
.Net/C#分库分表高性能O(1)瀑布流分页

框架介绍
依照惯例首先介绍本期主角:ShardingCore 一款ef-core下高性能、轻量级针对分表分库读写分离的解决方案,具有零依赖、零学习成本、零业务代码入侵
dotnet下唯一一款全自动分表,多字段分表框架,拥有高性能,零依赖、零学习成本、零业务代码入侵,并且支持读写分离动态分表分库,同一种路由可以完全自定义的新星组件框架
你的star和点赞是我坚持下去的最大动力,一起为.net生态提供更好的解决方案
项目地址
github地址 https://github.com/dotnetcore/sharding-core
gitee地址 https://gitee.com/dotnetchina/sharding-core
背景
在大数据量下针对app端的瀑布流页面分页的优化实战,有大量的数据,前端需要以瀑布流的形式展示出来,我们最简单的就是以用户发布的文章为例,假设我们有大量的文章帖子被,需求需要按帖子的发布时间倒序展示给用户看,那么在手机端我们一般都是以下拉刷新,上拉加载的形式去展示,那么我们一般会有以下集中写法。
常规分页操作
select count(*) from article
select * from article order by publish_time desc limit 0,20
这个操作是一般我们的常规分页操作,先进行total然后进行分页获取,这种做法的好处是支持任意规则的分页,缺点就是需要查询两次,一次count一次limit当然后期数据量实在太大可以只需要第一次count,但是也有一个问题就是如果数据量一直在变化会出现下一次分页中还会有上一次的部分数据,因为数据在不断地新增,你的分页没跟上发布的速度那么就会有这个情况发送.
瀑布流分页
除了上述常规分页操作外,我们针对特定顺序的分页也可以进行特定的分页方式来实现高性能,因为基于大前提我们是大数量下的瀑布流,我们的文章假设是以雪花id作为主键,那么我们的分页可以这么写
select * from article where id<last_id order by publish_time desc limit 0,20
首先我们来分析一下,这个语句是利用了插入的数据分布是顺序和你需要查询的排序一直来实现的,又因为id不会重复并且雪花id的顺序和时间是一致的都是同向的所以可以利用这种方式来进行排序,limit每次不需要跳过任何数目,直接获取需要的数目即可,只需要传递上一次的查询结果的id即可,这个方式弥补了上述常规分页带来的问题,并且拥有非常高的性能,但是缺点也显而易见,不支持跳页,不支持任意排序,所以这个方式目前来说非常适合前端app的瀑布流排序。
分片下的实现
首先分片下需要实现这个功能我们需要有id支持分片,并且publish_time按时间分表,两者缺一不可。
原理
假设文章表article我们是以publish_time作为分片字段,假设按天分表,那么我们会拥有如下的表
article_20220101、article_20220102、article_20220103、article_20220104、article_20220105、article_20220106......
雪花id辅助分片
因为雪花id可以反解析出时间,所以我们对雪花id的=,>=,>,<=,<,contains的操作都是可以进行辅助分片进行缩小分片范围
假设我们的雪花id解析出来是2021-01-05 11:11:11,那么针对这个雪花id的<小于操作我们可以等价于x < 2021-01-05 11:11:11,那么如果我问你这下我们需要查询的表有哪些,很明显 [article_20220101、article_20220102、article_20220103、article_20220104、article_20220105],除了20220106外我们都需要查询。
union all分片模式
如果你使用union all的分片模式那么通常会将20220101-20220105的所有的表进行union all然后机械能过滤,那么优点可想而知:简单,连接数消耗仅1个,sql语句支持的多,缺点也显而易见,优化起来后期是个很大的问题,并且跨库下的使用有问题
select * from
(select * from article_20220101 union all select * from article_20220102 union all select * from article_20220103....) t
where id<last_id order by publish_time desc limit 0,20
流式分片,顺序查询
如果你是流式分片模式进行聚合通常我们会将20220101-20220105的所有的表进行并行的分别查询,然后针对每个查询的结果集进行优先级队列的排序后获取,优点:语句简单便于优化,性能可控,支持分库,缺点:实现复杂,连接数消耗多
select * from article_20220101 where id<last_id order by publish_time desc limit 0,20
select * from article_20220102where id<last_id order by publish_time desc limit 0,20
select * from article_20220103 where id<last_id order by publish_time desc limit 0,20
......
流式分片下的优化
目前 ShardingCore采用的是流式聚合+union all,当且仅当用户手动3调用UseUnionAllMerge时会将分片sql转成union all 聚合。
针对上述瀑布流的分页ShardingCore是这么操作的
确定分片表的顺序,也就是因为分片字段是
publish_time,又因为排序字段是publish_time所以分片表其实是有顺序的,也就是[article_20220105、article_20220104、article_20220103、article_20220102、article_20220101],
因为我们是开启n个并发线程所以这个排序可能没有意义,但是如果我们是仅开启设置单个连接并发的时候,程序将现在通过id说明:假设
last_id反解析出来的结果是2022-01-04 05:05:05那么可以基本上排除article_20220105,判断并发连接数如果是1那么直接查询article_20220104,如果不满足继续查询article_20220103,直到查询结果为20条如果并发连接数是2那么查询[article_20220104、article_20220103]如果不满足继续下面两张表直到获取到结果为20条数据,所以我们可以很清晰的了解其工作原理并且来优化
说明
通过上述优化可以保证流式聚合查询在顺序查询下的高性能O(1)
通过上述优化可以保证客户端分片拥有最小化连接数控制
设置合理的主键可以有效的解决我们在大数据分片下的性能优化
实践
ShardingCore目前针对分片查询进行了不断地优化和尽可能的无业务代码入侵来实现高性能分片查询聚合。
接下来我将为大家展示一款dotnet下唯一一款全自动路由、多字段分片、无代码入侵、高性能顺序查询的框架在传统数据库领域下的分片功能,如果你使用过我相信你一定会爱上他。
第一步:安装依赖
# ShardingCore核心框架 版本6.4.2.4+
PM> Install-Package ShardingCore
# 数据库驱动这边选择的是mysql的社区驱动 efcore6最新版本即可
PM> Install-Package Pomelo.EntityFrameworkCore.MySql
第二步添加对象和上下文
有很多朋友问我一定需要使用fluentapi来使用ShardingCore吗,只是个人喜好,这边我才用dbset+attribute来实现
//文章表
[Table(nameof(Article))]
public class Article
{
[MaxLength(128)]
[Key]
public string Id { get; set; }
[MaxLength(128)]
[Required]
public string Title { get; set; }
[MaxLength(256)]
[Required]
public string Content { get; set; }
public DateTime PublishTime { get; set; }
}
//dbcontext
public class MyDbContext:AbstractShardingDbContext,IShardingTableDbContext
{
public MyDbContext(DbContextOptions options) : base(options)
{
//请勿添加会导致efcore 的model提前加载的方法如Database.xxxx
}
public IRouteTail RouteTail { get; set; }
public DbSet Articles { get; set; }
}
第三步:添加文章路由
public class ArticleRoute:AbstractSimpleShardingDayKeyDateTimeVirtualTableRoute
{
public override void Configure(EntityMetadataTableBuilder builder)
{
builder.ShardingProperty(o => o.PublishTime);
}
public override bool AutoCreateTableByTime()
{
return true;
}
public override DateTime GetBeginTime()
{
