
轻量化日志Loki全攻略,再也不会整懵了
点击关注公众号,Java干货及时送达👇

文章来源:https://c1n.cn/0wHvF
前言
简介
架构说明
部署
使用
前言
简介
Loki 是 Grafana Labs 团队最新的开源项目,是一个水平可扩展,高可用性,多租户的日志聚合系统。
它的设计非常经济高效且易于操作,因为它不会为日志内容编制索引,而是为每个日志流编制一组标签,专门为 Prometheus 和 Kubernetes 用户做了相关优化。
该项目受 Prometheus 启发,官方的介绍就是:Like Prometheus,But For Logs。类似于 Prometheus 的日志系统。
https://github.com/grafana/loki/
不对日志进行全文索引。通过存储压缩非结构化日志和仅索引元数据,Loki 操作起来会更简单,更省成本。
通过使用与 Prometheus 相同的标签记录流对日志进行索引和分组,这使得日志的扩展和操作效率更高,能对接 alertmanager。
特别适合储存 Kubernetes Pod 日志;诸如 Pod 标签之类的元数据会被自动删除和编入索引。
受 Grafana 原生支持,避免 kibana 和 grafana 来回切换。
架构说明
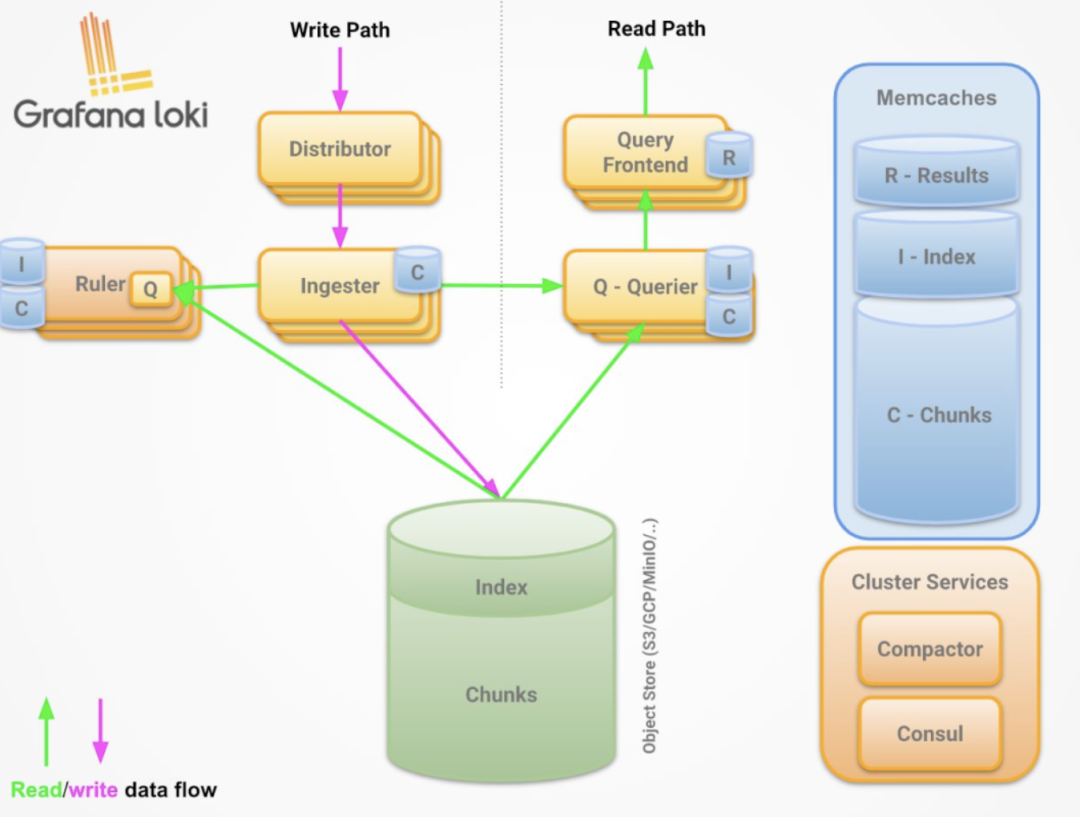
| 组件说明
说明如下:
Promtail 作为采集器,类比 filebeat
Loki 相当于服务端,类比 es
querier 查询器
inester 日志存储器
query-frontend 前置查询器
distributor 写入分发器
| read path
查询器接受 HTTP/1 数据请求
查询器将查询传递给所有 ingesters 请求内存中的数据
接收器接受读取的请求,并返回与查询匹配的数据(如果有)
如果没有接受者返回数据,则查询器会从后备存储中延迟加载数据并对其执行查询
查询器将迭代所有接收到的数据并进行重复数据删除,从而通过 HTTP/1 连接返回最终数据集
| write path

分发服务器收到一个 HTTP/1 请求,以存储流数据
每个流都使用散列环散列
分发程序将每个流发送到适当的 inester 和其副本(基于配置的复制因子)
每个实例将为流的数据创建一个块或将其追加到现有块中,, 每个租户和每个标签集的块都是唯一的
分发服务器通过 HTTP/1 链接以成功代码作为响应
部署
| 本地化模式安装
下载 Promtail 和 Loki:
wget https://github.com/grafana/loki/releases/download/v2.2.1/loki-linux-amd64.zip
