
从源码分析面试中经常出现的集合类问题
点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达
Collection接口
/* @author Josh Bloch
* @author Neal Gafter
* @see Set
* @see List
* @see Map
* @see SortedSet
* @see SortedMap
* @see HashSet
* @see TreeSet
* @see ArrayList
* @see LinkedList
* @see Vector
* @see Collections
* @see Arrays
* @see AbstractCollection
* @since 1.2
集合层次结构中的根接口。集合表示一组对象,称为其元素。
一些集合允许重复的元素,而另一些则不允许。有些是有序的,而另一些则是无序的。
JDK不提供此接口的任何直接实现:它提供了更多特定子接口的实现
*/
public interface Collection<E> extends Iterable<E> {
// Query Operations
/**
返回此集合中的元素数
*/
int size();
/**
如果此集合不包含任何元素,则返回<tt> true </ tt>
*/
boolean isEmpty();
...........
.........
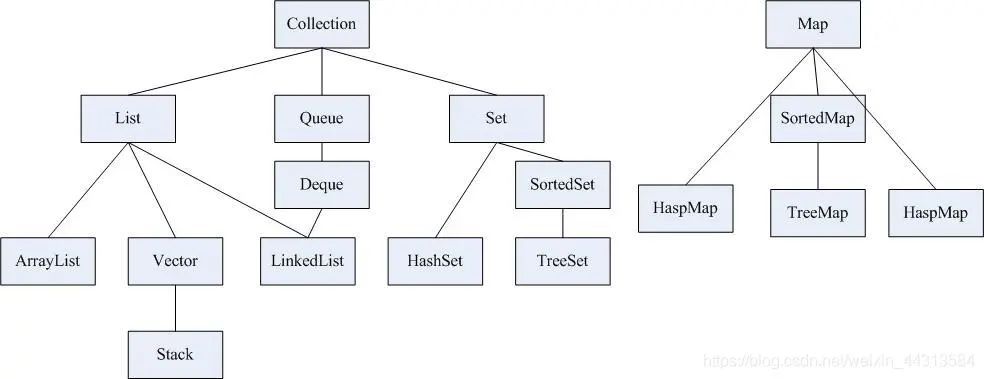
Collection接口是集合类的根接口,继承了Iterable接口,Java中没有直接提供Collection接口的实现类。但是却产生了两个接口,就是Set和List。Set中不能包含重复的元素。List是一个有序的集合,可以包含重复的元素,提供了按索引访问的方式。
List接口
1、List(有序、可重复)
List里存放的对象是有序的,同时也是可以重复的,List关注的是索引,拥有一系列和索引相关的方法,查询速度快。因为往list集合里插入或删除数据时,会伴随着后面数据的移动,所有插入删除数据速度慢。
2、Set(无序、不能重复)
Set里存放的对象是无序,不能重复的,集合中的对象不按特定的方式排序,只是简单地把对象加入集合中。
/* @see Collection
* @see List
* @see SortedSet
* @see HashSet
* @see TreeSet
* @see AbstractSet
* @see Collections#singleton(java.lang.Object)
* @see Collections#EMPTY_SET
* @since 1.2
不包含重复元素的集合
*/
public interface Set<E> extends Collection<E> {
// Query Operations
/**
返回此集合中的元素数(其基数)
*/
int size();
/**
如果此集合不包含任何元素,则返回<tt> true </ tt>
*/
boolean isEmpty();
/**
如果此集合包含指定的元素,则返回<tt> true </ tt>
*/
boolean contains(Object o);
/**
返回此集合中元素的迭代器。 *元素以不特定的顺序返回(除非此集合是提供保证的某些*类的实例)。
*/
Iterator<E> iterator();
...........
.........
