
我用 Java 爬了一下CSDN,发现了这些秘密。
大家好,我是大尧。
今天我们使用Java语言写一个爬虫,用来爬取csdn首页推荐博客的博主,看看这些博主有多少人在写微信公众号。
一、爬虫原理
爬虫就是去请求某个url,然后将响应的页面进行解析,将解析到的数据保存,同时解析出当前页面的url,继续进行爬取,一直循环下去,爬取当前网站的内容。

二、分析CSDN页面数据
因为我们的目标很明确,就是去分析首页推荐博客博主写微信公众号的比例,因此我们只需要找到我们需要的数据进行保存即可,不需要爬取网站的全部数据。
2.1 找到CSDN首页的博客链接
在浏览器输入csdn首页链接
https://www.csdn.net/,找到我们爬取的目标,如下图所示
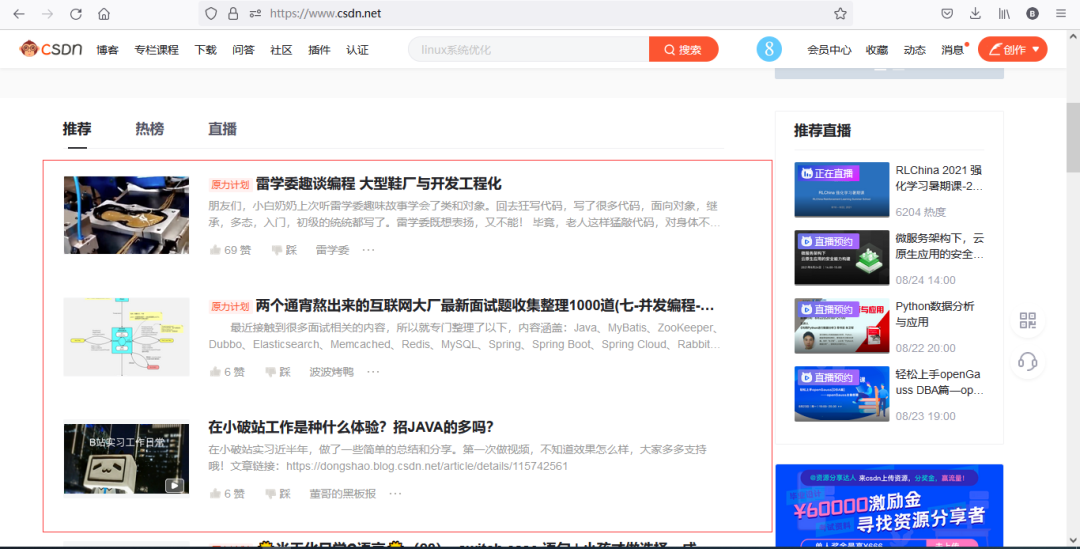
使用 f12查看目标元素
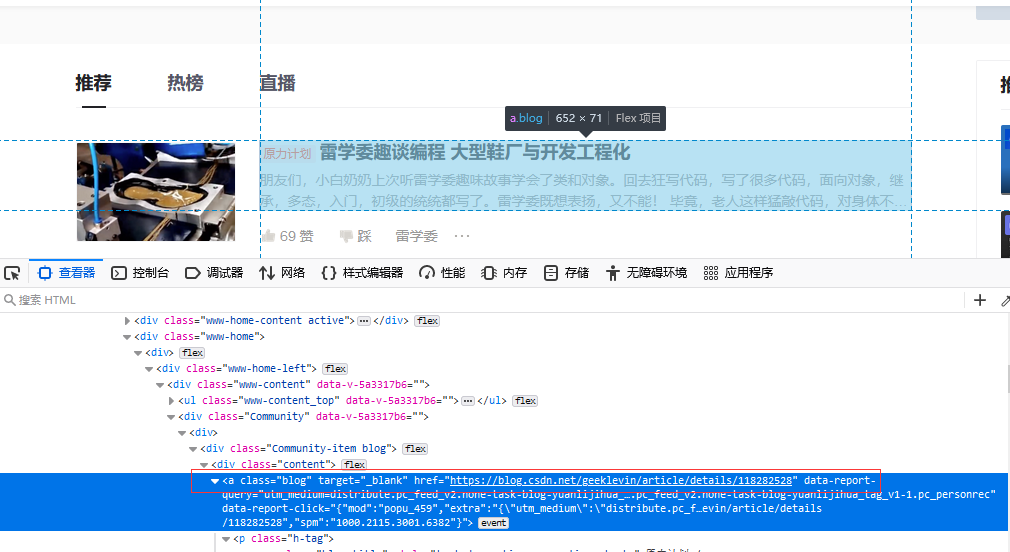
根据目标元素,我们可以提取两个关键元素,其一是目标链接在<a></a>中,其二是博客地址的格式为https://blog.csdn.net/+"用户名"+/article/details/+"文章标识"(记住这个博客地址,后面有用)。
2.2 提取设置了公众号信息的博主
在文章详情页面有博主相关的信息,csdn博客左侧有一块是博主用来自定义信息的,如下图:
还是一样,f12来查看DOM元素,发这一块内容在id=asideCustom的
中。

2.3 爬取思路
通过爬取首页,解析出所有
a标签筛选
a标签,根据博客地址格式,匹配到所有的博客地址爬取博客地址,解析
id=asideCustom的如果第3步可以解析出来,则说明该博主设置了自定义信息
三、编写爬虫
根据上面的分析我们需要两个工具包,一个是httpclient用于网络请求,另一个是用来解析DOM元素的jsoup。
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.10</version>
</dependency>
<!-- 添加jsoup支持 -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.1</version>
</dependency>
网络调用伪代码
public static ArrayList<Document> HttpUtil(HashSet<String> urls){
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
ArrayList<Document> list = new ArrayList<>();
try {
for(String url : urls){
HttpGet request = new HttpGet(url);
response = httpClient.execute(request);
//判断响应状态为200,请求成功,进行处理
if(response.getStatusLine().getStatusCode() == 200) {
