
TMDB电影数据分析报告
TMDB电影数据分析报告
前言
数据分析的基本流程:
提出问题 理解数据 数据清洗 构建模型 数据可视化 形成报告
一、提出问题
本次报告的主要任务是:根据历史电影数据,分析哪种电影收益能力更好,未来电影的流行趋势,以及为电影拍摄提供建议。细化为以下几个小问题:
电影风格随时间变化的趋势;1. 不同风格电影的收益能力;1. 不同风格电影的受欢迎程度1. 不同风格电影的评分比较;1. 原创电影与改编电影对比;1. 影响票房收入的因素;1. 比较行业内两家巨头公司Universal Pictures和Paramount Pictures.
二、理解数据
从Kaggle平台上下载原始数据集:tmdb_5000_movies和tmdb_5000_credits,前者为电影基本信息,包含20个变量,后者为演职员信息,包含4个变量。导入数据集后,通过对数据的查看,并结合要分析的问题,筛选出以下9个要重点分析的变量:
|序号|变量名|说明 |------ |1|budget|电影预算(单位:美元) |2|genres|电影风格 |3|keywords|电影关键字 |4|popularity|受欢迎程度 |5|production_companies|制作公司 |6|release_year|上映时间 |7|revenue|票房收入(单位:美元) |8|vote_average|平均评分 |9|vote_count|评分次数
三、数据清洗
针对本数据集,数据清洗主要包括三个步骤:1.数据预处理 2.特征提取 3.特征选择
数据预处理:(1)通过查看数据集信息,发现’runtime’列有一条缺失数据,‘release_date’列有一条缺失数据,‘homepage’有30条缺失数据,只对‘release’列和‘runtime’列进行缺失值填补。具体操作方法是:通过索引的方式找到具体是哪一部电影,然后上网搜索准确的数据,将其填补。(详见后续代码) (2)对‘release_date’列进行格式转化,并从中抽取出“年份”信息。1. 特征提取:(1)credits数据集中cast,crew这两列都是json格式,需要将演员、导演分别从这两列中提取出来;movies数据集中的genres,keywords,production_companies都是json格式,需要将其转化为字符串格式。(2)处理过程:通过json.loads先将json格式转换为字典列表"[{},{},{}]"的形式,再遍历每个字典,取出键(key)为‘name’所对应的值(value),并将这些值(value)用“,”分隔,形成一个“多选题”的结构。在进行具体问题分析的时候,再将“多选题”编码为虚拟变量,即所有多选题的每一个不重复的选项,拿出来作为新变量,每一条观测包含该选项则填1,否则填0。1. 特征选择:在分析每一个小问题之前,都要通过特征提取,选择最适合分析的变量,即在分析每一个小问题时,都要先构造一个数据框,放入要分析的变量,而不是在原数据框中乱涂乱画。
四、数据可视化
本次数据分析只是对数据集进行了基本的描述性分析和相关性分析,构建模型步骤均与特征选取、新建数据框一起完成,本案例不属于机器学习范畴,因此不涉及构建模型问题。本次数据可视化用到的图形有:折线图、柱状图、直方图、饼图、散点图、词云图。(详见后续代码)
五、形成数据分析报告











代码部分:
导入包,并读取数据集:
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('darkgrid')
from pandas import DataFrame, Series
import json
from wordcloud import WordCloud, STOPWORDS
plt.rcParams['font.sans-serif'] = ['SimHei']
#读取数据集:电影信息、演员信息
movies = pd.read_csv('tmdb_5000_movies.csv',encoding = 'utf_8')
credits = pd.read_csv('tmdb_5000_credits.csv',encoding = 'utf_8')
处理json数据格式,将两张表合并为一张表,并删除不需要的字段:
#将json数据转换为字符串
#credits:json数据解析
json_cols = ['cast', 'crew']
for i in json_cols:
credits[i] = credits[i].apply(json.loads)
#提取演员
def get_names(x):
return ','.join([i['name'] for i in x])
credits['cast'] = credits['cast'].apply(get_names)
credits.head()
#提取导演
