
一文看懂eBPF|eBPF实现原理
在上一篇文章中,我们主要简单介绍了什么是 eBPF 和 eBPF 的简单使用,而本文重点介绍 eBPF 的实现原理。
在介绍 eBPF 的实现原理前,我们先来回顾一下 eBPF 的架构图:
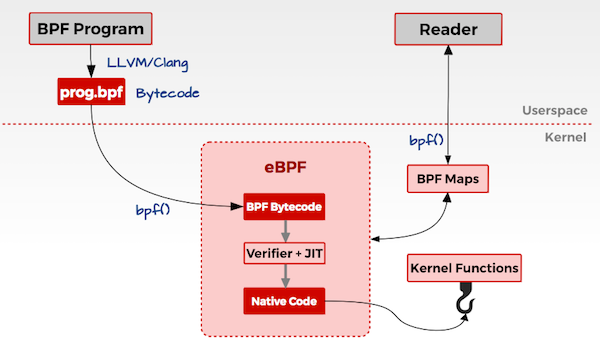
这幅图对理解 eBPF 实现原理有非常大的作用,在分析 eBPF 实现原理时,要经常参照这幅图来进行分析。
eBPF虚拟机
其实我不太想介绍 eBPF 虚拟机的,因为一般来说很少会用到 eBPF 汇编来写程序。但是,不介绍 eBPF 虚拟机的话,又不能说清 eBPF 的原理。
所以,还是先简单介绍一下 eBPF 虚拟机的原理,这样对分析 eBPF 实现有很大的帮助。
eBPF汇编
eBPF 本质上是一个虚拟机(Virtual Machine),可以执行 eBPF 字节码。
用户可以使用 eBPF 汇编或者 C 语言来编写程序,然后编译成 eBPF 字节码,再由 eBPF 虚拟机执行。
什么是虚拟机?
官方的解释是:虚拟机(VM)是一种创建于物理硬件系统(位于外部或内部)、充当虚拟计算机系统的虚拟环境,它模拟出了自己的整套硬件,包括 CPU、内存、网络接口和存储器。通过名为虚拟机监控程序的软件,用户可以将机器的资源与硬件分开并进行适当设置,以供虚拟机使用。
通俗的解释:虚拟机就是模拟计算机的运行环境,你可以把它当成是一台虚拟出来的计算机。
计算机的最本质功能就是执行代码,所以 eBPF 虚拟机也一样,可以运行 eBPF 字节码。
用户编写的 eBPF 程序最终会被编译成 eBPF 字节码,eBPF 字节码使用 bpf_insn 结构来表示,如下:
struct bpf_insn {
__u8 code; // 操作码
__u8 dst_reg:4; // 目标寄存器
__u8 src_reg:4; // 源寄存器
__s16 off; // 偏移量
__s32 imm; // 立即操作数
};
下面介绍一下 bpf_insn 结构各个字段的作用:
code:指令操作码,如 mov、add 等。dst_reg:目标寄存器,用于指定要操作哪个寄存器。src_reg:源寄存器,用于指定数据来源于哪个寄存器。off:偏移量,用于指定某个结构体的成员。imm:立即操作数,当数据是一个常数时,直接在这里指定。
eBPF 程序会被 LLVM/Clang 编译成 bpf_insn 结构数组,当内核要执行 eBPF 字节码时,会调用 __bpf_prog_run() 函数来执行。
如果开启了 JIT(即时编译技术),内核会将 eBPF 字节码编译成本地机器码(Native Code)。这样就可以直接执行,而不需要虚拟机来执行。
关于 eBPF 汇编相关的知识点可以参考《eBPF汇编指令介绍》,这里就不作深入的分析,我们只需要记住 eBPF 程序会被编译成 eBPF 字节码即可。
eBPF虚拟机
eBPF 虚拟机的作用就是执行 eBPF 字节码,eBPF 虚拟机比较简单(只有300行代码左右),由 __bpf_prog_run() 函数实现。
通用虚拟机因为要模拟真实的计算机,所以通常来说实现比较复杂(如Qemu、Virtual Box等)。
但像 eBPF 虚拟机这种用于特定功能的虚拟机,由于只需要模拟计算机的小部分功能,所以实现通常比较简单。
eBPF 虚拟机的运行环境只有 1 个 512KB 的栈和 11 个寄存器(还有一个 PC 寄存器,用于指向当前正在执行的 eBPF 字节码)。如下图所示:
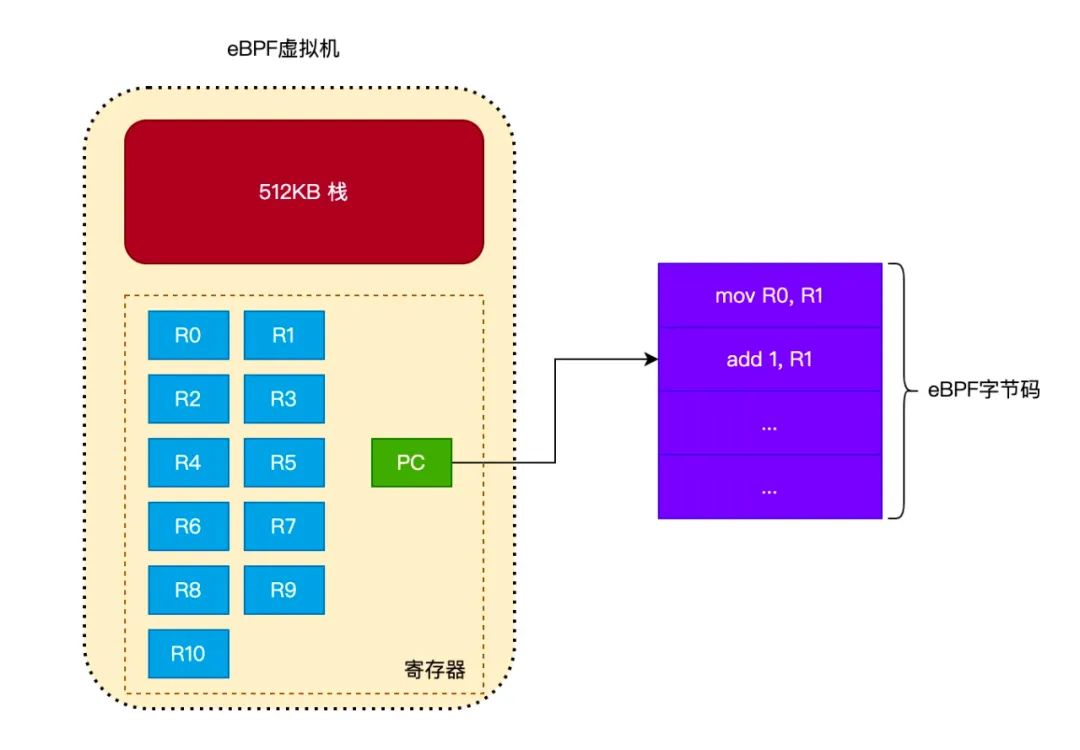
