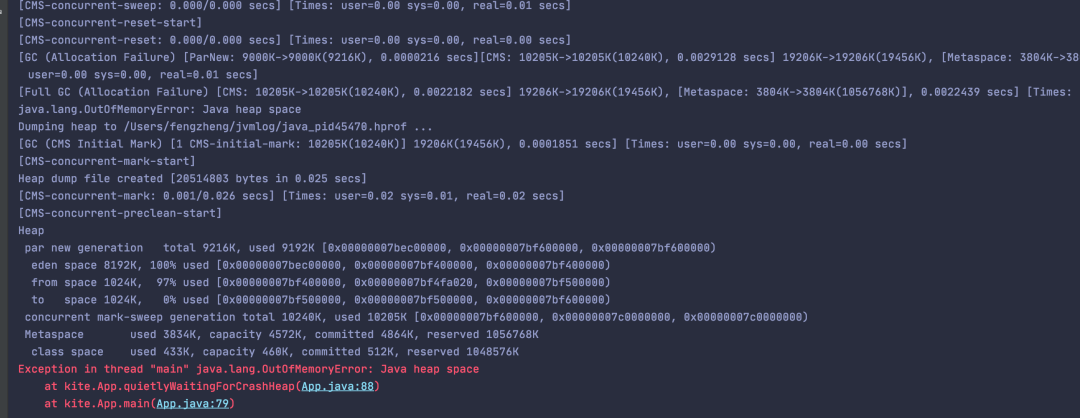
发生堆内存溢出的根本原因就是使用中的对象大小超过了堆内存大小。
堆内存空间设置的太小,要根据预估的实际使用堆大小合理的设置堆空间设置。
程序有漏洞导致,某些静态变量持续的增大,例如缓存数据错误的初始化,导致缓存无止境的增加,最终导致堆内存溢出。针对这种情况,恐怕没什么好方法,除了做好测试之外,就是在问题发生后做好日志分析。
栈溢出
虚拟机栈是用来存储局部变量表、操作数栈、动态链接、方法出口等信息的,每调用一个 Java 方法就会为此方法在虚拟机栈中生成栈帧。
栈除了包括虚拟机栈之外,还包括本地方法栈,当调用的方法是本地方法(例如 C 语言实现的方法)时,会用到本地方法栈。不过,在 HotSpot 虚拟机中,虚拟机栈和本地方法栈被合二为一了。
模拟栈溢出场景
public static void main(String[] args){
stackOverflow();
}
/**
* stackoverflow
*/
public static void stackOverflow() {
stackOverflow();
}
在上面的代码中,stackOverflow() 方法的调用是一个无限递归的过程,没有递归出口。前面说了,每调用一个方法就会在虚拟机栈中生成栈帧,无限的递归,必定造成无限的生成栈帧,最后导致栈空间被填满,从而发生溢出。
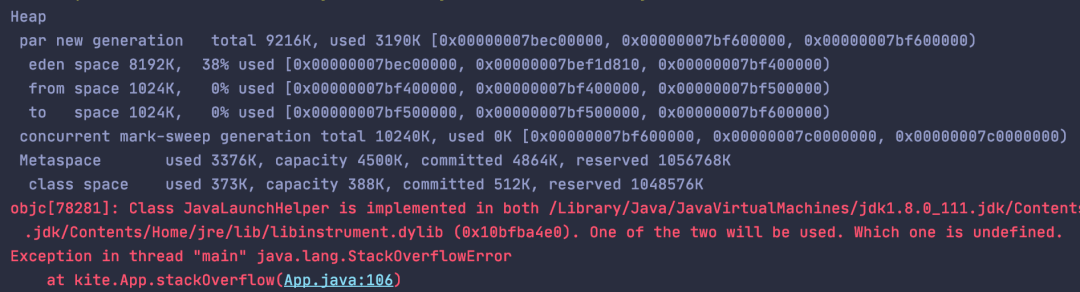
上面模拟了最常见的一种状况,产生这种状况的原因很可能是由于程序 bug 导致的,一般来说,递归必定会有递归出口,如果由于某些原因导致了程序在执行的过程中无法达到出口条件,那就会造成这种异常。还有就是循环体,循环体的循环次数如果过大,也有可能出现栈溢出。
另外还可能是其他比较不容易出现的原因,比如创建的线程数过多,线程创建要在虚拟机栈中分配空间,如果创建线程过多,可能会出现 OutOfMemoryError异常,但是一般来说,都会用线程池的方法代替手动创建线程的方式,所以,这种情况不容易出现。
元空间溢出
用于存储已被虚拟机加载的类信息,常量,静态变量,即时编译(JIT)后的代码等数据,在 JDK 8 中,已经用 metaSpace 代替了永久代的。默认情况下 metaSpace 的大小是没有限制的,也就是所在服务器的实际内存大小,但是,一般情况下,最好还是设置元空间的大小。
一般在产生大量动态生成类的情景中,可能会出现元空间的内存溢出。
模拟元空间溢出
public static void main(String[] args){
List<byte[]> byteList = new ArrayList<>();
//quietlyWaitingForCrashHeap(byteList);
// stackOverflow();
methodAreaOverflow();
}
public static void methodAreaOverflow() {
int i = 0;
while (true) {