def get_directors(x):
for i in x:
if i['job'] == 'Director':
return i['name']
credits['crew'] = credits['crew'].apply(get_directors)
#将字段‘crew’改为‘director’
credits.rename(columns={'crew':'director'}, inplace = True)
#movies:json数据解析
json_cols = ['genres', 'keywords', 'spoken_languages', 'production_companies', 'production_countries']
for i in json_cols:
movies[i] = movies[i].apply(json.loads)
def get_names(x):
return ','.join([i['name'] for i in x])
movies['genres'] = movies['genres'].apply(get_names)
movies['keywords'] = movies['keywords'].apply(get_names)
movies['spoken_languages'] = movies['spoken_languages'].apply(get_names)
movies['production_countries'] = movies['production_countries'].apply(get_names)
movies['production_companies'] = movies['production_companies'].apply(get_names)
#合并数据
#credits, movies两个表中都有字段id, title,检查两个字段是否相同
(movies['title'] == credits['title']).describe()
#删除重复字段
del movies['title']
#合并两张表,参数代表合并方式
df = credits.merge(right = movies, how = 'inner', left_on = 'movie_id', right_on = 'id')
#删除分析不需要的字段
del df['overview']
del df['original_title']
del df['id']
del df['homepage']
del df['spoken_languages']
del df['tagline']
填补缺失值,并抽取“年份”信息:
#填补缺失值
#首先查找出缺失值记录
df[df.release_date.isnull()]
#然后在网上查询到该电影的发行年份,进行填补
df['release_date'] = df['release_date'].fillna('2014-06-01')
#电影时长也和上面的处理一样
df.loc[2656] = df.loc[2656].fillna(94)
df.loc[4140] = df.loc[2656].fillna(81)
#转换日期格式,只保留年份信息
df['release_year'] = pd.to_datetime(df.release_date, format = '%Y-%m-%d').dt.year
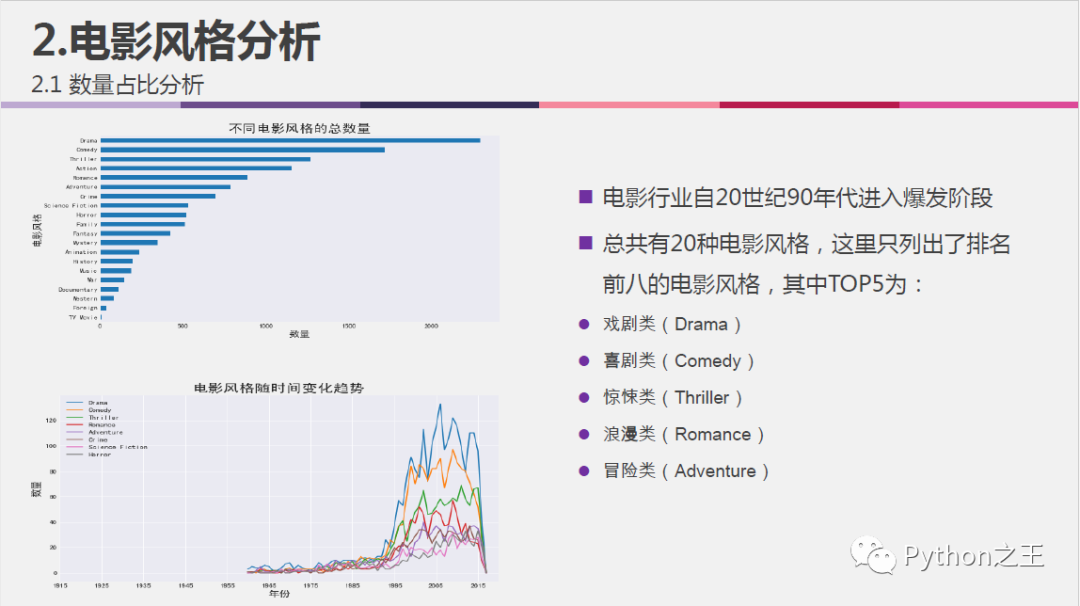
不同电影风格的数量占比分析,以及随时间变化的趋势:
#获取电影类型信息
genre = set()
for i in df['genres'].str.split(','):
genre = set().union(i,genre)
#转化为列表
genre = list(genre)
#移除列表中无用的字段
genre.remove('')
#对电影类型进行one-hot编码
for genr in genre:
df[genr] = df['genres'].str.contains(genr).apply(lambda x: 1 if x else 0)
df_gy = df.loc[:, genre]
df_gy.index = df['release_year']
#各种电影类型的总数量
df_gysum = df_gy.sum().sort_values(ascending = True)
df_gysum.plot.barh(label='genre', figsize=(10,6))
plt.xlabel('数量',fontsize=15)
plt.ylabel('电影风格',fontsize=15)
plt.title('不同电影风格的总数量',fontsize=20)
plt.grid(False)
