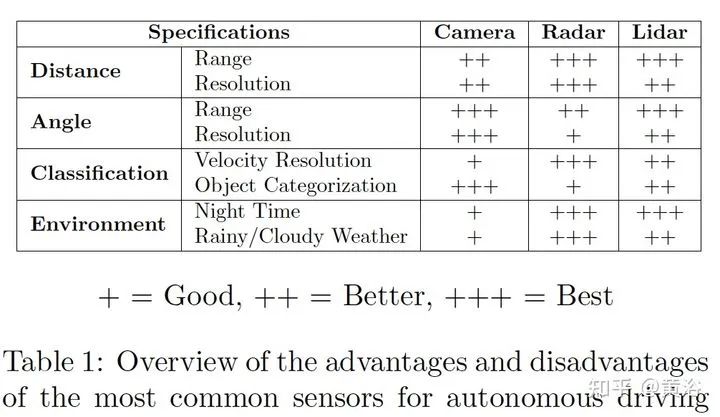
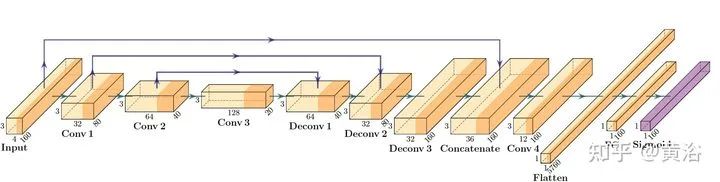
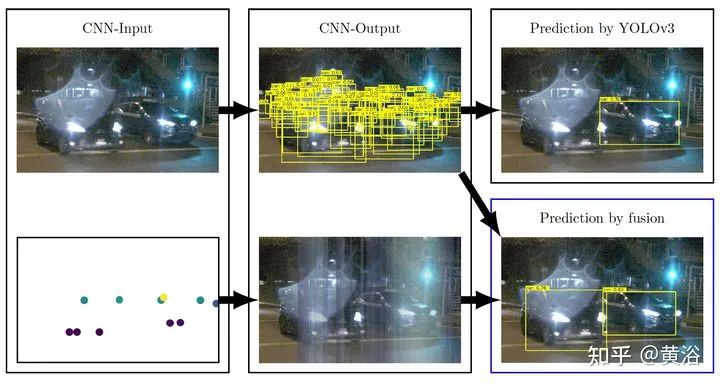
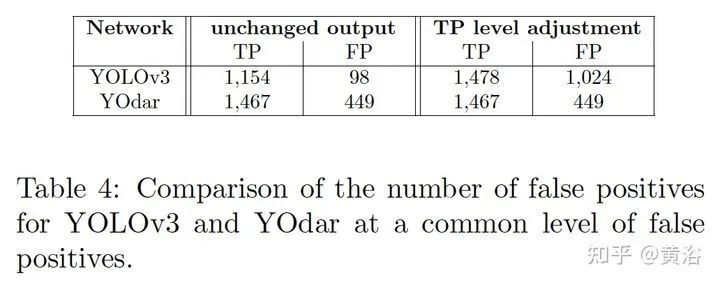
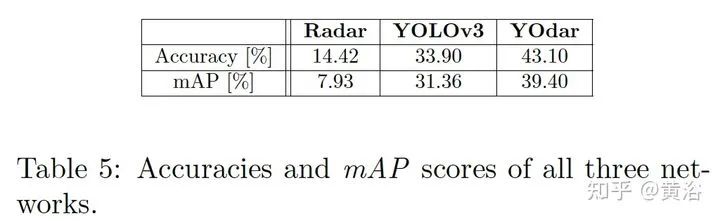
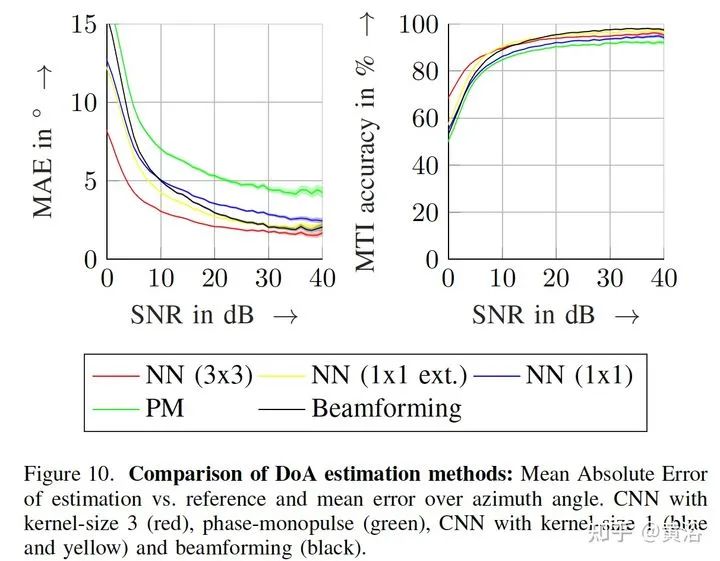
关于传感器融合,特别是摄像头、激光雷达和雷达的前融合和和特征融合,是一个引人注意的方向。 1 “YOdar: Uncertainty-based Sensor Fusion for Vehicle Detection with Camera and Radar Sensors“, 11,2020 基于不确定性的融合方法。后处理采用gradient boosting,视觉来自YOLOv3,雷达来自1D segmentation network。 FCN-8 inspired radar network Image of a radar detection example with four predicted slice bundles YOdar
