
Python数据可视化教程之实践篇
本篇文章在基础篇的基础上,选择实际案例进行了练习。
再明确一次三个步骤:
确定问题,选择图形
转换数据,应用函数
参数设置,一目了然
下面,我们通过案例来进行演示:
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt #导入plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')#忽略警告加载数据
数据采用kaggle中的共享单车项目,比赛提供了跨越两年的每小时共享单车租赁数据,包含天气信息和日期信息。
字段说明
datetime(日期) - hourly date + timestamp
season(季节) - 1 = spring, 2 = summer, 3 = fall, 4 = winter
holiday(是否假日) - whether the day is considered a holiday
workingday(是否工作日) - whether the day is neither a weekend nor holiday
weather(天气等级)
Clear, Few clouds, Partly cloudy 清澈,少云,多云。
Mist + Cloudy, Mist + Broken clouds, Mist + Few clouds, Mist 雾+阴天,雾+碎云、雾+少云、雾
Light Snow, Light Rain + Thunderstorm + Scattered clouds, Light Rain + Scattered clouds 小雪、小雨+雷暴+散云,小雨+云
Heavy Rain + Ice Pallets + Thunderstorm + Mist, Snow + Fog 暴雨+冰雹+雷暴+雾,雪+雾
temp(温度) - temperature in Celsius
atemp(体感温度) - "feels like" temperature in Celsius
humidity(相对湿度) - relative humidity
windspeed(风速) - wind speed
casual(临时租赁数量) - number of non-registered user rentals initiated
registered(会员租赁数量) - number of registered user rentals initiated
count(总租赁数量) - number of total rentals
date(日期) - 由datetime拆分得到
hour(小时)-由datetime拆分得到
year(年份)-由datetime拆分得到
month(月份)-由datetime拆分得到
weeekday(周几)-由datetime拆分得到
windspeed_rfr(经过随机森林树填充0值得到的风速)
#读取数据
#Bikedata = pd.read_csv('./Bike.csv')
Bikedata.head()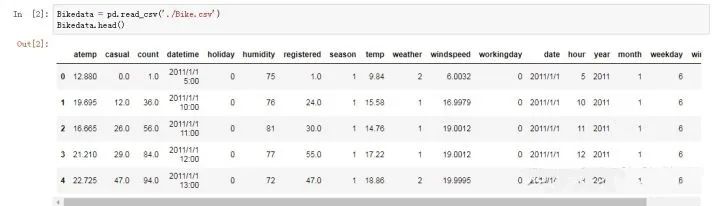
#查看描述统计
Bikedata.describe()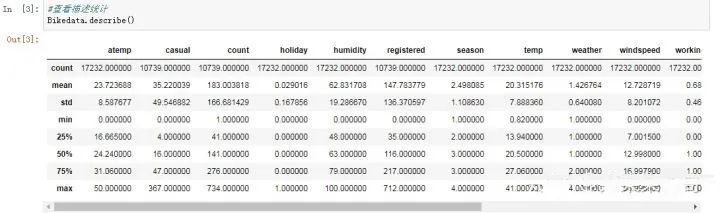
#对于整体数据,我们希望查看与三个租赁数量相关的其他特征值的关系,可以选用seaborn包的pairplot函数(多变量图)
sns.pairplot(Bikedata,x_vars=['holiday','workingday','season','weather','hour','windspeed_rfr','atemp','humidity','temp'],y_vars=['count','registered','casual'],plot_kws={'alpha': 0.1})
0xadcef98> 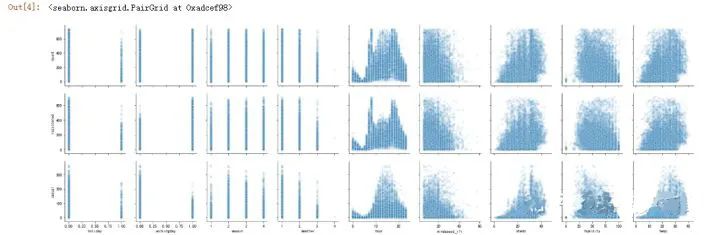
大致可以看出:会员在工作日出行较多,节假日次数减少,而临时用户相反,第一季度出行人数总体偏低,出行人数受天气影响较大,会员在每天早晚有两个高峰期,对应上下班时间;非会员在下午出行较密集 风速对出行人数有较大的影响 相对湿度,温度和体感温度对非会员出行影响较大,对会员出行影响较小。
#接下来,我们通过相关系数的大小来依次对特征进行可视化分析
#首先,列出相关系数矩阵:df.corr()
corrdf = Bikedata.corr()
corrdf
#各特征按照与租赁总量count的相关系数大小进行排序
corrdf['count'].sort_values(ascending=False)
count 1.000000
registered 0.966209
casual 0.704764
hour 0.405437
temp 0.385954
atemp 0.381967
year 0.234959
month 0.164673
season 0.159801
windspeed_rfr 0.111783
windspeed 0.106074
weekday 0.022602
holiday 0.002978
workingday -0.020764
weather -0.127519
humidity -0.317028
Name: count, dtype: float64可见,特征对租赁总量的影响力为:
时段>温度>湿度>年份>月份>季节>天气>风速>工作日>节假日
对特征逐项分析
1
首先对时段进行分析
第一步
提出问题:租赁总量对应湿度的变化趋势
适合图形:因为湿度属于连续性数值变量,我们可以选择折线图反应变化趋势
第二步
转换数据:我们需要一个二维数据框,按照温度变化排序,取对应的三个租赁数的平均值
应用函数:直接应用plt的plot函数即可完成折线图
workingday_df = Bikedata[Bikedata['workingday']==1]#t
workingday_df = workingday_df.groupby(['hour'],as_index=True).agg({'count':'mean','registered':'mean','casual':'mean'})
nworkingday_df = Bikedata[Bikedata['workingday']==0]
nworkingday_df = nworkingday_df.groupby(['hour'],as_index=True).agg({'count':'mean','registered':'mean','casual':'mean'})
nworkingday_df.head()第三步:设置参数
figure,axes = plt.subplots(1,2,sharey=True)#设置一个1*2的画布,且共享y轴
workingday_df.plot(figsize=(15,5),title='The average number of rentals initiated per hour in the working day',ax=axes[0])
nworkingday_df.plot(figsize=(15,5),title='The average number of rentals initiated per hour in the nworking day',ax=axes[1])
0xe452940> 可以看出:
在工作日,会员出行对应两个很明显的早晚高峰期,并且在中午会有一个小的高峰,可能对应中午外出就餐需求;
工作日非会员用户出行高峰大概在下午三点;
工作日会员出行次数远多于非会员用户;
在周末,总体出行趋势一致,大部分用车发生在11-5点这段时间,早上五点为用车之最。
2
对温度进行分析
第一步
提出问题:租赁总量对应湿度的变化趋势
适合图形:因为湿度属于连续性数值变量,我们可以选择折线图反应变化趋势
第二步
转换数据:我们需要一个二维数据框,按照温度变化排序,取对应的三个租赁数的平均值
应用函数:直接应用plt的plot函数即可完成折线图
第三步
参数设置:只需要设置折线图的标题,其他参数默认
temp_df = Bikedata.groupby(['temp'],as_index='True').agg({'count':'mean','registered':'mean','casual':'mean'})
temp_df.plot(title = 'The average number of rentals initiated per hour changes with the temperature')
0xe57d7f0> 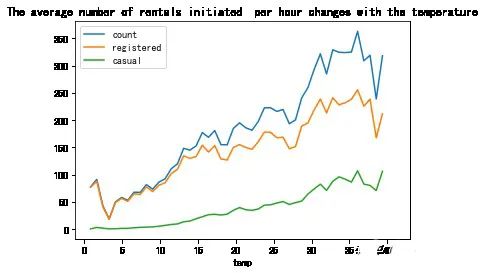
随着温度的升高,租赁数量呈上升趋势;
在温度达到35度时,因天气炎热,总体数量开始下降;
在温度在4度时,租赁数达到最低点;
3
湿度对租赁数量的影响
第一步
提出问题:租赁总量对应湿度的变化趋势
适合图形:因为湿度属于连续性数值变量,我们可以选择折线图反应变化趋势
第二步
转换数据:我们需要一个二维数据框,按照温度变化排序,取对应的三个租赁数的平均值
应用函数:直接应用plt的plot函数即可完成折线图
第三步
参数设置:只需要设置折线图的标题,其他参数默认
humidity_df = Bikedata.groupby(['humidity'],as_index=True).agg({'count':'mean','registered':'mean','casual':'mean'})
humidity_df.plot(title='Average number of rentals initiated per hour in different humidity')
0xe582400> 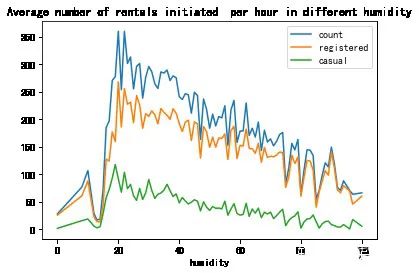
可以观察到在湿度20左右租赁数量迅速达到高峰值,此后缓慢递减。
年份,月份和季节作图方法类似,都采用折线图绘制,这里省略。
4
查看不同天气对出行情况的影响
第一步
提出问题:租赁总量对应湿度的变化趋势
适合图形:因为天气情况属于数值型分类变量,我们可以选择柱形图观察数量分布
第二步
转换数据:我们需要一个二维数据框,按照天气情况对租赁数量取平均值
应用函数:应用plt的plot.bar函数绘制组合柱形图
第三步
参数设置:只需要设置折线图的标题,其他参数默认
weather_df = Bikedata.groupby(['weather'],as_index=True).agg({'registered':'mean','casual':'mean'})
weather_df.plot.bar(stacked=True,title='Average number of rentals initiated per hour in different weather')
0xe7e0a90> 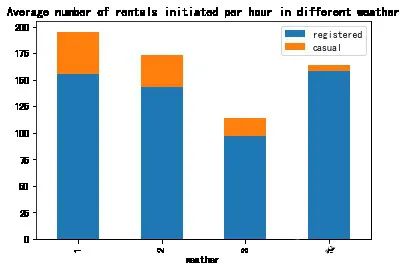
观察到天气等级为4时,平均出行人数比天气等级为2是还要高,这不符合常理
我们查看一下天气等级为4的详细情况
count_weather = Bikedata.groupby('weather')
count_weather[['casual','registered','count']].count()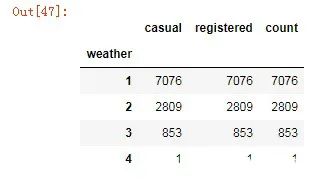
天气状况为4级的只有一天,我们把数据打印出来查看一下
Bikedata[Bikedata['weather']==4]
时间为工作日的下午六点钟,属于晚高峰异常数据,不具有代表性。
5
会员用户和临时用户在整体用户中占比
第一步
提出问题:查看会员用户和临时用户在整体用户中的比例
适合图形:查看占比,适合用饼图pie
第二步
转换数据:需要一个二维数据框,按天数取两种用户的平均值
应用函数:应用plt的plot.pie函数绘制饼图
第三步
参数设置:这是数据标签和类别标签
#考虑到相同日期是否工作日,星期几,以及所属年份等信息是一样的,把租赁数据按天求和,其它日期类数据取平均值
day_df = Bikedata.groupby(['date'], as_index=False).agg({'casual':'sum','registered':'sum','count':'sum', 'workingday':'mean','weekday':'mean','holiday':'mean','year':'mean'})
day_df.head()#按天取两种类型用户平均值
number_pei=day_df[['casual','registered']].mean()
number_pei
casual 517.411765
registered 2171.067031
dtype: float64
#绘制饼图
plt.axes(aspect='equal')
plt.pie(number_pei, labels=['casual','registered'], autopct='%1.1f%%', pctdistance=0.6 , labeldistance=1.05 , radius=1 )
plt.title('Casual or registered in the total lease')
Text(0.5,1,'Casual or registered in the total lease')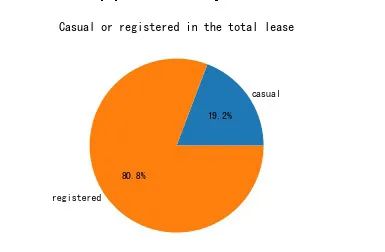
python作图的简单案例
6
总结
要清楚自己想表达什么,有了明确的问题,选择合适的图形,然后按照需求从整体数据中选择自己需要的数据,查阅资料了解函数的参数设置,最后完成图形的绘制
matplotlib是python绘图的基础,也是其他拓展包的基础,认真学习matplotlib的常用图形和参数是很有必要的
学习期间思考为什么要加载matplotlib.pyplot?来进行绘图
- END -
本文为转载分享&推荐阅读,若侵权请联系后台删除
扫一扫下面的二维码 一起学习进步哦~~
“扫一扫,领取Python学习资料”
