
Excel公式太复杂?我花一晚上用Python做了个格式化工具
来源:凹凸数据
作者简介:
小小明,熟悉python、java、scala,了解go、c/c++。10年左右编码经验,逻辑思维能力良好,做过windows应用程序开发和大数据开发与运维,会大数据、web全栈开发、自动化办公、pandas数据处理,了解区块链开发、机器学习、 VBA、爬虫。

大概就是很多跟数据打交道的人都需要面对过很复杂的excel,嵌套层数特别多,肉眼观看很容易蒙圈。有了这样的需求,小小明就有了解决问题的想法,说干就干于是一个比较牛逼的excel公式格式化的工具出现了。
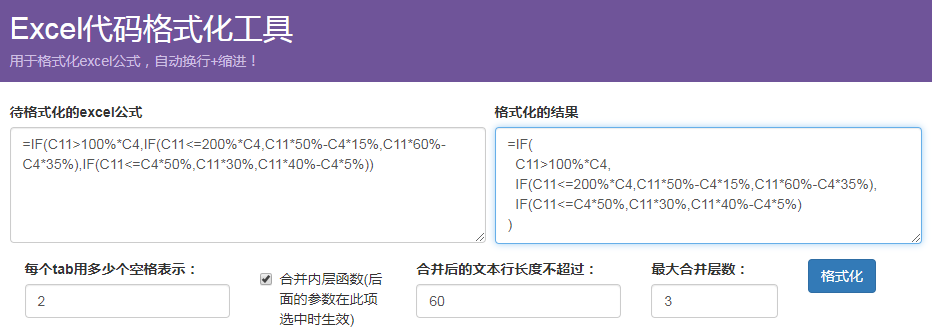
1、效果体验
先看看效果吧:
=IF(C11>100%*C4,IF(C11<=200%*C4,C11*50%-C4*15%,C11*60%-C4*35%),IF(C11<=C4*50%,C11*30%,C11*40%-C4*5%))
的格式化结果是:
=IF(
C11>100%*C4,
IF(
C11<=200%*C4,
C11*50%-C4*15%,
C11*60%-C4*35%
),
IF(
C11<=C4*50%,
C11*30%,
C11*40%-C4*5%
)
)
(SMA(MAX(CLOSE-DELAY(CLOSE,1),0),12,1)/SMA(ABS(CLOSE-DELAY(CLOSE,1)),12,1)*100-MIN(SMA(MAX(CLOSE-DELAY(
CLOSE,1),0),12,1)/SMA(ABS(CLOSE-DELAY(CLOSE,1)),12,1)*100,12))/(MAX(SMA(MAX(CLOSE-DELAY(CLOSE,1),0),12,
1)/SMA(ABS(CLOSE-DELAY(CLOSE,1)),12,1)*100,12)-MIN(SMA(MAX(CLOSE-DELAY(CLOSE,1),0),12,1)/SMA(ABS(
CLOSE-DELAY(CLOSE,1)),12,1)*100,12))
的格式化结果为:
(
SMA(MAX(CLOSE-DELAY(CLOSE,1),0),12,1)
/
SMA(ABS(CLOSE-DELAY(CLOSE,1)),12,1)
*
100-MIN(
SMA(MAX(CLOSE-DELAY(CLOSE,1),0),12,1)
/
SMA(ABS(CLOSE-DELAY(CLOSE,1)),12,1)*100,
12
)
)
/
(
MAX(
SMA(MAX(CLOSE-DELAY(CLOSE,1),0),12,1)
/
SMA(ABS(CLOSE-DELAY(CLOSE,1)),12,1)*100,
12
)
-
MIN(
SMA(MAX(CLOSE-DELAY(CLOSE,1),0),12,1)
/
SMA(ABS(CLOSE-DELAY(CLOSE,1)),12,1)*100,
12
)
)

=IF(ROW()>COLUMN(),"",IF(ROW()=COLUMN(),$B15,ROUNDDOWN($B15*INDIRECT(SUBSTITUTE(ADDRESS(1,3+COLUMN()-ROW(),
4),1,"")&56),0)))
的格式化结果为:
=IF(
ROW()>COLUMN(),
"",
IF(
ROW()=COLUMN(),
$B15,
ROUNDDOWN(
$B15*INDIRECT(
SUBSTITUTE(ADDRESS(1,3+COLUMN()-ROW(), 4),1,"")
&
56
),
0
)
)
)

如果你已经心动了,可以进入下滑到文末,点击阅读原文!直接使用体验!但本人不保证服务器一直会续费,网址能够永久使用。
不过接下来,将公布这套格式化程序的完整代码和开发思想,有技术能力的小伙伴可以考虑改进该代码。
2、完整代码
__author__ = 'xiaoxiaoming'
from collections import deque
import re
class Node:
def __init__(self, parent=None, tab_size=0):
self.parent = parent
self.tab_size = tab_size
self.data = []
def is_single_node(self):
for e in self.data:
if not isinstance(e, str):
return False
