3W 字详解 Java 集合
超全技术栈的Java入门+进阶+实战!(非白嫖,点击查看)
本文一共 3.5 W字,25 张图,预计阅读 2h。可以收藏这篇文章,用的时候防止找不到,这可能是你能看到的最详细的一篇文章了。
1. 集合框架
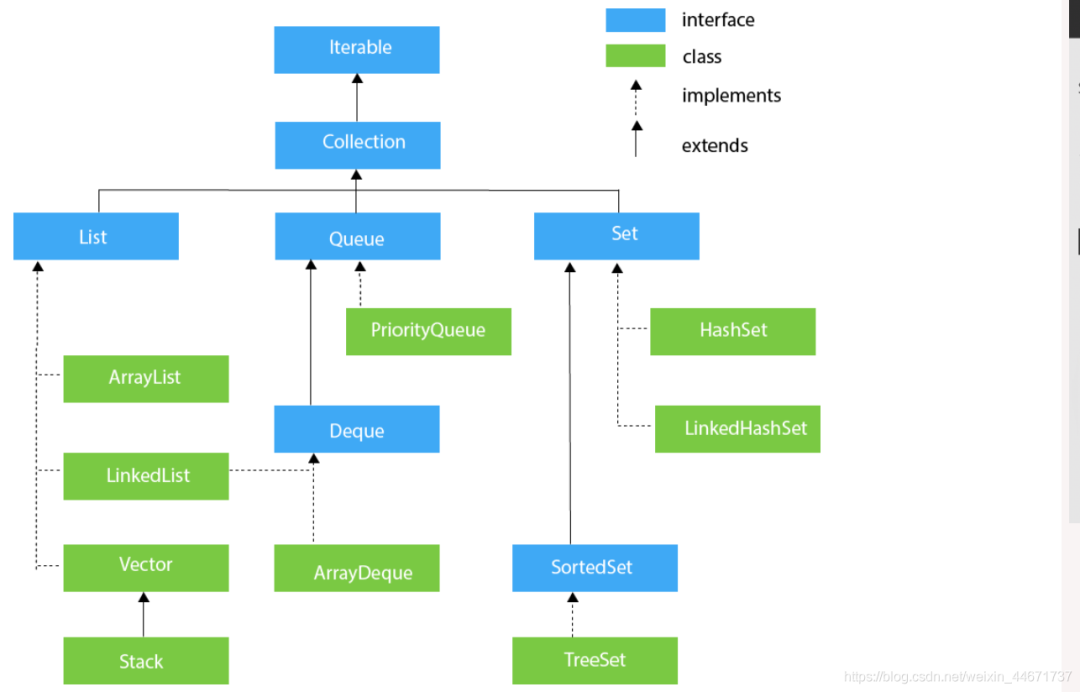
1.1 顶层接口Iterable
//支持lambda函数接口
import java.util.function.Consumer;
public interface Iterable<T> {
//iterator()方法
Iterator<T> iterator();
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
default Spliterator<T> spliterator() {
return Spliterators.spliteratorUnknownSize(iterator(), 0);
}
}
package java.util;
import java.util.function.Predicate;
import java.util.stream.Stream;
import java.util.stream.StreamSupport;
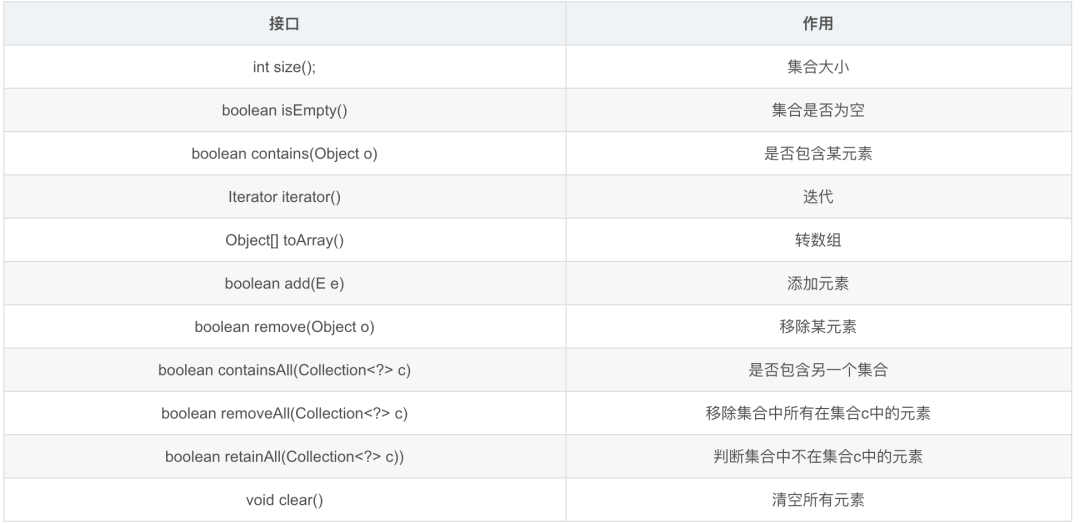
public interface Collection<E> extends Iterable<E> {
int size();
boolean isEmpty();
boolean contains(Object o);
Iterator<E> iterator();
Object[] toArray();
boolean add(E e);
boolean remove(Object o);
boolean containsAll(Collection<?> c);
boolean removeAll(Collection<?> c);
default boolean removeIf(Predicate<? super E> filter) {
Objects.requireNonNull(filter);
boolean removed = false;
final Iterator<E> each = iterator();
while (each.hasNext()) {
if (filter.test(each.next())) {
each.remove();
removed = true;
}
}
return removed;
}
boolean retainAll(Collection<?> c);
void clear();
int hashCode();
@Override
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, 0);
}
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
default Stream<E> parallelStream() {
return StreamSupport.stream(spliterator(), true);
}
}
2.1 List接口
package java.util;
import java.util.function.UnaryOperator;
public interface List<E> extends Collection<E> {
<T> T[] toArray(T[] a);
boolean addAll(Collection<? extends E> c);
boolean addAll(int index, Collection<? extends E> c);
default void replaceAll(UnaryOperator<E> operator) {
Objects.requireNonNull(operator);
final ListIterator<E> li = this.listIterator();
while (li.hasNext()) {
li.set(operator.apply(li.next()));
}
}
default void sort(Comparator<? super E> c) {
Object[] a = this.toArray();
Arrays.sort(a, (Comparator) c);
ListIterator<E> i = this.listIterator();
for (Object e : a) {
i.next();
i.set((E) e);
}
}
boolean equals(Object o);
E get(int index);
E set(int index, E element);
void add(int index, E element);
int indexOf(Object o);
int lastIndexOf(Object o);
ListIterator<E> listIterator();
List<E> subList(int fromIndex, int toIndex);
@Override
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, Spliterator.ORDERED);
}
}
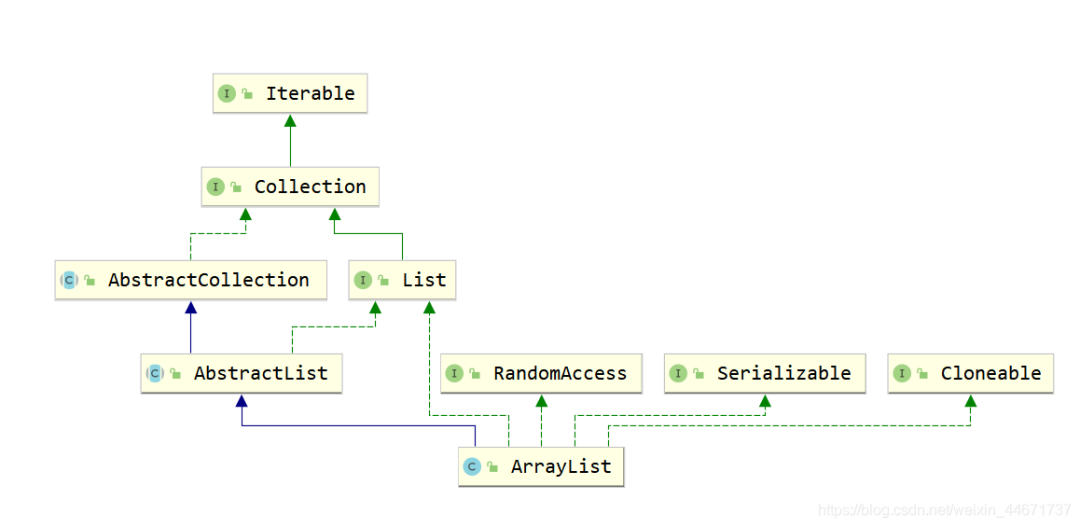
2.2 List实现ArrayList
ArrayList是List接口最常用的一个实现类,支持List接口的一些列操作。
2.2.1 ArrayList继承关系
2.2.2 ArrayList组成
private static final Object[] EMPTY_ELEMENTDATA = {};
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {}
//真正存放元素的数组
transient Object[] elementData; // non-private to simplify nested class access
private int size;
2.2.3 ArrayList构造函数
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
2.2.4 ArrayList中添加元素
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
2.2.4 ArrayList扩容
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
//DEFAULT_CAPACITY是10
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
int newCapacity = oldCapacity + (oldCapacity >> 1);
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
2.2.5 数组copy
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);
p = (int *)malloc(len*sizeof(int));
2.2.6 why?elementData用transient修饰?
1. transient的作用是该属性不参与序列化。
2. ArrayList继承了标示序列化的Serializable接口
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
/**
* Reconstitute the <tt>ArrayList</tt> instance from a stream (that is,
* deserialize it).
*/
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in capacity
s.readInt(); // ignored
if (size > 0) {
// be like clone(), allocate array based upon size not capacity
int capacity = calculateCapacity(elementData, size);
SharedSecrets.getJavaOISAccess().checkArray(s, Object[].class, capacity);
ensureCapacityInternal(size);
Object[] a = elementData;
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
a[i] = s.readObject();
}
}
}
protected transient int modCount = 0;
2.3 LinkedList
2.3.1 LinkedList继承关系
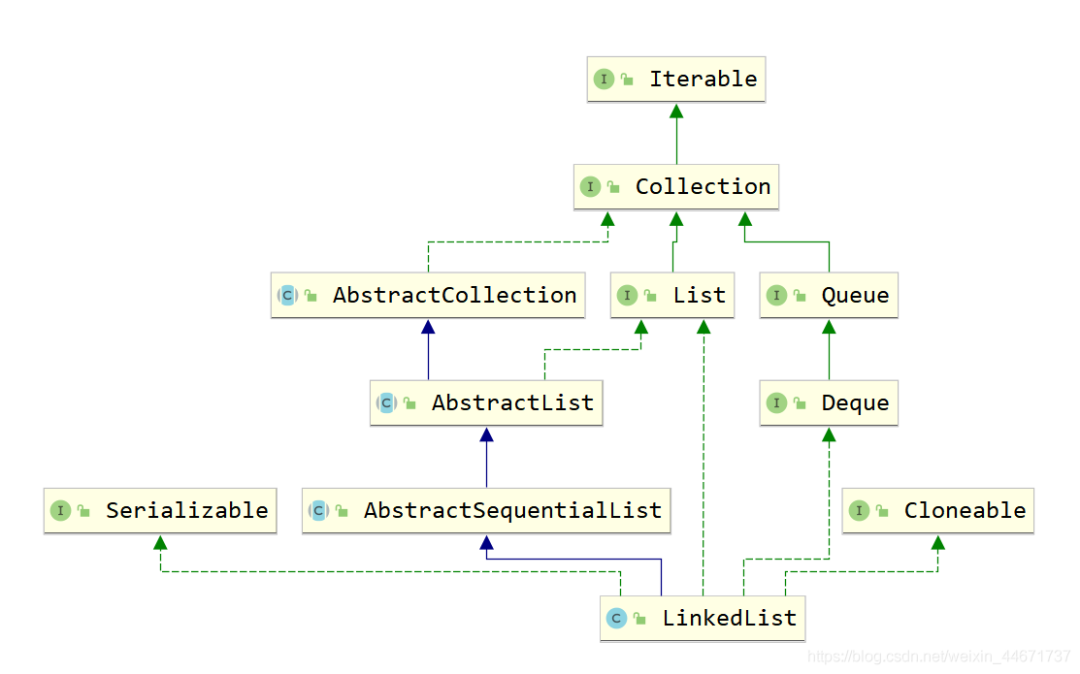
2.3.2 LinkedList的结构
transient Node<E> first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}transient int size = 0;
transient Node<E> first;
transient Node<E> last;
public LinkedList() {
}/**
* Links e as first element. 头插法
*/
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
/**
* Links e as last element. 尾插法
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}2.3.3 LinkedList查询方法
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}Node<E> node(int index) {
// assert isElementIndex(index);
//判断index更靠近头部还是尾部
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}2.4.3 LinkedList修改方法
public boolean add(E e) {
linkLast(e);
return true;
}2.5 Vector
和ArrayList一样,Vector也是List接口的一个实现类。其中List接口主要实现类有ArrayLIst,LinkedList,Vector,Stack,其中后两者用的特别少。
2.5.1 vector组成
//存放元素的数组
protected Object[] elementData;
//有效元素数量,小于等于数组长度
protected int elementCount;
//容量增加量,和扩容相关
protected int capacityIncrement;2.5.2 vector线程安全性
vector是线程安全的,synchronized修饰的操作方法。
2.5.3 vector扩容
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
//扩容大小
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}2.5.4 vector方法经典示例
public synchronized E remove(int index) {
modCount++;
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
E oldValue = elementData(index);
int numMoved = elementCount - index - 1;
if (numMoved > 0)
//复制数组,假设数组移除了中间某元素,后边有效值前移1位
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
//引用null ,gc会处理
elementData[--elementCount] = null; // Let gc do its work
return oldValue;
}总体上vector实现是比较简单粗暴的,也很少用到,随便看看即可。
2.6 Stack
2.6.1 Stack的继承关系
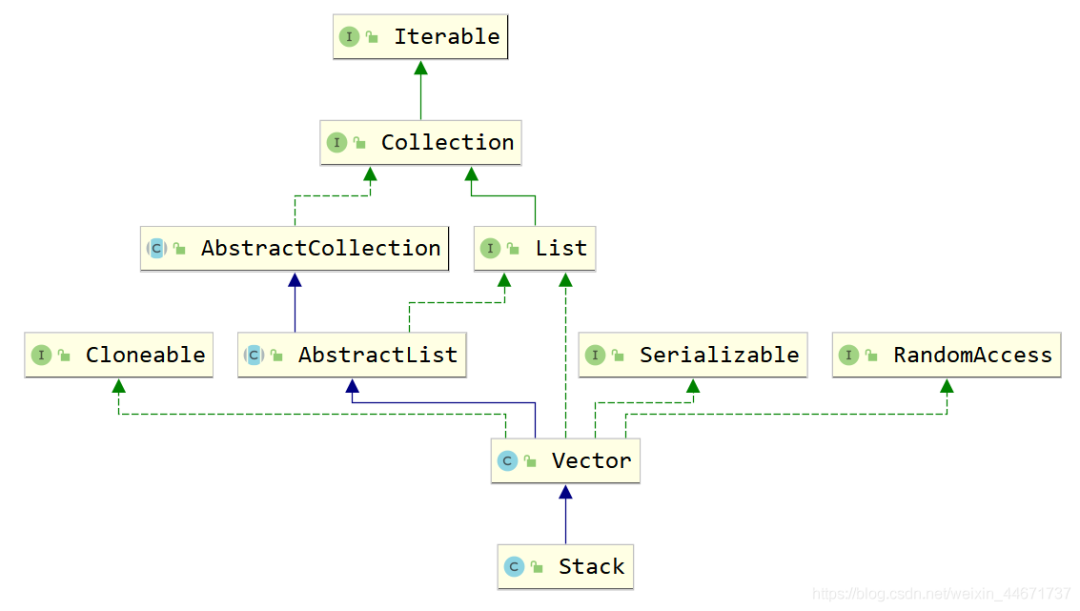
2.6.2 Stack的使用
Stack<String> strings = new Stack<>();