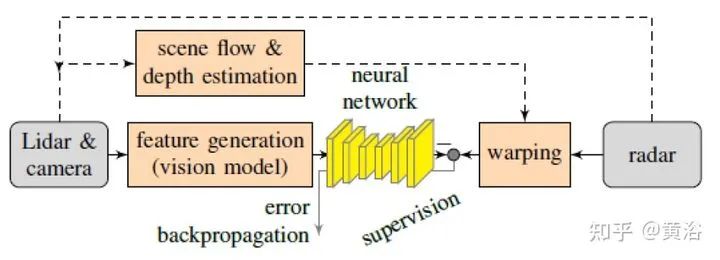
2 “Warping of Radar Data into Camera Image for Cross-Modal Supervision in Automotive Applications”,12,2020
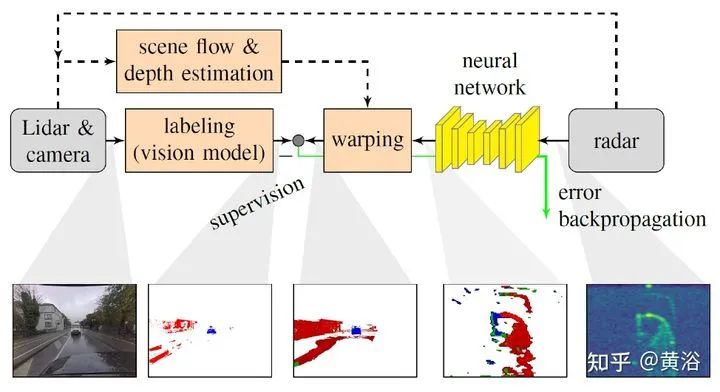
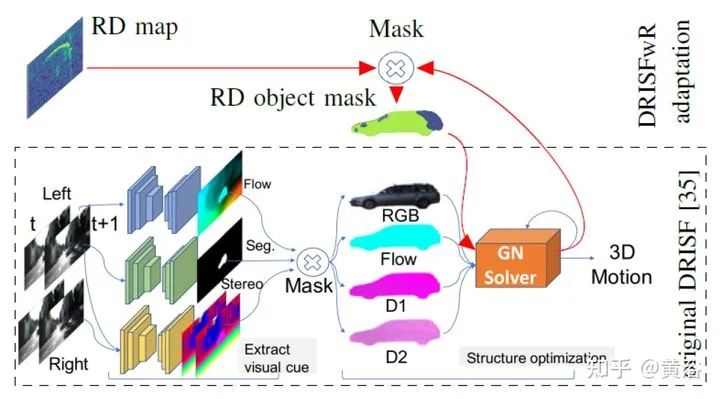
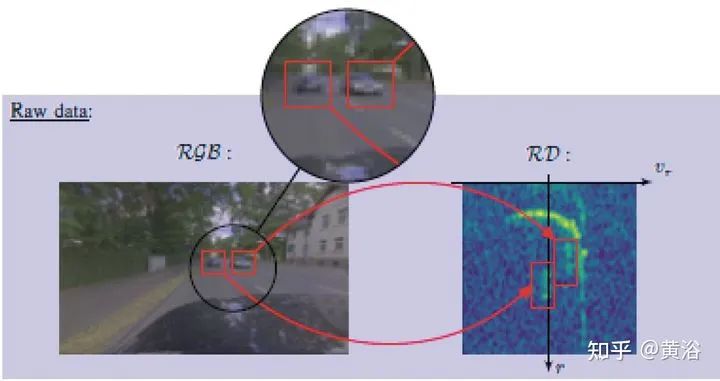
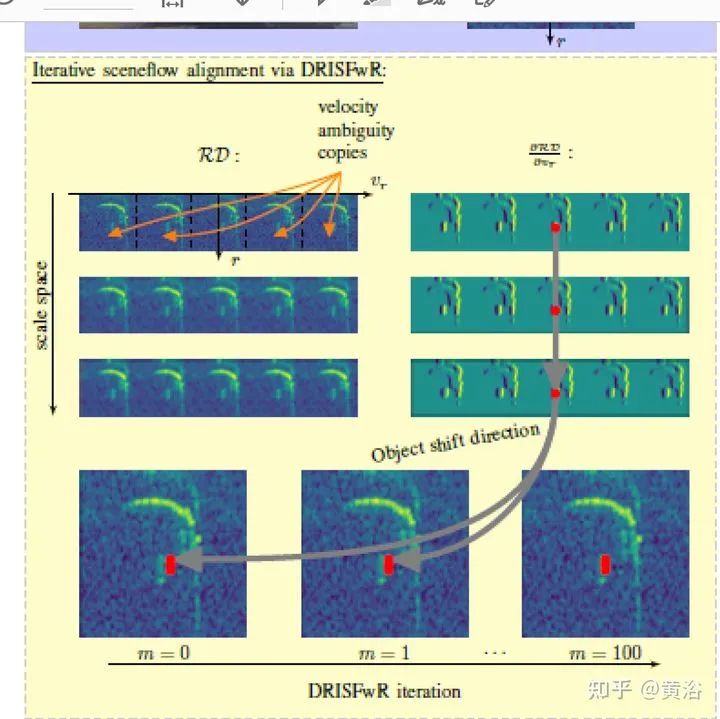
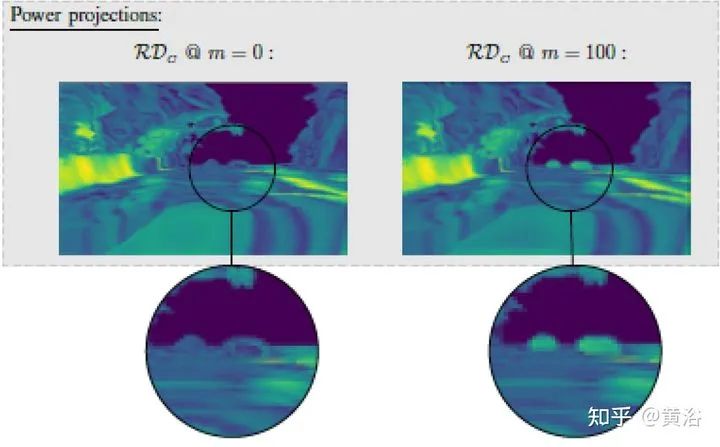
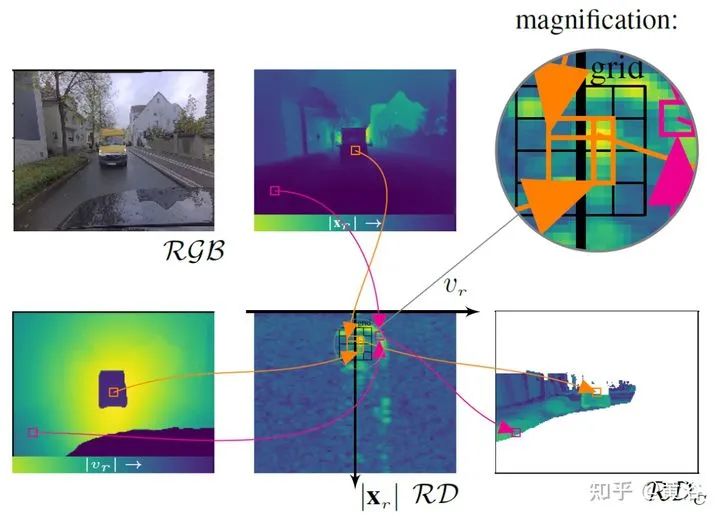
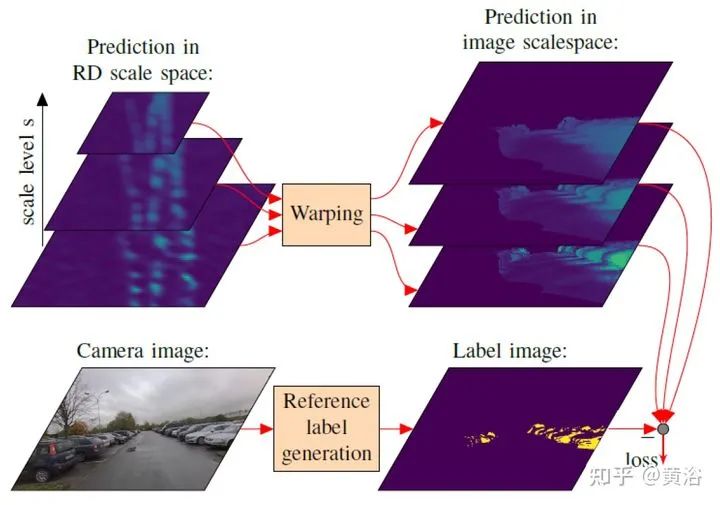
