
HugeCTR源码简单走读
前言
这段时间除了开发算子之外,还在做一些推荐系统相关的工作,这期间主要看的是HugeCTR的代码,其性能优异,系统不复杂,代码结构较扁平,整体还是比较清晰。在这段时间看源码的过程中也算是对HugeCTR有一点了解,这篇博客主要梳理下HugeCTR代码的结构,以及他在MLPERF中做的一些优化。
仓库地址:NVIDIA-Merlin/HugeCTR
MLPERF博客:
Boosting NVIDIA MLPerf Training v1.1 Performance with Full Stack Optimization
MLPerf v1.0 Training Benchmarks: Insights into a Record-Setting NVIDIA Performance
整体结构
仓库主体结构如下,一些不重要的目录就省去了
- HugeCTR 主要的源码目录
- gpu_cache GPU 带缓存机制的Embedding实现
- onnx_converter onnx模型转换器
- samples 模型示例目录,包含如DLRM, DeepFM等常用模型
- sparse_operation_kit 稀疏操作库,可以作为一款插件搭配在其他框架上使用,如Tensorflow
我们主要还是关注 HugeCTR 这个主目录,里面分别存放了头文件(include)和对应的实现(src),我们基于头文件目录来看下结构:
HugeCTR
| - include
| - collectives 通信相关部分
| - cpu CPU版本实现全部集中放在这一目录
| - data_readers 数据加载器部分
| - embedding_training_cache Embedding训练缓存机制
| - embedding 不同类型Embedding实现部分,如混合Embedding等
| - hashtable GPU哈希表
| - embedding 不同类型Embedding实现部分,如混合Embedding等
| - hps 系统组件实现部分,包含内存池,各种数据库后端等
| - inference 推理实现
| - layers 不同神经网络层实现
| - optimizers 不同优化器实现
| - prims 我理解是提供cuda基础操作部分,如reduce,矩阵求外积等基础操作
| - pybind cpp接口导出到python部分
| - regularizer L1/2 regularizer实现
| - resource_managers 系统资源管理
| - shuffle (不知道这部分是干啥的,有了解的朋友也可以帮忙补充下)
直接硬翻源码我觉得是有点难的,我的方法是从一个模型开始,看其分别涉及到了哪些代码,下面我们就以官方的DLRM示例来看源码,并针对我比较熟悉的算子实现展开。
Python这部分接口HugeCTR走的是Keras风格,习惯PyTorch的朋友可能一时还不太习惯
CreateSolver
第一部分是构建了一个Solver,看起来是一个全局模型主体配置的东西:
solver = hugectr.CreateSolver(max_eval_batches = 51,
batchsize_eval = 1769472,
batchsize = 55296,
vvgpu = [[0,1,2,3,4,5,6,7]],
repeat_dataset = True,
lr = 24.0,
...
is_dlrm = True)
对应我们找到其pybind文件solver_wrapper.hpp,在cpp层创建了一个Solver对象,并将参数set进去:
std::unique_ptr solver(new Solver()) ;
solver->model_name = model_name;
solver->seed = seed;
solver->lr_policy = lr_policy;
solver->lr = lr;
...
DataReaderParams
这部分是配置数据读取的一些参数
reader = hugectr.DataReaderParams(data_reader_type = hugectr.DataReaderType_t.RawAsync,
source = ["./train_data.bin"],
eval_source = "./test_data.bin"
...
其作为一个结构体,具体在 DataReaderParams::DataReaderParams,并在后续的model中传入并调用
Model::Model(const Solver& solver, const DataReaderParams& reader_params,...)
CreateOptimizer
显然这部分是创建整个模型使用的优化器
optimizer = hugectr.CreateOptimizer(optimizer_type = hugectr.Optimizer_t.SGD,
update_type = hugectr.Update_t.Local,
atomic_update = True)
在optimizer_wrapper.hpp里面,对不同优化器的参数进行配置:
OptHyperParams opt_hyper_params;
// 给Adam优化器的beta1 beta2配置
opt_hyper_params.adam.beta1 = beta1;
...
