
图解 Kafka 生产者元数据拉取管理全流程
阅读本文大约需要 60 分钟。
大家好,我是 华仔, 又跟大家见面了。
在上一篇中,正式开启了「Kafka的源码之旅」,主要讲述了 KafkaProducer 初始化时用到的核心组件以及消息发送的核心流程,带你梳理生产者初始化整体的源码分析脉络,并通过「场景驱动」的方式带大家一点点的对 Kafka 源码进行深度剖析,一起掌握 Kafka 源码核心架构设计思想。
今天这篇我们就来聊聊生产者是会如何拉取和管理元数据的,带你梳理生产者元数据管理整体的源码分析脉络。
认真读完这篇文章,我相信你会对 Kafka 生产获取和管理元数据源码有更加深刻的理解。
这篇文章干货很多,希望你可以耐心读完。
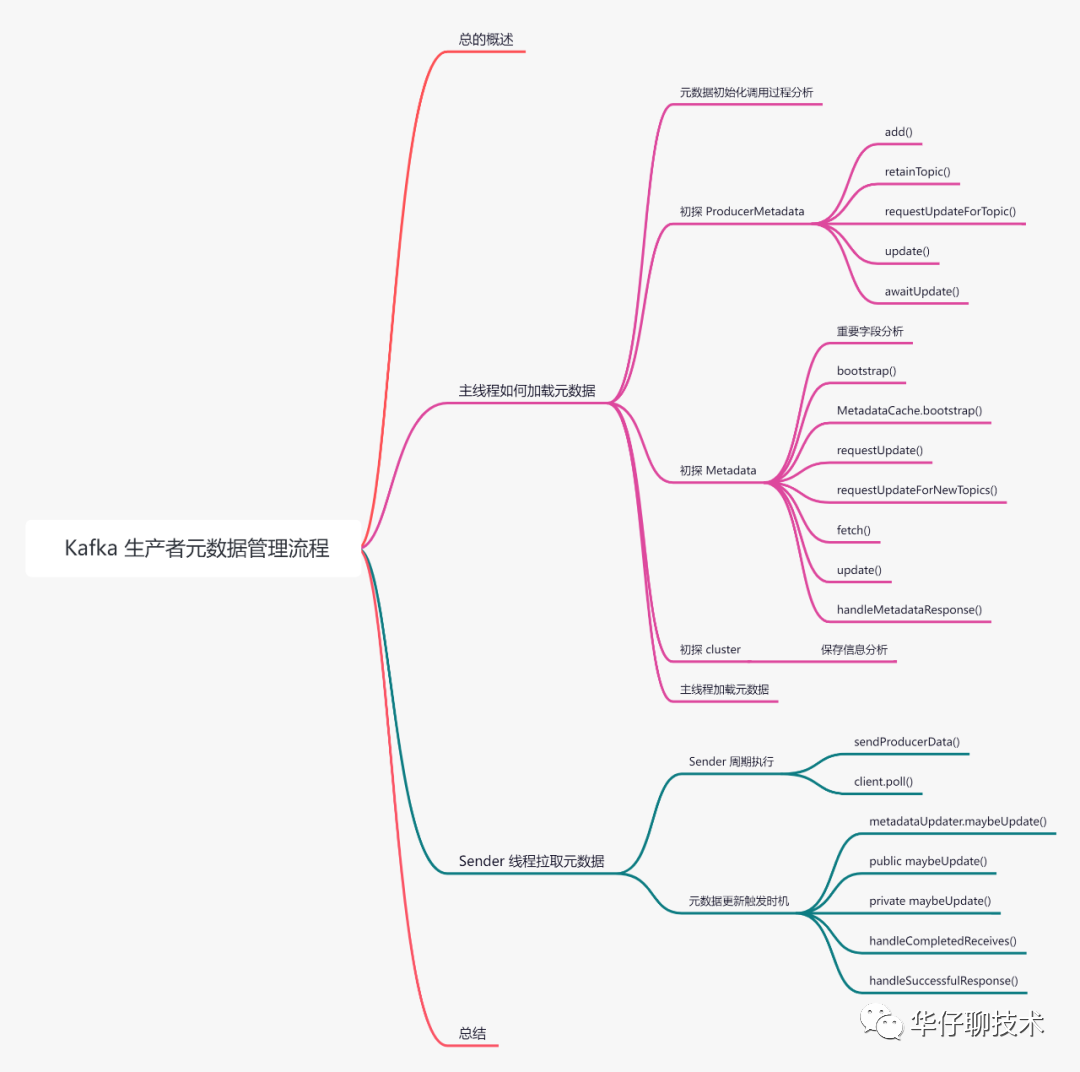
01 总的概述
消息想从 Producer 端发送到 Broker 端,必须要先知道 Topic 在 Broker 的分布情况,才能判断消息该发往哪些节点,比如:「Topic 对应的 Leader 分区有哪些」、「Leader分区分布在哪些 Broker 节点」、「Topic 分区动态变更」等等,所以及时获取元数据对生产者正常工作是非常有必要的。
元数据获取涉及的底层组件比较多,主要分为:「KafkaProducer 主线程加载元数据」、「Sender 子线程拉取元数据」。
接下来我们逐一分析元数据在生产者端是如何被加载和拉取、更新的。为了方便大家理解,所有的源码只保留骨干。
02 主线程如何加载元数据
首先我们来看下 KafkaProducer 主线程是如何加载元数据的。
在上一篇中《图解Kafka生产者初始化核心流程》我们分析知道集群元数据的初始化是在 KafkaProducer 主线程的构造函数中来完成的,我们来看一下相关源码:
// 初始化 Kafka 集群元数据,元数据会保存到客户端中,并与服务端元数据保持一致
if (metadata != null) {
this.metadata = metadata;
} else {
// 初始化集群元数据
this.metadata = new ProducerMetadata(retryBackoffMs,
// 元数据过期时间:默认5分钟
config.getLong(ProducerConfig.METADATA_MAX_AGE_CONFIG),
// topic最大空闲时间,如果在规定时间没有被访问,将从缓存删除,下次访问时强制获取元数据
config.getLong(ProducerConfig.METADATA_MAX_IDLE_CONFIG),
logContext,
clusterResourceListeners,
Time.SYSTEM);
// 启动metadata的引导程序
this.metadata.bootstrap(addresses);
}
从上述源代码我们可以看出在 KafkaProducer 的构造方法中,如果metadata为空就会初始化集群元数据类「ProducerMetadata」,然后通过调用 「this.metadata.bootstrap」这个方法来启动引导程序,这时 metaData 对象里并没有具体的元数据信息,因为客户端还没发送元数据更新的请求,后面会通过唤醒 Sender 线程进行发送请求获取元数据的。