Enhancer enhancer = new Enhancer();
enhancer.setUseCache(false);
enhancer.setSuperclass(MethodOverflow.class);
enhancer.setCallback(new MethodInterceptor() {
@Override
public Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {
return methodProxy.invokeSuper(o, objects);
}
});
enhancer.create();
System.out.println(++i);
}
}
通过 CGLIB 的方式动态的创建很多个动态类,这样一来,类信息就会越来越多的存到元空间,从而导致元空间溢出。
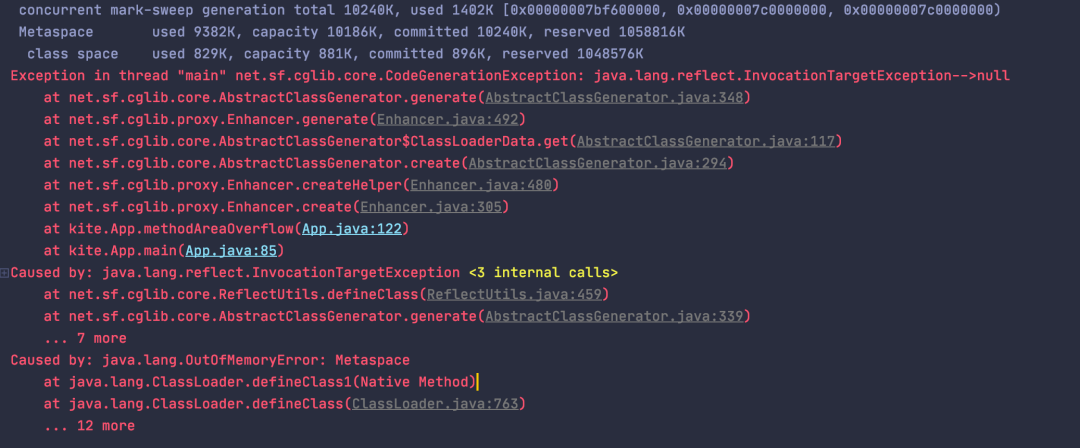
例如在使用 Spring、 MyBatis 等技术框架的时候会动态创建 Bean 实例类,另外,Spring AOP 也会产生动态代理类。
堆外内存溢出
大多数情况下,内存都会在 JVM 堆内存中分配,很少情况下需要直接在堆外分配内存空间。使用堆外内存的几个好处是:
在进程间可以共享,减少虚拟机间的复制
对垃圾回收停顿的改善:如果应用某些长期存活并大量存在的对象,经常会触发YGC或者FullGC,可以考虑把这些对象放到堆外。过大的堆会影响Java应用的性能。如果使用堆外内存的话,堆外内存是直接受操作系统管理( 而不是虚拟机 )。这样做的结果就是能保持一个较小的堆内内存,以减少垃圾收集对应用的影响。
在某些场景下可以提升程序I/O操纵的性能。少去了将数据从堆内内存拷贝到堆外内存的步骤。
通常在需要大量频繁的进行 IO 操作的时候会用到堆外内存,例如 Netty、RocketMQ 等使用到了堆外内存,目的就是为了加快速度。
所以,在出现系统内存占用过大的情况时,排查堆栈无果后,可以看一下堆外内存的使用情况,看看是不是堆外内存溢出了。
总结
事前做好配置
JVM 问题本身就是比较抽象和难以直观发现的,所以在项目上线前除了做好代码逻辑的测试外,还要对 JVM 参数进行合理配置,根据应用程序的体量和特点选择好合适的参数,比如堆栈大小、垃圾收集器种类等等。
另外,垃圾收集日志一定要有保留,还有就是发生内存溢出时要保存 dump 文件。
事中做好监控
在程序上线运行的过程中,做好 JVM 的监控工作,比如用 Spring Admin 这种比较轻量的监控工具,或者大型项目用 Cat、SkyWallking 等这些分布式链路监控系统。
事后做好现场保护和分析
再合理的参数配置和监控平台,也难免不发生异常,这也是很正常的,不出现异常才有问题好吧。在发生异常之后,要及时的保留现场,如果是多实例应用,可以暂时将发生异常的实例做下线处理,然后再进行问题的排查。如果是单实例的服务,那要及时的确认最新的日志和dump已经留存好,确认完成后,再采取错误让服务重启。
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️