strings.push("aaa");
strings.push("bbb");
strings.push("ccc");
System.err.println(strings.pop());
2.6.3 Stack源码
/**
* Stack源码(Jdk8)
*/
public
class Stack<E> extends Vector<E> {
public Stack() {
}
//入栈,使用的是Vector的addElement方法。
public E push(E item) {
addElement(item);
return item;
}
//出栈,找到数组最后一个元素,移除并返回。
public synchronized E pop() {
E obj;
int len = size();
obj = peek();
removeElementAt(len - 1);
return obj;
}
public synchronized E peek() {
int len = size();
if (len == 0)
throw new EmptyStackException();
return elementAt(len - 1);
}
public boolean empty() {
return size() == 0;
}
public synchronized int search(Object o) {
int i = lastIndexOf(o);
if (i >= 0) {
return size() - i;
}
return -1;
}
private static final long serialVersionUID = 1224463164541339165L;
}3. Queue
正如数据结构中描述,queue是一种先进先出的数据结构,也就是first in first out。可以将queue看作一个只可以从某一段放元素进去的一个容器,取元素只能从另一端取,整个机制如下图所示,不过需要注意的是,队列并没有规定是从哪一端插入,从哪一段取出。

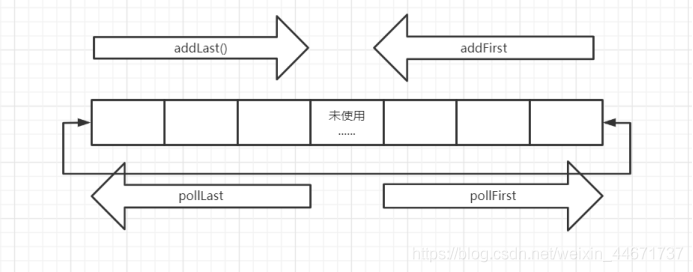
3.1 什么是Deque
Deque英文全称是Double ended queue,也就是俗称的双端队列。就是说对于这个队列容器,既可以从头部插入也可以从尾部插入,既可以从头部获取,也可以从尾部获取,其机制如下图所示。

3.1.1 Java中的Queue接口
package java.util;
public interface Queue<E> extends Collection<E> {
//集合中插入元素
boolean add(E e);
//队列中插入元素
boolean offer(E e);
//移除元素,当集合为空,抛出异常
E remove();
//移除队列头部元素并返回,如果为空,返回null
E poll();
//查询集合第一个元素,如果为空,抛出异常
E element();
//查询队列中第一个元素,如果为空,返回null
E peek();
}
3.1.2 Deque接口
package java.util;
public interface Deque<E> extends Queue<E> {
//deque的操作方法
void addFirst(E e);
void addLast(E e);
boolean offerFirst(E e);
boolean offerLast(E e);
E removeFirst();
E removeLast();
E pollFirst();
E pollLast();
E getFirst();
E getLast();
E peekFirst();
E peekLast();
boolean removeFirstOccurrence(Object o);
boolean removeLastOccurrence(Object o);
// *** Queue methods ***
boolean add(E e);
boolean offer(E e);
E remove();
E poll();
E element();
E peek();
// 省略一堆stack接口方法和collection接口方法
}3.1.3 Queue,Deque的实现类
Java中关于Queue的实现主要用的是双端队列,毕竟操作更加方便自由,Queue的实现有PriorityQueue,Deque在java.util中主要有ArrayDeque和LinkedList两个实现类,两者一个是基于数组的实现,一个是基于链表的实现。在之前LinkedList文章中也提到过其是一个双向链表,在此基础之上实现了Deque接口。
3.2 PriorityQueue
PriorityQueue是Java中唯一一个Queue接口的直接实现,如其名字所示,优先队列,其内部支持按照一定的规则对内部元素进行排序。
3.2.1 PriorityQueue继承关系
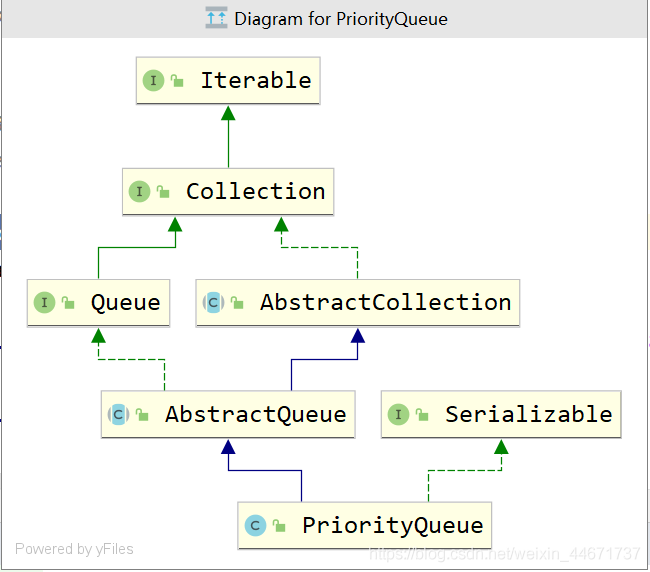
3.2.2 PriorityQueue的使用
PriorityQueue<Integer> queue = new PriorityQueue<>();
queue.add(20);queue.add(14);queue.add(21);queue.add(8);queue.add(9);
queue.add(11);queue.add(13);queue.add(10);queue.add(12);queue.add(15);
while (queue.size()>0){
Integer poll = queue.poll();
System.err.print(poll+"->");
}
// 必须实现Comparable方法,想String,数值本身即可比较
private static class Test implements Comparable<Test>{
private int a;
public Test(int a) {
this.a = a;
}
public int getA() {
return a;
}
public void setA(int a) {
this.a = a;
}
@Override
public String toString() {
return "Test{" +
"a=" + a +
'}';
}
@Override