这里的 this.meta 其实就是 Kafka 内存中的一个对象,底层会做一层缓存,因此并不会一直请求 Kafka Broker 端进行获取。
我先给大家总结下元数据初始化及启动的调用关系图,口说无凭,我们来扒开源码瞅一瞅,这样更真实。
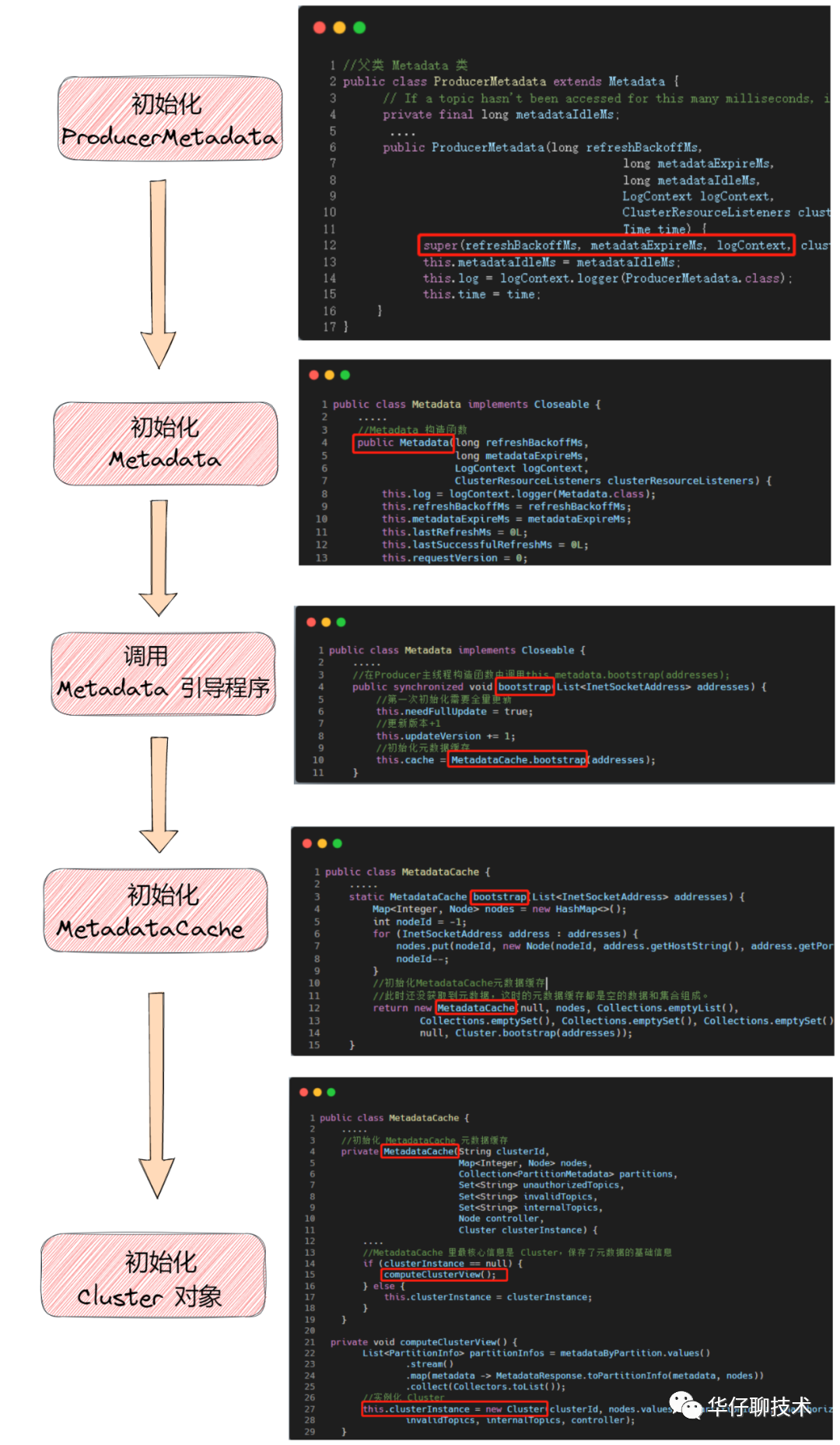
通过上述的调用关系图,我们可以看出:
ProducerMetadata 类是 MetaData 的子类。 Metadata 类是元数据基类,封装了元数据的具体信息、版本控制、更新标识、响应解析等。 元数据的信息其实最终是保存在元数据缓存即 MetadataCache 中,而 它最核心的是 Cluster , 保存了元数据基础信息。
接下来会挨个类展开来进行讲解。
02.1 初探 ProducerMetadata
在主线程中初始化了 ProducerMetadata 类的对象,我们先来看看这个类都做了哪些事情。
github 源码地址如下:
https://github.com/apache/kafka/blob/2.7/clients/src/main/java/org/apache/kafka/clients/producer/internals/ProducerMetadata.java
public class ProducerMetadata extends Metadata {
// 主题元数据过期时间,如果在这个时间段内未被访问,它就会从缓存中删除。
private final long metadataIdleMs;
/* Topics with expiry time */
// map集合,生产者的元数据主题集合,里面保存着
// 主题和主题过期时间的对应关系,即 topic, nowMs + metadataIdleMs,
// 过期了的主题会被踢出去。
private final Map topics = new HashMap<>();
// 新的主题集合, set集合,即第一次要发送的主题
private final Set newTopics = new HashSet<>();
private final Logger log;
private final Time time;
public ProducerMetadata(long refreshBackoffMs,
long metadataExpireMs,
long metadataIdleMs,
LogContext logContext,
ClusterResourceListeners clusterResourceListeners,
Time time) {
//调用父类 Metadata 的构造函数
super(refreshBackoffMs, metadataExpireMs, logContext, clusterResourceListeners);
....