return True
def get_single_text(self):
return "".join(self.data)
def split_text_blocks(excel_func_text):
"""
将excel公式字符串,按照一定的规则切割成数组
:param excel_func_text: 被切割的excel公式字符串
:return: 切割后的结果
"""
excel_func_text = excel_func_text.replace('\n', '').replace('\r', '')
excel_func_text = re.sub(" +", " ", excel_func_text)
lines = []
i, j = 0, 0
while j < len(excel_func_text):
c = excel_func_text[j]
if (c == '(' and excel_func_text[j + 1] != ')') or c == ',':
lines.append(excel_func_text[i:j + 1])
i = j = j + 1
elif c == ')' and excel_func_text[j - 1] != '(':
if i < j:
lines.append(excel_func_text[i:j])
i = j # 起始文件块置于)处
# 以下代码查找,如果中间不包含(或),则将)和,之间的文本块加入到划分结果
k = excel_func_text.find(",", j + 1)
l = excel_func_text.find("(", j + 1, k)
m = excel_func_text.find(")", j + 1, k)
if k != -1 and l == -1 and m == -1:
lines.append(excel_func_text[i:k + 1])
i = j = k + 1
elif j + 1 < len(excel_func_text) and excel_func_text[j + 1] != ')':
lines.append(")")
lines.append(excel_func_text[j + 1])
i = j = j + 2
else:
lines.append(")")
i = j = j + 1
elif c == '"':
j = excel_func_text.find('"', j + 1) + 1
else:
j += 1
return lines
blank_char_count = 2
def combine_node(root, text_max_length=60, max_combine_layer=3):
"""
合并最内层的只有纯文本子节点的节点为单个文本节点
:param root: 被合并的节点
:param text_max_length: 合并后的文本长度不超过该参数,则应用该合并替换原节点
:param max_combine_layer: 最大合并层数
:return:
"""
for _ in range(max_combine_layer):
no_change = True
stack = deque([root])
while stack:
node = stack.pop()
tmp = {}
for i, e in enumerate(node.data):
if isinstance(e, Node):
if e.is_single_node():
single_text = e.get_single_text()
if len(single_text) < text_max_length:
tmp[i] = single_text
else:
stack.append(e)
for i, e in tmp.items():
node.data[i] = e
if len(tmp) != 0:
no_change = False
if no_change:
break
def node_next_line(node):
for i, e in enumerate(node.data):
if isinstance(e, str):
if i == 0 or i == len(node.data) - 1:
tab = node.tab_size - 1
else:
tab = node.tab_size
yield f"{' ' * blank_char_count * tab}{e}"
else:
yield from node_next_line(e)
def excel_func_format(excel_func_text, blank_count=2, combine_single_node=True, text_max_length=60,
max_combine_layer=3):
"""
将excel公式格式化成比较容易阅读的格式
:param excel_func_text: 被格式化的excel公式字符串
:param blank_count: 最终显示的格式化字符串的1个tab用几个空格表示
:param combine_single_node: 是否合并纯文本节点,该参数设置为True后面的参数才生效
:param text_max_length: 合并后的文本长度不超过该参数,则应用该合并替换原节点
:param max_combine_layer: 最大合并层数
:return: 格式化后的字符串
"""
global blank_char_count
blank_char_count = blank_count
blocks = split_text_blocks(excel_func_text)
# print("\n".join(blocks))
# print('-----------拆分结果-----------')
tab_size = 0
node = root = Node()
for block in blocks:
if block.endswith("("):
tab_size += 1
child_node = Node(node, tab_size)
node.data.append(child_node)
node = child_node
node.data.append(block)
elif block.startswith(")"):
tab_size -= 1
node.data.append(block)
node = node.parent
else:
node.data.append(block)
if combine_single_node:
combine_node(root, text_max_length, max_combine_layer)
result = [line for line in node_next_line(root)]
return "\n".join(result)
3、处理流程浅析
下面都以如下公式作为示例:
=IF(ROW()>COLUMN(),"",IF(ROW()=COLUMN(),$B15,ROUNDDOWN($B15*INDIRECT(SUBSTITUTE(ADDRESS(1,3+COLUMN()-ROW(),
4),1,"")&56),0)))
文本分块切分
def split_text_blocks(excel_func_text):
"""
将excel公式字符串,按照一定的规则切割成数组
:param excel_func_text: 被切割的excel公式字符串
:return: 切割后的结果
"""
excel_func_text = excel_func_text.replace('\n', '').replace('\r', '')
excel_func_text = re.sub(" +", " ", excel_func_text)
lines = []
i, j = 0, 0
while j < len(excel_func_text):
c = excel_func_text[j]
if (c == '(' and excel_func_text[j + 1] != ')') or c == ',':
lines.append(excel_func_text[i:j + 1])
i = j = j + 1
elif c == ')' and excel_func_text[j - 1] != '(':
if i < j:
lines.append(excel_func_text[i:j])
i = j # 起始文件块置于)处
# 以下代码查找,如果中间不包含(或),则将)和,之间的文本块加入到划分结果
k = excel_func_text.find(",", j + 1)
l = excel_func_text.find("(", j + 1, k)