// 设置Adagrad初始累加值
opt_hyper_params.adagrad.initial_accu_value = initial_accu_value;
...
opt_hyper_params.momentum.factor = momentum_factor;
opt_hyper_params.nesterov.mu = momentum_factor;
opt_hyper_params.sgd.atomic_update = atomic_update;
实例化Model
做完前置工作后,这里正式实例化一个Model主体,传入solver,reader,optimizer这三者
model = hugectr.Model(solver, reader, optimizer)
在其头文件中model.hpp描述了Model对象的一些成员,这里面包含的挺杂的,诸如:
GpuLearningRateSchedulers gpu_lr_sches_; lr_sch_; // 学习率调度器
std::vector<std::shared_ptrfloat>>> train_weight_buff_list_; // 用于训练时float32类型权重分配显存
std::vector<std::shared_ptr>> train_weight_buff_half_list_; // 用于开启混合精度时,对half类型权重分配显存
std::vector<std::string> data_input_info_; // 输入data信息,这里是字符串形式
std::map<std::string, std::vector<size_t>> tensor_shape_info_; // tensor形状信息
std::vector<std::pair<std::string, std::string>>
input_output_info_; // 每一层输入,输出信息
std::vector<std::string> layer_info_; // layer信息,有一个枚举类型维护string到实际网络层的映射关系
...
就不一一列举了。
在Model::Model里面,根据传进来的信息做一系列初始化:
// 使用多少gpu训练
for (size_t i = 0; i < resource_manager_->get_local_gpu_count(); i++) {
train_weight_buff_list_.emplace_back(blobs_buff_list_[i]->create_block<float>());
...
auto id = resource_manager_->get_local_gpu(i)->get_local_id();
// 如果开启混合精度,那么就给half版本的wgrad设置以及allreduce通信操作,并给float版本的wgrad设置float类型分配器
if (solver_.use_mixed_precision) {
wgrad_buff_half_list_.emplace_back(
(solver_.grouped_all_reduce)
? std::dynamic_pointer_cast>(exchange_wgrad_)
->get_network_wgrad_buffs()[id]
: std::dynamic_pointer_cast>(exchange_wgrad_)
->get_network_wgrad_buffs()[id]);
wgrad_buff_list_.emplace_back(blobs_buff_list_[i]->create_block<float>());
} else {
// 不开启混合精度,就给float版本的wgrad设置对应的allreduce通信操作
wgrad_buff_list_.emplace_back(...);
wgrad_buff_half_list_.emplace_back(...); // placeholder
}
}
...
// initialize optimizer
init_optimizer(opt_params_, solver_, opt_params_py);
init_learning_rate_scheduler(lr_sch_, solver_, gpu_lr_sches_, resource_manager_);
构建Input,SparseEmbedding
model.add(hugectr.Input(label_dim = 1, label_name = "label",
dense_dim = 13, dense_name = "dense",
...))
model.add(hugectr.SparseEmbedding(embedding_type = hugectr.Embedding_t.HybridSparseEmbedding,
workspace_size_per_gpu_in_mb = 15000,
...)))
这里调用model的add方法添加输入层和Embedding层,我们先看下add方法,在对应的pybind绑定中model_wrapper.hpp对应四种重载:
// 1. 输入层
.def("add", pybind11::overload_cast(&HugeCTR::Model::add), pybind11::arg("input"))
// 2. Embedding层
.def("add", pybind11::overload_cast(&HugeCTR::Model::add),
pybind11::arg("sparse_embedding"))
// 3. 全连接层
.def("add", pybind11::overload_cast(&HugeCTR::Model::add),
pybind11::arg("dense_layer"))
// 4. 多层全连接层
.def("add", pybind11::overload_cast(&HugeCTR::Model::add),
pybind11::arg("group_dense_layer"))
Input和SparseEmbedding重载实现对应在model.cpp内,这里就不再展开了。
增加全连接层
DLRM主体计算部分是由两部分bottom_mlp和top_mlp组成的,因此模型后续代码就是在构建这部分:
model.add(hugectr.GroupDenseLayer(group_layer_type = hugectr.GroupLayer_t.GroupFusedInnerProduct,
bottom_name_list = ["dense"],
top_name_list = ["fc1", "fc2", "fc3"],
num_outputs = [512, 256, 128],
last_act_type = hugectr.Activation_t.Relu))
model.add(hugectr.DenseLayer(bottom_names = ["fc3","sparse_embedding1"],
top_names = ["interaction1", "interaction1_grad"]...))
model.add(hugectr.GroupDenseLayer(...))
model.add(hugectr.DenseLayer(...))
bottom_name_list和top_name_list来表示输入Tensor列表,输出Tensor列表,这样后续层可以根据这个名字来实现网络层相连。num_outputs表示的是全连接层输出维度大小last_act_type表示最后一层全连接层的激活层类型,这里是ReLU
下面我们以全连接层来看一下一个网络层的具体实现,首先看一下基类Layer的头文件layer.hpp
...
// 前向计算逻辑
virtual void fprop(bool is_train) = 0;
// 反向计算逻辑
virtual void bprop() = 0;
virtual std::string get_no_trained_params_in_string() { return std::string(); }
void init_params(const curandGenerator_t& generator);
Layer(const std::shared_ptr& gpu_resource,
std::vector initializer_types = std::vector())
: gpu_resource_(gpu_resource), initializer_types_(initializer_types) {}
Layer(const Layer&) = delete;
Layer& operator=(const Layer&) = delete;
virtual ~Layer() = default;
// 参数初始化
virtual void initialize() {}
// 算法搜索,比如全连接层,HugeCTR会通过试跑选择一个最快的算法
virtual void search_algorithm() {}
我们以fused_relu_bias_fully_connected_layer.cu为具体例子:
构造函数
在构造函数中,根据tensor的形状信息得到m,n,k,并推算出kernel,bias tensor的形状等:
size_t m = bottom_tensor_dim[0];
size_t n = top_tensor_dim[1];
size_t k = bottom_tensor_dim[1];
std::vector<size_t> kernel_dim = {k, n};
std::vector<size_t> bias_dim = {1, n};
std::vector<size_t> identity_dim = {1, m};
接着对这些tensor分配显存:
{
Tensor2<float> tensor;
master_weights_buff->reserve(kernel_dim, &tensor);
weights_.push_back(tensor);
}
{
Tensor2<float> tensor;
master_weights_buff->reserve(bias_dim, &tensor);
weights_.push_back(tensor);
}
...
initialize
这个Fuse矩阵乘是通过cublasLt实现的,因此在这个函数里做了一些cublasLt所需要的初始化,如矩阵信息,设置计算类型,设置epilogue(指定cublasLt的fuse模式)
HCTR_LIB_THROW(cublasLtMatmulDescSetAttribute(cublas_op_desc_, CUBLASLT_MATMUL_DESC_TRANSA,
&trans, sizeof(trans)));
HCTR_LIB_THROW(cublasLtMatmulDescSetAttribute(cublas_op_desc_, CUBLASLT_MATMUL_DESC_TRANSB,
&trans, sizeof(trans)));
...
cublasLtEpilogue_t epi = CUBLASLT_EPILOGUE_RELU_AUX_BIAS; // 设置epilogue
...
// 创建kernel, bias, output的矩阵维度,数据类型
HCTR_LIB_THROW(cublasLtMatrixLayoutCreate(&cublas_kernel_desc_, CUDA_R_16F, n, k, n));
HCTR_LIB_THROW(cublasLtMatrixLayoutCreate(&cublas_bottom_desc_, CUDA_R_16F, k, m, k));
HCTR_LIB_THROW(cublasLtMatrixLayoutCreate(&cublas_top_desc_, CUDA_R_16F, n, m, n));
...
initialize_dgrad() 和 initialize_wgrad() 则是给矩阵乘后向对应的2次矩阵乘分别做上述类似初始化,这里不再赘述
fprop
调用cublasLtMatmul进行前向计算:
const __half* kernel = weights_half_[0].get_ptr();
const __half* bias = weights_half_[1].get_ptr();
const __half* bottom = get_bottom_tensor_fprop(is_train).get_ptr();
...
HCTR_LIB_THROW(cublasLtMatmul(...));
bprop也是类似的逻辑
search_algorithm
HugeCTR设定了一个最大算法个数,通过cublasLtMatmulAlgoGetHeuristic启发式搜索算法接口获取当前全连接层可用的算法,并使用cudaEvent进行计时,选取表现最好的算法:
// 获取当前可用算法
cublasLtMatmulHeuristicResult_t heuristic_result[max_algo_count] = {0};
int algo_count = 0;
HCTR_LIB_THROW(cublasLtMatmulAlgoGetHeuristic(...));
// 遍历所有算法
for (int algoIdx = 0; algoIdx < algo_count; algoIdx++) {
cublasStatus_t status = CUBLAS_STATUS_SUCCESS;
const float alpha = 1.0f;
const float beta = 0.0f;
HCTR_LIB_THROW(cudaEventRecord(start, get_gpu().get_stream()));
// 执行repeat_num次矩阵乘
for (size_t i = 0; i < repeat_num && status == CUBLAS_STATUS_SUCCESS; ++i) {
status = cublasLtMatmul(...);
}
// 记录时间
HCTR_LIB_THROW(cudaEventRecord(stop, get_gpu().get_stream()));
HCTR_LIB_THROW(cudaEventSynchronize(stop));
HCTR_LIB_THROW(cudaEventElapsedTime(&time, start, stop));
// Avg Time(ms) for this alorithm for fprop GEMM
time = time / repeat_num;
...
// 更新最佳时间
if (time < shortestTime) {
shortestTime = time;
// 把当前最佳的算法拷贝到falgo_k,在计算过程中使用falgo_k
memcpy(&falgo_k_, &heuristic_result[algoIdx].algo, sizeof(falgo_k_));
}
}
这也是为什么在nsys前半部分,能看到一堆密密麻麻的矩阵乘
模型搭建完以后,后续调用compile, fit执行训练,这部分也可以在model.cpp看到对应实现,这里就不展开了,下面我们讲下HugeCTR在MLPERF提及到的一些优化
MLPERF1.0
Hybrid Embedding
频繁的Embedding交换是模型训练过程中的一个重要瓶颈,对此HugeCTR实现了HybridEmbedding。输入中会存在重复id,因此一开始会剔除掉重复的数据,对应反向传播也做相应处理。此外它还针对数据做了统计,根据频率分为高频Embedding,低频Embedding。高频Embedding以数据并行实现,这样能够在一个batch内删掉更多重复的数据,减少Embedding交换,而低频Embedding以模型并行实现。
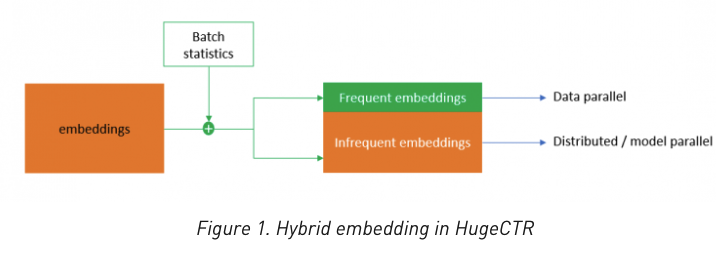
通信优化
笔者不太了解通信方面的知识