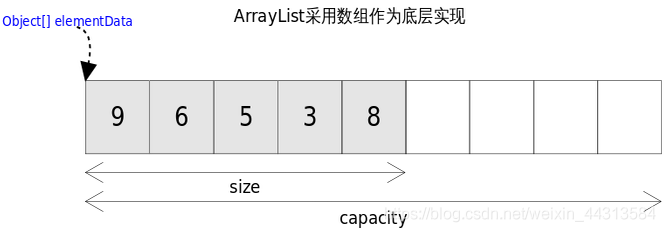
ArrayList(动态数组)
List接口的可调整大小的数组实现。实现所有可选的列表操作(实现了List的全部方法),并允许所有元素,包括null;
/* @see Collection
* @see List
* @see LinkedList
* @see Vector
* @since 1.2
List接口的可调整大小的数组实现。实现所有可选的列表操作,并允许所有元素,包括null。除了实现 List接口之外,此类还提供了一些方法来操纵内部用于存储列表的数组的大小
*/
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
private static final long serialVersionUID = 8683452581122892189L;
/**
默认初始容量
*/
private static final int DEFAULT_CAPACITY = 10;
/**
用于空实例的共享空数组实例
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
/**
共享的空数组实例,用于默认大小的空实例。我们将其与EMPTY_ELEMENTDATA区别开来,以了解添加第一个元素时需要充气多少
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
用于存储ArrayList元素的数组缓冲区。ArrayList的容量是此数组缓冲区的长度。添加第一个元素时,任何具有elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA的空ArrayList都将扩展为DEFAULT_CAPACITY,
该elementData是真正存放元素的容器,可见ArrayList是基于数组实现的;
*/
transient Object[] elementData; //非私有,以简化嵌套类的访问
ArrayList提供了三个构造方法
/** *构造一个具有指定初始容量的空列表。 @param initialCapacity列表的初始容量@如果指定的初始容量为负,则抛出IllegalArgumentException */
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/** *构造一个初始容量为10的空列表。 */
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
/**构造一个包含指定集合的元素的列表,其顺序由集合的迭代器返回。 @param c 要将其元素放入此列表的集合如果指定的集合为null,则抛出NullPointerException */
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
ArrayList扩容和add,set等方法
可见当初始化的list是一个空ArrayList的时候,会直接扩容到DEFAULT_CAPACITY,该值大小是一个默认值10。而当添加进ArrayList中的元素超过了数组能存放的最大值就会进行扩容。
/** ArrayList扩容
默认初始容量 DEFAULT_CAPACITY = 10
*/
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
get,add,set等方法
/** *返回此列表中指定位置的元素。@要返回的元素的索引索引 @返回此列表中指定位置的元素、@throws IndexOutOfBoundsException {@inheritDoc} */
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
/**
用指定的元素替换此列表中指定位置的元素。@param要替换元素的索引index @param要存储在指定位置的元素 @返回先前在指定位置的元素 @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E set(int index, E element) {
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
/**
将指定的元素追加到此列表的末尾。@要附加到此列表的参数元素 @返回 true (由{@link Collection#add}指定)
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
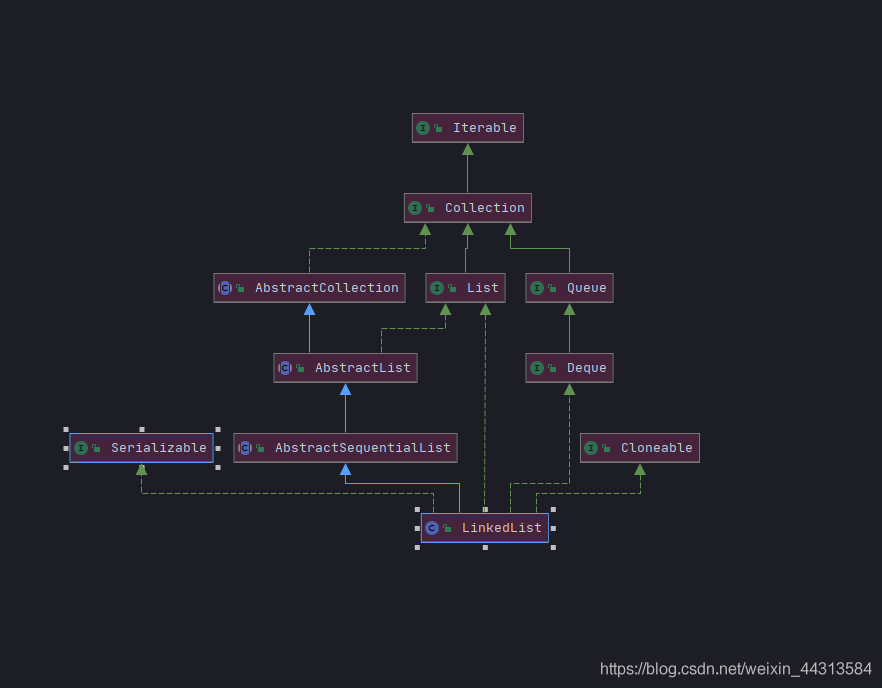
LinkedList(双向链表)
LinkedList是一种链表结构,从UML图可以看到,LinkList接口实现了Queue接口和List接口
进LinkList源码看看
List和Deque接口的双链列表实现。实现所有可选的列表操作(实现了List的全部方法),并允许所有元素(包括null)
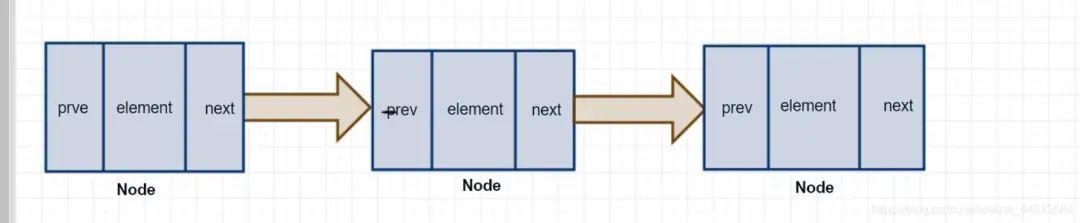
LinkedList由一个头节点和一个尾节点组成,分别指向链表的头部和尾部。
/** {@code List}和{@code Deque}接口的双链列表实现。实现所有可选的列表操作,
并允许所有元素(包括{@code null})。
所有操作均按双链接列表的预期执行。索引到列表中的操作将从开头或结尾遍历列表,
以更接近指定索引的位置为准。
*/
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0;
/**
指向第一个节点的指针
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