wget https://github.com/grafana/loki/releases/download/v2.2.1/promtail-linux-amd64.zip
安装 Promtail:
$ mkdir /opt/app/{promtail,loki} -pv
# promtail配置文件
$ cat < /opt/app/promtail/promtail.yaml
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /var/log/positions.yaml # This location needs to be writeable by promtail.
client:
url: http://localhost:3100/loki/api/v1/push
scrape_configs:
- job_name: system
pipeline_stages:
static_configs:
- targets:
- localhost
labels:
job: varlogs
host: yourhost
__path__: /var/log/*.log
EOF
# 解压安装包
unzip promtail-linux-amd64.zip
mv promtail-linux-amd64 /opt/app/promtail/promtail
# service文件
$ cat </etc/systemd/system/promtail.service
[Unit]
Description=promtail server
Wants=network-online.target
After=network-online.target
[Service]
ExecStart=/opt/app/promtail/promtail -config.file=/opt/app/promtail/promtail.yaml
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=promtail
[Install]
WantedBy=default.target
EOF
systemctl daemon-reload
systemctl restart promtail
systemctl status promtail
安装 Loki:
$ mkdir /opt/app/{promtail,loki} -pv
# promtail配置文件
$ cat < /opt/app/loki/loki.yaml
auth_enabled: false
server:
http_listen_port: 3100
grpc_listen_port: 9096
ingester:
wal:
enabled: true
dir: /opt/app/loki/wal
lifecycler:
address: 127.0.0.1
ring:
kvstore:
store: inmemory
replication_factor: 1
final_sleep: 0s
chunk_idle_period: 1h # Any chunk not receiving new logs in this time will be flushed
max_chunk_age: 1h # All chunks will be flushed when they hit this age, default is 1h
chunk_target_size: 1048576 # Loki will attempt to build chunks up to 1.5MB, flushing first if chunk_idle_period or max_chunk_age is reached first
chunk_retain_period: 30s # Must be greater than index read cache TTL if using an index cache (Default index read cache TTL is 5m)
max_transfer_retries: 0 # Chunk transfers disabled
schema_config:
configs:
- from: 2020-10-24
store: boltdb-shipper
object_store: filesystem
schema: v11
index:
prefix: index_
period: 24h
storage_config:
boltdb_shipper:
active_index_directory: /opt/app/loki/boltdb-shipper-active
cache_location: /opt/app/loki/boltdb-shipper-cache
cache_ttl: 24h # Can be increased for faster performance over longer query periods, uses more disk space
shared_store: filesystem
filesystem:
directory: /opt/app/loki/chunks
compactor:
working_directory: /opt/app/loki/boltdb-shipper-compactor
shared_store: filesystem
limits_config:
reject_old_samples: true
reject_old_samples_max_age: 168h
chunk_store_config:
max_look_back_period: 0s
table_manager:
retention_deletes_enabled: false
retention_period: 0s
ruler:
storage:
type: local
local:
directory: /opt/app/loki/rules
rule_path: /opt/app/loki/rules-temp
alertmanager_url: http://localhost:9093
ring:
kvstore:
store: inmemory
enable_api: true
EOF
# 解压包
unzip loki-linux-amd64.zip
mv loki-linux-amd64 /opt/app/loki/loki
# service文件
$ cat </etc/systemd/system/loki.service
[Unit]
Description=loki server
Wants=network-online.target
After=network-online.target
[Service]
ExecStart=/opt/app/loki/loki -config.file=/opt/app/loki/loki.yaml
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=loki
[Install]
WantedBy=default.target
EOF
systemctl daemon-reload
systemctl restart loki
systemctl status loki
使用
| grafana 上配置 loki 数据源
如下图:
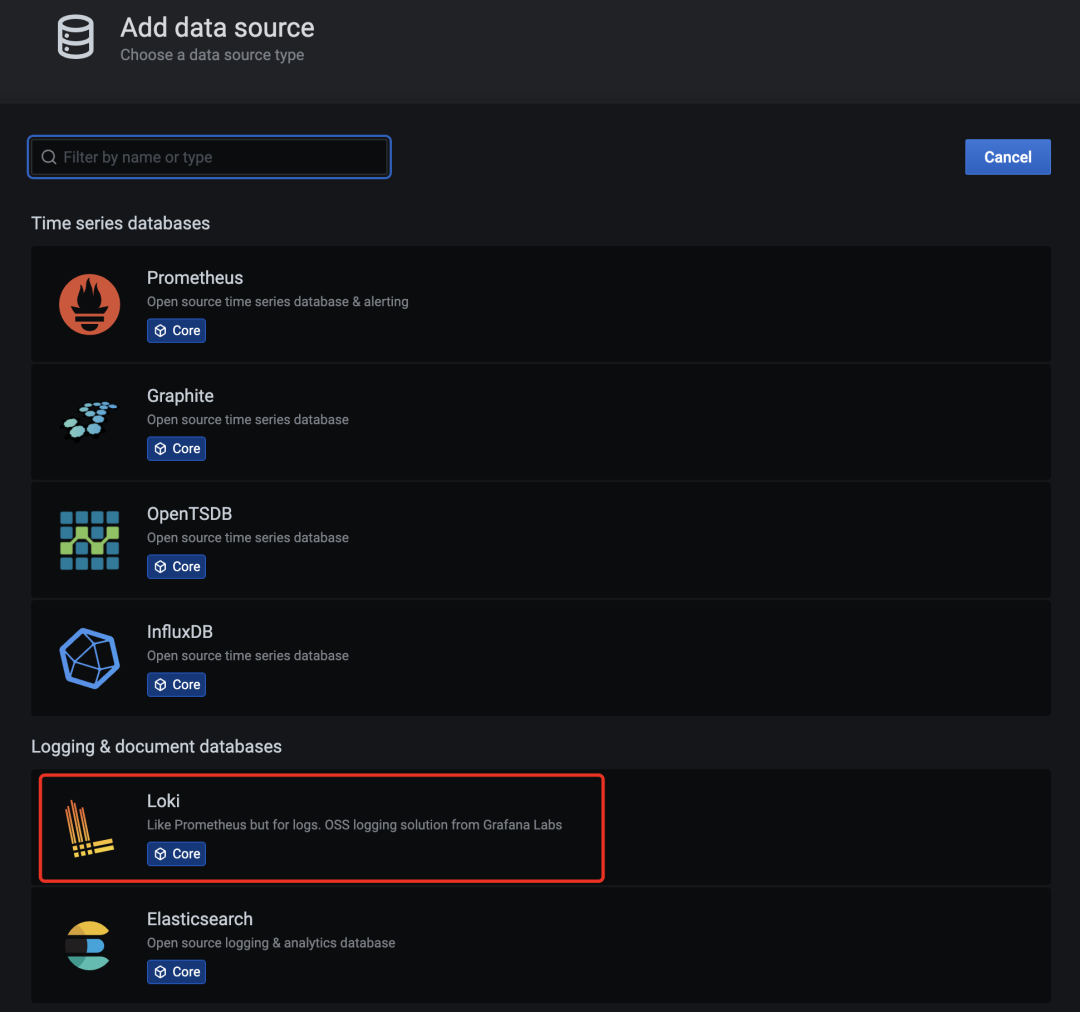
grafana-loki-dashsource
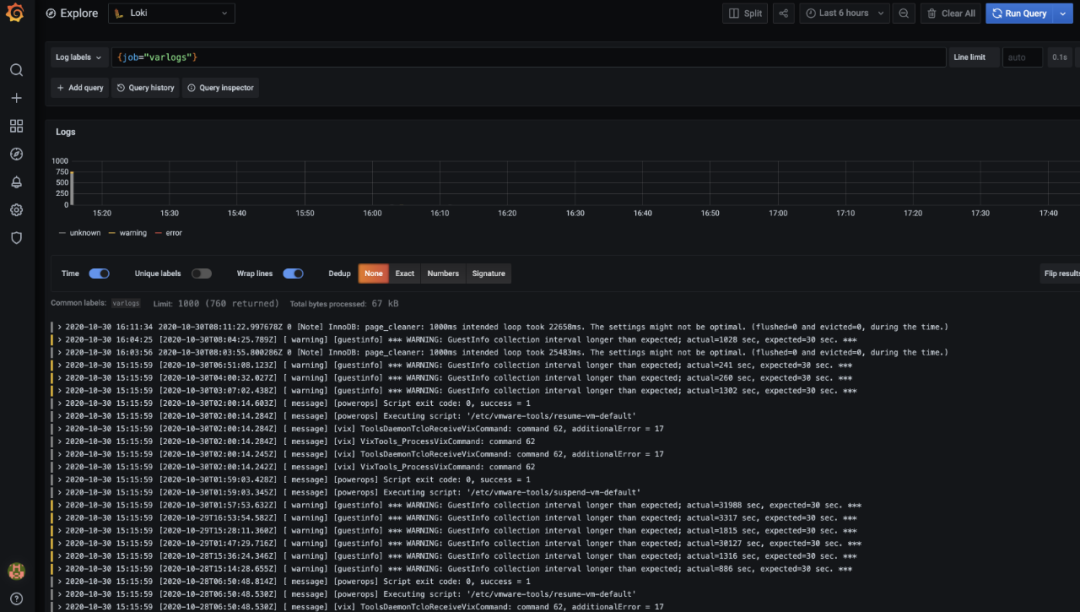
保存完成后,切换到 grafana 左侧区域的 Explore,即可进入到 Loki 的页面:
然后我们点击 Log labels 就可以把当前系统采集的日志标签给显示出来,可以根据这些标签进行日志的过滤查询:
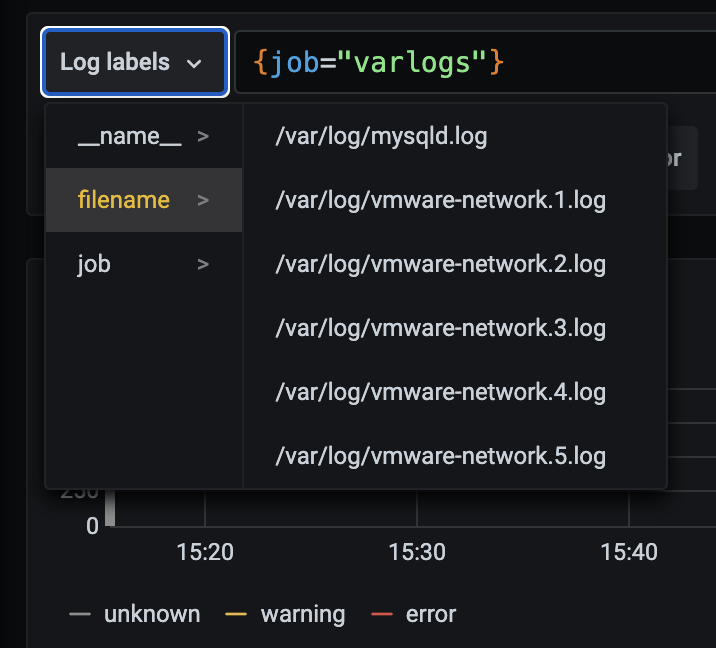
比如我们这里选择 /var/log/messages,就会把该文件下面的日志过滤展示出来,不过由于时区的问题,可能还需要设置下时间才可以看到数据:
promtail 容器 /etc/promtail/config.yml:
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml
clients:
- url: http://loki:3100/loki/api/v1/push
scrape_configs:
- job_name: system
static_configs:
- targets:
- localhost
labels:
job: varlogs
__path__: /var/log/*log
这里的 job 就是 varlog,文件路径就是 /var/log/*log。
| 在 grafana explore 上配置查看日志
查看日志 rate({job="message"} |="kubelet"
算 qps rate({job=”message”} |=”kubelet” [1m])
| 只索引标签
之前多次提到 loki 和 es 最大的不同是 loki 只对标签进行索引而不对内容索引。下面我们举例来看下。
静态标签匹配模式
scrape_configs:
- job_name: system
pipeline_stages:
static_configs:
- targets:
- localhost
labels:
job: message
__path__: /var/log/messages
配置解读:
上面这段配置代表启动一个日志采集任务
这个任务有 1 个固定标签 job=”syslog”
采集日志路径为 /var/log/messages,会以一个名为 filename 的固定标签
在 promtail 的 web 页面上可以看到类似 prometheus 的 target 信息页面
可以和使用 Prometheus 一样的标签匹配语句进行查询。
scrape_configs:
- job_name: system
pipeline_stages:
static_configs:
- targets:
- localhost
labels:
job: syslog
__path__: /var/log/syslog
- job_name: system
pipeline_stages:
static_configs:
- targets:
- localhost
labels:
job: apache
__path__: /var/log/apache.log
| 标签匹配模式的特点
原理如下:
和 prometheus 一致,相同标签对应的是一个流 prometheus 处理 series 的模式
prometheus 中标签一致对应的同一个 hash 值和 refid(正整数递增的 id),也就是同一个 series
时序数据不断的 append 追加到这个 memseries 中
当有任意标签发生变化时会产生新的 hash 值和 refid,对应新的 series
查询过程:
所以 loki 先根据标签算出 hash 值在倒排索引中找到对应的 chunk?
然后再根据查询语句中的关键词等进行过滤,这样能大大的提速
因为这种根据标签算哈希在倒排中查找 id,对应找到存储的块在 prometheus 中已经被验证过了
属于开销低
速度快
| 动态标签和高基数
何为动态标签:说白了就是标签的 value 不固定
何为高基数标签:说白了就是标签的 value 可能性太多了,达到 10 万,100 万甚至更多
比如 apache 的 access 日志:
11.11.11.11 - frank [25/Jan/2000:14:00:01 -0500] "GET /1986.js HTTP/1.1" 200 932 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; de; rv:1.9.1.7) Gecko/20091221 Firefox/3.5.7 GTB6"
scrape_configs:
- job_name: system
pipeline_stages:
static_configs:
- targets:
- localhost
labels:
job: syslog
__path__: /var/log/syslog
- job_name: system
pipeline_stages:
static_configs:
- targets:
- localhost
labels:
job: apache
__path__: /var/log/apache.log
- job_name: system
pipeline_stages:
- regex:
expression: "^(?P<ip>\\S+) (?P<identd>\\S+) (?P<user>\\S+) \\[(?P<timestamp>[\\w:/]+\\s[+\\-]\\d{4})\\] \"(?P<action>\\S+)\\s?(?P<path>\\S+)?\\s?(?P<protocol>\\S+)?\" (?P<status_code>\\d{3}|-) (?P<size>\\d+|-)\\s?\"?(?P<referer>[^\"]*)\"?\\s?\"?(?P<useragent>[^\"]*)?\"?$"
- labels:
action:
status_code:
static_configs:
- targets:
- localhost
labels:
job: apache
env: dev
__path__: /var/log/apache.log
那么对应 action=get/post 和 status_code=200/400 则对应 4 个流:
11.11.11.11 - frank [25/Jan/2000:14:00:01 -0500] "GET /1986.js HTTP/1.1" 200 932 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; de; rv:1.9.1.7) Gecko/20091221 Firefox/3.5.7 GTB6"
11.11.11.12 - frank [25/Jan/2000:14:00:02 -0500] "POST /1986.js HTTP/1.1" 200 932 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; de; rv:1.9.1.7) Gecko/20091221 Firefox/3.5.7 GTB6"
11.11.11.13 - frank [25/Jan/2000:14:00:03 -0500] "GET /1986.js HTTP/1.1" 400 932 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; de; rv:1.9.1.7) Gecko/20091221 Firefox/3.5.7 GTB6"
11.11.11.14 - frank [25/Jan/2000:14:00:04 -0500] "POST /1986.js HTTP/1.1" 400 932 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; de; rv:1.9.1.7) Gecko/20091221 Firefox/3.5.7 GTB6"
高基数问题:就像上面,如果给 ip 设置一个标签,现在想象一下,如果您为设置了标签 ip,来自用户的每个不同的 ip 请求不仅成为唯一的流。可以快速生成成千上万的流,这是高基数,这可以杀死 Loki。
| 全文索引问题
加速查询没标签字段:以上边提到的 ip 字段为例 - 使用过滤器表达式查询。
{job="apache"} |= "11.11.11.11"
loki 查询时的分片(按时间范围分段 grep):
Loki 将把查询分解成较小的分片,并为与标签匹配的流打开每个区块,并开始寻找该 IP 地址。
这些分片的大小和并行化的数量是可配置的,并取决于您提供的资源
如果需要,您可以将分片间隔配置为 5m,部署 20 个查询器,并在几秒钟内处理千兆字节的日志
或者,您可以发疯并设置 200 个查询器并处理 TB 的日志!
两种索引模式对比:
es 的大索引,不管你查不查询,他都必须时刻存在。比如长时间占用过多的内存
loki 的逻辑是查询时再启动多个分段并行查询
日志量少时少加标签:
因为每多加载一个 chunk 就有额外的开销
举例,如果该查询是 {app=”loki”,level!=”debug”}
在没加 level 标签的情况下只需加载一个 chunk 即 app=“loki” 的标签
如果加了 level 的情况,则需要把 level=info,warn,error,critical 5 个 chunk 都加载再查询
需要标签时再去添加:
当 chunk_target_size=1MB 时代表 以 1MB 的压缩大小来切割块
对应的原始日志大小在 5MB-10MB,如果日志在 max_chunk_age 时间内能达到 10MB,考虑添加标签
日志应当按时间递增:
这个问题和 tsdb 中处理旧数据是一样的道理
目前 loki 为了性能考虑直接拒绝掉旧数据
最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
获取方式:点“在看”,关注公众号并回复 Java 领取,更多内容陆续奉上。
PS:因公众号平台更改了推送规则,如果不想错过内容,记得读完点一下“在看”,加个“星标”,这样每次新文章推送才会第一时间出现在你的订阅列表里。
点“在看”支持小哈呀,谢谢啦😀