HttpEntity httpEntity = response.getEntity();
String html = EntityUtils.toString(httpEntity, "utf-8");
Document document = Jsoup.parse(html);
list.add(document);
} else {
System.out.println("返回状态不是200");
}
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
return list;
}
调用及解析伪代码
public static void main(String[] args) {
// 标记有多少博主设置了自定义信息
int i = 0;
// 首页url
HashSet<String> url = new HashSet<>();
// 文章urls
HashSet<String> articleUrls = new HashSet<>();
url.add("https://www.csdn.net/");
// 爬取csdn首页
ArrayList<Document> list = HttpUtil(url);
// 选择a标签
for(Document document : list){
Elements a = document.select("a");
for(Element element : a){
// 获取a中的url
// <a href = "https://xxxx"> </a>
String href = element.attr("href");
// 筛选博客地址
if(href.contains("article/details")){
articleUrls.add(href);
}
}
}
ArrayList<Document> list2 = HttpUtil(articleUrls);
for(Document document : list2){
Element asideCustom = document.getElementById("asideCustom");
if(asideCustom != null){
i++;
}
}
// 输出爬取的文章数量 和 设置了自定义信息的博主数量
System.out.println("爬取的文章数量="+articleUrls.size()+"\n"+"写公众号的博主数量="+i);
}
控制台输出信息
爬取的文章数量=25
写公众号的博主数量=5
四、结尾
从上面的结果中可以看出,在25篇博客中,就有五个博主在写公众号。但是,这个数据并不能说明csdn的1/5博主就在更新自己的公众号。
csdn首页推荐数据是分页拉取的,爬虫只能爬取到第一页的数据,也就是25条 有些博主虽然设置了自定义信息,但是并不是公众号 有些博主虽然没有设置自定义信息,但是在简介或者其他地方留了公众号名称
不过这些都没关系,本文的重点是使用java语言写个爬虫程序,来爬取目标数据。
赞赏显得见外,在看才是真爱!
评论