指向最后一个节点的指针
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
/**
构造一个空List
*/
public LinkedList() {
}
/**
构造一个包含指定集合的元素的List,其顺序由集合的迭代器返回。
@param c 要将其元素放入此List的集合
如果指定的集合为null,则抛出NullPointerException
*/
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
/** Node节点*/
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
}
数据结构中链表的头插法linkFirst和尾插法linkLast
/**
* Links e as last element.
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
/**
* Inserts element e before non-null Node succ.
*/
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
LinkList的查询方法
/**
返回此列表中指定位置的元素,要遍历,找到节点才能拿到元素
*/
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
/**返回指定元素索引处的(非空)节点 */
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
注意!ArrayList随机访问比LinkedList快的原因,LinkedList要遍历找到该位置才能进行修改,而ArrayList是内部数组操作会更快
(1)ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
(2)对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要遍历找节点。
(3)对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。这一点要看实际情况的。若只对单条数据插入或删除,ArrayList的速度反而优于LinkedList。但若是批量随机的插入删除数据,LinkedList的速度大大优于ArrayList. 因为ArrayList每插入一条数据,要移动插入点及之后的所有数据。
Vector
Vector类实现了对象的可增长数组。像数组一样,初始数组大小为10和ArrayList相同,它包含可以使用整数索引访问的组件。但是Vector的大小可以根据需要增大或缩小,以适应创建Vector之后的添加和删除项;
与新的集合实现不同,Vector是同步的,线程安全的。如果不需要线程安全实现,建议使用 ArrayList代替 Vector,ArrayList是线程不安全的
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
/**
向量分量存储在其中的数组缓冲区。
向量的容量是此数组缓冲区的长度,
并且至少足够大以包含所有向量的元素。
Vector中最后一个元素之后的所有数组元素均为null
*/
protected Object[] elementData;
/**
此Vector对象中有效组件的数量
* @serial
*/
protected int elementCount;
/**
向量的容量在其大小大于其容量时自动增加的量。如果容量增量小于或等于零,
则向量的容量每次需要增长时都会加倍。
* @serial
*/
protected int capacityIncrement;
/** 使用JDK 1.0.2中的serialVersionUID来实现互操作性 */
private static final long serialVersionUID = -2767605614048989439L;
/**
使用指定的初始容量和容量增量构造一个空向量。 @param initialCapacity向量的初始容量
@param Capacity增大向量溢出时容量增加的数量
如果指定的初始容量为负,则抛出IllegalArgumentException
*/
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
/**
构造一个具有指定初始容量和*容量增量等于零的空向量。
@param initialCapacity向量的初始容量
@如果指定的initialCapacity为负,则抛出IllegalArgumentException
*/
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}
/**
构造一个空向量,以便其内部数据数组的大小为 10,并且其标准容量增量为零
*/
public Vector() {
this(10);
}
/**
构造一个向量,该向量包含指定集合的元素,
并按集合的迭代器返回它们的顺序。
@param c 将元素放置在此向量中的集合
如果指定的集合为null,则抛出NullPointerException
*/
public Vector(Collection<? extends E> c) {
elementData = c.toArray();
elementCount = elementData.length;
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, elementCount, Object[].class);
}
为什么Vector是线程安全的?