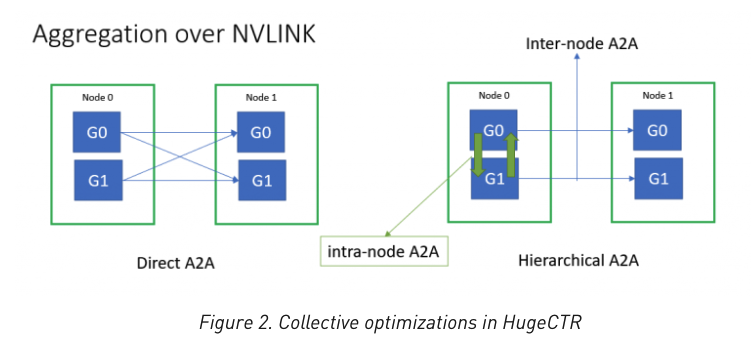 all2all和allreduce耗时在拓展模型过程中是很重要的一环,对于比较小的message,多节点的all2all吞吐量受限于IB的消息速率的限制,为此将All2All分为节点内All2All,节点间All2All。并将高频Embedding和MLP的AllReduce放在一个AllReduce操作内完成,以减少延迟。
all2all和allreduce耗时在拓展模型过程中是很重要的一环,对于比较小的message,多节点的all2all吞吐量受限于IB的消息速率的限制,为此将All2All分为节点内All2All,节点间All2All。并将高频Embedding和MLP的AllReduce放在一个AllReduce操作内完成,以减少延迟。
数据读取优化
采用Linux的异步方式读取,以达到IO峰值
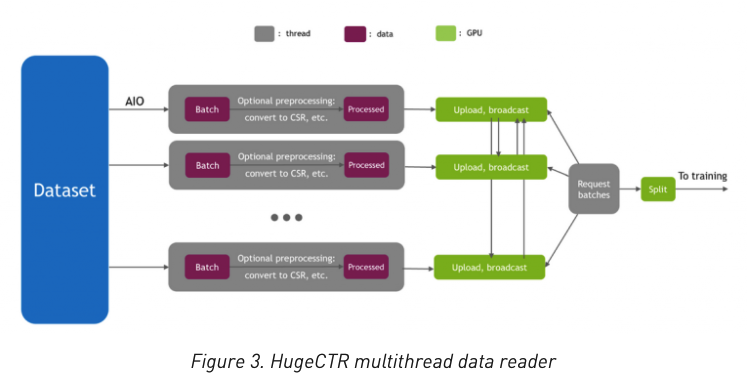
重叠MLP和Embedding
在DLRM中,bottom_mlp部分和Embedding之间不存在依赖,因此做了如下的流水线重叠:
BottomMLP前向过程和Embedding前向进行重叠 高频Embedding在更新local权重时和AllReduce重叠 MLP权重更新和节点内All2All重叠
cublasLt算子融合
cublasLt可以通过epilogue来选择不同算子融合方式,比如 matmul+bias, matmul+bias+relu,以及对应的后向矩阵乘等
CUDA Graph
为了减少kernel launch开销,将模型的所有操作都包到一个 CUDA Graph 内。
关于CUDA Graph可以参考 https://zhuanlan.zhihu.com/p/467466998
MLPERF1.1
Hybrid Embedding索引预计算
在之前的Hybrid Embedding中需要计算索引来决定在哪儿读取对应的Embedding,而索引计算只依赖于输入数据,这些数据可以在提前几个iter时候预取好(Prefetch),预先计算好Index,以隐藏延迟
通信与计算之间更好的重叠
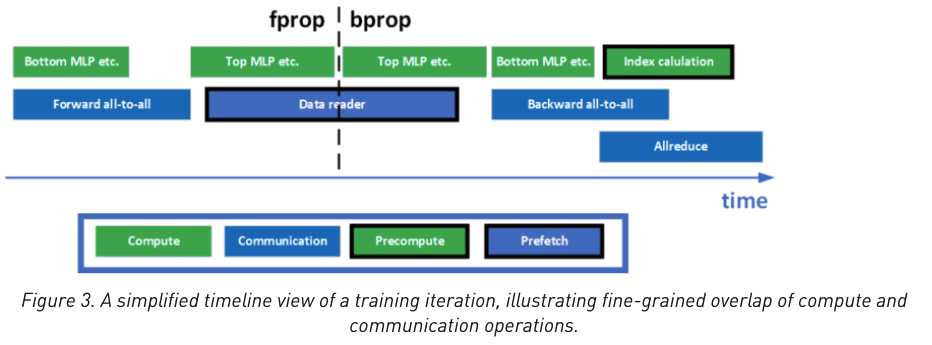
这里就不过多阐述了,这里的图描述的十分详细
异步梯度计算
在矩阵乘中,其反向对应有2个矩阵乘,而这两个矩阵乘接受相同的输入dy,分别输出weight,input的梯度。因此这两个计算可以重叠起来,具体在代码中FusedReluBiasFullyConnectedLayer::bprop()
// dgrad
HCTR_LIB_THROW(cublasLtMatmul(..., get_gpu().get_stream()));
// bgrad+wgrad
HCTR_LIB_THROW(cublasLtMatmul(..., get_gpu().get_comp_overlap_stream()));
在nsys中,是这样:

Better Fusion
其中一个是CublasLt提供了更多的fuse方式,另外一个是在混合精度情况下,将fp32权重cast成fp16的部分,放到Optimizer更新时候做,这样就避免单独启动Cast Kernel,在SGD优化器代码中可以看到对应的操作sgd_optimizer.cu
template <typename T>
__device__ inline void sgd_update_device(int len, float* weight, __half* weight_half,
const T* wgrad, float lr, float scaler) {
...
weight[i] -= lr * gi;
weight_half[i] = (__half)weight[i];
}