m = excel_func_text.find(")", j + 1, k)
if k != -1 and l == -1 and m == -1:
lines.append(excel_func_text[i:k + 1])
i = j = k + 1
elif j + 1 < len(excel_func_text) and excel_func_text[j + 1] != ')':
lines.append(")")
lines.append(excel_func_text[j + 1])
i = j = j + 2
else:
lines.append(")")
i = j = j + 1
elif c == '"':
j = excel_func_text.find('"', j + 1) + 1
else:
j += 1
return lines
s = """=IF(ROW()>COLUMN(),"",IF(ROW()=COLUMN(),$B15,ROUNDDOWN($B15*INDIRECT(SUBSTITUTE(ADDRESS(1,3+COLUMN()-ROW(),
4),1,"")&56),0))) """
blocks = split_text_blocks(s)
for block in blocks:
print(block)
的运行结果为:
=IF(
ROW()>COLUMN(),
"",
IF(
ROW()=COLUMN(),
$B15,
ROUNDDOWN(
$B15*INDIRECT(
SUBSTITUTE(
ADDRESS(
1,
3+COLUMN()-ROW(),
4
),
1,
""
)
&
56
),
0
)
)
)
这端代码首先替换掉所有的换行符,将多个空格替换为单个空格,然后将左右括号和逗号作为切分点进行切分。
但存在一些特殊情况,例如ROW()和COLUMN()括号内部没有任何内容,所有这种括号应该作为普通字符处理,另外被""包含的字符串可能包含括号,也应该作为普通字符。
构建多叉树层次结构
设计数据结构:
class Node:
def __init__(self, parent=None, tab_size=0):
self.parent = parent
self.tab_size = tab_size
self.data = []
parent存储父节点的指针,tab_size存储当前节点的层级,data存储当前节点的所有数据。
构建代码:
tab_size = 0
node = root = Node()
for block in blocks:
if block.endswith("("):
tab_size += 1
child_node = Node(node, tab_size)
node.data.append(child_node)
node = child_node
node.data.append(block)
elif block.startswith(")"):
tab_size -= 1
node.data.append(block)
node = node.parent
else:
node.data.append(block)
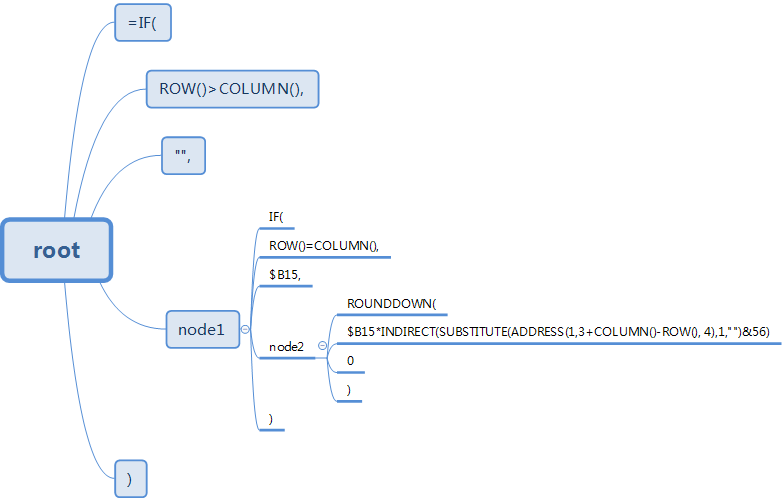
构建完毕后,这段数据在内存中的结构(仅展示data)如下:
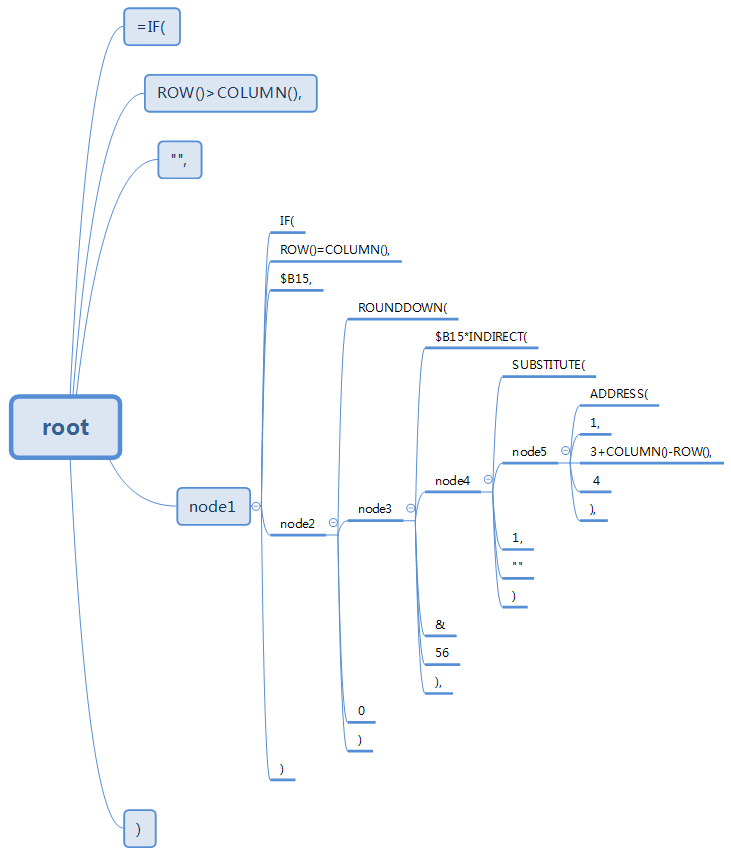
遍历打印这颗多叉树
def node_next_line(node):
for i, e in enumerate(node.data):
if isinstance(e, str):
if i == 0 or i == len(node.data) - 1:
tab = node.tab_size - 1
else:
tab = node.tab_size
yield f"{' ' * 2 * tab}{e}"
else:
yield from node_next_line(e)
result = [line for line in node_next_line(root)]
print("\n".join(result))
结果:
=IF(
ROW()>COLUMN(),
"",
IF(
ROW()=COLUMN(),
$B15,
ROUNDDOWN(
$B15*INDIRECT(
SUBSTITUTE(
ADDRESS(
1,
3+COLUMN()-ROW(),
4
),
1,
""
)
&
56
),
0
)
