
从留存率业务案例谈0-1的数据指标体系
背景
大家好,我是宝器!
经常会听到互联网人形容一个产品的体量和知名度用活跃用户来衡量,比如:“微信的日活接近10亿了,真社交巨兽。”
这里面有个几个关键的词:衡量、日、活跃、用户。这些综合起来是什么,DAU。对于分析师来说,这是一个可反应业务产品活跃用户现状的一个指标。
这样思考下去你可能会问想知道:
指标是什么?
按照比较官方的定义是在一定条件和时间下反应某种现象的规模和比例,由指标名称和数值构成。
实际上是不是所有的这种反应某种现象和规模的数据都可以叫做指标呢?我觉得不是,因为不是所有这样的数据都是对业务有参考价值的。
张涛老师的说法个人较为认可:对当前业务有参考价值的可统计的数据可以是指标,它是可以反应哪个用户做了哪些行为,给业务带来了什么样的结果指标[1]。
所以常用的数据指标可以分成:用户数据(新增、日活、留存等);行为数据(访问深度、转化率等);业务数据(一般会和用户数据指标和行为数据指标有些交叉,反应的是业务大盘的情况,比如GMV、ARPU值等)。
使用这些指标的注意和坑
假如你是一名分析师吗,可能你会遇到这样的场景,”同一个指标“不同的人可能也得到不一样的结果:
比如产品经理A说的本月的留存率是20%,产品经理B说本月的留存是24%,那到底谁是对的,为什么他们计算的结果会不一样?
其实没有绝对的对错,只是A和B对这些数据指标背后的定义和口径是不一致的。但后续分析过程中一定要注意形成统一明确的数据指标定义,这样才能去做后续的分析,不然后续的对比结果可能也是错的。
留存率的案例
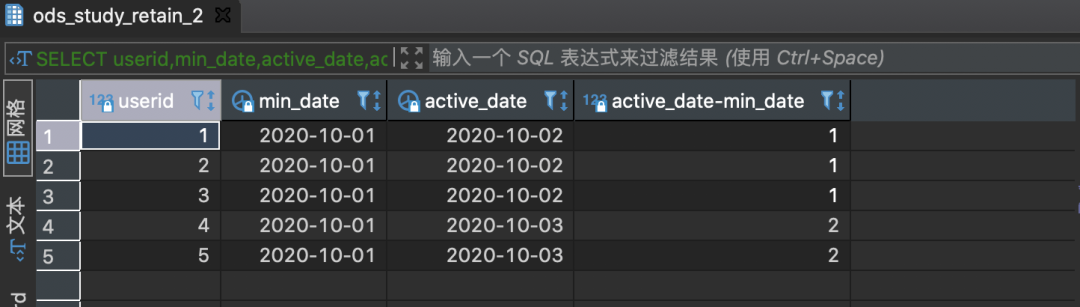
某高质量用户产品在2020年国庆节那一天(10月1日)开始试运营,那天通过拉新来了5位用户,国庆节过完来,老板想知道10月1日这波拉新用户的7日留存率。
Fake数据表
CREATE TABLE ods_study_1.ods_study_retain_1
(
userid int,
min_date DATE,
active_date DATE
);
INSERT INTO ods_study_1.ods_study_retain_2(userid,min_date,active_date) VALUES(1,'2020-10-01','2020-10-02'),(2,'2020-10-01','2020-10-02'),(3,'2020-10-01','2020-10-02'),(4,'2020-10-01','2020-10-03'),(5,'2020-10-01','2020-10-03')
查看下数据
SELECT userid,min_date,active_date,active_date-min_date FROM ods_study_1.ods_study_retain_2
国庆后,产品经理A汇报说,“老板,我们这次7日留存下来的用户是0,7日留存率0,效果非常不好,不可以继续投放拉新了
SELECT
min_date,
COUNT(CASE WHEN (active_date-min_date) = 6 THEN userid ELSE NULL END ) restay_num,
COUNT(DISTINCT userid) all_num
FROM
ods_study_1.ods_study_retain_2
GROUP BY
min_date;

国庆后,产品经理B汇报说,“老板,我们这次7日留存下来的用户是5,7日留存率是100%,效果非常好,可以继续投放拉新”。
SELECT
min_date,
COUNT(CASE WHEN (active_date-min_date) <= 6 THEN userid ELSE NULL END ) restay_num,
COUNT(DISTINCT userid) all_num
FROM
ods_study_1.ods_study_retain_2
GROUP BY
min_date;