vector是线程同步的,所以它也是线程安全的,而arraylist是线程异步的,是不安全的。如果不考虑到线程的安全因素,一般用arraylist效率比较高
使用synchronized给方法加锁,达到线程安全的目的;
..........
public synchronized E get(int index) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
return elementData(index);
}
public synchronized E set(int index, E element) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
............
ArrayList是非线程安全的,Vector是线程安全的;
HashMap是非线程安全的,HashTable是线程安全的;
StringBuilder是非线程安全的,StringBuffer是线程安全的。
Vector和ArrayList扩容数组的区别
ArrayList扩容数组1.5倍,扩容50%;
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
Vector扩容数组2倍,扩容100%;
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
Set接口
Set里存放的对象是无序,不能重复的,集合中的对象不按特定的方式排序,只是简单地把对象加入集合中。
不包含重复元素的集合
HashSet(无序)
此类实现由散列表(实际上是 HashMap 实例)支持的Set接口。它不保证集合的迭代顺序。特别是,它不能保证顺序会随时间保持不变。此类允许null 元素
如果多个线程同时访问哈希集,并且线程中的至少一个修改了哈希集,则它必须 </ i> >从外部进行同步。这通常是通过对自然封装了该集合的某个对象进行同步来完成的。如果不存在这样的对象,则应使用Collections synchronized Set Collections.synchronizedSet} 方法来“包装”该集合。最好在创建时完成此操作,以防止意外异步访问集合;(说明Hashset线程不安全)
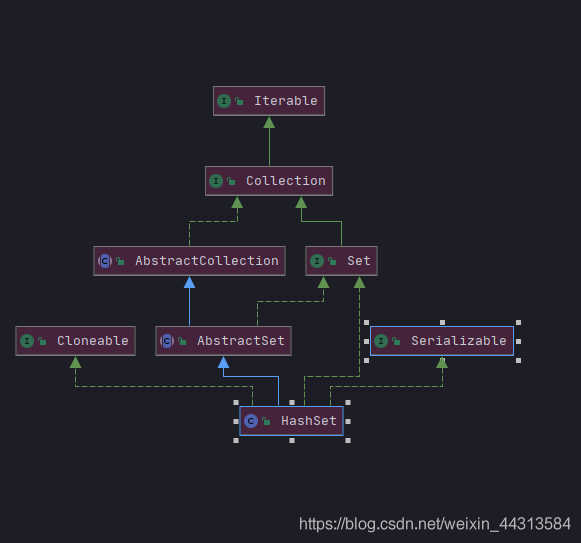
HashSet集合底层就是
HashMap(hashmap无序所以hashset也无序),基于二叉树的treemap,treeset有序
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
/**
构造一个新的空集
支持的HashMap实例具有默认初始容量(16)和负载因子(0.75)
*/
public HashSet() {
map = new HashMap<>();
}
/**
构造一个新集合,其中包含指定集合中的元素。
HashMap是使用默认负载因子(0.75)和足以容纳指定集合中的元素的初始容量创建的。
@param c 要将其元素放入此集合的集合
如果指定的集合为null,则抛出NullPointerException
*/
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
/**
构造一个新的空链接哈希集(此包private构造函数仅由LinkedHashSet使用)
支持 HashMap实例是具有指定的初始容量和指定的负载因子的LinkedHashMap。
@param initialCapacity 哈希图的初始容量
@param loadFactor 哈希图的负载因子
@param dummy(将此构造函数与其他int,float构造函数区分开。
@throws IllegalArgumentException如果初始容量为小于零,或者负载因子为非正
*/
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
HashSet怎么保证元素不重复?
public boolean add(E e) {
return map.put(e, PRESENT)==null; //map元素是不重复的 后面见到HashMap
}
HashSet是如何保证元素的唯一性?