public int compareTo(Test o) {
return 0;
}
}
public static void main(String[] args) {
PriorityQueue<Test> queue = new PriorityQueue<>();
queue.add(new Test(20));queue.add(new Test(14));queue.add(new Test(21));queue.add(new Test(8));queue.add(new Test(9));
queue.add(new Test(11));queue.add(new Test(13));queue.add(new Test(10));queue.add(new Test(12));queue.add(new Test(15));
while (queue.size()>0){
Test poll = queue.poll();
System.err.print(poll+"->");
}
}
3.2.3 PriorityQueue组成
/**
* 默认容量大小,数组大小
*/
private static final int DEFAULT_INITIAL_CAPACITY = 11;
/**
* 存放元素的数组
*/
transient Object[] queue; // non-private to simplify nested class access
/**
* 队列中存放了多少元素
*/
private int size = 0;
/**
* 自定义的比较规则,有该规则时优先使用,否则使用元素实现的Comparable接口方法。
*/
private final Comparator<? super E> comparator;
/**
* 队列修改次数,每次存取都算一次修改
*/
transient int modCount = 0; // non-private to simplify nested class access3.2.4 PriorityQueue操作方法
offer方法
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length)
grow(i + 1);
size = i + 1;
//i=size,当queue为空的时候
if (i == 0)
queue[0] = e;
else
siftUp(i, e);
return true;
}private void siftUp(int k, E x) {
if (comparator != null)
siftUpUsingComparator(k, x);
else
siftUpComparable(k, x);
}private void siftUpComparable(int k, E x) {
Comparable<? super E> key = (Comparable<? super E>) x;
while (k > 0) {
//为什么-1, 思考数组位置0,1,2。0是1和2的父节点
int parent = (k - 1) >>> 1;
//父节点
Object e = queue[parent];
//当传入的新节点大于父节点则不做处理,否则二者交换
if (key.compareTo((E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = key;
}pool方法
public E poll() {
if (size == 0)
return null;
int s = --size;
modCount++;
E result = (E) queue[0];
//s = --size,即原来数组的最后一个元素
E x = (E) queue[s];
queue[s] = null;
if (s != 0)
siftDown(0, x);
return result;
}private void siftDownComparable(int k, E x) {
Comparable<? super E> key = (Comparable<? super E>)x;
int half = size >>> 1; // loop while a non-leaf
while (k < half) {
int child = (k << 1) + 1; // assume left child is least
Object c = queue[child];
int right = child + 1;
if (right < size &&
//c和right是parent的两个子节点,找出小的那个成为新的c。
((Comparable<? super E>) c).compareTo((E) queue[right]) > 0)
c = queue[child = right];
if (key.compareTo((E) c) <= 0)
break;
//小的变成了新的父节点
queue[k] = c;
k = child;
}
queue[k] = key;
}3.3 ArrayDeque
ArrayDeque是Java中基于数组实现的双端队列,在Java中Deque的实现有LinkedList和ArrayDeque,正如它两的名字就标志了它们的不同,LinkedList是基于双向链表实现的,而ArrayDeque是基于数组实现的。
3.3.1 ArrayDeque的继承关系
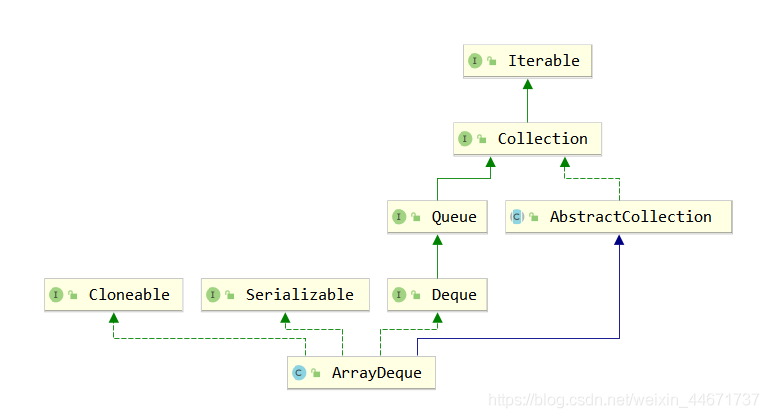
3.3.2 ArrayDeque使用
ArrayDeque<String> deque = new ArrayDeque<>();
deque.offer("aaa");
deque.offer("bbb");
deque.offer("ccc");
deque.offer("ddd");
//peek方法只获取不移除
System.err.println(deque.peekFirst());
System.err.println(deque.peekLast());
ArrayDeque<String> deque = new ArrayDeque<>();
deque.offerFirst("aaa");
deque.offerLast("bbb");
deque.offerFirst("ccc");
deque.offerLast("ddd");
String a;
