
Pandas缺失数据处理大全(附代码)

导读:本文将有关数据清洗、数据分析的一些技能再次进行分类,里面也包含了我平时用到的一些小技巧,此次就从数据清洗缺失值处理走起。
作者:东哥起飞
来源:Python数据科学(ID:PyDataScience)
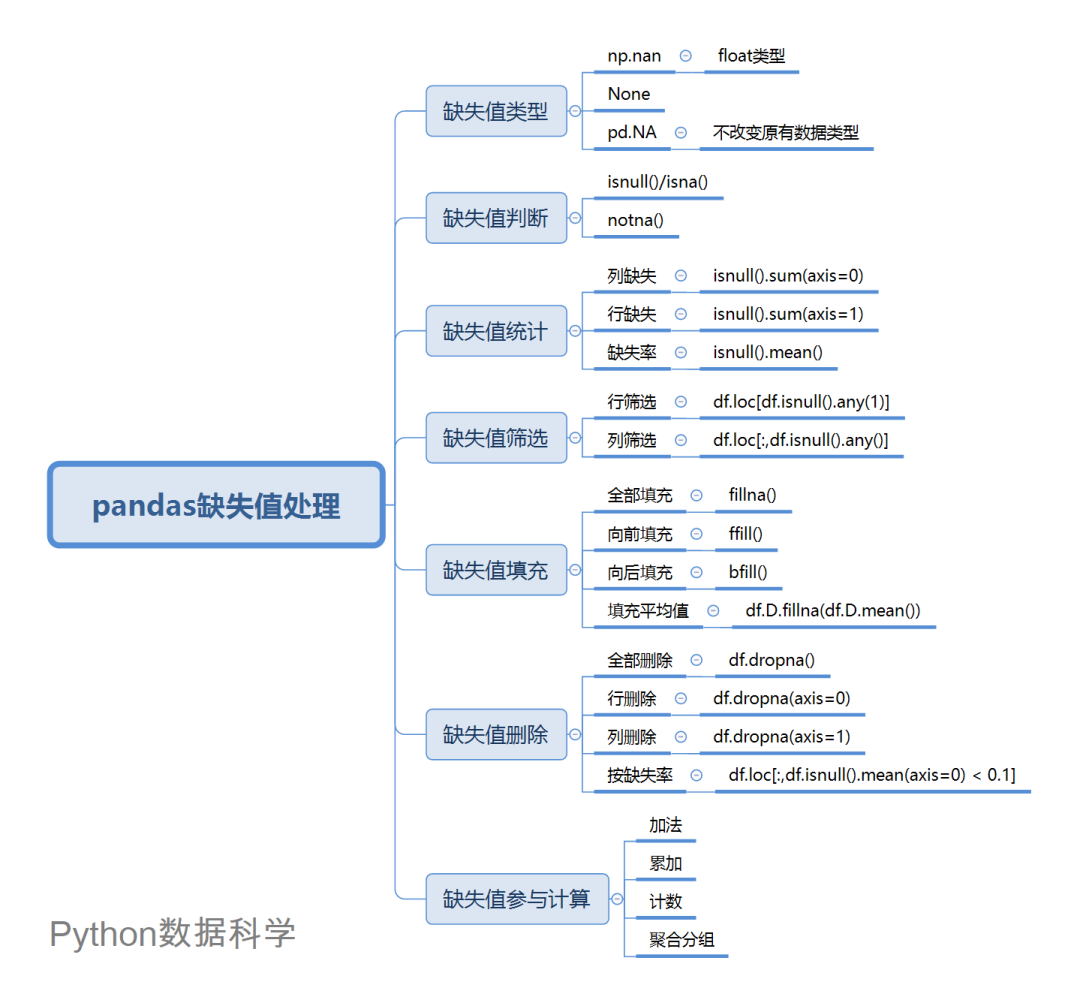
np.nan == np.nan
>> Falsetype(np.nan)
>> float
pd.Series([1,2,3]).dtype
>> dtype('int64')
pd.Series([1,np.nan,3]).dtype
>> dtype('float64')s_time = pd.Series([pd.Timestamp('20220101')]*3)
s_time
>> 0 2022-01-01
1 2022-01-01
2 2022-01-01
dtype:datetime64[ns]
-----------------
s_time[2] = pd.NaT
s_time
>> 0 2022-01-01
1 2022-01-01
2 NaT
dtype:datetime64[ns]
None == None
>> Truetype(pd.Series([1,None])[1])
>> numpy.float64type(pd.Series([1,None],dtype='O')[1])
>> NoneType
s_new = pd.Series([1, 2], dtype="Int64")
s_new
>> 0 1
1 2
dtype: Int64
-----------------
s_new[1] = pd.NaT
s_new
>> 0 1
1
dtype: Int64##### 算术运算
# 加法
pd.NA + 1
>>
-----------
# 乘法
"a" * pd.NA
>>
-----------
# 以下两种其中结果为1
pd.NA ** 0
>> 1
-----------
1 ** pd.NA
>> 1
##### 比较运算
pd.NA == pd.NA
>>
-----------
pd.NA < 2.5
>>
-----------
np.log(pd.NA)
>>
-----------
np.add(pd.NA, 1)
>>
df = pd.DataFrame({
'A':['a1','a1','a2','a3'],
'B':['b1',None,'b2','b3'],
'C':[1,2,3,4],
'D':[5,None,9,10]})
# 将无穷设置为缺失值
pd.options.mode.use_inf_as_na = True
df.isnull()
>> A B C D
0 False False False False
1 False True False True
2 False False False False
3 False False False False
df['C'].isnull()
>> 0 False
1 False
2 False
3 False
Name: C, dtype: bool## 列缺失统计
isnull().sum(axis=0)
## 行缺失统计
isnull().sum(axis=1)
## 缺失率
df.isnull().sum(axis=0)/df.shape[0]
## 缺失率(一步到位)
isnull().mean()
# 筛选有缺失值的行
df.loc[df.isnull().any(1)]
>> A B C D
1 a1 None 2 NaN
-----------------
# 筛选有缺失值的列
df.loc[:,df.isnull().any()]
>> B D
0 b1 5.0
1 None NaN
2 b2 9.0
3 b3 10.0