#电影类型随时间变化的趋势
df_gy1 = df_gy.sort_index(ascending = False)
df_gys = df_gy1.groupby('release_year').sum()
df_sub_gys = df_gys[[ 'Drama', 'Comedy', 'Thriller', 'Romance',
'Adventure', 'Crime', 'Science Fiction', 'Horror']].loc[1960:,:]
plt.figure(figsize=(10,6))
plt.plot(df_sub_gys, label = df_sub_gys.columns)
plt.legend(df_sub_gys)
plt.xticks(range(1915,2018,10))
plt.xlabel('年份', fontsize=15)
plt.ylabel('数量', fontsize=15)
plt.title('电影风格随时间变化趋势', fontsize=20)
plt.show()
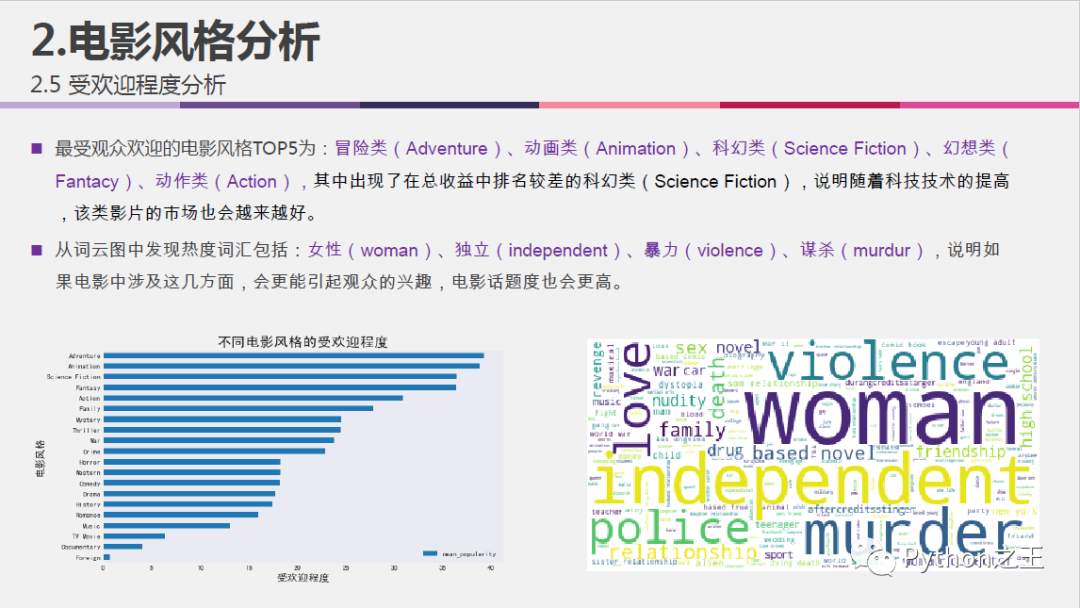
不同电影风格的受欢迎程度分析:
#定义一个数据框,以电影类型为索引,以每种电影类型的受欢迎程度为值
df_gen_popu = pd.DataFrame(index = genre)
#计算每种电影类型的平均受欢迎程度
list = []
for genr in genre:
list.append(df.groupby(genr)['popularity'].mean())
list2 = []
for i in range(len(genre)):
list2.append(list[i][1])
df_gen_popu['mean_popularity'] = list2
df_gen_popu.sort_values(by = 'mean_popularity', ascending=True).plot.barh(label = genre, figsize=(10,6))
plt.xlabel('受欢迎程度', fontsize=15)
plt.ylabel('电影风格', fontsize=15)
plt.title('不同电影风格的受欢迎程度', fontsize=20)
plt.grid(False)
plt.show()
#keywords关键词分析
keywords_list = []
for i in df['keywords']:
keywords_list.append(i)
keywords_list
#把字符串列表连接成一个长字符串
lis = ''.join(keywords_list)
lis.replace('\'s','')
#设置停用词
stopwords = set(STOPWORDS)
stopwords.add('film')
wordcloud = WordCloud(
background_color = 'white',
stopwords = stopwords,
max_words = 3000,
scale=1).generate(lis)
plt.figure(figsize=(10,6))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
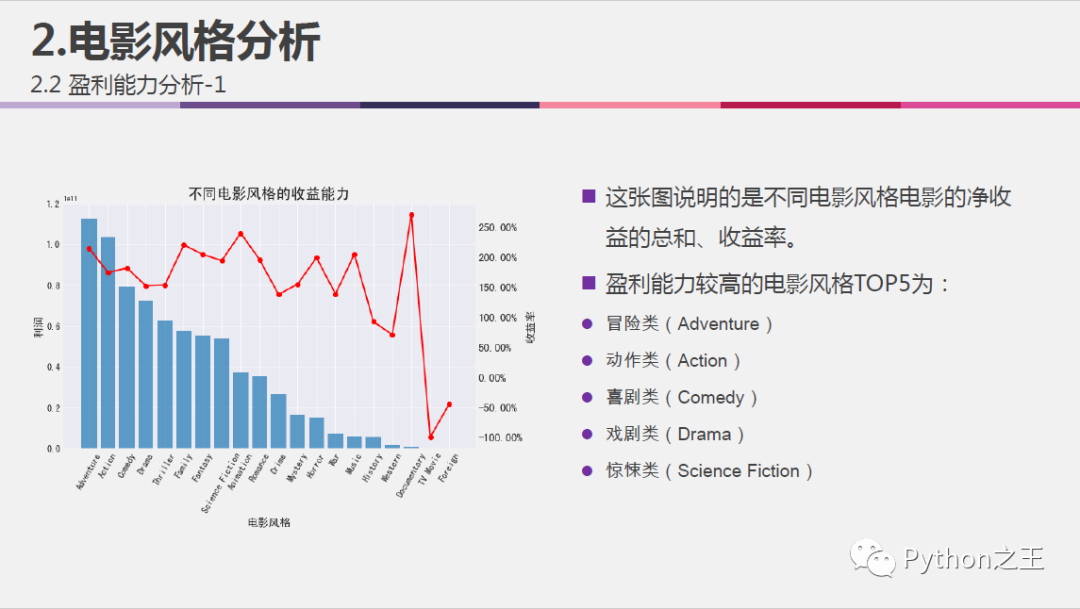
不同电影风格的收益能力分析:
#不同电影风格的收益能力分析
#增加收益列
df['profit'] = df['revenue'] - df['budget']
#创建收益数据框
profit_df = pd.DataFrame()
profit_df = pd.concat([df.loc[:,genre], df['profit']], axis=1)
#创建一个Series,其index为各个genre,值为按genre分类计算的profit之和
profit_sum_by_genre = pd.Series(index=genre)
for genr in genre:
profit_sum_by_genre.loc[genr] = profit_df.loc[:, [genr, 'profit']].groupby(genr, as_index = False).sum().loc[1, 'profit']
#创建一个Series,其index为各个genre,值为按genre分类计算的budget之和
budget_df = pd.concat([df.loc[:,genre], df['budget']], axis=1)
budget_by_genre = pd.Series(index=genre)
for genr in genre:
budget_by_genre.loc[genr] = budget_df.loc[:, [genr, 'budget']].groupby(genr, as_index = False).sum().loc[1, 'budget']
#横向合并数据框
profit_rate = pd.concat([profit_sum_by_genre, budget_by_genre], axis=1)
profit_rate.columns = ['profit', 'budget']
#添加收益率列
profit_rate['profit_rate'] = (profit_rate['profit']/profit_rate['budget'])*100
profit_rate.sort_values(by=['profit', 'profit_rate'], ascending=False, inplace=True)
#xl为索引实际值
xl = profit_rate.index
#可视化不同风格电影的收益(柱状图)和收益率(折线图)
fig = plt.figure(figsize=(10,6))
ax1 = fig.add_subplot(1,1,1)
plt.bar(range(0,20), profit_rate['profit'], label='profit', alpha=0.7)
plt.xticks(range(0,20),xl,rotation=60, fontsize=12)
plt.yticks(fontsize=12)
ax1.set_xlabel('电影风格', fontsize=15)
ax1.set_ylabel('利润', fontsize=15)
ax1.set_title('不同电影风格的收益能力', fontsize=20)
ax1.set_ylim(0,1.2e11)
#次纵坐标轴标签设置为百分比显示
import matplotlib.ticker as mtick
ax2 = ax1.twinx()
ax2.plot(range(0,20), profit_rate['profit_rate'], 'ro-', lw=2, label='profit_rate')
fmt='%.2f%%'
yticks = mtick.FormatStrFormatter(fmt)
ax2.yaxis.set_major_formatter(yticks)
plt.xticks(range(0,20),xl,rotation=60, fontsize=12)
plt.yticks(fontsize=15)
ax2.set_ylabel('收益率', fontsize=15)
plt.grid(False)
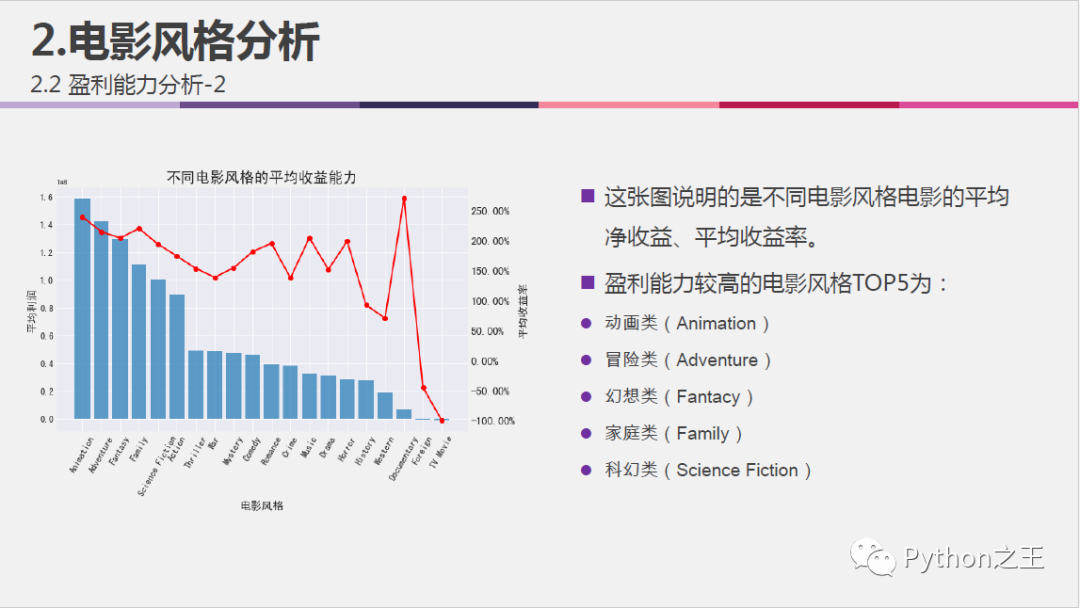
不同电影风格的平均收益能力分析:
#不同电影风格的平均收益能力分析
#创建一个Series,其index为各个genre,值为按genre分类计算的profit平均值
profit_mean_by_genre = pd.Series(index=genre)
for genr in genre:
profit_mean_by_genre.loc[genr] = profit_df.loc[:, [genr, 'profit']].groupby(genr, as_index = False).mean().loc[1, 'profit']
#创建一个Series,其index为各个genre,值为按genre分类计算的budget之和
budget_df = pd.concat([df.loc[:,genre], df['budget']], axis=1)
budget_mean_by_genre = pd.Series(index=genre)
for genr in genre:
budget_mean_by_genre.loc[genr] = budget_df.loc[:, [genr, 'budget']].groupby(genr, as_index = False).mean().loc[1, 'budget']
#横向合并数据框
profit_rate_mean = pd.concat([profit_mean_by_genre, budget_mean_by_genre], axis=1)
profit_rate_mean.columns = ['mean_profit', 'mean_budget']
#添加收益率列
profit_rate_mean['mean_profit_rate'] = (profit_rate_mean['mean_profit']/profit_rate_mean['mean_budget'])*100
profit_rate_mean.sort_values(by=['mean_profit', 'mean_profit_rate'], ascending=False, inplace=True)
