
「ClickHouse系列」ClickHouse的优化之Block+LSM


第一部分:
Block + LSM
其实本部分的标题也可以换成批处理+预排序。clickhouse通过block的设计来实现批处理,通过lsm算法来实现预排序。我们分别来分析一下,这个组合对查询速度的影响。
首先,我们分析有序存储和无序存储对查询速度的影响。我们一般在做查询时,大致可以分为按值查询和按范围查询两种。

两种查询对的磁盘访问
从表中可以看出,在都使用了索引的情况下,如果是按值查询那么有序存储和无序存储基本都能做到一次磁盘IO就能实现数据读取。但按范围读取,因为是有序存储,因此只需要一次对磁盘的访问即可读取所有数据。而对于无序存储的数据来说,最坏的情况可能需要读取n次磁盘。
还是以一个小例子来做下说明:
SELECT avg(price) FROM orders where age between 20 and 30;
计算订单中年龄在20到30岁用户的平均订单金额。假设数仓内有1亿条记录,每条数据约1k,其中20-30岁之间的用户订单大约有10%。
在数据按照age有序存储的情况下,读取的数据量为1亿*10%*1KB≈10G。
若数据未按照age有序存储,这种情况下,读取的数据量为1亿*10%4K(1-27.1%)≈29.2G。两者相差接近3倍。
由此可见,整体上来说,有序的数据在查询时更占优势。因此,clickhouse在设计时使用了写入前预排序,以保证查询时能获得更快的速度。不过这也必然带来了数据写入的延时,因此clickhouse不适合用在写多读少的场景。
说完了预排序,再来说下批处理对性能的影响。clickhouse能处理的最小单位是block,block就是一群行的集合,默认最大8192行组成一个block。
其实做了预排序后再做批处理很好理解,毕竟存储到clickhouse中的数据都是有序的,而clickhouse设计出来是为了处理上百亿条记录的大数据数仓,因此一般的范围查询返回的数据量都非常大,如果每次处理1行数据的话,就会大大增加磁盘IO次的次数。当然,到目前为止,只是增加了IO次数,并没有减少数据量,因此到此时,按照block读取的优化好像显得没有必要,毕竟一次IO的时间和读取数据的时间相比,基本可以忽略不计。读者们不用着急,真正block的省时的点就在下一段。
block真正发挥威力的点其实是在压缩!对,没错,就是毫不起眼的压缩!那么压缩能节省多少数据量呢?我们还是拿clickhouse存储引擎中实际存储的数据说话。以clickhouse官方提供的hits_v1库为例,我挑选了其中的UserID列为例,使用clickhouse提供的compressor工具读取该列的数据文件,可以看到这个文件中每一个block的压缩前和压缩后的大小。
我大致看了一下,压缩率最大的一个block压缩前是130272字节,压缩后只有639字节,压缩率高达203倍!当然,这是特例,那我们统计下整个文件的block的压缩前和压缩后的大小,还是这个列为例,UserID列压缩前是70991184字节,压缩后是11596909字节,压缩比约为6.2倍!