//如果此集合已经包含元素,则调用将使该集合保持不变
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
------------------------------------------------------
public V put(K key, V value) { // HashMap中的put方法
return putVal(hash(key), key, value, false, true);
}
/** 首先会使用 hash() 函数生成一个 int 类型的 hashCode 散列值,然后与已经存储的元素的 hashCode 值作比较,如果 hashCode 值不相等,则所存储的两个对象一定不相等,此时把这个新元素存储在它的 hashCode 位置上;如果 hashCode 相等*/
TreeSet(有序)
基于TreeMap的NavigableSet实现。元素使用其{@link Comparable 自然排序}进行排序,或通过在集合创建时提供的{@link Comparator}进行排序,具体取决于所使用的构造函数。此实现为基本操作({@code add},{@ code remove}和{@code contains})提供了保证的log(n)时间成本。请注意,如果要正确实现{@code Set}接口,则集合(无论是否提供了显式比较器)所维护的顺序必须与equals 一致。
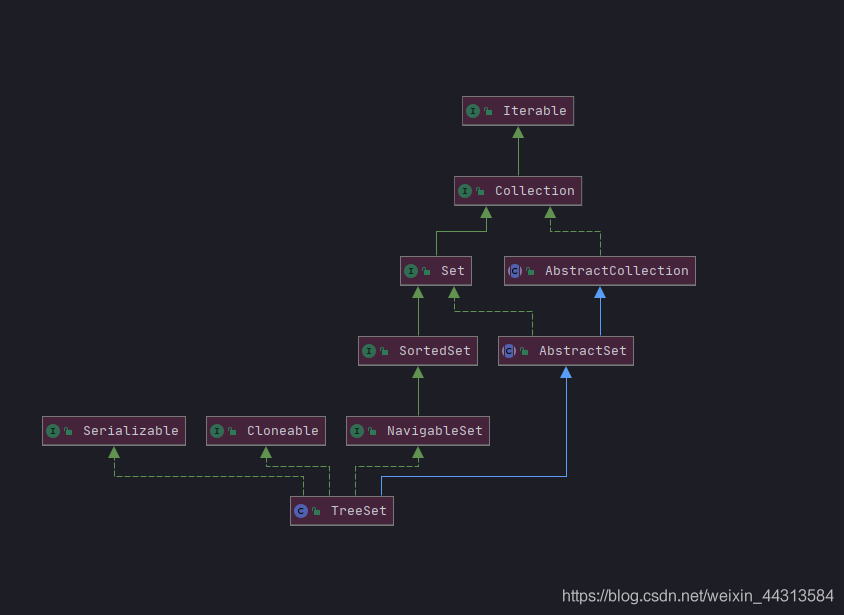
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
private transient NavigableMap<E,Object> m;
private static final Object PRESENT = new Object();
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
/**
构造一个新的空树集,并根据其元素的自然顺序进行排序。
插入到集合中的所有元素都必须实现{@link Comparable}接口
*/
public TreeSet() {
this(new TreeMap<E,Object>());
}
/**
构造一个新的空树集,并根据指定的比较器进行排序。
插入到集合中的所有元素都必须由指定的比较器进行相互比较:
{@code比较器.compare(e1,* e2)}
*/
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
/**
*构造一个新的树集,其中包含指定集合中的元素,并根据其元素的自然顺序进行排序。
插入集合中的所有元素都必须实现{@link Comparable}接口。
此外,所有此类元素必须可相互比较:
@param c集合,其元素将组成新集合
*/
public TreeSet(Collection<? extends E> c) {
this();
addAll(c);
}

Map接口
将键(key)映射到值(value)的对象。映射不能包含重复的键;每个键最多可以映射到一个值
public interface Map<K,V> {
// Query Operations
/**
返回此映射中的键值映射数
*/
int size();
/**
如果此映射不包含键值映射,则返回true
*/
boolean isEmpty();
/**
如果此映射包含指定*键的映射,则返回true
*/
boolean containsKey(Object key);
/**
如果此映射将一个或多个键映射到指定值,则返回 true
*/
boolean containsValue(Object value);
/**
返回指定键所映射到的值
如果此映射不包含该键的映射,则返回 null
*/
V get(Object key);
// Modification Operations
/**
将指定值与此映射中的指定键关联(可选操作)
如果该映射先前包含键的映射,则旧值将替换为指定值
*/
V put(K key, V value);
/**
从该映射中删除键的映射(如果存在)
*/
V remove(Object key);
HashMap(链表加数组)
HashMap是 Map 接口的基于哈希表的实现。HashMap提供了所有可选的映射操作,并允许 null 值和null 键。HashMap类与 Hashtable大致等效,除了HashMap不同步并且允许空值。)此类不保证map的顺序;特别是,它不能保证顺序会随着时间的推移保持恒定;
HashMap是线程不安全的,HashTable是线程安全的