#xl为索引实际值
xl = profit_rate_mean.index
#可视化不同风格电影的收益(柱状图)和收益率(折线图)
fig = plt.figure(figsize=(10,6))
ax3 = fig.add_subplot(1,1,1)
plt.bar(range(0,20), profit_rate_mean['mean_profit'], label='mean_profit', alpha=0.7)
plt.xticks(range(0,20),xl,rotation=60, fontsize=12)
plt.yticks(fontsize=12)
ax3.set_xlabel('电影风格', fontsize=15)
ax3.set_ylabel('平均利润', fontsize=15)
ax3.set_title('不同电影风格的平均收益能力', fontsize=20)
#ax3.set_ylim(0,1.2e11)
#次纵坐标轴标签设置为百分比显示
import matplotlib.ticker as mtick
ax4 = ax3.twinx()
ax4.plot(range(0,20), profit_rate_mean['mean_profit_rate'], 'ro-', lw=2, label='mean_profit_rate')
fmt='%.2f%%'
yticks = mtick.FormatStrFormatter(fmt)
ax4.yaxis.set_major_formatter(yticks)
plt.xticks(range(0,20),xl,rotation=60, fontsize=12)
plt.yticks(fontsize=15)
ax4.set_ylabel('平均收益率', fontsize=15)
plt.grid(False)
plt.show()
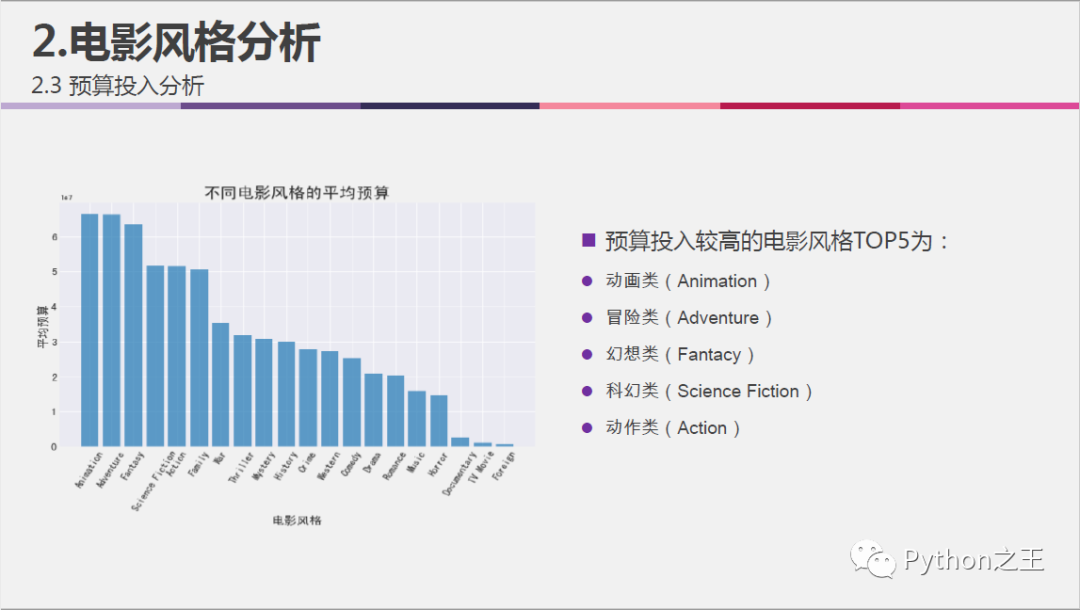
不同电影风格的预算分析:
#可视化不同风格电影的预算
profit_rate_mean.sort_values(by=['mean_budget'], ascending=False, inplace=True)
xl = profit_rate_mean.index
fig = plt.figure(figsize=(10,6))
ax5 = fig.add_subplot(1,1,1)
plt.bar(range(0,20), profit_rate_mean['mean_budget'], label='mean_budget', alpha=0.7)
plt.xticks(range(0,20),xl,rotation=60, fontsize=12)
plt.yticks(fontsize=12)
ax5.set_xlabel('电影风格', fontsize=15)
ax5.set_ylabel('平均预算', fontsize=15)
ax5.set_title('不同电影风格的平均预算', fontsize=20)
#定义一个数据框,以电影类型为索引,以每种电影类型的受欢迎程度为值
df_gen_popu = pd.DataFrame(index = genre)
#计算每种电影类型的平均受欢迎程度
list = []
for genr in genre:
list.append(df.groupby(genr)['popularity'].mean())
list2 = []
for i in range(len(genre)):
list2.append(list[i][1])
df_gen_popu['mean_popularity'] = list2
df_gen_popu.sort_values(by = 'mean_popularity', ascending=True).plot.barh(label = genre, figsize=(10,6))
plt.xlabel('受欢迎程度', fontsize=15)
plt.ylabel('电影风格', fontsize=15)
plt.title('不同电影风格的受欢迎程度', fontsize=20)
plt.grid(False)
plt.show()
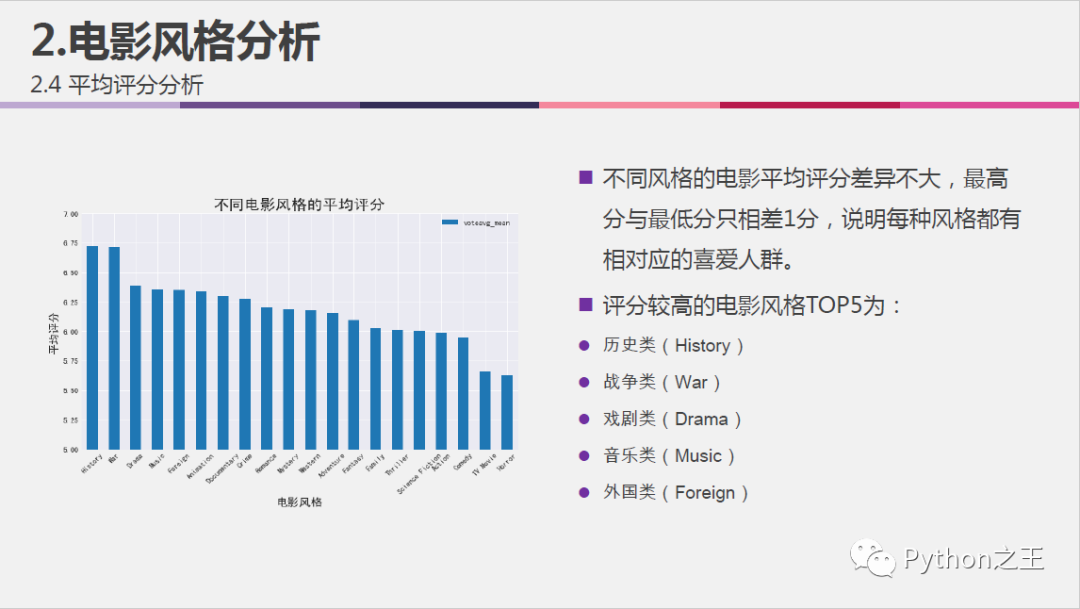
不同电影风格的平均评分分析:
#创建平均评分数据框
vote_avg_df = pd.concat([df.loc[:,genre], df['vote_average']], axis=1)
voteavg_mean_list = []
for genr in genre:
voteavg_mean_list.append(vote_avg_df.groupby(genr, as_index = False).mean().loc[1, 'vote_average'])
#创建不同风格电影平均评分数据框
voteavg_mean_by_genre = pd.DataFrame(index = genre)
voteavg_mean_by_genre['voteavg_mean'] = voteavg_mean_list
df['popularity'].corr(df['vote_average'])
#可视化不同风格电影的平均评分
voteavg_mean_by_genre.sort_values(by='voteavg_mean', ascending=False, inplace = True)
fig = plt.figure(figsize=(10,6))
ax = fig.add_subplot(1,1,1)
voteavg_mean_by_genre.plot.bar(ax=ax)
plt.title('不同电影风格的平均评分', fontsize=20)
plt.xlabel('电影风格', fontsize = 15)
plt.ylabel('平均评分', fontsize = 15)
plt.xticks(rotation=45)
plt.ylim(5, 7, 0.5)
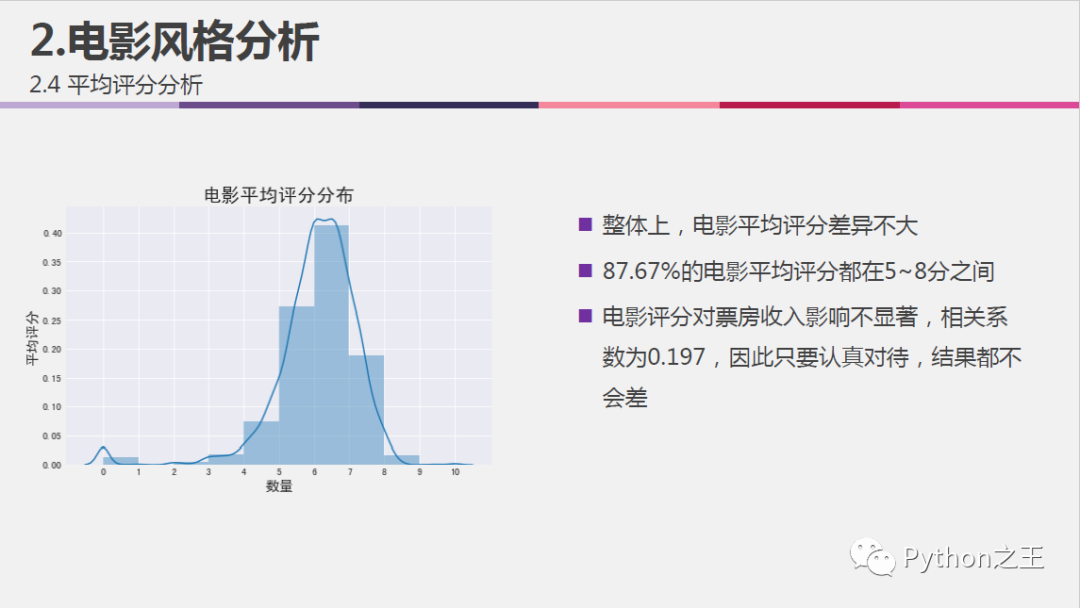
#可视化所有电影的评分分布
fig, ax = plt.subplots(figsize=(8,5))
ax = sns.distplot(df['vote_average'], bins=10)
plt.title('电影平均评分分布', fontsize=20)
plt.xlabel('数量', fontsize = 15)
plt.ylabel('平均评分', fontsize = 15)
plt.xticks(np.arange(11))
plt.grid(True)
plt.show()
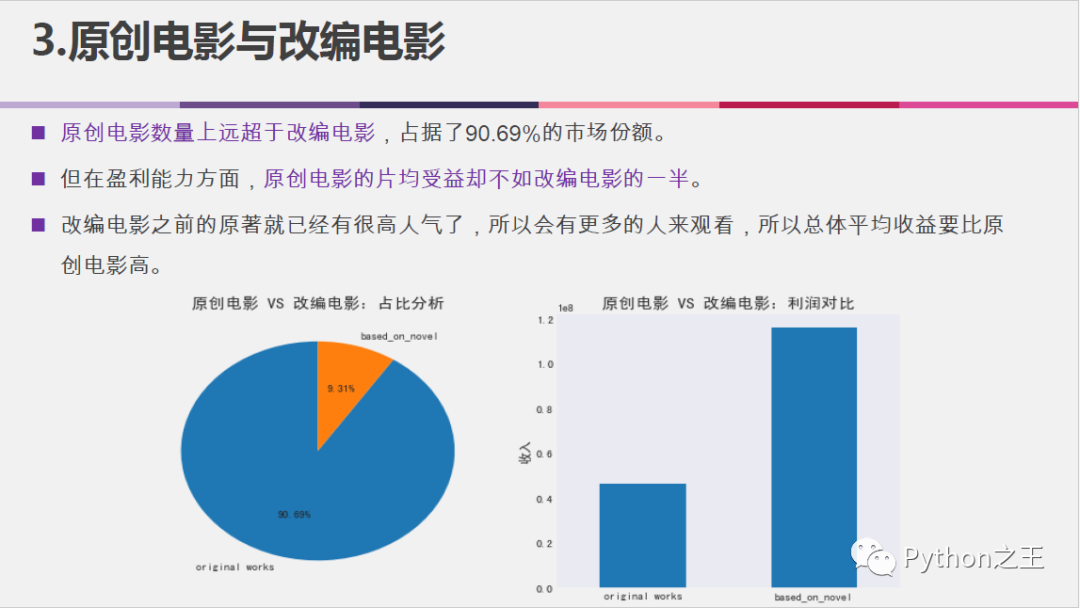
原创电影与改编电影对比分析:
#原创电影与改编电影对比分析
original_novel = pd.DataFrame()
original_novel['keywords'] = df['keywords'].str.contains('based on').map(lambda x: 1 if x else 0)
original_novel['profit'] = df['profit']
novel_count = original_novel['keywords'].sum()
original_count = original_novel['keywords'].count() - original_novel['keywords'].sum()
original_novel = original_novel.groupby('keywords', as_index = False).mean()
#创建原创与改编对比的数据框
org_vs_novel = pd.DataFrame()
org_vs_novel['count'] = [original_count, novel_count]
org_vs_novel['profit'] = original_novel['profit']
org_vs_novel.index = ['original works', 'based_on_novel']
#可视化原创电影与改编电影的数量占比(饼图)、片均受益(柱状图)
fig= plt.figure(figsize = (12,5))
ax1 = plt.subplot(1, 2, 1)
ax1 = plt.pie(org_vs_novel['count'], labels=org_vs_novel.index, autopct='%.2f%%', startangle=90, pctdistance=0.6)
plt.title('原创电影 VS 改编电影:占比分析', fontsize=15)
ax2 = plt.subplot(1, 2, 2)
ax2 = org_vs_novel['profit'].plot.bar()
plt.xticks(rotation=0)
plt.ylabel('收入', fontsize=12)
plt.title('原创电影 VS 改编电影:利润对比', fontsize=15)
plt.grid(False)
plt.show()
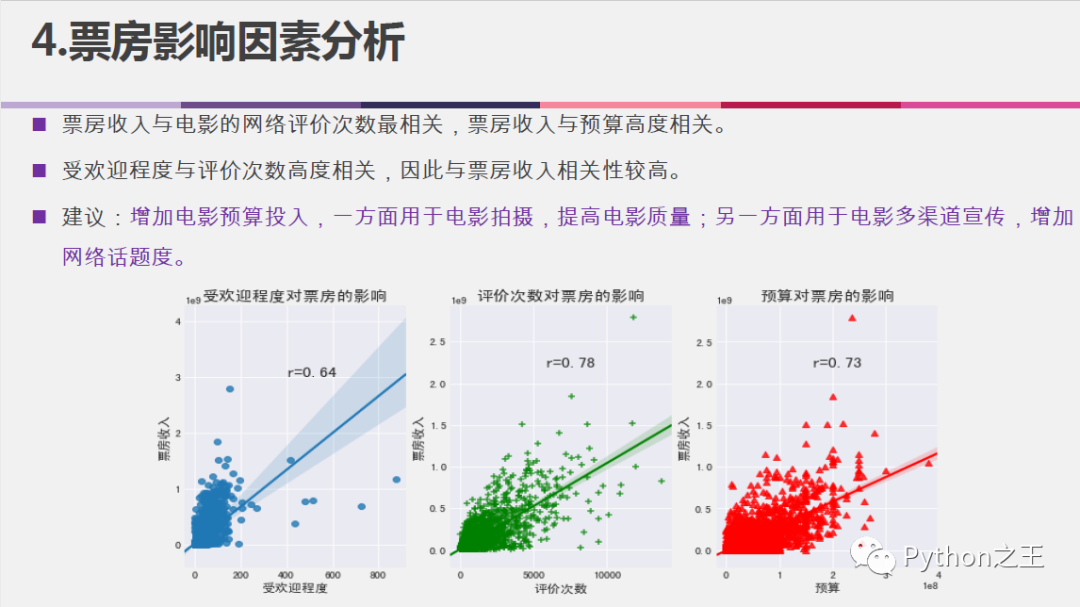
票房收入影响因素分析:
#通过相关性分析观察影响票房的因素
df[['budget', 'popularity', 'revenue', 'runtime', 'vote_average', 'vote_count']].corr()