老板非常疑惑,你们怎么回事,怎么得出的结论正好相反?
产品经理B看了看A的计算逻辑,给A说,兄弟,我们这款产品具有周期性,当时调研的时候就反馈了用户一般只会在每个月的2号和3号有时间去使用这款产品。
所以你不能计算10月1日之后的第7日还剩下多少人活跃,要计算10月2日-10月7日之间一共有多少用户在活跃。
这个小案例其实反馈的就是业务线对指标定义不一致计算得到不同的结果,一个是7日日留存,一个是7日内留存。
数据指标体系的构建
所以指标准确的定义是产品、运营、数据等团队做分析必要的前提,且在每个分析师心中都有一套完整的数据指标体系。指标是单一的,指标体系是完整的,是可以表示业务之间的相关性和结构性。
一个优质的数据指标体系可以反应出:发生了什么?为什么这件事会发生?这样持续下去未来可能会发生什么?我们应该根据这些做些什么?

这一块涉及的内容较多,一篇文章应该讲不完整,这次简单分享下。分析师构建一套完整的指标体系搭建步骤和所需合作同事:
明确产品各业务线目的(相关业务线产品经理出) 明确指标体系的建设规划模型方案(分析师和相关业务线的产品经理拉通统一) 明确指标对应的埋点和存储逻辑(各业务线产品经理和埋点研发人员) 梳理指标的准确性,取数校验(分析师) 指标跌倒更新和删减(分析师和产品经理) 数据指标体系平台建设和迭代(分析师、产品、研发)
步骤2的规划模型方案思路这一块建议阅读GrowingIO发布的那本小册子《指标体系与数据采集》[2],写的比较清晰。
参考资料
张涛: 神策数据副总裁
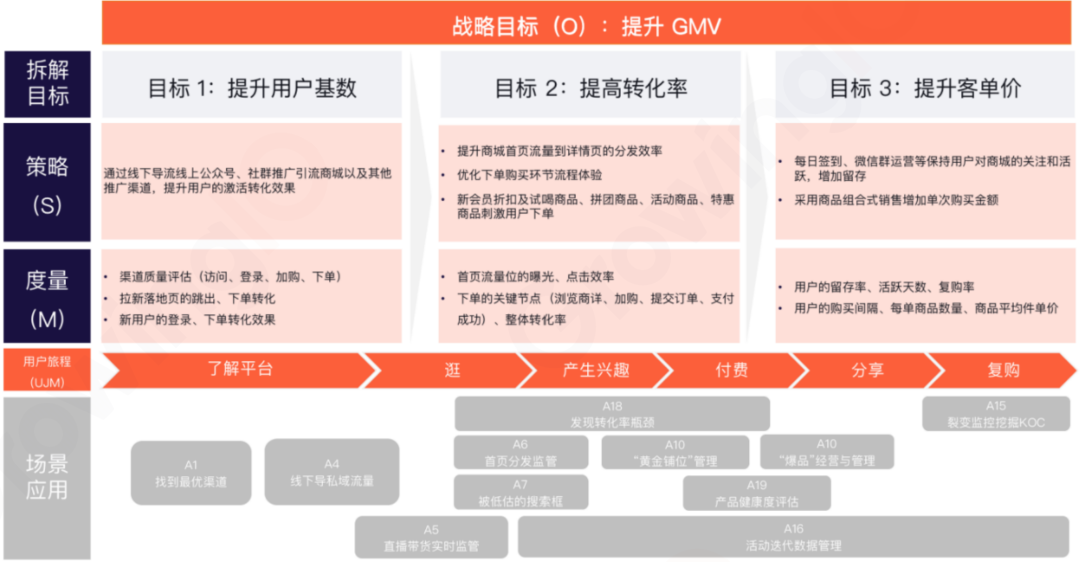
[2]GrowingIO,《指标体系与数据采集》: 某电商产品基于OSM和UJM相结合的指标体系构建全景图
写在最后
之前那篇文章:写给所有数据人,文末宝器说会分享数据指标体系的一些个人认知内容,今天算是这部分的内容一点开始,更多敬请期待。
因个人知识和时间都有限,也深知现在关注宝器的业界朋友越来越多,写文会会更严谨(这篇文章从构思、写作、表述、删改、排版一共写了6小时,所以不能保正日更新原创),文中观点不一定完全正确,不当之处,还请各位兄弟萌多一些理解。
我是宝器,毕业于成都七中附属大学,一个不知名分析师,一个为终极目标而不断努力的打工人。
秘籍:后台回顾【数据分析体系】,下载 GrowingIO 出品的这本《指标体系与数据采集》,攀升“王者”段位
往期精彩: