
终于有人把A/B测试讲明白了(文末赠书)
导读:对照实验有时也称为A/B测试、A/B/n 测试(强调多变体测试)、实地实验、随机对照实验、分拆测试、分桶测试和平行飞行测试。本文带你了解一些相关术语及应用案例。
一个精确的测量胜过一千个专家的意见。
——海军准将格雷斯·霍珀
2012年,必应(微软的搜索引擎)的一名员工提出了关于改进搜索页广告标题陈列方式的一个想法 (Kohavi and Thomke 2017):将标题下方的第一行文字移至标题同一行,以使标题变长,如图1.1所示。

▲图1.1 改进必应上广告陈列方式的实验
在成百上千的产品建议中,没有人预料到这样一个简单的改动竟然成了必应历史上最成功的实现营收增长的想法!
起初,这个产品建议的优先级很低,被埋没在待办列表中超过半年。直到有一天,一个软件工程师决定试一试这个从编程角度来说非常简单的改动。
他实现了该想法,并通过真实的用户反馈来评估它:随机给一部分用户显示新的标题陈列方式,而对另一部分用户依旧显示老版本。用户在网站上的行为,包括广告点击以及产生的营收都被一一记录。
这就是一个A/B测试的例子:一种简单的用于比较A和B两组变体的对照实验。A和B也分别称为对照组和实验组。
该测试开始后的几个小时,“营收过高”的警报被触发,提示实验有异常。实验组,也就是新的标题陈列方式,产生了过高的广告营收。这种“好到难以置信”的警报非常有用,它们通常能提示严重的漏洞,如营收被重复上报(双重计费)或者因网页出错而导致只能看到广告。
然而就这个实验而言,营收增长是真实有效的。在没有显著损害其他关键用户体验指标的情况下,必应的营收增长高达12%,这意味着仅在美国,当年的营收增长就将超过1亿美金。这一实验在后来很长一段时间里被多次重复验证。
这个例子体现了关于线上对照实验的几个关键主题:
一个想法的价值很难被预估。在这个案例中,一个价值超过每年1亿美金的简单的产品改动被耽搁了好几个月。
小改动可以有大影响。一个工程师几天的工作就能带来每年1亿美金的回报。当然这样极端的投资回报率(return-on-investment, ROI)也很罕见。
有很大影响的实验是少见的。必应每年运行上万个实验,但这种小改动实现大增长的案例几年才出一个。
运行实验的启动成本要低。必应的工程师可以使用微软的实验平台ExP,来便利地科学评估产品改动。
综合评估标准(overall evaluation criterion,OEC)必须清晰。在这个案例中,营收是OEC的一个关键组成,但仅营收本身不足以成为一个OEC。以营收为唯一指标可能导致网站满是广告而伤害用户体验。必应使用的OEC权衡了营收指标和用户体验指标,包括人均会话数(用户是否放弃使用或者活跃度增加)和其他一些成分。关键宗旨是即使营收大幅增长,用户体验指标也不能显著下降。
接下来先介绍对照实验的术语。
01 线上对照实验的术语
对照实验有一段长而有趣的历史,我们的网站有相关分享(Kohavi, Tang and Xu 2019)。对照实验有时也称为A/B测试、A/B/n 测试(强调多变体测试)、实地实验、随机对照实验、分拆测试、分桶测试和平行飞行测试。
很多公司广泛使用线上对照实验,例如爱彼迎(Airbnb)、亚马逊(Amazon)、缤客(Booking.com)、易贝(eBay)、脸书(Facebook)、谷歌(Google)、领英(LinkedIn)、来福车(Lyft)、微软(Microsoft)、奈飞(Netflix)、推特(Twitter)、优步(Uber)、Yahoo!/Oath和Yandex(Gupta et al. 2019)。
这些公司每年运行成千上万个实验,实验有时涉及百万量级的用户,测试内容更是涵盖各个方面,包括用户界面(User Interface, UI)的改动、关联算法(搜索、广告、个性化、推荐等)、延迟/性能、内容管理系统、客户支持系统等。
实验可运行于多种平台或渠道:网站、桌面应用程序、移动端应用程序和邮件。
最常见的线上对照实验把用户随机分配到各变体,且这种分配遵循一以贯之的原则(一个多次访问的用户始终会被分配至同一变体)。
在开篇必应的例子中,对照组是原本的广告标题陈列方式,实验组是长标题陈列方式。用户在必应网站上的互动被以日志的形式记录,即监测和上报。根据上报的数据计算得到的各项指标可以帮助我们评估两个变体之间的区别。
最简单的对照实验有两个变体,如图1.2所示:对照组(A)和实验组(B)。
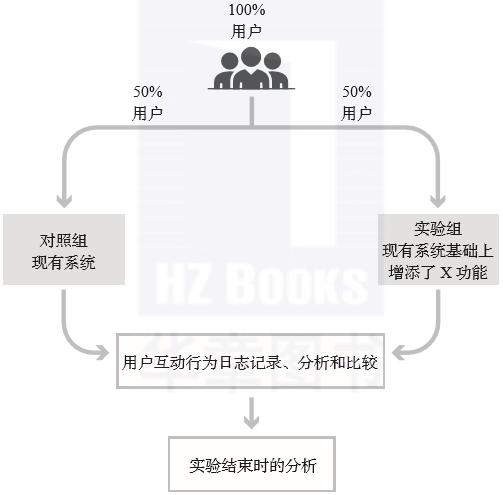
▲图1.2 一个简单的对照实验:A/B测试
以下,我们将遵循Kohavi和Longbottom等人(Kohavi and Longbottom (2017), Kohavi, Longbottom et al. (2009))使用的术语进行介绍,并提供其他领域的相关术语。更多关于实验和A/B测试的资源可以在本章结尾的补充阅读部分中找到。
1. 综合评估标准(Overall Evaluation Criterion, OEC)
实验目标的定量测量。例如,你的OEC可能是人均活跃天数,指示实验期间用户有几天是活跃的(即有访问并有其他行动)。OEC的增长意味着用户更频繁地访问了网站,这是好的结果。
OEC需要在短期内(实验期间)可测量,同时要对长期战略目标有因果关系的驱动作用。在搜索引擎的例子中,OEC可以是使用量(如人均会话数)、关联(如成功的会话、成功需时)以及广告营收的综合考量(有些搜索引擎不会用到所有这些指标,有些则会用到更多种类的指标)。
在统计学中,OEC也常称为响应变量或因变量(Mason, Gunst and Hess 1989, Box, Hunter and Hunter 2005)。其他的同义词还有结果、评估和适应度函数(Quarto-vonTivadar 2006)。
虽然选择单一指标(可能是一个对多重目标进行加权组合的指标)常常是必须的和高度推荐的(Roy 2001, 50, 405-429),但实验可能有多重目标,且分析也可以采用平衡的分析看板的方法(Kaplan and Norton 1996)。
2. 参数
对照实验中被认为会影响OEC或其他我们感兴趣的指标的变量。参数有时也称为因素或变量。参数的赋值也称为因子水平。一个简单的A/B测试通常只有一个参数,两个赋值。对于线上实验,单变量多赋值(如A/B/C/D)的设计非常普遍。
多变量测试,也称多元检验,则可用于同时评估多个参数(变量),比如字体颜色和字体大小。多变量测试可以帮助实验者在参数间有交叉影响时找到全局最优值。
3. 变体
被测试的用户体验,一般通过给参数赋值实现。对于简单的A/B测试,A和B就是两个变体,通常被称为对照组和实验组。在某些文献中,变体只指代实验组。而我们把对照组也看作一种特殊的变体——用于进行对比的原始版本。
比如,实验中出现漏洞时,你需要中止这个实验,并确保所有用户被分配到对照组这个变体。
4. 随机化单元
以伪随机化(如哈希)过程将单元(如用户或页面)映射至不同变体。正确的随机分配过程非常重要,它可以确保不同变体的群体在统计意义上的相似性,从而高概率地确立因果关系。
映射时需遵循一以贯之和独立的原则(即如果以用户为随机化单元,那么同一个用户应该自始至终有一致的体验,并且一个用户被分配到某一变体的信息不会透露任何其他用户的分配信息)。
运行线上对照实验时,非常普遍且我们也强烈推荐的是以用户为随机化单元。有些实验设计会选择其他的随机化单元,例如页面、会话或用户日(即同一用户在由服务器决定的每个24小时的窗口内体验不变)。
正确的随机分配是至关重要的!如果实验设计为各个变体获得相同比例的用户,那么每个用户被分配到任何一个变体的概率应该是一样的。千万不要轻视随机分配。下面的例子解释了正确进行随机分配的挑战和重要性。
20世纪40年代,RAND公司需要为蒙特卡罗方法寻找随机数,为此,他们制作了一份由脉冲机器生成的百万乱数表。然后由于硬件偏移,原表被发现有严重的偏差,导致需要为新版重新生成随机数(RAND 1995)。
对照实验起初应用于医药领域。美国退伍军人事务部曾做过一个用于结核的链霉素的药物试验,由于医师在甄选程序中出现了偏差,这一试验最终宣告失败(Mark 1997)。英国有一项类似的试验以盲态程序甄选并获得了成功,成为对照试验领域的分水岭时刻(Doll 1998)。
任何因素都不应影响变体的分配。用户(随机化单元)不能被随意地分配(Weiss 1997)。值得注意的是,随机不代表“随意或无计划,而是一种基于概率的慎重选择”(Mosteller, Gilbert and Mcpeek 1983)。Senn (2012)探讨了更多关于随机分配的迷思。
02 为什么进行实验?相关性、因果关系和可信赖度
假设你在一家提供订阅服务的公司(比如奈飞)工作,公司每个月有X%的用户流失(取消订阅)。你决定引入一个新功能,观察到使用这个新功能的用户的流失率仅为一半:X%/2。