如果内核支持 JIT(Just In Time)运行模式,那么内核将会把 eBPF 字节码编译成本地机器码,这时可以直接运行这些机器码,而不需要使用虚拟机来运行。
可以通过以下命令打开 JIT 运行模式:
$ echo 1 > /proc/sys/net/core/bpf_jit_enable
将 C 程序编译成 eBPF 字节码
由于使用 eBPF 汇编编写程序比较麻烦,所以 eBPF 提供了功能受限的 C 语言来编写 eBPF 程序,并且可以使用 Clang/LLVM 将 C 程序编译成 eBPF 字节码。
使用 Clang 编译 eBPF 程序时,需要加上 -target bpf 参数才能编译成功。
下面我们用一个简单的例子来介绍怎么使用 Clang 编译 eBPF 程序,我们新建一个文件 hello.c 并且输入以下代码:
#include
static int (*bpf_trace_printk)(const char *fmt, int fmtsize, ...)
= (void *)BPF_FUNC_trace_printk;
int hello_world(void *ctx)
{
char msg[] = "Hello World\n";
bpf_trace_printk(msg, sizeof(msg)-1);
return 0;
}
然后我们使用以下命令编译程序:
$ clang -target bpf -Wall -O2 -c hello.c -o hello.o
编译后会得到一个名为 hello.o 的文件,我们可以通过下面命令来看到编译后的字节码:
$ readelf -x .text hello.o
Hex dump of section '.text':
0x00000000 18010000 00000000 00000000 00000000 ................
0x00000010 b7020000 0c000000 85000000 06000000 ................
0x00000020 b7000000 00000000 95000000 00000000 ................
由于编译出来的字节码是二进制的,不利于人类查阅。所以,可以通过以下命令将 eBPF 程序编译成 eBPF 汇编代码:
$ clang -target bpf -S -o hello.s hello.c
编译后会得到一个名为 hello.s 的文件,我们可以使用文本编辑器来查看其汇编代码:
...
hello_world:
*(u64 *)(r10 - 8) = r1 # 把r1的值保存到栈
r1 = bpf_trace_printk ll #
r1 = *(u64 *)(r1 + 0) # r1赋值为 bpf_trace_printk 函数地址
r2 = .L.str ll # r2赋值为 "Hello World\n"
r3 = 12 # r3赋值为12
*(u64 *)(r10 - 16) = r1 # 把r1的值保存到栈
r1 = r2 # 调用 bpf_trace_printk 函数的参数1
r2 = r3 # 调用 bpf_trace_printk 函数的参数2
r3 = *(u64 *)(r10 - 16) # 获取 bpf_trace_printk 函数地址
callx r3 # 调用 bpf_trace_printk 函数
r1 = 0 # r1赋值为0
*(u64 *)(r10 - 24) = r0 # 把r0的值保存到栈
r0 = r1 # 返回0
exit # 退出eBPF程序
...