while((a = deque.pollLast())!=null){
System.err.print(a+"->");
}
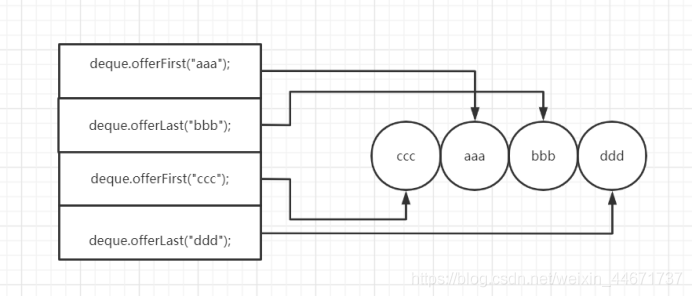
3.3.4 ArrayDeque内部组成
//具体存放元素的数组,数组大小一定是2的幂次方
transient Object[] elements; // non-private to
//队列头索引
transient int head;
//队列尾索引
transient int tail;
//默认的最小初始化容量,即传入的容量小于8容量为8,而默认容量是16
private static final int MIN_INITIAL_CAPACITY = 8;3.3.5 数组elements长度
private static int calculateSize(int numElements) {
int initialCapacity = MIN_INITIAL_CAPACITY;
// Find the best power of two to hold elements.
// Tests "<=" because arrays aren't kept full.
if (numElements >= initialCapacity) {
initialCapacity = numElements;
initialCapacity |= (initialCapacity >>> 1);
initialCapacity |= (initialCapacity >>> 2);
initialCapacity |= (initialCapacity >>> 4);
initialCapacity |= (initialCapacity >>> 8);
initialCapacity |= (initialCapacity >>> 16);
initialCapacity++;
if (initialCapacity < 0) // Too many elements, must back off
initialCapacity >>>= 1;// Good luck allocating 2 ^ 30 elements
}
return initialCapacity;
}3.3.6 ArrayDeque实现机制
源码:
public void addFirst(E e) {
if (e == null)
throw new NullPointerException();
elements[head = (head - 1) & (elements.length - 1)] = e;
if (head == tail)
doubleCapacity();
}注意下边这行代码,表示当head-1大于等于0时,head=head-1,否则head=elements.length - 1。
head = (head - 1) & (elements.length - 1)换一种写法就是下边这样,是不是就是上边addFirst的指针移动方向?
head = head-1>=0?head-1:elements.length-1这个就是位运算的神奇操作了,因为任何数与大于它的一个全是二进制1做&运算时等于它自身,如1010&1111 = 1010,此处不赘述。
public void addLast(E e) {
if (e == null)
throw new NullPointerException();
elements[tail] = e;
if ( (tail = (tail + 1) & (elements.length - 1)) == head)
doubleCapacity();
}(tail = (tail + 1) & (elements.length - 1))tail = tail+1>element-1?0:tail+1,是不是很神奇的写法,其原理是一个二进制数全部由1组成和一个大于它的数做&运算结果为0,如10000&1111 = 0。poll方法和add方法逻辑是相反的,此处就不再赘述,诸君共求之!4.1 Set接口
package java.util;
public interface Set<E> extends Collection<E> {
// Query Operations
int size();
boolean isEmpty();
Object[] toArray();
<T> T[] toArray(T[] a);
// Modification Operations
boolean add(E e);
boolean remove(Object o);
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c);
boolean retainAll(Collection<?> c);
boolean removeAll(Collection<?> c);
void clear();
boolean equals(Object o);
int hashCode();
//此处和Collection接口由区别
Spliterator<E> spliterator() {
return Spliterators.spliterator(this, Spliterator.DISTINCT);
}
}4.2 HashSet
4.2.1 HashSet继承关系
4.2.3 HashSet源码
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap<E,Object> map;
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
public Iterator<E> iterator() {
return map.keySet().iterator();
}
public int size() {
return map.size();
}
public boolean isEmpty() {
return map.isEmpty();
}
public boolean contains(Object o) {
return map.containsKey(o);
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
public void clear() {
map.clear();
}
}4.2.4 HashSet是如何保证不重复的呢?
4.3 LinkedHashSet
LinkedHashSet用的也比较少,其也是基于Set的实现。
4.3.1 LinkedHashSet继承关系
4.3.2 LinkedHashSet源码
package java.util;
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
private static final long serialVersionUID = -2851667679971038690L;
public LinkedHashSet(int initialCapacity, float loadFactor) {
//调用HashSet的构造方法
super(initialCapacity, loadFactor, true);
}
public LinkedHashSet(int initialCapacity) {
super(initialCapacity, .75f, true);
}
public LinkedHashSet() {
super(16, .75f, true);
}
public LinkedHashSet(Collection<? extends E> c) {
super(Math.max(2*c.size(), 11), .75f, true);
addAll(c);
}
@Override
public Spliterator<E> spliterator() {
return Spliterators.spliterator(this, Spliterator.DISTINCT |
Spliterator.ORDERED);
}
}其操作方法和HashSet完全一样,那么二者区别是什么呢?
1.首先LinkedHashSet是HashSet的子类。
2.LinkedHashSet中用于存储值的实现LinkedHashMap,而HashSet使用的是HashMap。LinkedHashSet中调用的父类构造器,可以看到其实列是一个LinkedHashMap。
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}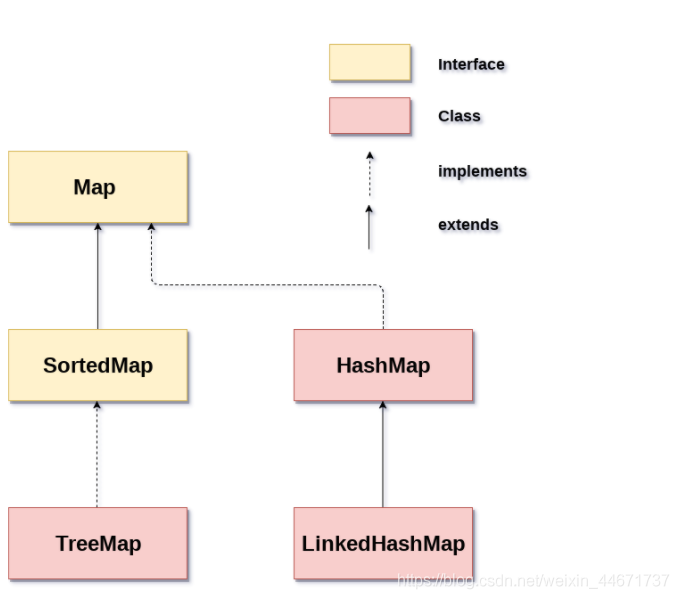
Map是一种键值对的结构,就是常说的Key-Value结构,一个Map就是很多这样K-V键值对组成的,一个K-V结构我们将其称作Entry,在Java里,Map是用的非常多的一种数据结构。上图展示了Map家族最基础的一个结构(只是指java.util中)。
5.1 Map接口
package java.util;
import java.util.function.BiConsumer;
import java.util.function.BiFunction;
import java.util.function.Function;
import java.io.Serializable;
public interface Map<K,V> {
// Query Operations
int size();
boolean isEmpty();
boolean containsKey(Object key);
boolean containsValue(Object value);
V get(Object key);
// Modification Operations
V put(K key, V value);
V remove(Object key);
// Bulk Operations
void putAll(Map<? extends K, ? extends V> m);
void clear();
Set<K> keySet();
Collection<V> values();
Set<Map.Entry<K, V>> entrySet();
interface Entry<K,V> {
K getKey();
V getValue();
V setValue(V value);
boolean equals(Object o);
int hashCode();
public static <K extends Comparable<? super K>, V> Comparator<Map.Entry<K,V>> comparingByKey() {
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> c1.getKey().compareTo(c2.getKey());
}
public static <K, V extends Comparable<? super V>> Comparator<Map.Entry<K,V>> comparingByValue() {
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> c1.getValue().compareTo(c2.getValue());
}
public static <K, V> Comparator<Map.Entry<K, V>> comparingByKey(Comparator<? super K> cmp) {
Objects.requireNonNull(cmp);
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> cmp.compare(c1.getKey(), c2.getKey());
}
public static <K, V> Comparator<Map.Entry<K, V>> comparingByValue(Comparator<? super V> cmp) {
Objects.requireNonNull(cmp);
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> cmp.compare(c1.getValue(), c2.getValue());
}
}
// Comparison and hashing
boolean equals(Object o);
int hashCode();
default V getOrDefault(Object key, V defaultValue) {
V v;
return (((v = get(key)) != null) || containsKey(key))
? v
: defaultValue;
}
default void forEach(BiConsumer<? super K, ? super V> action) {
Objects.requireNonNull(action);
for (Map.Entry<K, V> entry : entrySet()) {
K k;
V v;
try {
k = entry.getKey();
v = entry.getValue();
} catch(IllegalStateException ise) {
// this usually means the entry is no longer in the map.
throw new ConcurrentModificationException(ise);
}
action.accept(k, v);
}
}
default void replaceAll(BiFunction<? super K, ? super V, ? extends V> function) {
Objects.requireNonNull(function);
for (Map.Entry<K, V> entry : entrySet()) {
K k;
V v;
try {
k = entry.getKey();
v = entry.getValue();
} catch(IllegalStateException ise) {
// this usually means the entry is no longer in the map.
throw new ConcurrentModificationException(ise);
}
// ise thrown from function is not a cme.
v = function.apply(k, v);
try {
entry.setValue(v);
} catch(IllegalStateException ise) {
// this usually means the entry is no longer in the map.
throw new ConcurrentModificationException(ise);
}
}
}
default V putIfAbsent(K key, V value) {
V v = get(key);
if (v == null) {
v = put(key, value);
}
return v;
}
default boolean remove(Object key, Object value) {
Object curValue = get(key);
if (!Objects.equals(curValue, value) ||
(curValue == null && !containsKey(key))) {
return false;
}
remove(key);
return true;
}
default boolean replace(K key, V oldValue, V newValue) {
Object curValue = get(key);
if (!Objects.equals(curValue, oldValue) ||
(curValue == null && !containsKey(key))) {
return false;
}
put(key, newValue);
return true;
}
default V replace(K key, V value) {
V curValue;
if (((curValue = get(key)) != null) || containsKey(key)) {
curValue = put(key, value);
}
return curValue;
}
default V computeIfAbsent(K key,
Function<? super K, ? extends V> mappingFunction) {
Objects.requireNonNull(mappingFunction);
V v;
if ((v = get(key)) == null) {
V newValue;
if ((newValue = mappingFunction.apply(key)) != null) {
put(key, newValue);
return newValue;
}
}
return v;
}
default V computeIfPresent(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
Objects.requireNonNull(remappingFunction);
V oldValue;
if ((oldValue = get(key)) != null) {
V newValue = remappingFunction.apply(key, oldValue);
if (newValue != null) {
put(key, newValue);
return newValue;
} else {
remove(key);
return null;
}
} else {
return null;
}
}
default V compute(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
Objects.requireNonNull(remappingFunction);
V oldValue = get(key);
V newValue = remappingFunction.apply(key, oldValue);
if (newValue == null) {
// delete mapping
if (oldValue != null || containsKey(key)) {
// something to remove
remove(key);
return null;
} else {
// nothing to do. Leave things as they were.
return null;
}
} else {
// add or replace old mapping
put(key, newValue);
return newValue;
}
}
default V merge(K key, V value,
BiFunction<? super V, ? super V, ? extends V> remappingFunction) {
Objects.requireNonNull(remappingFunction);
Objects.requireNonNull(value);
V oldValue = get(key);
V newValue = (oldValue == null) ? value :
remappingFunction.apply(oldValue, value);
if(newValue == null) {
remove(key);
} else {
put(key, newValue);
}
return newValue;
}
}Map接口本身就是一个顶层接口,由一堆Map自身接口方法和一个Entry接口组成,Entry接口定义了主要是关于Key-Value自身的一些操作,Map接口定义的是一些属性和关于属性查找修改的一些接口方法。
5.2 HashMap
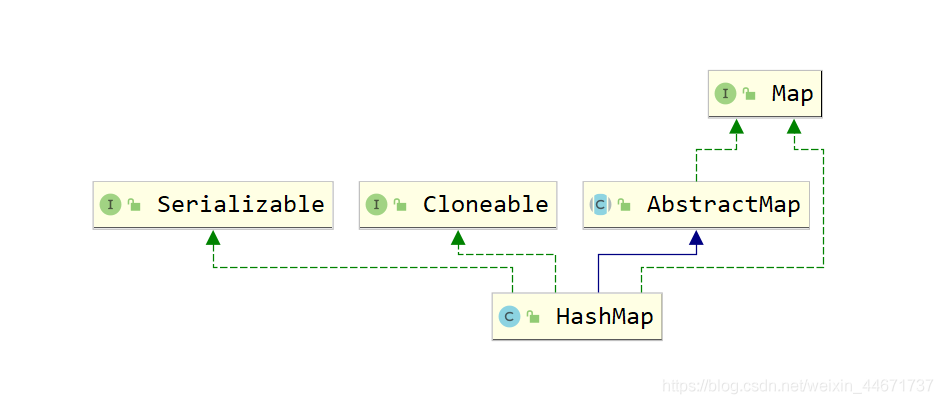
5.2.1 HashMap继承关系
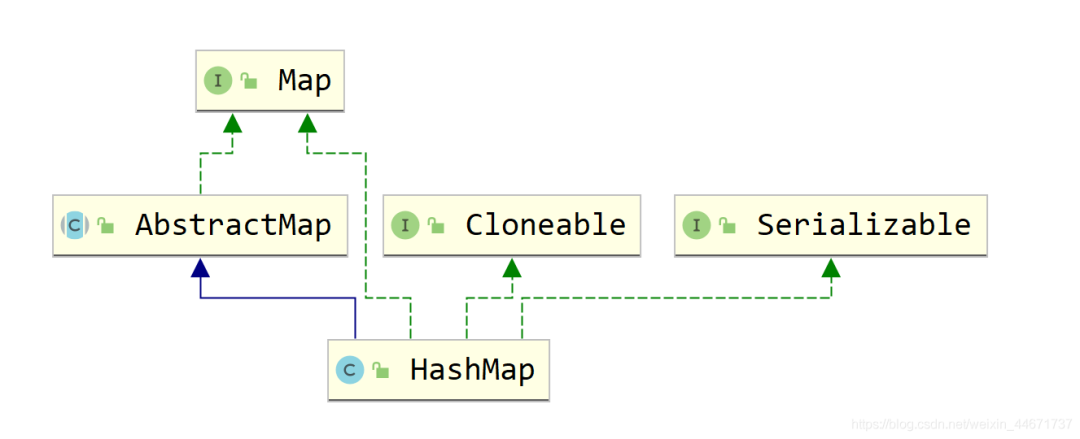
5.2.2 HashMap存储的数据
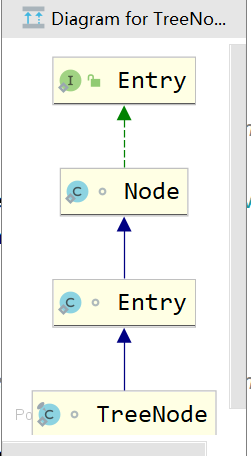
Map接口中有一个Entry接口,在HashMap中对其进行了实现,Entry的实现是HashMap存放的数据的类型。其中Entry在HashMap的实现是Node,Node是一个单链表的结构,TreeNode是其子类,是一个红黑树的类型,其继承结构图如下:
HashMap存放数据的数据是什么呢?代码中存放数据的容器如下:
transient Node<K,V>[] table;
5.2.3 HashMap的组成
//是hashMap的最小容量16,容量就是数组的大小也就是变量,transient Node<K,V>[] table。
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
//最大数量,该数组最大值为2^31一次方。
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认的加载因子,如果构造的时候不传则为0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//一个位置里存放的节点转化成树的阈值,也就是8,比如数组里有一个node,这个
// node链表的长度达到该值才会转化为红黑树。
static final int TREEIFY_THRESHOLD = 8;
//当一个反树化的阈值,当这个node长度减少到该值就会从树转化成链表
static final int UNTREEIFY_THRESHOLD = 6;
//满足节点变成树的另一个条件,就是存放node的数组长度要达到64
static final int MIN_TREEIFY_CAPACITY = 64;
//具体存放数据的数组
transient Node<K,V>[] table;
//entrySet,一个存放k-v缓冲区
transient Set<Map.Entry<K,V>> entrySet;
//size是指hashMap中存放了多少个键值对
transient int size;
//对map的修改次数
transient int modCount;
//加载因子
final float loadFactor;5.2.4 HashMap中的构造函数
//只有容量,initialCapacity
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
if (table == null) { // pre-size
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
if (t > threshold)
threshold = tableSizeFor(t);
}
else if (s > threshold)
resize();
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0) // 容量不能为负数
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
//当容量大于2^31就取最大值1<<31;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
//当前数组table的大小,一定是是2的幂次方
// tableSizeFor保证了数组一定是是2的幂次方,是大于initialCapacity最结进的值。
this.threshold = tableSizeFor(initialCapacity);
}tableSizeFor()方法保证了数组大小一定是是2的幂次方,是如何实现的呢?