能达到这么高压缩比,其实是列存的功劳,对于列存数据库,由于每一列单独存储,因此每个数据文件相比行存数据库来说更有规律,因此可以达到非常高的压缩率。
到这里,批处理的威力就出来了,通过压缩,再次降低了6倍的文件大小,也就是说再次减少6倍的磁盘IO时间。
这里就是clickhouse最重要的存储引擎上的优化,通过批处理+预排序,相比较于无此功能的列式数据库来说,减少了范围查询量在10%左右时大约18倍的磁盘读取时间。而若在百亿数据库中,查询量1%左右时能节省24倍的磁盘读取时间。
当然,任何架构都有两面性,在节省磁盘读取时间的情况下,也带来了如下缺点:
适合数据的大批量写入,如果写入频繁,会影响写入性能 如果范围查询的数据量大,那么性能提升会低。因此数据量太小时无法发挥最大优势。 由于按照block作为最小处理单位,因此删除单条数据性能不高。 修改的性能很差,尤其是修改了用于排序的列。因此不适合做事务型数据库。
附
可能有读者会问,为什么无序存储要乘以4K。这个原因是因为操作系统在读取磁盘时,依据数据局部性原理,会按照页为单位读取,每页的大小默认是4k。在unistd.h头文件中的getpagesize()可以获取本机的页面大小,这里按照默认大小进行计算。
式子中的27.1%是指的缓存命中率,命中率由需要查询的数据占所有数据的百分比r决定。在本例中按照4k的页面大小和1k的记录大小,命中率和数据占比之间的关系如下图所示:
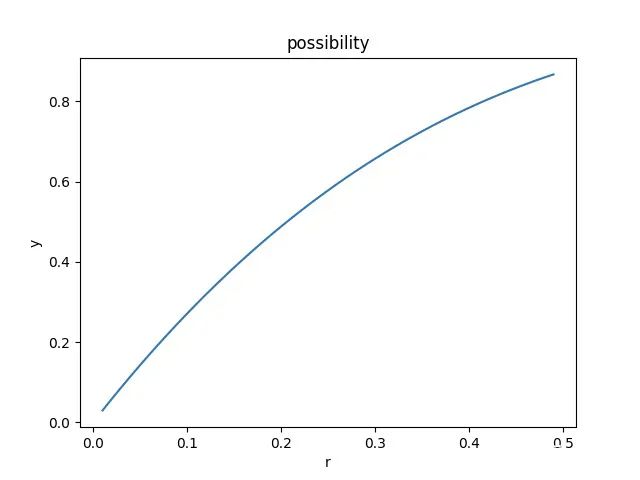
不难发现,两者成负相关的相关性。
第二部分:
LSM算法最早出现在1991年的ACM期刊上,之后其思想在各大大数据存储系统中被广泛使用,例如LevelDB,HBase,Cassandra……LSM算法由于适应的场景不同,存在很多的变体,clickhouse也使用lsm算来实现其预排序的功能,本部分将着重介绍clickhouse中的使用,同时也会适当涉及一些其他系统的使用用以让读者体会架构设计的随心所欲。
我们都知道,用户在调用insert向clickhouse插入数据时,数据不一定是按已经按照排序键排序好的数据,大概率是乱序数据。那么这种乱序的请求如何做到写入磁盘时变得有序呢?这个就是LSM算法实现的。
LSM算法的几个核心步骤:
在于数据写入存储系统前首先记录日志,防止系统崩溃 记录完日志后在内存中以供使用,当内存达到极限后写入磁盘,记录合并次数Level为0(L=0)。已经写入磁盘的文件不可变。 每过一段时间将磁盘上L和L+1的文件合并
我们用一个示例来展示下整个过程
T=0时刻,数据库为空。