将雷达的range-Doppler (RD) spectrum投射到摄像头平面。由于设计的warping函数可微分,所以在训练框架下做BP。该warping操作依赖于环境精确的scene flow,故提出一个来自激光雷达、摄像头和雷达的scene flow估计方法,以提高warping操作精度。实验应用涉及了direction-of-arrival (DoA) estimation, target detection, semantic segmentation 和 estimation of radar power from camera data等。 model pipeline DRISFwR overview (deep rigid instance scene flow with radar) Automatic scene flow alignment to Radar data via DRISFwR: RGB image and RD-map with two vehicles Scale-space of radar data used in DRISFwR with energy & partial derivative Power projections RD-map warping into camera image: Loss in scale-space: 最后实验结果比较: Qualitative results of target detection on test data examples Qualitative results of semantic segmentation on test data examples Overview of the model pipeline for camera based estimators for NN training: Qualitative results of SNR prediction on test data:
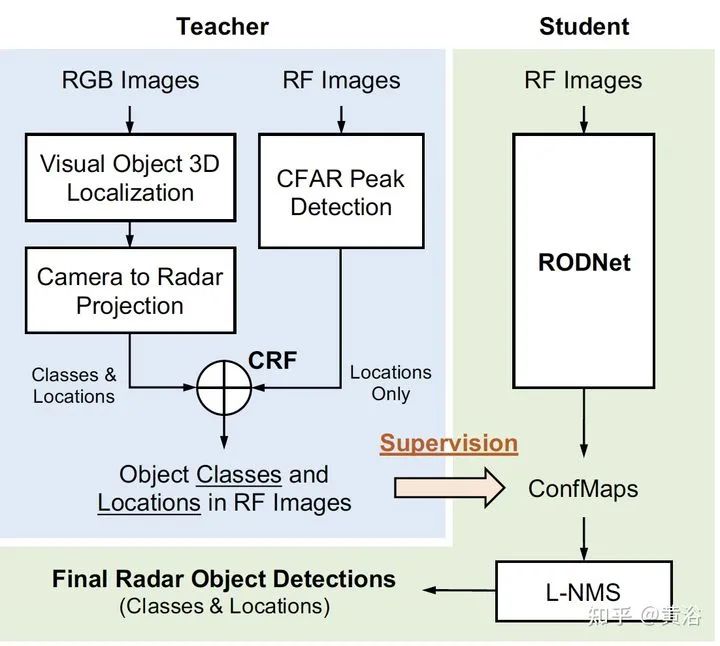
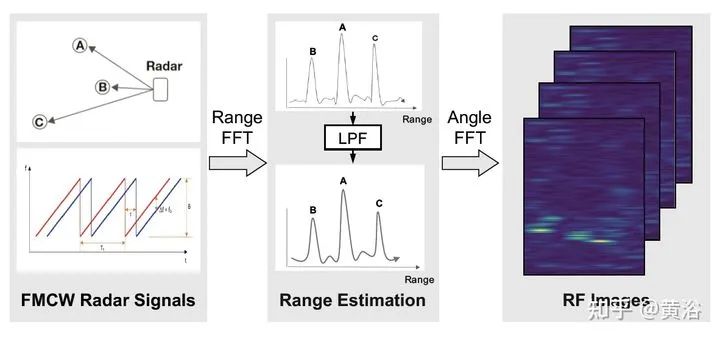
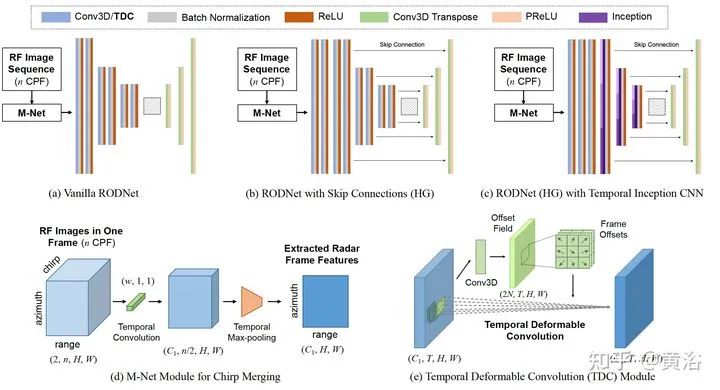
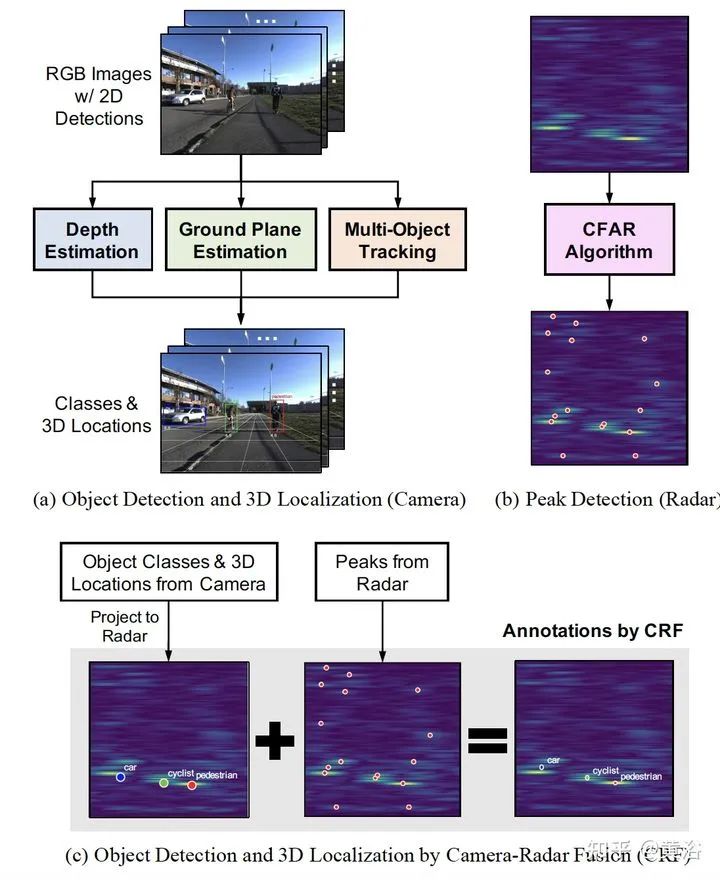