df.loc[~(df.isnull().any(1))]
>> A B C D
0 a1 b1 1 5.0
2 a2 b2 3 9.0
3 a3 b3 4 10.0# 将dataframe所有缺失值填充为0
df.fillna(0)
>> A B C D
0 a1 b1 1 5.0
1 a1 0 2 0.0
2 a2 b2 3 9.0
3 a3 b3 4 10.0
--------------
# 将D列缺失值填充为-999
df.D.fillna('-999')
>> 0 5
1 -999
2 9
3 10
Name: D, dtype: objectinplace:可以设置fillna(0, inplace=True)来让填充生效,原dataFrame被填充。 methond:可以设置methond方法来实现向前或者向后填充,pad/ffill为向前填充,bfill/backfill为向后填充,比如df.fillna(methond='ffill'),也可以简写为df.ffill()。
df.ffill()
>> A B C D
0 a1 b1 1 5.0
1 a1 b1 2 5.0
2 a2 b2 3 9.0
3 a3 b3 4 10.0
df.D.fillna(df.D.mean())
>> 0 5.0
1 8.0
2 9.0
3 10.0
Name: D, dtype: float64
# 全部直接删除
df.dropna()
>> A B C D
0 a1 b1 1 5.0
2 a2 b2 3 9.0
3 a3 b3 4 10.0
# 行缺失删除
df.dropna(axis=0)
>> A B C D
0 a1 b1 1 5.0
2 a2 b2 3 9.0
3 a3 b3 4 10.0
# 列缺失删除
df.dropna(axis=1)
>> A C
0 a1 1
1 a1 2
2 a2 3
3 a3 4
-------------
# 删除指定列范围内的缺失,因为C列无缺失,所以最后没有变化
df.dropna(subset=['C'])
>> A B C D
0 a1 b1 1 5.0
1 a1 None 2 NaN
2 a2 b2 3 9.0
3 a3 b3 4 10.0
df.loc[:,df.isnull().mean(axis=0) < 0.1]
>> A C
0 a1 1
1 a1 2
2 a2 3
3 a3 4
-------------
# 删除行缺失大于0.1的
df.loc[df.isnull().mean(axis=1) < 0.1]
>> A B C D
0 a1 b1 1 5.0
2 a2 b2 3 9.0
3 a3 b3 4 10.0
df
>>A B C D
0 a1 b1 1 5.0
1 a1 None 2 NaN
2 a2 b2 3 9.0
3 a3 b3 4 10.0
---------------
# 对所有列求和
df.sum()
>> A a1a1a2a3
C 10
D 24
# 对D列进行累加
df.D.cumsum()
>> 0 5.0
1 NaN
2 14.0
3 24.0
Name: D, dtype: float64
---------------
df.D.cumsum(skipna=False)
>> 0 5.0
1 NaN
2 NaN
3 NaN
Name: D, dtype: float64# 对列计数
df.count()
>> A 4
B 3
C 4
D 3
dtype: int64
df.groupby('B').sum()
>> C D
B
b1 1 5.0
b2 3 9.0
b3 4 10.0
---------------
df.groupby('B',dropna=False).sum()
>> C D
B
b1 1 5.0
b2 3 9.0
b3 4 10.0
NaN 2 0.0

延伸阅读👇

延伸阅读《深入浅出Pandas》
干货直达👇
评论