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}5.2.5 put方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//当hash到的位置,该位置为null的时候,存放一个新node放入
// 这儿p赋值成了table该位置的node值
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//该位置第一个就是查找到的值,将p赋给e
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//如果是红黑树,调用红黑树的putTreeVal方法
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//是链表,遍历,注意e = p.next这个一直将下一节点赋值给e,直到尾部,注意开头是++binCount
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//当链表长度大于等于7,插入第8位,树化
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}5.2.6 查找方法
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
//先判断表不为空
if ((tab = table) != null && (n = tab.length) > 0 &&
//这一行是找到要查询的Key在table中的位置,table是存放HashMap中每一个Node的数组。
(first = tab[(n - 1) & hash]) != null) {
//Node可能是一个链表或者树,先判断根节点是否是要查询的key,就是根节点,方便后续遍历Node写法并且
//对于只有根节点的Node直接判断
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
//有子节点
if ((e = first.next) != null) {
//红黑树查找
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
//链表查找
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
//遍历链表,当链表后续为null则推出循环
while ((e = e.next) != null);
}
}
return null;
}5.3 HashTable
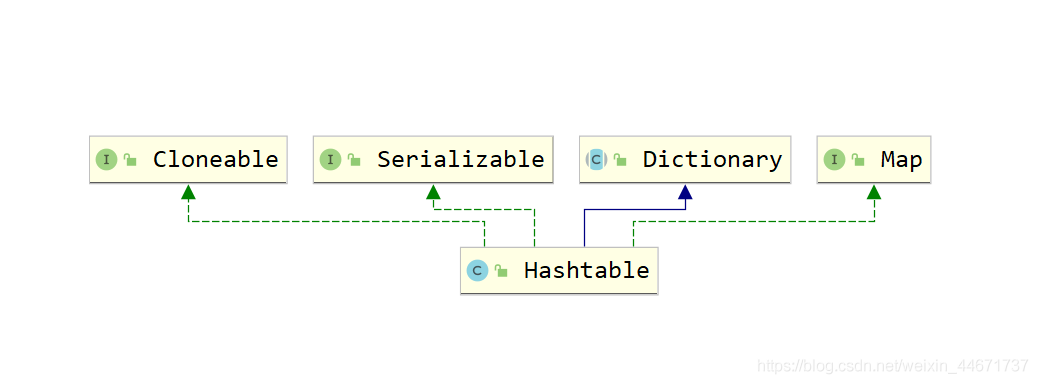
5.3.1 HashTable的类继承关系图
HashTable
public abstract
class Dictionary<K,V> {
public Dictionary() {
}
public abstract int size();
public abstract boolean isEmpty();
public abstract Enumeration<K> keys();
public abstract Enumeration<V> elements();
public abstract V get(Object key);
public abstract V put(K key, V value);
public abstract V remove(Object key);
}//throws NullPointerException if the {@code key} is {@code null}.5.3.3 HashTable组成
/**
* The hash table data.
* 真正存放数据的数组
*/
private transient Entry<?,?>[] table;
/**
* The total number of entries in the hash table.
*/
private transient int count;
/**
* The table is rehashed when its size exceeds this threshold. (The
* value of this field is (int)(capacity * loadFactor).)
* 重新hash的阈值
* @serial
*/
private int threshold;
/**
* The load factor for the hashtable.
* @serial
*/
private float loadFactor;5.3.4 HashTable中的Entry
final int hash;
final K key;
V value;
Entry<K,V> next;知道Entry是一个单链表即可,和HashMap中的Node结构相同,但是HashMap中还有Node的子类TreeNode。
5.3.5 put方法
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
//在数组中的位置 0x7fffffff 是31位二进制1
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
//如果遍历链表找到了则替换旧值并返回
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}本质上就是先hash求索引,遍历该索引Entry链表,如果找到hash值和key都和put的key一样的时候就替换旧值,否则使用addEntry方法添加新值进入table,因为添加新元素就涉及到修改元素大小,还可能需要扩容等,具体看下边的addEntry方法可知。
private void addEntry(int hash, K key, V value, int index) {
Entry<?,?> tab[] = table;
//如果扩容需要重新计算hash,所以index和table都会被修改
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>) tab[index];
//插入新元素
tab[index] = new Entry<>(hash, key, value, e);
count++;
modCount++;
}tab[index] = new Entry<>(hash, key, value, e);5.3.6 get方法
@SuppressWarnings("unchecked")
public synchronized V get(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}get方法就简单很多就是hash,找到索引,遍历链表找到对应的value,没有则返回null。相比诸君都已经看到,HashTable中方法是用synchronized修饰的,所以其操作是线程安全的,但是效率会受影响。

胖虎联合一线大厂朋友花费8个月的时间,录制了一份Java入门+进阶视频教程
课程特色:
总共88G,时常高达365小时,覆盖所有主流技术栈
均为同一人录制,不是东拼西凑的
对标线下T0级别的培训课,讲师大厂架构师,多年授课经验,通俗易懂
内容丰富,每一个技术点除了视频,还有课堂源码、笔记、PPT、图解
五大实战项目(视频+源码+笔记+SQL+软件)
一次付费,持续更新,永无二次费用
点击下方超链接查看详情 (或者点击文末阅读原文):
(或者点击文末阅读原文):