return new DateTime(2022, 3, 1);
}
}
到目前为止基本上Article已经支持了按天分表
第四步:添加查询配置,让框架知道我们是顺序分表且定义分表的顺序
public class TailDayReverseComparer : IComparer<string>
{
public int Compare(string? x, string? y)
{
//程序默认使用的是正序也就是按时间正序排序我们需要使用倒序所以直接调用原生的比较器然后乘以负一即可
return Comparer<string>.Default.Compare(x, y) * -1;
}
}
//当前查询满足的复核条件必须是单个分片对象的查询,可以join普通非分片表
public class ArticleEntityQueryConfiguration:IEntityQueryConfiguration
{
public void Configure(EntityQueryBuilder builder)
{
//设置默认的框架针对Article的排序顺序,这边设置的是倒序
builder.ShardingTailComparer(new TailDayReverseComparer());
////如下设置和上述是一样的效果让框架真对Article的后缀排序使用倒序
//builder.ShardingTailComparer(Comparer.Default, false);
//简单解释一下下面这个配置的意思
//第一个参数表名Article的哪个属性是顺序排序和Tail按天排序是一样的这边使用了PublishTime
//第二个参数表示对属性PublishTime asc时是否和上述配置的ShardingTailComparer一致,true表示一致,很明显这边是相反的因为默认已经设置了tail排序是倒序
//第三个参数表示是否是Article属性才可以,这边设置的是名称一样也可以,因为考虑到匿名对象的select
builder.AddOrder(o => o.PublishTime, false,SeqOrderMatchEnum.Owner|SeqOrderMatchEnum.Named);
//这边为了演示使用的id是简单的时间格式化所以和时间的配置一样
builder.AddOrder(o => o.Id, false,SeqOrderMatchEnum.Owner|SeqOrderMatchEnum.Named);
//这边设置如果本次查询默认没有带上述配置的order的时候才用何种排序手段
//第一个参数表示是否和ShardingTailComparer配置的一样,目前配置的是倒序,也就是从最近时间开始查询,如果是false就是从最早的时间开始查询
//后面配置的是熔断器,也就是复核熔断条件的比如FirstOrDefault只需要满足一个就可以熔断
builder.AddDefaultSequenceQueryTrip(true, CircuitBreakerMethodNameEnum.Enumerator, CircuitBreakerMethodNameEnum.FirstOrDefault);
//这边配置的是当使用顺序查询配置的时候默认开启的连接数限制是多少,startup一开始可以设置一个默认是当前cpu的线程数,这边优化到只需要一个线程即可,当然如果跨表那么就是串行执行
builder.AddConnectionsLimit(1, LimitMethodNameEnum.Enumerator, LimitMethodNameEnum.FirstOrDefault);
}
}
第五步:添加配置到路由
public class ArticleRoute:AbstractSimpleShardingDayKeyDateTimeVirtualTableRoute
{
//省略.....
public override IEntityQueryConfiguration CreateEntityQueryConfiguration()
{
return new ArticleEntityQueryConfiguration();
}
}
第六步:startup配置
var builder = WebApplication.CreateBuilder(args);
// Add services to the container.
ILoggerFactory efLogger = LoggerFactory.Create(builder =>
{
builder.AddFilter((category, level) => category == DbLoggerCategory.Database.Command.Name && level == LogLevel.Information).AddConsole();
});
builder.Services.AddControllers();
builder.Services.AddShardingDbContext()
.AddEntityConfig(o =>
{
o.CreateShardingTableOnStart = true;
o.EnsureCreatedWithOutShardingTable = true;
o.AddShardingTableRoute();
})
.AddConfig(o =>
{
o.ConfigId = "c1";
o.UseShardingQuery((conStr, b) =>
{
b.UseMySql(conStr, new MySqlServerVersion(new Version())).UseLoggerFactory(efLogger);
});
o.UseShardingTransaction((conn, b) =>
{
b.UseMySql(conn, new MySqlServerVersion(new Version())).UseLoggerFactory(efLogger);
});
o.AddDefaultDataSource("ds0", "server=127.0.0.1;port=3306;database=ShardingWaterfallDB;userid=root;password=root;");
o.ReplaceTableEnsureManager(sp => new MySqlTableEnsureManager());
}).EnsureConfig();
var app = builder.Build();
app.Services.GetRequiredService().Start();
using (var scope = app.Services.CreateScope())
{
var myDbContext = scope.ServiceProvider.GetRequiredService();
if (!myDbContext.Articles.Any())
{
List articles = new List();
var beginTime = new DateTime(2022, 3, 1, 1, 1,1);
for (int i = 0; i < 70; i++)
{
var article = new Article();
article.Id = beginTime.ToString("yyyyMMddHHmmss");
article.Title = "标题" + i;
article.Content = "内容" + i;
article.PublishTime = beginTime;
articles.Add(article);
beginTime= beginTime.AddHours(2).AddMinutes(3).AddSeconds(4);
}
myDbContext.AddRange(articles);
myDbContext.SaveChanges();
}
}
app.MapControllers();
app.Run();
第七步编写查询表达式
public async Task Waterfall([FromQuery] string lastId,[FromQuery]int take)
{
Console.WriteLine($"-----------开始查询,lastId:[{lastId}],take:[{take}]-----------");
var list = await _myDbContext.Articles.WhereIf(o => String.Compare(o.Id, lastId) < 0,!string.IsNullOrWhiteSpace(lastId)).Take(take)..OrderByDescending(o => o.PublishTime)ToListAsync();
return Ok(list);
}
运行程序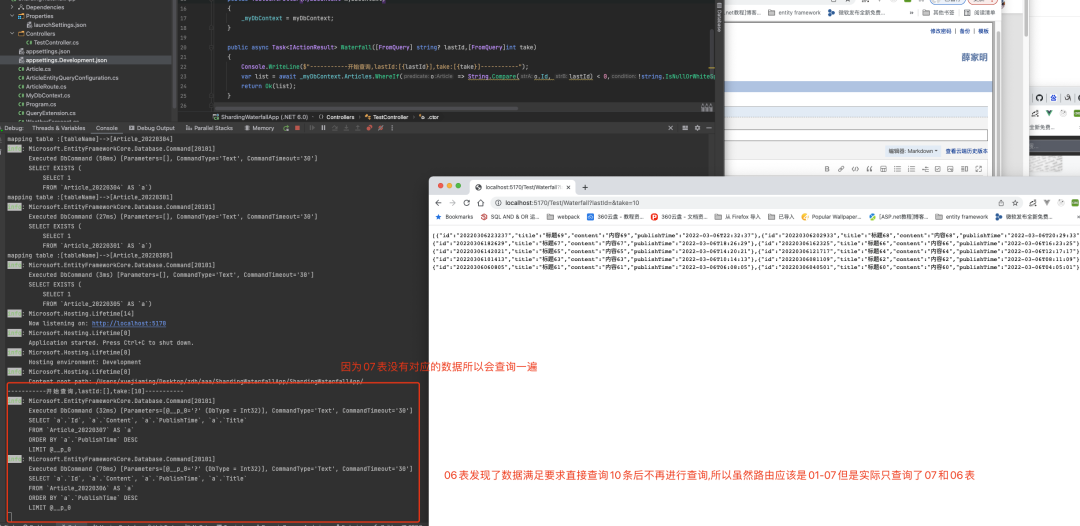
因为07表是没有的所以这次查询会查询07和06表,之后我们进行下一次分页传入上次id
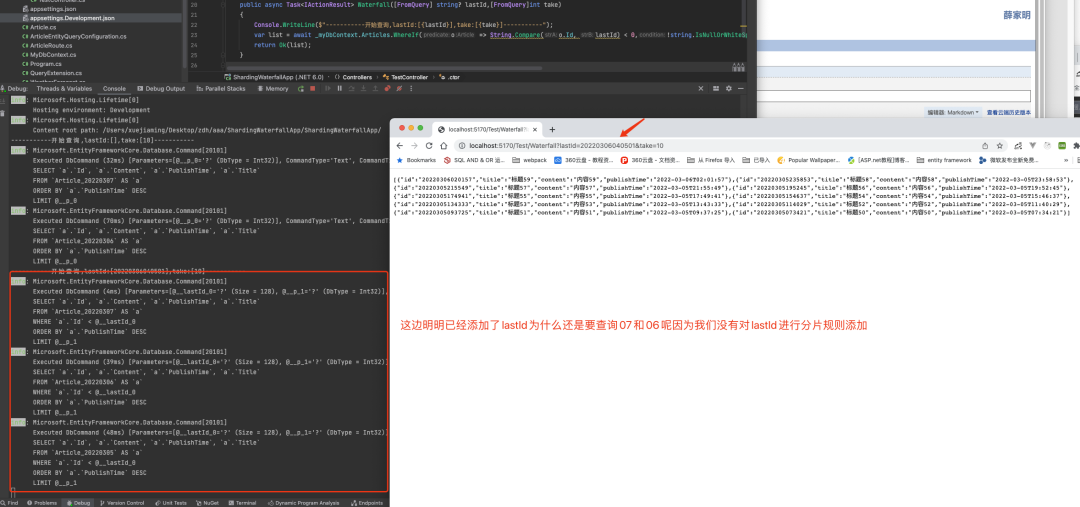
因为没有对Article.Id进行分片路由的规则编写所以没办法进行对id的过滤,那么接下来我们配置Id的分片规则
首先针对ArticleRoute进行代码编写
public class ArticleRoute:AbstractSimpleShardingDayKeyDateTimeVirtualTableRoute
{
public override void Configure(EntityMetadataTableBuilder builder)
{
builder.ShardingProperty(o => o.PublishTime);
builder.ShardingExtraProperty(o => o.Id);
}
public override bool AutoCreateTableByTime()
{
return true;
}
public override DateTime GetBeginTime()
{
return new DateTime(2022, 3, 1);
}
public override IEntityQueryConfiguration CreateEntityQueryConfiguration()
{
return new ArticleEntityQueryConfiguration();
}
public override Expressionstring, bool>> GetExtraRouteFilter(object shardingKey, ShardingOperatorEnum shardingOperator, string shardingPropertyName)
{
switch (shardingPropertyName)
{
case nameof(Article.Id): return GetArticleIdRouteFilter(shardingKey, shardingOperator);
}
return base.GetExtraRouteFilter(shardingKey, shardingOperator, shardingPropertyName);
}
///
/// 文章id的路由
///
///
///
///
private Expressionstring, bool>> GetArticleIdRouteFilter(object shardingKey,
ShardingOperatorEnum shardingOperator)
{
//将分表字段转成订单编号
var id = shardingKey?.ToString() ?? string.Empty;
//判断订单编号是否是我们符合的格式
if (!CheckArticleId(id, out var orderTime))
{