}
}
我们可以看出这里只是调用了父类的构造函数进行类属性的初始化,接下来我们深度分析下 ProducerMetadata 类中的几个比较重要的方法。
02.1.1 add()
public synchronized void add(String topic, long nowMs) {
// 判断对象是否为空
Objects.requireNonNull(topic, "topic cannot be null");
if (topics.put(topic, nowMs + metadataIdleMs) == null) {
// 添加主题到新主题集合中
newTopics.add(topic);
// 更新元数据标记 属于Metadata类方法,后面小节分析
requestUpdateForNewTopics();
}
}
该方法主要用来向元数据主题集合 topics 中添加主题,主要用在「KafkaProducer 主线程」以及「Sender 子线程」中,我们来看下是如何添加的,具体逻辑如下:
往元数据主题集合 topics 中添加主题和对应的过期时间(当时时间+过期时间段「默认值:5分钟」)。 如果元数据主题集合中不存在该主题时,说明是第一次就把该主题添加到新主题集合中。 标记要更新新主题元数据的属性字段「lastRefreshMs」 、「needPartialUpdate」 、「requestVersion」,以便后续唤醒 Sender 线程去服务端拉取新主题的元数据。
此时主题被添加到元数据主题主题集合中,但是如果集合里面数据过期了该怎么办?接下来我们看另外一个方法是如何判断的。
02.1.2 retainTopic()
public synchronized boolean retainTopic(String topic, boolean isInternal, long nowMs) {
// 获取该主题的过期时间
Long expireMs = topics.get(topic);
// 如果为空表示该主题不在元数据主题集合中
if (expireMs == null) {
return false;
// 判断该主题是否在新集合中
} else if (newTopics.contains(topic)) {
return true;
// 判断是否超过了过期时间
} else if (expireMs <= nowMs) {
log.debug("Removing unused topic {} from the metadata list, expiryMs {} now {}", topic, expireMs, nowMs);
// 超过后直接从元数据主题集合中删除该主题
topics.remove(topic);
return false;
} else {
return true;
}
}
该方法用来判断元数据中是否该保留该主题,会在 handleMetadataResponse 即处理元数据响应结果的时候进行调用,我们来看下它是如何判断的。
先判断元数据主题集合中是否存在该主题,如果不存在直接返回false。 然后判断该主题是否在新主题集合中,如果存在直接返回true。 再判断该主题是否超过了过期时间,如果超过了,就从元数据主题集合中删除该主题,再请求元数据的时候就不用带上该主题,可以有效的减少网络传输数据大小。
02.1.3 requestUpdateForTopic()
public synchronized int requestUpdateForTopic(String topic) {
// 如果新主题集合中存在该主题
if (newTopics.contains(topic)) {
// 针对新主题集合标记部分更新,并返回版本
return requestUpdateForNewTopics();
} else {
// 全量更新,并返回版本
return requestUpdate();
}
}
该方法用来判断是全量更新元数据还是部分更新元数据,逻辑相对比较简单,主要用在 KafkaProducer 主线程元数据同步等待时调用,后续小节会详细分析。
02.1.4 update()
public synchronized void update(int requestVersion, MetadataResponse response, boolean isPartialUpdate, long nowMs) {
// 调用父类的update方法
super.update(requestVersion, response, isPartialUpdate, nowMs);
// 如果新主题集合不为空,则遍历响应元数据找出已经获取元数据的主题,并从新主题集合中删除
if (!newTopics.isEmpty()) {
for (MetadataResponse.TopicMetadata metadata : response.topicMetadata()) {
newTopics.remove(metadata.topic());
}
}
// 唤醒等待元数据更新完成的线程
notifyAll();
}
该方法用来更新生产端元数据的,具体逻辑如下:
先调用父类的 update() 方法。 然后判断新主题集合是否不为空,如果不为空则遍历响应元数据找出已经获取元数据的主题,并从新主题集合中删除。 最后调用 notifyAll() 来唤醒等待元数据更新完成的线程。
从上述 update()方法 中可以看出最后调用 notifyAll() 来唤醒阻塞的线程, 那么它是如何唤醒的呢,这就是接下来要分析的方法。
02.1.5 awaitUpdate()
public synchronized void awaitUpdate(final int lastVersion, final long timeoutMs) throws InterruptedException {
long currentTimeMs = time.milliseconds();
long deadlineMs = currentTimeMs + timeoutMs < 0 ? Long.MAX_VALUE : currentTimeMs + timeoutMs;
// 通过调用 time.waitObject 来实现线程阻塞
time.waitObject(this, () -> {
// Throw fatal exceptions, if there are any. Recoverable topic errors will be handled by the caller.
maybeThrowFatalException();
return updateVersion() > lastVersion || isClosed();
}, deadlineMs);
if (isClosed())
throw new KafkaException("Requested metadata update after close");
}
该方法用来实现线程阻塞的功能,用在主线程中如果发现主题对应的元数据不存在时,阻塞并等待 Sender 线程将元数据更新完成。
重点是调用了 time.waitObject() 方法来实现阻塞功能,它的实现还是有一些技巧的,它的底层通过调用 SystemTime 包里面的 waitObject() 实现的,源码如下:
public void waitObject(Object obj, Supplier condition, long deadlineMs) throws InterruptedException {
synchronized (obj) {
while (true) {
// 判断条件是否满足即元数据是否更新成功,成功直接返回
if (condition.get())
return;
long currentTimeMs = milliseconds();
// 超时抛出异常
if (currentTimeMs >= deadlineMs)
throw new TimeoutException("Condition not satisfied before deadline");
// 调用 wait 阻塞线程
obj.wait(deadlineMs - currentTimeMs);
}
}
}
通过一个循环来判断条件是否满足,即元数据是否更新成功了,如果成功则跳出循环,释放锁。 获取当前时间,判断是否超时,如果超时后会抛出超时的异常。 如果未超时就调用 wait 方法来阻塞线程,直到满足过期时间的条件,解除阻塞。
如果你的项目中也需要类似的功能要实现一个锁,可以参考这里的代码,实现非常巧妙。
接下来我们来重点分析下元数据基类。
02.2 初探 Metadata
首先它是一个线程安全的类,因此Metadata通过synchronized修饰几乎所有方法来保证线程安全,里面封装了元数据基本信息以及元数据的相关操作,主要被用在生产端的 「KafkaProducer 主线程」、「Sender 子线程」中,对于生产者来说只需要获取自己发送的主题集合的元数据,这样可以有效降低网络传输的数据量。因此,它内部只维护部分主题的元数据。
github 源码地址如下:
https://github.com/apache/kafka/blob/2.7/clients/src/main/java/org/apache/kafka/clients/Metadata.java
https://github.com/apache/kafka/blob/2.7/clients/src/main/java/org/apache/kafka/clients/MetadataCache.java
我们先来看下这个类的重要字段:
public class Metadata implements Closeable {
private final Logger log;
// 请求元数据失败后重试间隔时间,默认值:100ms
private final long refreshBackoffMs;
// 元数据过期时间,默认值:5分钟
private final long metadataExpireMs;
// 元数据版本号,每次请求服务端+1,保存在本地内存中
private int updateVersion;
// 元数据加入到新主题集合的版本号
private int requestVersion;
// 最后一次更新元数据的时间
private long lastRefreshMs;
// 最后一次成功更新全部主题元数据的时间
private long lastSuccessfulRefreshMs;
// 失败异常
private KafkaException fatalException;
// 无效的主题集合
private Set invalidTopics;
// 无权限的主题集合
private Set unauthorizedTopics;
// 元数据缓存
private MetadataCache cache = MetadataCache.empty();
// 是否全部主题更新
private boolean needFullUpdate;
// 是否部分主题更新
private boolean needPartialUpdate;
// 初始化 Metadata
public Metadata(long refreshBackoffMs,
long metadataExpireMs,
LogContext logContext,
ClusterResourceListeners clusterResourceListeners) {
this.refreshBackoffMs = refreshBackoffMs;
this.metadataExpireMs = metadataExpireMs;
this.lastRefreshMs = 0L;
this.lastSuccessfulRefreshMs = 0L;
this.requestVersion = 0;
this.updateVersion = 0;
this.needFullUpdate = false;
this.needPartialUpdate = false;
this.invalidTopics = Collections.emptySet();
this.unauthorizedTopics = Collections.emptySet();
}
refreshBackoffMs:请求元数据失败后重试间隔时间,默认值:100ms。 metadataExpireMs:元数据过期时间,默认值:5分钟,时间一到会再次发送获取元数据的请求。 updateVersion:元数据版本号,每次请求服务端+1,保存在本地内存中。 requestVersion:元数据加入到新主题集合的版本号,每次+1。 lastRefreshMs:最后一次更新元数据的时间。 lastSuccessfulRefreshMs:最后一次成功更新全部主题元数据的时间。 fatalException:失败异常。 invalidTopics:无效的主题集合。 unauthorizedTopics:无权限的主题集合。 MetadataCache:元数据缓存,客户端真正存储元数据的对象。 needFullUpdate:是否全部主题更新,对生产者来说,全部主题是指最近发送的主题集合。 needPartialUpdate:是否部分主题更新,对生产者来说,部分主题是指新发送的主题集合。
介绍完字段后,我们来深度分析下几个元数据用到的重要方法。
02.2.1 bootstrap()
public synchronized void bootstrap(List addresses) {
// 是否全部主题更新为true
this.needFullUpdate = true;
// 版本更新为1
this.updateVersion += 1;
// 初始化元数据缓存
this.cache = MetadataCache.bootstrap(addresses);
}
该方法用来引导启动程序的,即在第一次使用前进行初始化的工作。
由于此时生产者刚启动,本地缓存中的元数据是空的,因此先将 needFullUpdate 置为 true,即需要全部主题进行更新。 在初始化时将 updateVersion 置为 0,此时将版本更新+1。 调用元数据缓存类 MetadataCache.bootstrap() 初始化元数据缓存。
我们来看下元数据缓存的启动程序都做了哪些事情。
02.2.2 MetadataCache.bootstrap()
static MetadataCache bootstrap(List addresses) {
...