eBPF 虚拟机的规范:
寄存器
r1-r5:作为函数调用参数使用。在 eBPF 程序启动时,寄存器r1包含 "上下文" 参数指针。寄存器
r0:存储函数的返回值,包括函数调用和当前程序退出。寄存器
r10:eBPF程序的栈指针。
eBPF 加载器
eBPF 程序是由用户编写的,编译成 eBPF 字节码后,需要加载到内核才能被内核使用。
用户态可以通过调用 sys_bpf() 系统调用把 eBPF 程序加载到内核,而 sys_bpf() 系统调用会通过调用 bpf_prog_load() 内核函数加载 eBPF 程序。
我们来看看 bpf_prog_load() 函数的实现(经过精简后):
static int bpf_prog_load(union bpf_attr *attr)
{
enum bpf_prog_type type = attr->prog_type;
struct bpf_prog *prog;
int err;
...
// 创建 bpf_prog 对象,用于保存 eBPF 字节码和相关信息
prog = bpf_prog_alloc(bpf_prog_size(attr->insn_cnt), GFP_USER);
...
prog->len = attr->insn_cnt; // eBPF 字节码长度(也就是有多少条 eBPF 字节码)
err = -EFAULT;
// 把 eBPF 字节码从用户态复制到 bpf_prog 对象中
if (copy_from_user(prog->insns, u64_to_ptr(attr->insns),
prog->len * sizeof(struct bpf_insn)) != 0)
goto free_prog;
...
// 这里主要找到特定模块的相关处理函数(如修正helper函数)
err = find_prog_type(type, prog);
// 检查 eBPF 字节码是否合法
err = bpf_check(&prog, attr);
// 修正helper函数的偏移量
fixup_bpf_calls(prog);
// 尝试将 eBPF 字节码编译成本地机器码(JIT模式)
err = bpf_prog_select_runtime(prog);
// 申请一个文件句柄用于与 bpf_prog 对象关联
err = bpf_prog_new_fd(prog);
return err;
...
}
bpf_prog_load() 函数主要完成以下几个工作:
- 创建一个
bpf_prog对象,用于保存 eBPF 字节码和 eBPF 程序的相关信息。 - 把 eBPF 字节码从用户态复制到
bpf_prog对象的insns成员中,insns成员是一个类型为bpf_insn结构的数组。 - 根据 eBPF 程序所属的类型(如
socket、kprobes或xdp等),找到其相关处理函数(如helper函数对应的修正函数,下面会介绍)。 - 检查 eBPF 字节码是否合法。由于 eBPF 程序运行在内核态,所以要保证其安全性,否则将会导致内核崩溃。
- 修正
helper函数的偏移量(下面会介绍)。 - 尝试将 eBPF 字节码编译成本地机器码,主要为了提高 eBPF 程序的执行效率。
- 申请一个文件句柄用于与
bpf_prog对象关联,这个文件句柄将会返回给用户态,用户态可以通过这个文件句柄来读取内核中的 eBPF 程序。
修正 helper 函数
helper 函数是 eBPF 提供给用户使用的一些辅助函数。
由于 eBPF 程序运行在内核态,所为了安全,eBPF 程序中不能随意调用内核函数,只能调用 eBPF 提供的辅助函数(helper functions)。
调用 eBPF 的 helper 函数与调用普通的函数并不一样,调用 helper 函数时并不是直接调用的,而是通过 helper 函数的编号来进行调用。
每个 eBPF 的 helper 函数都有一个编号(通过枚举类型 bpf_func_id 来定义),定义在 include/uapi/linux/bpf.h 文件中,定义如下(只列出一部分):
enum bpf_func_id {
BPF_FUNC_unspec, // 0
BPF_FUNC_map_lookup_elem, // 1
BPF_FUNC_map_update_elem, // 2
BPF_FUNC_map_delete_elem, // 3
BPF_FUNC_probe_read, // 4
BPF_FUNC_ktime_get_ns, // 5
BPF_FUNC_trace_printk, // 6
BPF_FUNC_get_prandom_u32, // 7
BPF_FUNC_get_smp_processor_id, // 8
BPF_FUNC_skb_store_bytes, // 9
BPF_FUNC_l3_csum_replace, // 10
BPF_FUNC_l4_csum_replace, // 11
BPF_FUNC_tail_call, // 12
BPF_FUNC_clone_redirect, // 13
BPF_FUNC_get_current_pid_tgid, // 14
BPF_FUNC_get_current_uid_gid, // 15
...
__BPF_FUNC_MAX_ID,
};
下面我们来看看在 eBPF 程序中怎么调用 helper 函数:
#include
// 声明要调用的helper函数为:BPF_FUNC_trace_printk
static int (*bpf_trace_printk)(const char *fmt, int fmtsize, ...)
= (void *)BPF_FUNC_trace_printk;
int hello_world(void *ctx)
{
char msg[] = "Hello World\n";
// 调用helper函数
bpf_trace_printk(msg, sizeof(msg)-1);
return 0;
}
从上面的代码可以知道,当要调用 helper 函数时,需要先定义一个函数指针,并且将函数指针赋值为 helper 函数的编号,然后才能调用这个 helper 函数。
定义函数指针的原因是:指定调用函数时的参数。
所以,调用的 helper 函数其实并不是真实的函数地址。那么内核是怎么找到真实的 helper 函数地址呢?
这里就是通过上面说的修正 helper 函数来实现的。
在介绍加载 eBPF 程序时说过,加载器会通过调用 fixup_bpf_calls() 函数来修正 helper 函数的地址。我们来看看 fixup_bpf_calls() 函数的实现:
static void fixup_bpf_calls(struct bpf_prog *prog)
{
const struct bpf_func_proto *fn;
int i;
// 遍历所有的 eBPF 字节码
for (i = 0; i < prog->len; i++) {
struct bpf_insn *insn = &prog->insnsi[i];
// 如果是函数调用指令
if (insn->code == (BPF_JMP | BPF_CALL)) {
...
// 通过 helper 函数的编号获取其真实地址
fn = prog->aux->ops->get_func_proto(insn->imm);
...
// 由于 bpf_insn 结构的 imm 字段类型为 int,
// 为了能够将 helper 函数的地址(64位)保存到一个 int 中,
// 所以减去一个基础函数地址,调用的时候加上这个基础函数地址即可。
insn->imm = fn->func - __bpf_call_base;
}
}
}
fixup_bpf_calls() 函数主要完成修正 helper 函数的地址,其工作原理如下:
- 遍历 eBPF 程序的所有字节码。
- 如果字节码指令是一个函数调用,那么将进行函数地址修正,修正过程如下:
- 根据
helper函数的编号获取其真实的函数地址。 - 将
helper函数的真实地址减去__bpf_call_base函数的地址,并且保存到字节码的imm字段中。
从上面修正 helper 函数地址的过程可知,当调用 helper 函数时需要加上 __bpf_call_base 函数的地址。
eBPF 程序运行时机
上面介绍了 eBPF 程序的运行机制,现在来说说内核什么时候执行 eBPF 程序。
在《eBPF的简单使用》一文中介绍过,eBPF 程序需要挂载到某个内核路径(挂在点)才能被执行。
根据挂载点功能的不同,大概可以分为以下几个模块:
- 性能跟踪(kprobes/uprobes/tracepoints)
- 网络(socket/xdp)
- 容器(cgroup)
- 安全(seccomp)
比如要将 eBPF 程序挂载在 socket(套接字) 上,可以使用 setsockopt() 函数来实现,代码如下:
setsockopt(sock, SOL_SOCKET, SO_ATTACH_BPF, &prog_fd, sizeof(prog_fd));
下面说说 setsockopt() 函数各个参数的意义:
- sock:要挂载 eBPF 程序的 socket 句柄。
- SOL_SOCKET:设置的选项的级别,如果想要在套接字级别上设置选项,就必须设置为
SOL_SOCKET。 - SO_ATTACH_BPF:表示挂载 eBPF 程序到 socket 上。
- prog_fd:通过调用
bpf()系统调用加载 eBPF 程序到内核后返回的文件句柄。
通过上面的代码,就能将 eBPF 程序挂载到 socket 上,当 socket 接收到数据包时,将会执行这个 eBPF 程序对数据包进行过滤。
我们看看当 socket 接收到数据包时的操作:
// file: net/packet/af_packet.c
static int
packet_rcv(struct sk_buff *skb,
struct net_device *dev,
struct packet_type *pt,
struct net_device *orig_dev)
{
...
// 执行 eBPF 程序
res = run_filter(skb, sk, snaplen);
if (!res)
goto drop_n_restore;
...
}
当 socket 接收到数据包时,会调用 run_filter() 函数执行 eBPF 程序。
总结
本文主要介绍了 eBPF 的实现原理,当然本文只是按大体思路去分析,有很多细节需要读者自己阅读源码来了解。
下篇文章将会介绍 kprobes 是怎么结合 eBPF 进行内核函数追踪的。