//如果格式不一样就直接返回false那么本次查询因为是and链接的所以本次查询不会经过任何路由,可以有效的防止恶意攻击
return tail => false;
}
//当前时间的tail
var currentTail = TimeFormatToTail(orderTime);
//因为是按月分表所以获取下个月的时间判断id是否是在临界点创建的
//var nextMonthFirstDay = ShardingCoreHelper.GetNextMonthFirstDay(DateTime.Now);//这个是错误的
var nextMonthFirstDay = ShardingCoreHelper.GetNextMonthFirstDay(orderTime);
if (orderTime.AddSeconds(10) > nextMonthFirstDay)
{
var nextTail = TimeFormatToTail(nextMonthFirstDay);
return DoArticleIdFilter(shardingOperator, orderTime, currentTail, nextTail);
}
//因为是按月分表所以获取这个月月初的时间判断id是否是在临界点创建的
//if (orderTime.AddSeconds(-10) < ShardingCoreHelper.GetCurrentMonthFirstDay(DateTime.Now))//这个是错误的
if (orderTime.AddSeconds(-10) < ShardingCoreHelper.GetCurrentMonthFirstDay(orderTime))
{
//上个月tail
var previewTail = TimeFormatToTail(orderTime.AddSeconds(-10));
return DoArticleIdFilter(shardingOperator, orderTime, previewTail, currentTail);
}
return DoArticleIdFilter(shardingOperator, orderTime, currentTail, currentTail);
}
private Expressionstring, bool>> DoArticleIdFilter(ShardingOperatorEnum shardingOperator, DateTime shardingKey, string minTail, string maxTail)
{
switch (shardingOperator)
{
case ShardingOperatorEnum.GreaterThan:
case ShardingOperatorEnum.GreaterThanOrEqual:
{
return tail => String.Compare(tail, minTail, StringComparison.Ordinal) >= 0;
}
case ShardingOperatorEnum.LessThan:
{
var currentMonth = ShardingCoreHelper.GetCurrentMonthFirstDay(shardingKey);
//处于临界值 o=>o.time < [2021-01-01 00:00:00] 尾巴20210101不应该被返回
if (currentMonth == shardingKey)
return tail => String.Compare(tail, maxTail, StringComparison.Ordinal) < 0;
return tail => String.Compare(tail, maxTail, StringComparison.Ordinal) <= 0;