// 因还未获取元数据,此时元数据缓存都是空集合
return new MetadataCache(null, nodes, Collections.emptyList(),
Collections.emptySet(), Collections.emptySet(), Collections.emptySet(),
null, Cluster.bootstrap(addresses));
}
此时获取元数据被启动了,但是还未获取元首,所以元数据缓存都是空的集合,接下来我们来分析下元数据是如何被更新以及如何解析响应的,这里涉及到以下几个方法。
02.2.3 requestUpdate()
/**
* Request an update of the current cluster metadata info, return the current updateVersion before the update
*/
public synchronized int requestUpdate() {
// 全部主题更新设置为true
this.needFullUpdate = true;
// 返回元数据版本号
return this.updateVersion;
}
该方法用来设置全部主题更新的标记,上来就先将 needFullUpdate 置为 true,即要全部更新主题,然后返回更新版本。 主要在「ProducerMetadata」、「sender 子线程」、「NetworkClient线程」中使用。
02.2.4 requestUpdateForNewTopics()
public synchronized int requestUpdateForNewTopics() {
// 重写上次刷新的时间戳以允许立即更新。
this.lastRefreshMs = 0;
// 部分主题更新设置为true
this.needPartialUpdate = true;
// 元数据加入到新主题集合的版本号 + 1
this.requestVersion++;
// 返回元数据版本号
return this.updateVersion;
}
该方法用来设置新集合主题更新的标记,这里并未真正发送更新元数据的请求,只是设置标识位的值,Kafka必须确保在第一次拉消息前元数据是可用的,即必须更新一次元数据。
将 lastRefreshMs 设置为0,即重写上次刷新的时间戳以允许立即更新。 将需要更新元数据的标志位 needPartialUpdate 设置 true。 将元数据加入到新主题集合的版本号 requestVersion +1 。 返回元数据版本号。
02.2.3 fetch()
/**
* Get the current cluster info without blocking
*/
public synchronized Cluster fetch() {
// 返回元数据缓存
return cache.cluster();
}
该方法用来获取集群元数据的,默认从元数据缓存中返回元数据。
02.2.4 update()
public synchronized void update(int requestVersion, MetadataResponse response, boolean isPartialUpdate, long nowMs) {
.....
// 是否是部分主题更新标记
this.needPartialUpdate = requestVersion < this.requestVersion;
// 最后一次更新元数据的时间为当前时间
this.lastRefreshMs = nowMs;
// 元数据版本号 +1
this.updateVersion += 1;
// 判断非部分更新即全部主题更新
if (!isPartialUpdate) {
// 全部主题更新标记为否
this.needFullUpdate = false;
// 最后一次成功更新全部主题元数据的时间更新为当前时间
this.lastSuccessfulRefreshMs = nowMs;
}
String previousClusterId = cache.clusterResource().clusterId();
// 解析元数据响应结果
this.cache = handleMetadataResponse(response, isPartialUpdate, nowMs);
....
}
该方法主要做了几件事情,具体如下:
设置是否是部分主题更新 needPartialUpdate,根据参数:元数据加入到新主题集合的版本号 「requestVersion」与「元数据中的requestVersion」对比。 设置最后一次更新元数据的时间为当前时间。 设置元数据版本号 +1 。 判断是否全部主题更新,如果是则说明更新全部主题的响应已经收到了,此时将 needFullUpdate 标记为否,lastSuccessfulRefreshMs 更新为当前时间。 解析元数据响应结果,并设置缓存。
最后调用了 handleMetadataResponse 这个重要方法来解析元数据响应,接下来重点分析下它做了些什么。
02.2.5 handleMetadataResponse()
private MetadataCache handleMetadataResponse(MetadataResponse metadataResponse, boolean isPartialUpdate, long nowMs) {
// All encountered topics.
Set topics = new HashSet<>();
// 初始化相关主题集合
Set internalTopics = new HashSet<>();
Set unauthorizedTopics = new HashSet<>();
Set invalidTopics = new HashSet<>();
List partitions = new ArrayList<>();
// 遍历主题的元数据响应
for (MetadataResponse.TopicMetadata metadata : metadataResponse.topicMetadata()) {
// 将该主题添加到元数据主题集合中
topics.add(metadata.topic());
// 判断是否保留主题元数据
if (!retainTopic(metadata.topic(), metadata.isInternal(), nowMs))
continue;
// 判断是否是内部主题。
if (metadata.isInternal())
internalTopics.add(metadata.topic());
// 判断是否元数据响应error为空
if (metadata.error() == Errors.NONE) {
// 遍历分区信息
for (MetadataResponse.PartitionMetadata partitionMetadata : metadata.partitionMetadata()) {
....
// 判断分区元数据是否有无效异常
if (partitionMetadata.error.exception() instanceof InvalidMetadataException) {
....
// 标记全部主题更新
requestUpdate();
}
}
} else { // 如果元数据响应有错误
// 判断是否是无效元数据异常
if (metadata.error().exception() instanceof InvalidMetadataException) {
....