#从相关性结果中发现对票房影响比较大的是预算、受欢迎度、评分次数
revenue_corr = df[['popularity', 'vote_count', 'budget', 'revenue']]
#可视化票房收入分别与受欢迎程度(蓝)、评价次数(绿)、电影预算(红)的相关性散点图
fig = plt.figure(figsize=(12,5))
ax1 = plt.subplot(1,3,1)
ax1 = sns.regplot(x='popularity', y='revenue', data=revenue_corr, x_jitter=0.1)
ax1.text(400,3e9, 'r=0.64', fontsize=15)
plt.title('受欢迎程度对票房的影响', fontsize=15)
plt.xlabel('受欢迎程度', fontsize=12)
plt.ylabel('票房收入', fontsize=12)
ax2 = plt.subplot(1,3,2)
ax2 = sns.regplot(x='vote_count', y='revenue', data=revenue_corr, x_jitter=0.1, color='g', marker='+')
ax2.text(5800,2.2e9, 'r=0.78', fontsize=15)
plt.title('评价次数对票房的影响', fontsize=15)
plt.xlabel('评价次数', fontsize=12)
plt.ylabel('票房收入', fontsize=12)
ax3 = plt.subplot(1,3,3)
ax3 = sns.regplot(x='budget', y='revenue', data=revenue_corr, x_jitter=0.1, color='r', marker='^')
ax3.text(1.6e8,2.2e9, 'r=0.73', fontsize=15)
plt.title('预算对票房的影响', fontsize=15)
plt.xlabel('预算', fontsize=12)
plt.ylabel('票房收入', fontsize=12)
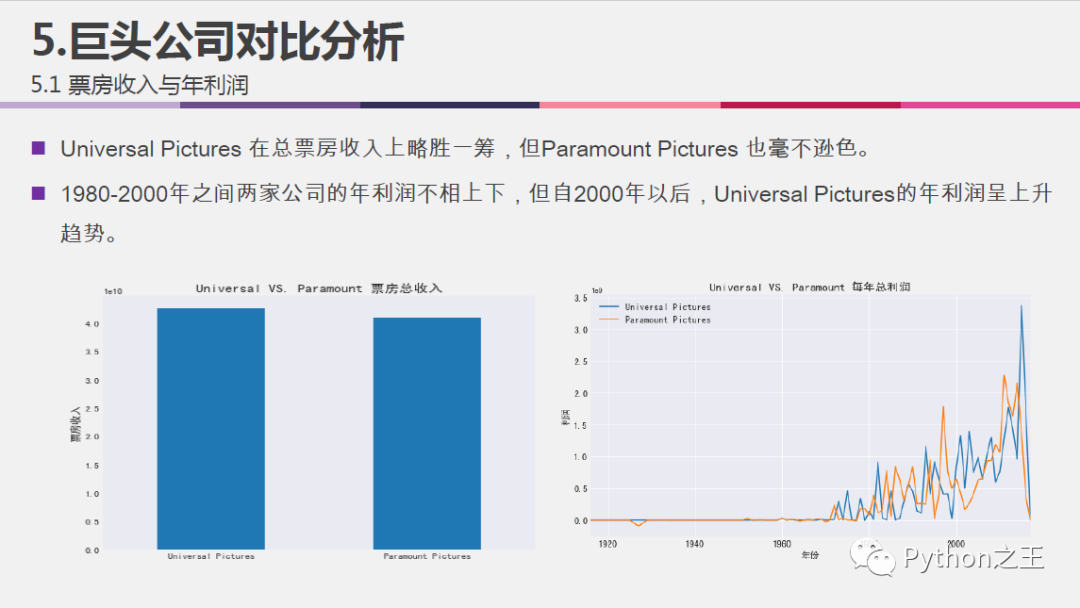
行业内两巨头公司对比分析:
#创建公司数据框
company_list = ['Universal Pictures', 'Paramount Pictures']
df_company = pd.DataFrame()
for company in company_list:
df_company[company] = df['production_companies'].str.contains(company).map(lambda x: 1 if x else 0)
df_company = pd.concat([df['release_year'], df_company, df.loc[:,genre], df['revenue'], df['profit']], axis=1)
#创建巨头对比数据框
Uni_vs_Para = pd.DataFrame(index=company_list, columns = df_company.columns[3:])
#计算两公司的收益总额
Uni_vs_Para.loc['Universal Pictures'] = df_company.groupby('Universal Pictures', as_index=False).sum().iloc[1,3:-1]
Uni_vs_Para.loc['Paramount Pictures'] = df_company.groupby('Paramount Pictures', as_index=False).sum().iloc[1,3:-1]
#可视化两公司票房收入对比
fig = plt.figure(figsize=(8,6))
ax = fig.add_subplot(1,1,1)
Uni_vs_Para['revenue'].plot(ax=ax, kind='bar')
plt.title('Universal VS. Paramount 票房总收入', fontsize=15)
plt.xticks(rotation=0)
plt.ylabel('票房收入', fontsize=12)
plt.grid(False)
plt.show()
#建立两家公司的利润对话框
df_company_profit = df_company[['Universal Pictures', 'Paramount Pictures', 'profit']].reset_index(drop=True)