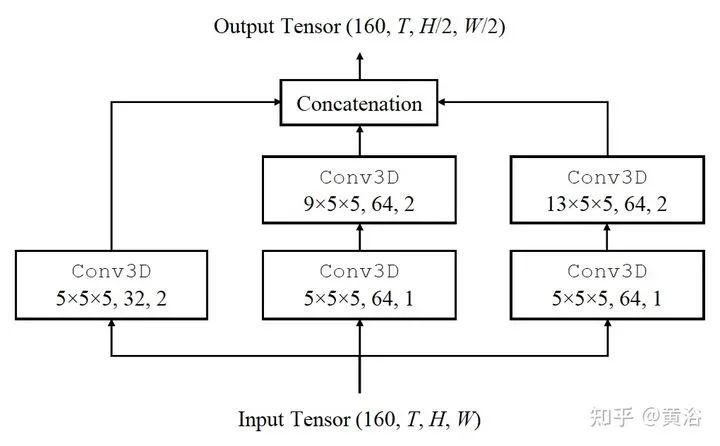
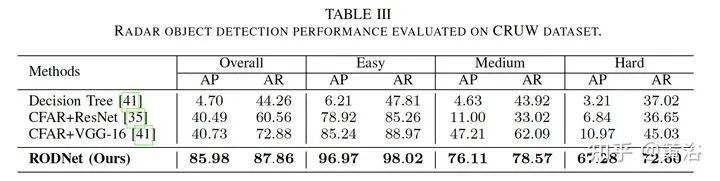
3 "RODNet: A Real-Time Radar Object Detection Network Cross-Supervised by Camera-Radar Fused Object 3D Localization", 2 2021
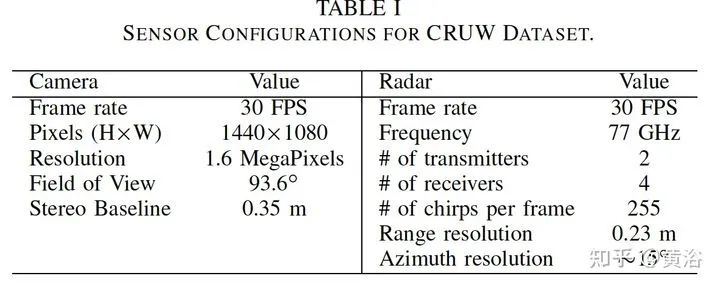
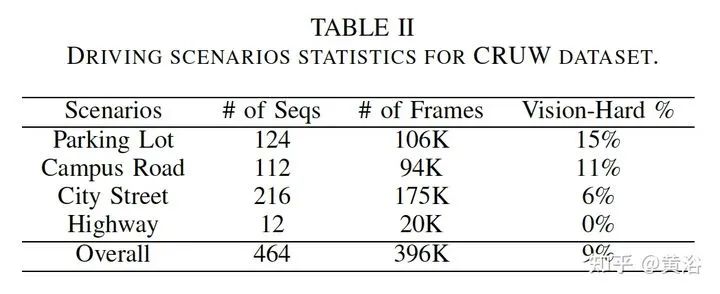
雷达目标检测网络RODNet,但训练是通过一个摄像头-雷达监督算法,无需标注,可实现射频(RF)图像的实时目标检测。原始毫米波雷达信号转换为range-azimuth坐标的RF图像;RODNet预测雷达FoV的目标似然性。两个定制的模块M-Net和temporal deformable convolution分别处理multi-chirp merging信息以及目标相对运动。训练中采用camera-radar fusion (CRF) 策略,另外还建立一个新数据集CRUW1。 