// 标记全部主题更新
requestUpdate();
}
// 判断是否无效主题错误
if (metadata.error() == Errors.INVALID_TOPIC_EXCEPTION)
// 将主题添加到无效主题集合中
invalidTopics.add(metadata.topic());
// 判断是否无权限主题错误
else if (metadata.error() == Errors.TOPIC_AUTHORIZATION_FAILED)
// 将主题添加到无权限主题集合中
unauthorizedTopics.add(metadata.topic());
}
}
Map nodes = metadataResponse.brokersById();
// 判断是否部分主题更新
if (isPartialUpdate)
// 如果是则与现在的元数据缓存合并在一起
return this.cache.mergeWith(metadataResponse.clusterId(), nodes, partitions,
unauthorizedTopics, invalidTopics, internalTopics, metadataResponse.controller(),
(topic, isInternal) -> !topics.contains(topic) && retainTopic(topic, isInternal, nowMs));
else
// 如果是全部主题更新的话,就重新初始化元数据缓存
return new MetadataCache(metadataResponse.clusterId(), nodes, partitions,
unauthorizedTopics, invalidTopics, internalTopics, metadataResponse.controller());
}
该方法用来解析元数据响应,我们具体分析下主流程的逻辑:
首先初始化相关集合:「内部主题集合」、「无效主题集合」、「无权限主题集合」。 遍历主题的元数据响应。 将该主题添加到元数据主题集合中。 判断是否保留主题元数据,如果过期可能就没必要保留了。 判断是否是内部主题,如果是内部主题就添加到内部主题集合。 判断是否元数据响应error为空的话
如果为空就开始遍历主题下的分区信息,更新本地元数据缓存。 判断分区元数据是否有无效异常,如果有则要打出相应的日志, 做好需要全部主题更新元数据的标记,后续会提醒 Sender 线程去更新元数据。 否则如果元数据响应error不为空的话
先判断是否是无效元数据异常,如果有则做好需要全部主题更新元数据的标记,后续会提醒 Sender 线程去更新元数据。 判断是否无效主题错误,如果是将主题添加到无效主题集合中。 判断是否无权限主题错误,如果是将主题添加到无权限主题集合中。 判断是否部分主题更新响应
如果是则与现在的元数据缓存合并在一起。 否则就重新初始化元数据缓存。
至此,元数据相关类的重要方法已经分析完毕,剩余没分析到的方法待到后续场景中进行分析,接下来我们看下主线程是如何加载元数据的。
02.3 初探 cluster
github 源码地址如下:
https://github.com/apache/kafka/blob/2.7/clients/src/main/java/org/apache/kafka/common/Cluster.java
https://github.com/apache/kafka/blob/2.7/clients/src/main/java/org/apache/kafka/common/Node.java
https://github.com/apache/kafka/blob/2.7/clients/src/main/java/org/apache/kafka/common/PartitionInfo.java
https://github.com/apache/kafka/blob/2.7/clients/src/main/java/org/apache/kafka/common/TopicPartition.java
public final class Cluster {
private final boolean isBootstrapConfigured;
// kafka集群中的broker节点
private final List nodes;
// 未授权的主题集合
private final Set unauthorizedTopics;
// 无效的主题集合
private final Set invalidTopics;
// 内部主题集合
private final Set internalTopics;
// controller 节点
private final Node controller;
// topic对应的 partition 信息字典,存放的 partition 不一定有 Leader 副本, 键为topic,值为 partition 信息集合。
private final Map partitionsByTopicPartition;
// 键为topic,值为可用 partition 信息集合,存放的 partition 一定有 Leader 副本
private final Map> partitionsByTopic;
// 键为broker的id,值为partition 信息集合
private final Map> availablePartitionsByTopic;
// 键为broker的id,值为表示该节点的node实例
private final Map> partitionsByNode;
private final Map nodesById;
private final ClusterResource clusterResource;
Cluster类基本保存了所有的kafka集群相关的信息。
Node broker节点的相关的信息
public class Node {
// broker 节点id
private final int id;
// broker 节点id的字符串
private final String idString;
// broker 节点的地址用于socket连接
private final String host;
// 端口
private final int port;
// broker 节点的机架
private final String rack;
// 初始化节点属性
public Node(int id, String host, int port, String rack) {
this.id = id;
this.idString = Integer.toString(id);
this.host = host;
this.port = port;
this.rack = rack;
}
}
PartitionInfo 分区信息
public class PartitionInfo {
// 主题
private final String topic;
// 分区编号id
private final int partition;
// 分区 Leader 副本信息,唯一进行通信的节点
private final Node leader;
// 全部副本信息
private final Node[] replicas;
// ISR 副本信息, follower角色
private final Node[] inSyncReplicas;
// 离线副本信息
private final Node[] offlineReplicas;
// 初始化分区信息
public PartitionInfo(String topic,
int partition,
Node leader,
Node[] replicas,
Node[] inSyncReplicas,
Node[] offlineReplicas) {
this.topic = topic;
this.partition = partition;
this.leader = leader;
this.replicas = replicas;
this.inSyncReplicas = inSyncReplicas;
this.offlineReplicas = offlineReplicas;
}
}
TopicPartition
每个topic和每个分区组成的唯一索引,代表一个分区标识。
public final class TopicPartition implements Serializable {
// hash值,用来hashCode方法缓存
private int hash = 0;
// 分区编号
private final int partition;
// 主题名称
private final String topic;
// 初始化主题分区索引
public TopicPartition(String topic, int partition) {
this.partition = partition;
this.topic = topic;
}
// 计算hash值
public int hashCode() {
if (hash != 0)
return hash;
final int prime = 31;
int result = 1;
result = prime * result + partition;
result = prime * result + Objects.hashCode(topic);
this.hash = result;
return result;
}
}
综上映射关系可以看出,kafka 是以「分区」为最小管理单元,然后分区中的 Leader 负责交互。「Cluster」代表整个kafka集群的实体类,「MetaData」的角色相当于「Cluster」的在客户端的一个维护者。
02.4 主线程加载元数据
我们先来看加载元数据大体过程。

接下来分析详细源码,首先客户端可以直接调用「 producer.send() 」进行发送,底层调用 doSend() 方法。
// 向 topic 异步地发送数据,当发送确认后唤起回调函数
public Future send(ProducerRecord record, Callback callback) {
ProducerRecord interceptedRecord = this.interceptors.onSend(record);
// 调用 doSend 发送,支持回调函数
return doSend(interceptedRecord, callback);
}
private Future doSend(ProducerRecord record, Callback callback) {
TopicPartition tp = null;
try {
// 假如 sender 线程为空或者不运行,报错
throwIfProducerClosed();
// 当前时间【毫秒】
long nowMs = time.milliseconds();
ClusterAndWaitTime clusterAndWaitTime;
try {
// 等待元数据更新
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), nowMs, maxBlockTimeMs);
} catch (KafkaException e) {
if (metadata.isClosed())
throw new KafkaException("Producer closed while send in progress", e);
throw e;
}
nowMs += clusterAndWaitTime.waitedOnMetadataMs;
long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);
Cluster cluster = clusterAndWaitTime.cluster;
....
// 将消息记录追加到消息缓冲区
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, true, nowMs);
// 当批次满了或者新批次被创建了,开始唤醒sender线程数据发送
if (result.batchIsFull || result.newBatchCreated) {
this.sender.wakeup();
}
return result.future;
} catch (ApiException e) {
....
return new FutureFailure(e);
} catch (InterruptedException e) {
....
throw new InterruptException(e);
} catch (KafkaException e) {
....
throw e;
} catch (Exception e) {
....
throw e;
}
}
从上述发送的源码中,可以看出来主线程在发送消息前需要先获取元数据,这样才能知道消息要发送到哪些节点。
中间通过调用 waitOnMetadata() 获取元数据的相关信息,为后续发送消息提供支持,接下来我们重点分析下 waitOnMetadata() 这个方法。
private ClusterAndWaitTime waitOnMetadata(String topic, Integer partition, long nowMs, long maxWaitMs) throws InterruptedException {
// 1. 从元数据缓存中获取元数据
Cluster cluster = metadata.fetch();
// 2. 判断该主题是否是无效的主题
if (cluster.invalidTopics().contains(topic))
throw new InvalidTopicException(topic);
// 3. 将该主题放入元数据主题列表中
metadata.add(topic, nowMs);
// 4. 从元数据缓存中获取主题对应的分区数
Integer partitionsCount = cluster.partitionCountForTopic(topic);
// 5. 满足这些条件后就不用拉取元数据,直接从元数据缓存中返回
if (partitionsCount != null && (partition == null || partition < partitionsCount))
// 返回元数据信息
return new ClusterAndWaitTime(cluster, 0);
long remainingWaitMs = maxWaitMs;
long elapsed = 0;
// 6. 不停的轮询唤醒 sender 线程更新元数据
do {
// 7. 将主题 topic及过期时间添加到元数据主题列表中
metadata.add(topic, nowMs + elapsed);
// 8. 标记元数据更新标识,获取元数据版本号
int version = metadata.requestUpdateForTopic(topic);
// 9. 唤醒 sender 子线程
sender.wakeup();
try {
// 10. 阻塞线程等待元数据更新成功
metadata.awaitUpdate(version, remainingWaitMs);
} catch (TimeoutException ex) {
...