df_company_profit.index = df['release_year']
#将两家公司的利润提取出来,并合并每年的利润
df_company_profit['Universal Pictures_profit'] = df_company_profit['Universal Pictures']*df_company_profit['profit']
df_company_profit['Paramount Pictures_profit'] = df_company_profit['Paramount Pictures']*df_company_profit['profit']
company1 = df_company_profit['Universal Pictures_profit'].groupby('release_year').sum()
company2 = df_company_profit['Paramount Pictures_profit'].groupby('release_year').sum()
#绘制两家公司的总利润随时间变化折线图
fig = plt.figure(figsize = (10,6))
ax1 = fig.add_subplot(1,1,1)
company1.plot(x=df_company_profit.index, y=df_company_profit['Universal Pictures_profit'], label='Universal Pictures', ax=ax1)
company2.plot(x=df_company_profit.index, y=df_company_profit['Paramount Pictures_profit'], label='Paramount Pictures', ax=ax1)
plt.title('Universal VS. Paramount 每年总利润', fontsize=15)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.xlabel('年份', fontsize=12)
plt.ylabel('利润', fontsize=12)
plt.legend(fontsize=12)
plt.show()
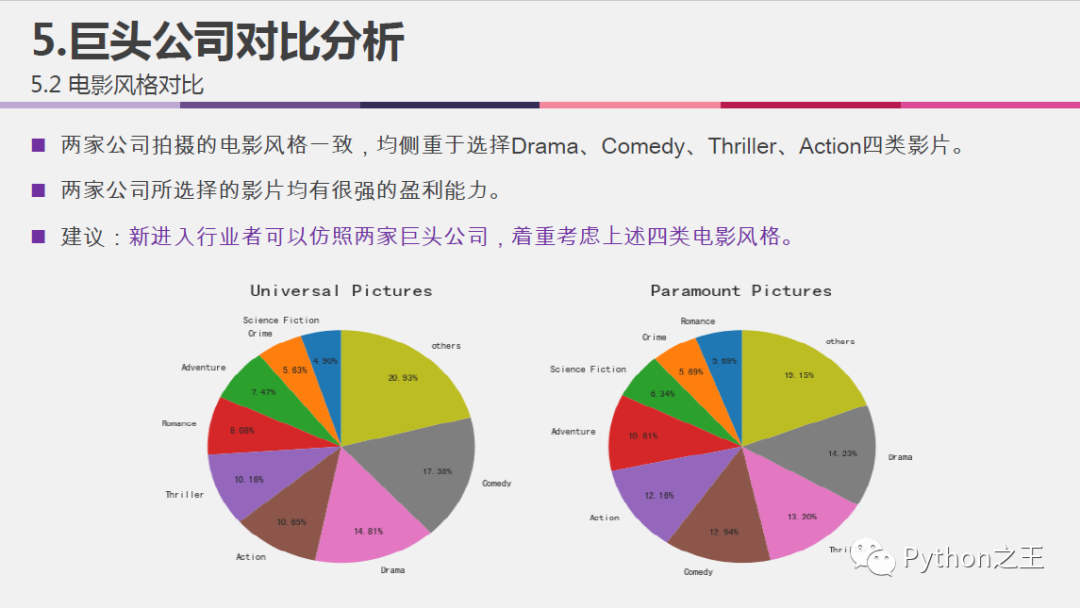
#转置
Uni_vs_Para = Uni_vs_Para.T
Universal = Uni_vs_Para['Universal Pictures'].iloc[:-1]
Paramount = Uni_vs_Para['Paramount Pictures'].iloc[:-1]
Universal['others'] = Universal.sort_values(ascending=False).iloc[8:].sum()
Universal = Universal.sort_values(ascending=True).iloc[-9:]
Paramount['others'] = Paramount.sort_values(ascending=False).iloc[8:].sum()
Paramount = Paramount.sort_values(ascending=True).iloc[-9:]
#两公司电影风格可视化
fig = plt.figure(figsize=(13, 6))
ax1 = plt.subplot(1,2,1)
ax1 = plt.pie(Universal, labels = Universal.index, autopct='%.2f%%', startangle=90, pctdistance=0.75)
plt.title('Universal Pictures', fontsize=20)
ax2 = plt.subplot(1,2,2)
ax2 = plt.pie(Paramount, labels = Paramount.index, autopct='%.2f%%', startangle=90, pctdistance=0.75)
plt.title('Paramount Pictures', fontsize=20)
plt.show()


Python“宝藏级”公众号【Python之王】专注于Python领域,会爬虫,数分,C++,tensorflow和Pytorch等等。
近 2年共原创 100+ 篇技术文章。创作的精品文章系列有:
日常收集整理了一批不错的 Python 学习资料,有需要的小伙可以自行免费领取。
获取方式如下:公众号回复资料。领取Python等系列笔记,项目,书籍,直接套上模板就可以用了。资料包含算法、python、算法小抄、力扣刷题手册和 C++ 等学习资料!