你可能据此推断出因果关系:该新功能使得流失率减半。由此得出结论:如果我们能让更多的用户发现这一功能并使用它,订阅数将会激增。错了!根据这个数据,我们无法得出该功能降低或增加用户流失率的结论,两个方向皆有可能。
同样提供订阅服务的微软Office 365有一个例子表明了这种逻辑的谬误。使用Office 365时看到错误信息并遭遇系统崩溃的用户有较低的流失率,但这并不代表Office 365应该显示更多的错误信息或者降低代码质量使得系统频繁崩溃。
这三个事件都有一个共同的因素:使用率。产品的重度用户看到较多的错误信息,经历较多的系统崩溃,其流失率也较低。相关性并不意味着因果关系,过度依赖观察结果往往导致做出错误的决策。
1995年,Guyatt et al. (1995)引入了证据可信度等级来为医学文献做出推荐评级,Greenhalgh在之后关于循证医学的实践讨论中进一步扩展了这个模型(1997, 2014)。
图1.3展示了一个翻译成我们的术语的基础版证据可信度等级(Bailar 1983, 1)。随机对照实验是确立因果关系的黄金准则。对随机对照实验的系统性检阅(即统合分析)则有更强的实证性和普适性。
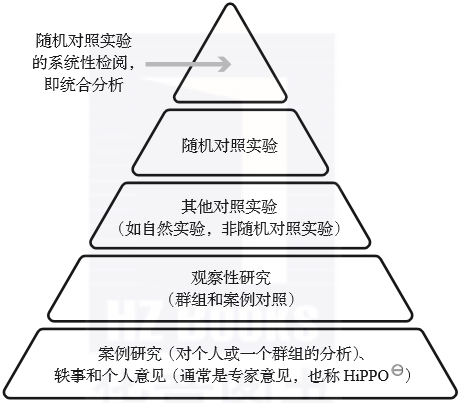
▲图1.3 用于评估实验设计质量的证据可信度等级 (Greenhalgh 2014)
这一领域还有更多更复杂的模型,比如牛津循证医学中心提出的证据分级(Level of Evidence)(2009)。
谷歌、领英和微软的实验平台每年可以运行成千上万个线上对照实验,并提供可信赖的实验结果。我们相信线上对照实验有以下特性:
它是以高概率确立因果关系的最佳科学方法。
能够检测其他技术难以检测到的微小变动,比如随时间的变化(灵敏度)。
能够检测到意想不到的变动。虽然常被低估,但很多实验发掘了一些对其他指标出乎意料的影响,比如性能的降低、系统崩溃和出错的增加或是对其他模块的点击的吞噬。
一个重点是实验中可能出现陷阱,我们需要给出能让实验结果更可信赖的方法。线上对照实验有其独一无二的线上收集大量可靠数据、随机分配和避免或检测陷阱的能力。当线上对照实验不可行的时候,我们才推荐使用其他可信度较低的方法,如观察性研究。
03 有效运行对照实验的必要元素
科学严谨的对照实验并不能用于所有的决策。比如,你无法在一个投资并购(M&A)场景中运行对照实验,因为我们无法让投资并购和它的虚拟事实(没有该投资并购)同时发生。
接下来我们将梳理有效运行对照实验的必要元素(Kohavi,Crook and Longbotham 2009),并提出机构的宗旨。
存在可以互不干扰(或干扰很小)地被分配至不同变体的实验单元,比如实验组的用户不会影响对照组的用户。
有足够的实验单元(如用户)。为了对照实验的有效性,我们推荐实验应包含上千个实验单元:数目越多,能检测到的效应越小。好消息是,即使是小型的软件初创公司通常也能很快地累积足够的用户,从检测较大的效应开始运行实验。随着业务的增长,检测较小变动的能力会变得越来越重要(例如,大型网站必须有能力检测出用户体验关键指标和营收百分比的微小变动),而实验灵敏度也会随着用户基数的增长而提高。
关键指标(最好是OEC)是经过一致同意的,且可以在实践中被评估。如果目标难以测量,那么应对使用的代理指标达成一致。可靠的数据最好能以低成本被广泛地收集到。在软件领域,记录系统事件和用户行为通常比较简单。
改动容易实现。软件的改动一般比硬件的要简单。然而即使是软件的改动,有些领域也需要一定级别的质量控制。推荐算法的改动很容易实现和评估,但美国飞机的飞行控制系统软件的改动则需经过美国联邦航空管理局一整套不同的批准流程。服务器端软件比客户端软件要容易改动得多,这就是为什么从客户端软件请求服务越来越普遍,从而使服务的升级和改动可以更快实现并运行对照实验。
大部分复杂的线上服务都有或者可以有这些必要组成部分,来运行基于对照实验的敏捷开发流程。很多“软件+服务”的实现也能相对容易地达到要求。Thomke指出机构可以通过实验与“创新系统”的结合实现利益最大化(Thomke 2003)。敏捷软件开发就是这样的创新系统。
对照实验不可行的时候,也可以用建模或其他的实验技术。关键是,如果可以运行对照实验,那么它将提供评估改动的最可靠且最灵敏的机制。

老规矩,文末留言,谈谈你认为的A/B实验和你平常接触的A/B实验都是什么样的,并转发朋友圈集赞,留言点赞前3名,各送《关键迭代》新书一本。
时间截止到周一(5.17)晚9:00。