}
case ShardingOperatorEnum.LessThanOrEqual:
return tail => String.Compare(tail, maxTail, StringComparison.Ordinal) <= 0;
case ShardingOperatorEnum.Equal:
{
var isSame = minTail == maxTail;
if (isSame)
{
return tail => tail == minTail;
}
else
{
return tail => tail == minTail || tail == maxTail;
}
}
default:
{
return tail => true;
}
}
}
private bool CheckArticleId(string orderNo, out DateTime orderTime)
{
//yyyyMMddHHmmss
if (orderNo.Length == 14)
{
if (DateTime.TryParseExact(orderNo, "yyyyMMddHHmmss", CultureInfo.InvariantCulture,
DateTimeStyles.None, out var parseDateTime))
{
orderTime = parseDateTime;
return true;
}
}
orderTime = DateTime.MinValue;
return false;
}
}
完整路由:针对Id进行多字段分片并且支持大于小于排序
以上是多字段分片的优化,详情博客可以点击这边 .Net下你不得不看的分表分库解决方案-多字段分片
然后我们继续查询看看结果
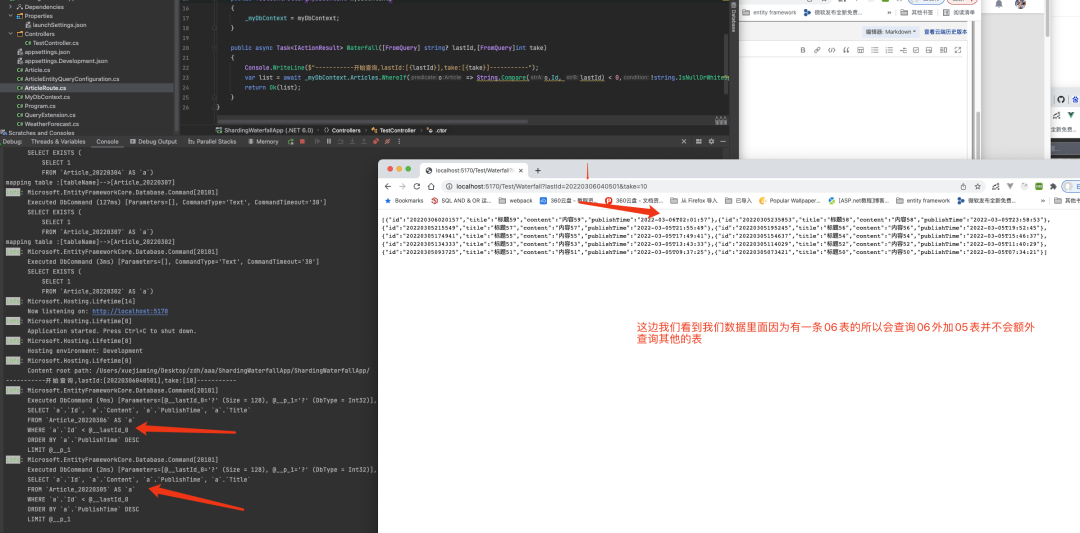
第三页也是如此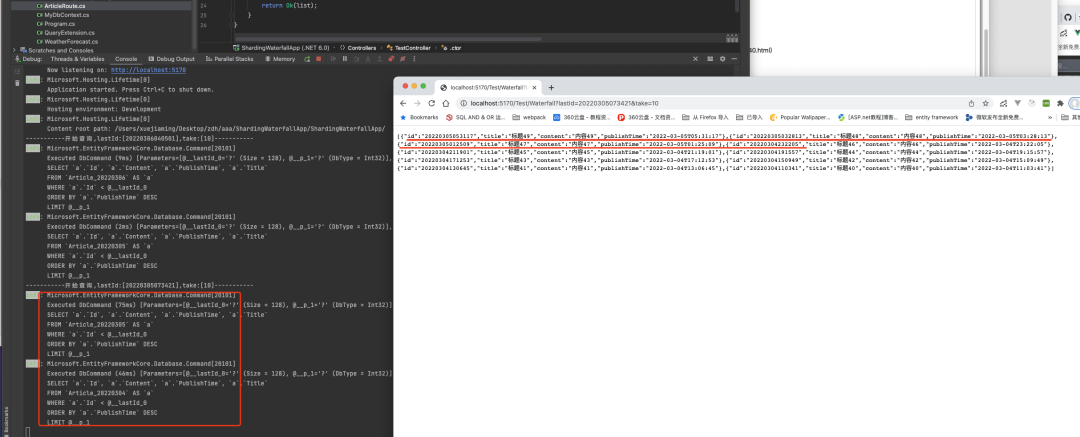
demo
DEMO
总结
当前框架虽然是一个很年轻的框架,但是我相信我对其在分片领域的性能优化应该在.net现有的所有框架下找不出第二个,并且框架整个也支持union all聚合,可以满足列入group+first的特殊语句的查询,又有很高的性能,一个不但是全自动分片而且还是高性能框架拥有非常多的特性性能,目标是榨干客户端分片的最后一点性能。
MAKE DOTNET GREAT AGAIN
最后的最后
身位一个dotnet程序员我相信在之前我们的分片选择方案除了mycat和shardingsphere-proxy外没有一个很好的分片选择,但是我相信通过ShardingCore 的原理解析,你不但可以了解到大数据下分片的知识点,更加可以参与到其中或者自行实现一个,我相信只有了解了分片的原理dotnet才会有更好的人才和未来,我们不但需要优雅的封装,更需要原理的是对原理了解。
我相信未来dotnet的生态会慢慢起来配上这近乎完美的语法
您的支持是开源作者能坚持下去的最大动力
Github ShardingCore
Gitee ShardingCore
博客
QQ群:771630778
个人QQ:326308290(欢迎技术支持提供您宝贵的意见)
个人邮箱:326308290@qq.com
往期精彩回顾.NET Core实战项目之CMS 第一章 入门篇-开篇及总体规划
【.NET Core微服务实战-统一身份认证】开篇及目录索引
Redis基本使用及百亿数据量中的使用技巧分享(附视频地址及观看指南)
.NET Core中的一个接口多种实现的依赖注入与动态选择看这篇就够了
用abp vNext快速开发Quartz.NET定时任务管理界面
在ASP.NET Core中创建基于Quartz.NET托管服务轻松实现作业调度