cross-modal supervision pipeline for radar object detection in a teacher-student platform workflow of the RF image generation from the raw radar signals The architecture and modules of RODNet Three teacher’s pipelines for cross-model supervision temporal inception convolution layer
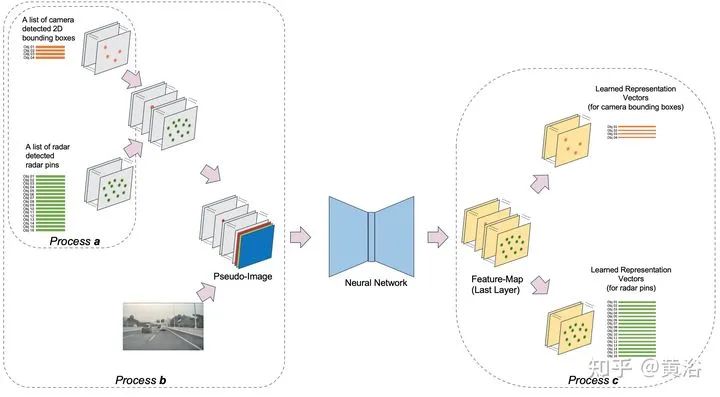
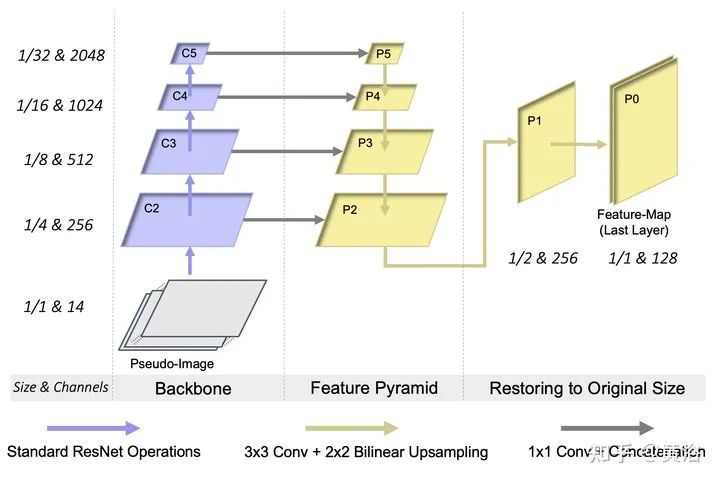
4 “Radar Camera Fusion via Representation Learning in Autonomous Driving”,4,2021
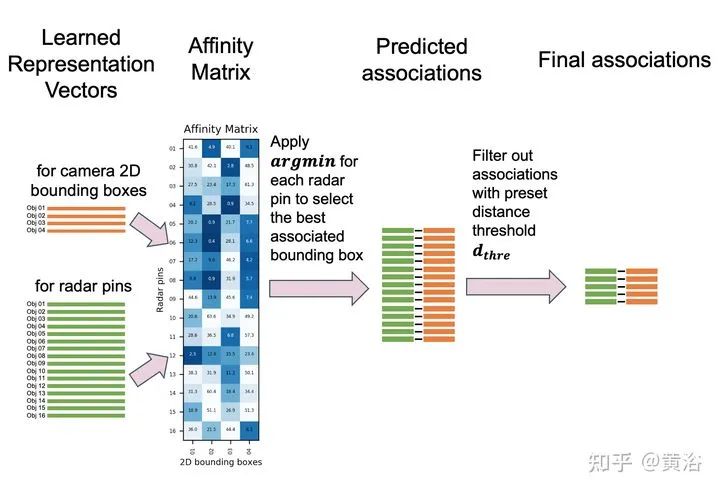