)
)
合并最内层的节点
显然将最内层的node5节点合并一下阅读性更好:
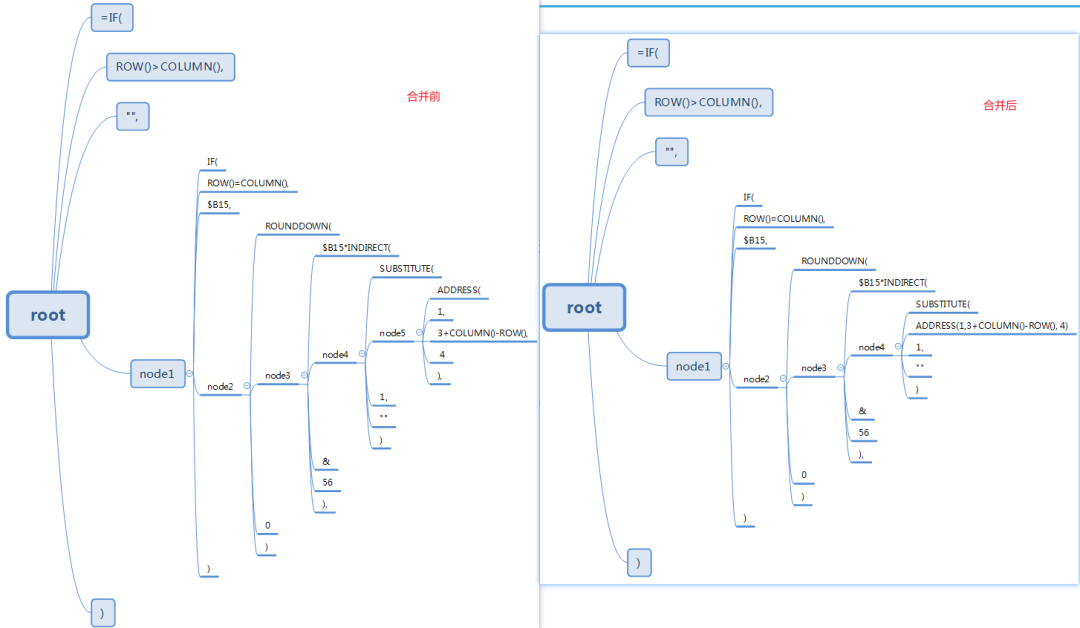
首先给数据结构增加判断是否为纯文本节点的方法:
class Node:
def __init__(self, parent=None, tab_size=0):
self.parent = parent
self.tab_size = tab_size
self.data = []
def is_single_node(self):
for e in self.data:
if not isinstance(e, str):
return False
return True
def get_single_text(self):
return "".join(self.data)
下面是合并纯文本节点的实现,max_combine_layer决定了合并的最大次数,如果合并后长度超过text_max_length参数,则不应用这次合并:
from collections import deque
def combine_node(root, text_max_length=60, max_combine_layer=3):
"""
合并最内层的只有纯文本子节点的节点为单个文本节点
:param root: 被合并的节点
:param text_max_length: 合并后的文本长度不超过该参数,则应用该合并替换原节点
:param max_combine_layer: 最大合并层数
:return:
"""
for _ in range(max_combine_layer):
no_change = True
stack = deque([root])
while stack:
node = stack.pop()
tmp = {}
for i, e in enumerate(node.data):
if isinstance(e, Node):
if e.is_single_node():
single_text = e.get_single_text()
if len(single_text) < text_max_length:
tmp[i] = single_text
else:
stack.append(e)
for i, e in tmp.items():
node.data[i] = e
if len(tmp) != 0:
no_change = False
if no_change:
break
合并一次:
combine_node(root, 100, 1)
result = [line for line in node_next_line(root)]
print("\n".join(result))
结果:
=IF(
ROW()>COLUMN(),
"",
IF(
ROW()=COLUMN(),
$B15,
ROUNDDOWN(
$B15*INDIRECT(
SUBSTITUTE(
ADDRESS(1,3+COLUMN()-ROW(), 4),
1,
""
)
&
56
),
0
)
)
)
合并二次:
combine_node(root, 100, 2)
result = [line for line in node_next_line(root)]
print("\n".join(result))
结果:
=IF(
ROW()>COLUMN(),
"",
IF(
ROW()=COLUMN(),
$B15,
ROUNDDOWN(
$B15*INDIRECT(
SUBSTITUTE(ADDRESS(1,3+COLUMN()-ROW(), 4),1,"")
&
56
),
0
)
)
)
合并三次:
combine_node(root, 100, 3)
result = [line for line in node_next_line(root)]
print("\n".join(result))
结果:
=IF(
ROW()>COLUMN(),
"",
IF(
ROW()=COLUMN(),
$B15,
ROUNDDOWN(
$B15*INDIRECT(SUBSTITUTE(ADDRESS(1,3+COLUMN()-ROW(), 4),1,"")&56),
0
)
)
)
合并三次后的内存情况:
http://xiaoxiaoming.xyz:8088/excel恋习Python 关注恋习Python,Python都好练 好文章,我在看❤️