}
// 11. 到这里,应该是当前cluster更新成功了,再次获取元数据
cluster = metadata.fetch();
// 12. 计算等待更新完成元数据消耗时间
elapsed = time.milliseconds() - nowMs;
// 13. 如果超时,抛超时异常
if (elapsed >= maxWaitMs) {
...
}
metadata.maybeThrowExceptionForTopic(topic);
remainingWaitMs = maxWaitMs - elapsed;
// 14. 获取元数据分区数
partitionsCount = cluster.partitionCountForTopic(topic);
} while (partitionsCount == null || (partition != null && partition >= partitionsCount));
// 15. 返回元数据以及消耗时间
return new ClusterAndWaitTime(cluster, elapsed);
}
该方法用来获取元数据以及元数据消耗时间,我们具体分析下主流程的逻辑:
从元数据缓存中获取元数据,如果metadata不存在当前topic的元数据,会触发一次强制刷新,metaData中的needUpdate置为true。 判断该主题是否是无效的主题, 如果是抛异常。 将该主题放入元数据的主题列表中,通过 Sender 线程定时更新这些主题的元数据。 从元数据缓存中获取主题对应的分区数。 判断元数据缓存是否能满足需要,就是说要能够找到要发送消息的主题分区,条件是:partitionsCount != null && (partition == null || partition < partitionsCount) 即「主题对应的分区数不能为空且发送的分区ID要小于主题的分区数」。 不停的轮询唤醒 sender 线程更新元数据,这里有两个条件要满足其一才可以。
partitionsCount == null 「从元数据缓存中获取主题对应的分区数为空」,这里要发送的主题连Leader分区都没有,可能主题分区根本不存在也可能没拉取到最新分区信息,如果真的不存在就没必要继续直接抛异常。 partition != null && partition >= partitionsCount「分区不为空且要发送的分区ID大于主题分区数」,这里说明了主题分区的数量增加了,需要重新拉取下获取最新分区信息。 将主题 topic及过期时间添加到元数据主题列表中 标记元数据更新标识,并获取当前元数据版本号,提醒 Sender 线程更新元数据。 唤醒 sender 子线程进行元数据更新以及消息发送。 阻塞主线程并等待Sender线程更新元数据成功。 待 「Sender 子线程更新元数据成功」或者「阻塞超时解除阻塞」,再次获取元数据。 计算等待更新完成元数据消耗时间。 如果超时,抛超时异常。maxWaitMs 最大1分钟。 获取元数据分区数。 返回元数据以及消耗时间。
聪明的读者可能发现在生产者中获取元数据都是基于topic的,主要原因就是对于生产者来说,没必要拉取全部的元数据,只拉取自己需要的主题元数据就可以了。
至此,元数据加载已经分析完了, 接下来我们看下 Sender 子线程是如何拉取元数据的。
03 Sender 线程拉取元数据
由于 Sender 线程的深度分析不是本文的重点,这里先简单的给大家带一带,后续会有专门篇章去分析。
github 源码地址如下:
https://github.com/apache/kafka/blob/2.7/clients/src/main/java/org/apache/kafka/clients/producer/internals/Sender.java
https://github.com/apache/kafka/blob/2.7/clients/src/main/java/org/apache/kafka/clients/NetworkClient.java
我们来看看 Sender 线程拉取元数据的大体过程。
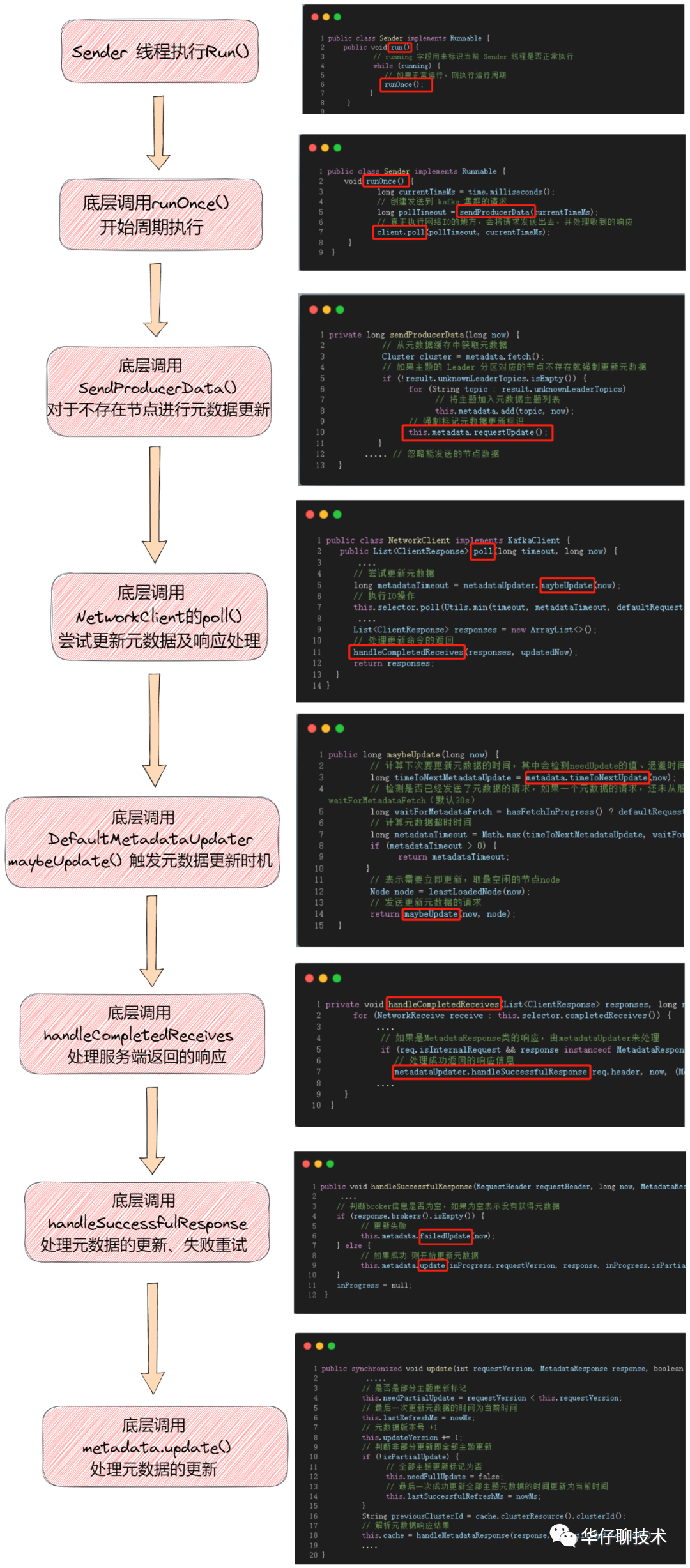
接下来我们详细分析具体的源码。
03.1 Sender 周期执行
通过源码可以得知 Sender 是一个 Runnable 对象,那整个 Sender 线程执行的核心逻辑就在 run() 方法中,run() 方法中的第一段代码就是循环调用 runOnce() 方法:
public class Sender implements Runnable {
public void run() {
// running 字段用来标识当前 Sender 线程是否正常执行
while (running) {
try {
// 如果正常运行,则执行运行周期
runOnce();
} catch (Exception e) {
log.error("Uncaught error in kafka producer I/O thread: ", e);
}
}
}
void runOnce() {
..... // 此处省略事务消息相关的处理逻辑
long currentTimeMs = time.milliseconds();
// 创建发送到 kafka 集群的请求
long pollTimeout = sendProducerData(currentTimeMs);
// 真正执行网络IO的地方,会将请求发送出去,并处理收到的响应
client.poll(pollTimeout, currentTimeMs);
}
}
上述源码中的 runOnce() 方法是 Sender 线程一个执行的周期,在这个周期中会进行一次批量的请求发送,并进行一次响应的处理。
接下来我们看里面2个涉及到元数据的重要方法:
03.1.1 sendProducerData()
private long sendProducerData(long now) {
// 从元数据缓存中获取元数据
Cluster cluster = metadata.fetch();
// 通过元数据cluster获取要发送的节点 Leader 分区信息
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
// 如果主题的 Leader 分区对应的节点不存在就强制更新元数据
if (!result.unknownLeaderTopics.isEmpty()) {
for (String topic : result.unknownLeaderTopics)
// 将主题加入元数据主题列表
this.metadata.add(topic, now);
// 强制标记元数据更新标识
this.metadata.requestUpdate();
}
..... // 忽略能发送的节点数据
}
该方法用来进行 Sender 线程创建请求的核心,这里只分析下元数据涉及的部分:
从元数据缓存中获取元数据。 通过元数据cluster获取要发送的节点 Leader 分区信息。 如果主题的 Leader 分区对应的节点不存在就强制更新元数据。
循环无 Leader 分区的主题,将主题加入元数据主题列表。 强制标记元数据更新标识。 对于无 Leader 分区的主题,可能分区正在选主中,也可能 Leader 分区所在节点 Crash,所以要强制更新元数据保证元数据一致性。
03.1.2 client.poll()
public class NetworkClient implements KafkaClient {
public List poll(long timeout, long now) {
....
// 尝试更新元数据
long metadataTimeout = metadataUpdater.maybeUpdate(now);
try {
// 执行IO操作
this.selector.poll(Utils.min(timeout, metadataTimeout, defaultRequestTimeoutMs));
} catch (IOException e) {
log.error("Unexpected error during I/O", e);
}
....
List responses = new ArrayList<>();
// 处理更新命令的返回
handleCompletedReceives(responses, updatedNow);
return responses;
}
}
该方法用来发送网络IO请求,在请求之前先执行尝试更新元数据的请求。
03.2 元数据更新触发时机
03.2.1 metadataUpdater.maybeUpdate()
public class NetworkClient implements KafkaClient {
private NetworkClient(MetadataUpdater metadataUpdater,
Metadata metadata,
Selectable selector,
String clientId,
int maxInFlightRequestsPerConnection,
long reconnectBackoffMs,
long reconnectBackoffMax,
int socketSendBuffer,
int socketReceiveBuffer,
int defaultRequestTimeoutMs,
long connectionSetupTimeoutMs,
long connectionSetupTimeoutMaxMs,
ClientDnsLookup clientDnsLookup,
Time time,
boolean discoverBrokerVersions,
ApiVersions apiVersions,
Sensor throttleTimeSensor,
LogContext logContext) {
if (metadataUpdater == null) {
// 通过这里可以看出 metadataUpdate 实例化对象
this.metadataUpdater = new DefaultMetadataUpdater(metadata);
} else {
this.metadataUpdater = metadataUpdater;
}
...
}
}
从初始化函数中可以得出元数据更新组件是调用 NetworkClient 内部类即 DefaultMetadataUpdater,前面已多次提到更新集群元数据的场景,而这些更新操作都是在标记集群元数据是否需要更新,而真正执行更新的操作是这里。接下来我们看下这个类的 maybeUpdate() 方法。
03.2.2 public maybeUpdate()
public long maybeUpdate(long now) {
// 计算下次要更新元数据的时间,其中会检测needUpdate的值、退避时间、是否长时间未更新
long timeToNextMetadataUpdate = metadata.timeToNextUpdate(now);
// 检测是否已经发送了元数据的请求,如果一个元数据的请求,还未从服务端返回,那么时间设置为 waitForMetadataFetch(默认30s)
long waitForMetadataFetch = hasFetchInProgress() ? defaultRequestTimeoutMs : 0;
// 计算元数据超时时间
long metadataTimeout = Math.max(timeToNextMetadataUpdate, waitForMetadataFetch);
if (metadataTimeout > 0) {
return metadataTimeout;
}
// 表示需要立即更新,取最空闲的节点node
Node node = leastLoadedNode(now);
// 发送更新元数据的请求
return maybeUpdate(now, node);
}
从这段源码中可以看出上来先计算下次要更新元数据的时间,我们看下这个计算过程。
public class Metadata implements Closeable {
// 计算下次更新元数据的时间
public synchronized long timeToNextUpdate(long nowMs) {
long timeToExpire = updateRequested() ? 0 : Math.max(this.lastSuccessfulRefreshMs + this.metadataExpireMs - nowMs, 0);
return Math.max(timeToExpire, timeToAllowUpdate(nowMs));
}
// 判断这2个标识是否为true
public synchronized boolean updateRequested() {
return this.needFullUpdate || this.needPartialUpdate;
}
// 计算允许更新元数据的时机
public synchronized long timeToAllowUpdate(long nowMs) {
return Math.max(this.lastRefreshMs + this.refreshBackoffMs - nowMs, 0);
}
}
元数据是否过期 timeToExpire,计算方式:
首先会通过 updateRequested() 方法检查 Metadata 中的 「needFullUpdate」「needPartialUpdate」,如果这两个标识位为 true,表示 Metadata 需要立即更新, 否则计算上次更新成功的时间距离当前时间是否已经超过了指定的元数据过期时间阈值metadataExpireMs「默认5分钟」。 允许更新的时间点 timeToAllowUpdate,计算方式:
上次更新时间 + 退避时间 - 当前时间的间隔 「要求上次更新时间与当前时间的间隔不能大于退避时间,如果大于则需要等待」。 最后计算这俩值的最大值作为下次更新元数据的时间。
分析完元数据更新时机,最后调用 maybeUpdate(now, node) 发送更新元数据的请求。
03.2.3 private maybeUpdate()
private long maybeUpdate(long now, Node node) {
String nodeConnectionId = node.idString();
// 判断当前node的状态是否可以发送Request请求
if (canSendRequest(nodeConnectionId, now)) {
// 构建元数据请求
Metadata.MetadataRequestAndVersion requestAndVersion = metadata.newMetadataRequestAndVersion(now);
MetadataRequest.Builder metadataRequest = requestAndVersion.requestBuilder;
// 向 nodeConnectionId 发送元数据请求
sendInternalMetadataRequest(metadataRequest, nodeConnectionId, now);
inProgress = new InProgressData(requestAndVersion.requestVersion, requestAndVersion.isPartialUpdate);
return defaultRequestTimeoutMs;
}
// 判断Node是否正在连接
if (isAnyNodeConnecting()) {
return reconnectBackoffMs;
}
// 如果存在可用的Node,则尝试初始化连接
if (connectionStates.canConnect(nodeConnectionId, now)) {
// 初始化与node的连接
initiateConnect(node, now);
return reconnectBackoffMs;
}
// 阻塞等待有新的节点可用
return Long.MAX_VALUE;
}
该方法用来发送更新元数据的请求,具体的实现逻辑如下:
canSendRequest() 判断当前node的状态是否可以发送Request请求, 如果可以发送则构建元数据请求,调用 sendInternalMetadataRequest() 向 nodeConnectionId 发送元数据请求。 isAnyNodeConnecting() 如果该 node 正在建立连接,则直接返回重新连接超时时间,等待更新成功。 connectionStates.canConnect() 如果存在可用的Node,则尝试初始化连接,返回重新连接超时时间,等待更新成功。 阻塞等待有新的节点可用。
从上述源码可以看出:更新流程一直在重试,直到元数据更新成功为止。
Sender 子线程第一次调用 poll() 方法时,尝试初始化与 node 的连接。 Sender 子线程第二次调用 poll() 方法时,发送 Metadata 请求。 Sender 子线程会阻塞等待一定时间,当有响应返回时则获取 metadataResponse,并更新 metadata。
如果元数据更新成功以后,KafkaProducer 主线程就不会被阻塞,当 NetworkClient 接收到服务端对 Metadata 请求的响应后,就会更新 Metadata 信息, 即 poll() 方法后续的操作。
03.2.4 handleCompletedReceives()
private void handleCompletedReceives(List responses, long now) {
for (NetworkReceive receive : this.selector.completedReceives()) {
....
// 如果是MetadataResponse类的响应,由metadataUpdater来处理
if (req.isInternalRequest && response instanceof MetadataResponse)
// 处理成功返回的响应信息
metadataUpdater.handleSuccessfulResponse(req.header, now, (MetadataResponse) response);
....
}
}
该方法用来判断成功接收服务端返回的响应,根据不同的响应返回做不同的操作,这里只看下跟元数据更新有关的逻辑。
03.2.5 handleSuccessfulResponse()
public void handleSuccessfulResponse(RequestHeader requestHeader, long now, MetadataResponse response) {
....
// Check if any topic's metadata failed to get updated
Map errors = response.errors();
// 如果返回错误,直接报错
if (!errors.isEmpty())
log.warn("Error while fetching metadata with correlation id {} : {}", requestHeader.correlationId(), errors);
// 判断broker信息是否为空,如果为空表示没有获得元数据
if (response.brokers().isEmpty()) {
// 更新失败
this.metadata.failedUpdate(now);
} else {
// 如果成功 则开始更新元数据
this.metadata.update(inProgress.requestVersion, response, inProgress.isPartialUpdate, now);
}
inProgress = null;
}
// 元数据更新失败
public synchronized void failedUpdate(long now) {
// 最后一次更新元数据的时间为当前时间
this.lastRefreshMs = now;
}
该方法用来对成功返回信息进行处理,主要是对元数据信息的更新。
查看 response 返回信息的 error。 判断broker信息是否为空
如果为空表示没有获得元数据即更新失败了,然后调用 failedUpdate(now)方法记录 lastRefreshMs 为当前时间,不允许立即更新元数据。 如果不为空表示获取元数据成功,则调用 MetaData.update() 更新元数据。
至此,Sender 子线程拉取并更新元数据分析完毕。
最后通过一张图来描述整个元数据拉取的全过程:
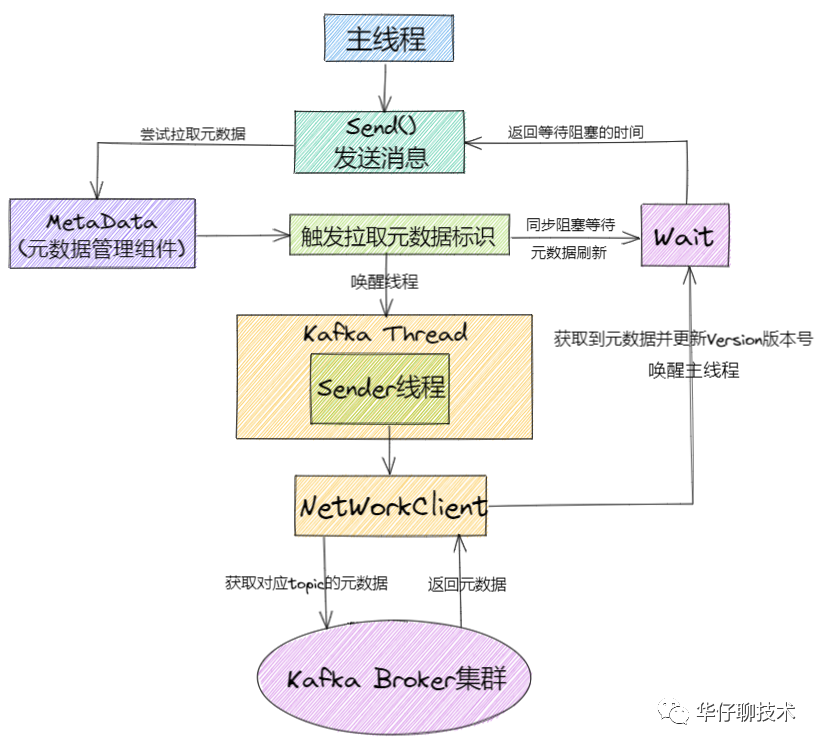
05 总结
这里,我们一起来总结一下这篇文章的重点。
1、通过「场景驱动」的方式从元数据的使用场景出发,抛出主线程加载元数据和子线程拉取元数据的过程是怎样的?
2、带你梳理了「主线程如何加载元数据源码全貌」,包括 ProducerMetadata 类、Metadata 元数据基类、cluster类的几个重要方法源码分析,最后分析主线程加载元数据过程。
3、又带你梳理了「Sender 线程拉取元数据」,包括 Sender 周期执行、元数据更新触发时机的几个重要方法源码分析。
3、最后通过一张元数据流程图来勾勒出元数据拉取和更新的全貌。
下一篇我们来深度剖析「Kafka NIO实现」,大家期待,我们下期见。
如另外欢迎加入我的技术交流群,关注本公众号并添加我个人微信,邀您进群。
如果我的文章对你有所帮助,还请帮忙点赞、在看、转发一下,非常感谢!
坚持总结, 持续输出高质量文章 关注我: 华仔聊技术
点个“赞”和“在看”鼓励一下嘛~