T=1时刻,clickhouse收到一条500条insert的插入请求,这500条数据时乱序的。此时,clickhouse开始插入操作。首先将500条插入请求一次性写入日志。接着在内存中进行排序,排序完成后将有序的结果写入磁盘,此时L=0;
T=2时刻,clickhouse收到一条800条insert的插入请求,这800条数据时乱序的。此时,clickhouse开始插入操作。首先将800条插入请求一次性写入日志。接着在内存中进行排序,排序完成后将有序的结果写入磁盘,此时L=0;
T=3时刻,clickhouse开始合并,此时此刻,磁盘上存在两个L=0的文件。这两个文件每个文件内部有序,但可能存在重合。(例如第一批500条的范围是300-400,第二批800条数据的范围是350-700)。因此需要合并。clickhouse在后台完成合并后,产生了一个新的L=1的文件。将两个L=0的文件标记为删除。
T=4时刻,clickhouse开始清理,将两个被标记为删除的文件真正地物理删除。
T=5时刻,clickhouse收到一条100条insert的插入请求,这100条数据时乱序的。此时,clickhouse开始插入操作。首先将100条插入请求一次性写入日志。接着在内存中进行排序,排序完成后将有序的结果写入磁盘,此时L=0;
T=6时刻,clickhouse开始合并,此时此刻,磁盘上存在1个L=0的文件和1个L=1的文件。这两个文件每个文件内部有序,但不存在重合。(例如L0文件的范围是100-200,L1文件的范围是300-700)。因此不需要合并。clickhouse在后台将L=0的文件升级成L=1,此时数据库内存在两个L=1的互不重合的文件。
……
以上就是LSM算法在clickhouse上的应用,我们总结一下,clickhouse使用LSM算法将乱序的数据在内存中排序为有序的数据,然后写入磁盘保存,并且定期合并有重合的磁盘文件。
不难发现,上述所有的过程对于磁盘的来说都是顺序写,因此这个也是LSM算法的一个特点——可以将大量的随机写入转换为顺序写入从而减少磁盘IO时间。leveldb就借助了lsm的这个特性。当然,clickhouse并没有使用到这个特性。下面会将简单介绍下leveldb是如何使用LSM的。
clickhouse借助LSM实现了预排序的功能,提高了磁盘的利用率,但也同时带来了一些牺牲。再次强调,没有完美的架构,当架构解决一个问题的同时,一定会带来一个全新的问题。