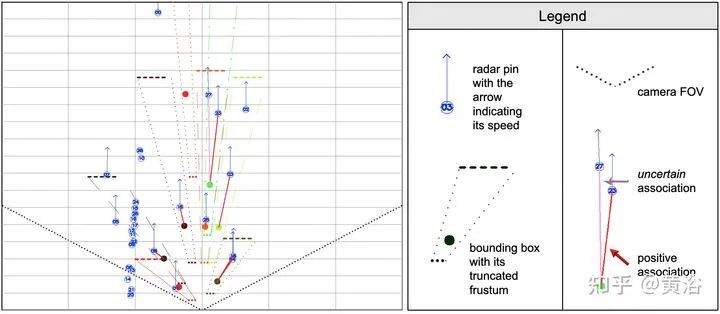
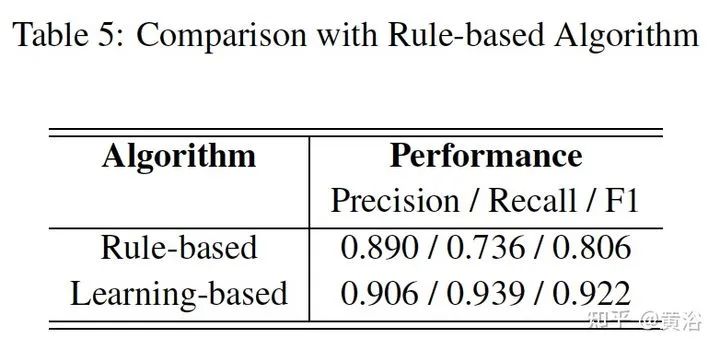
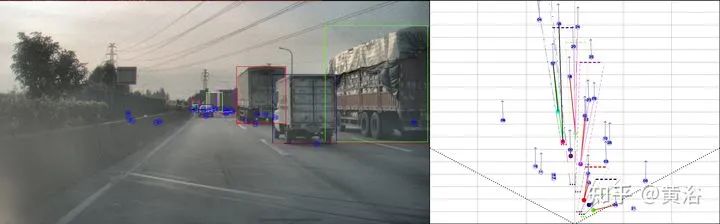
重点讨论data association问题。而rule-based association methods问题较多,故此讨论radar-camera association via deep representation learning 以开发特征级的交互和全局推理。将检测结果转换成图像通道,和原图像一起送入一个深度CNN模型,即AssociationNet。另外,设计了一个loss sampling mechanism 和 ordinal loss 来克服不完美的标注困难,确保一个类似人工的推理逻辑。 associations between radardetections (radar pins) and camera detections (2D bounding boxes). AssociationNet architecture of the neural network process of obtaining final associationsfrom the learned representation vectors illustration of radar pins, bounding boxes, and association relationships under BEV perspective the red solid lines represent the true-positive associations; and the pink solid lines represent predicted positive associations but labeled as uncertain in the ground-truth The added green lines represent the false-positive predictions; and the added black lines represent the false-negative predictions本文仅做学术分享,如有侵权,请联系删文。