对于clickhouse也一样,读者们已经知道了,clickhouse会在多次insert请求时创建独立的数据文件。虽然clickhouse会在合适时间进行合并,但如果查询发生在合并前,就有可能数据分布在两个数据文件内。此时clickhouse默认会返回两个列表,这两个列表内部有序,但相互之间却会有重合。这就给用户使用带来了不便,下图展示了这种情况。
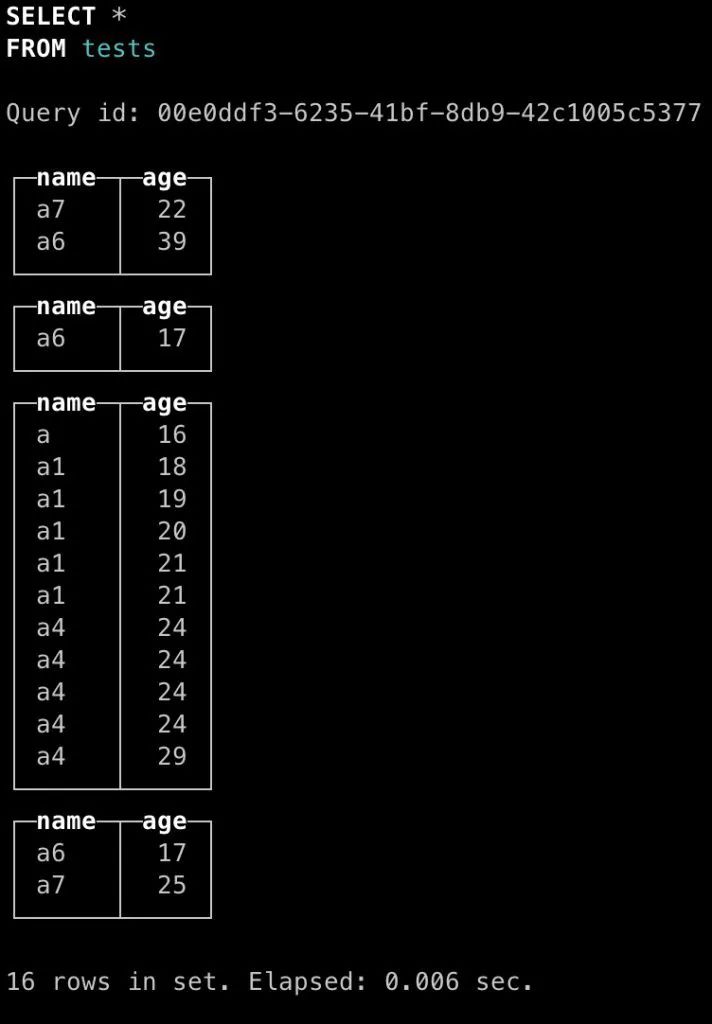
可以看出,此时clickhouse未合并时查询结果分成了4个独立的结果,每个结果内部有序,但相互之间存在重合,也就说对于这种情况需要用户自行合并。我们等待其合并后再次查询,结果如下:
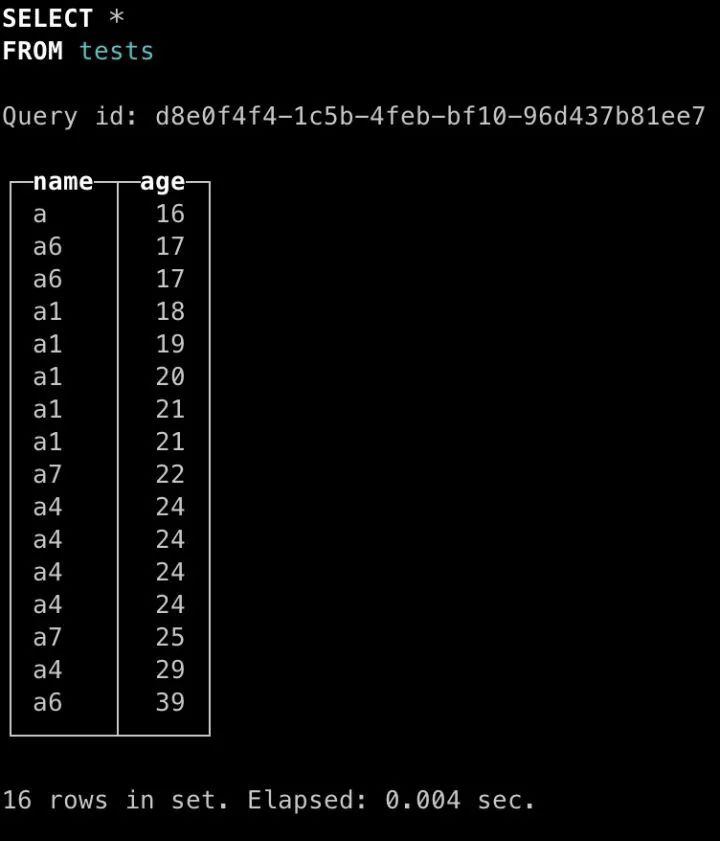
clickhouse合并后就能解决该问题。
LevelDB的用法
leveldb是一个允许修改的数据库,因此其对于LSM的使用和clickhouse类似,主要的不同在于写入日志后的操作不同。
clickhouse在记录日志后,会直接在内存中进行排序,从而写入磁盘。此时如果clickhouse又接到一条写入情况,会重新开启一个新的进程。
而leveldb在记录日志后,会将数据首先缓存在内存中,等待后续操作继续操作这块内存,直到这块内存被填满,才会一次性将数据写入磁盘。
这个差异主要时两个数据库面向的场景不同,clickhouse主要面向读多写少的分析场景,强调大批量一次性写入增加吞吐量。而leveldb主要面向写多读少的业务场景,强调低延时。
吞吐量和延时一向是互相对立的两个指标,不同系统都在这两个指标之间存在取舍。后续有机会我也会写一篇关于这两个指标之间的相爱相杀,以及知名开源软件在这两个指标之间的思考。
其他
扯回来,正因为面向的场景不同,clickhouse和leveldb对LSM的使用存在着不同。这也给了我们一个启发,作为架构师,我们要做到运用之妙存乎一心。要能够了解我们正在设计的业务的需求是什么,然后进行符合需求的修改。而不是无脑地认为LSM一定是用在写多读少的场景。
做到这一点会有点难,但幸好我们可以站在前人肩膀上,多体会一下前人设计的精妙绝伦的架构。有了这样的经验和思考,我们在遇到相同问题的时候就能做到更深的思考。
这也是我写这个系列的原因,clickhouse真的是工程师设计的典范之作,整个clickhouse没有发明新的科学理论,但却让我们看到了借助已有的理论也能将性能在某一方面发挥到极致,这种追求极致的工程师精神让我深深着迷,我觉得我需要将这种精妙的设计思想的传递给大家。希望有朝一日,我们中国的工程师也能将极致的产品带给世界。因为有你,因为有我,许许多多平凡而伟大的工程师的共同努力,这一天一定能够到来。向clickhouse的研发团队致敬。