HashMap的常量组成
//是hashMap的最小容量16,容量就是数组的大小也就是变量,
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
//最大数量,该数组最大值为2^31一次方。
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认的加载因子,如果构造的时候不传则为0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//一个位置里存放的节点转化成树的阈值,也就是8,比如数组里有一个node,这个
// node链表的长度达到该值才会转化为红黑树。
static final int TREEIFY_THRESHOLD = 8;
//当一个反树化的阈值,当这个node长度减少到该值就会从树转化成链表
static final int UNTREEIFY_THRESHOLD = 6;
//满足节点变成树的另一个条件,就是存放node的数组长度要达到64
static final int MIN_TREEIFY_CAPACITY = 64;
//具体存放数据的数组
transient Node<K,V>[] table;
//entrySet,一个存放k-v缓冲区
transient Set<Map.Entry<K,V>> entrySet;
//size是指hashMap中存放了多少个键值对
transient int size;
//对map的修改次数
transient int modCount;
//加载因子
final float loadFactor;
HashMap的构造方法
//只有容量,initialCapacity
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
if (table == null) { // pre-size
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
if (t > threshold)
threshold = tableSizeFor(t);
}
else if (s > threshold)
resize();
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0) // 容量不能为负数
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
//当容量大于2^31就取最大值1<<31;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
//当前数组table的大小,一定是是2的幂次方
// tableSizeFor保证了数组一定是是2的幂次方,是大于initialCapacity最结进的值。
this.threshold = tableSizeFor(initialCapacity);
}
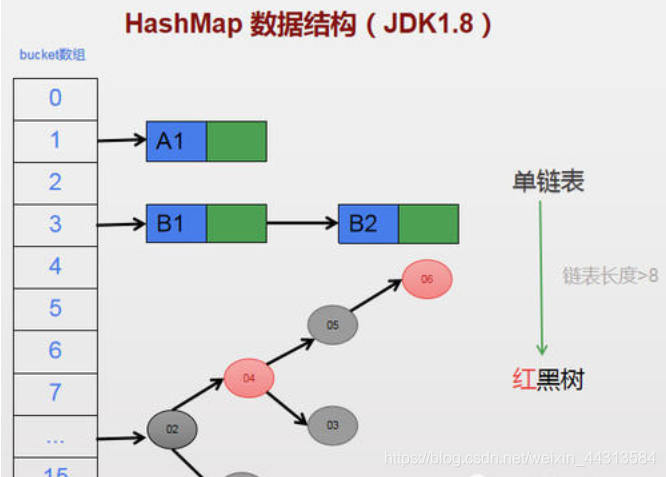
HashMap的哈希冲突解决方法-链式地址法
如何HashMap和HashTable存放数据的不同(哈希值的来源)?
HashMap的hash值:通过key的来计算得到的hash值,每一个hash值对应一个数组下标,由于不同的key值可能具有相同的hash值,即一个数组的某个位置出现两个相同的元素,对于这种情况,Hashmap采用链表的形式进行存储。(使用链表进行链接);
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
--------------------------------------------
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
HashTable的hash值:直接通过Key拿到hash值
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
HashMap采用Entry数组来存储key-value对,每一个键值对组成了一个Entry实体,Entry类实际上是一个单向的链表结构,它具有Next指针,可以连接下一个Entry实体。HashMap底层是以数组方式进行存储的。将key-value键值对作为数组的一个元素进行存储
只是在JDK1.8中,链表长度大于8的时候,链表会转成红黑树。
HashTable(链表加数组)
HashMap和Hashtable都实现了Map接口,并且都是key-value的数据结构。它们的不同点主要在三个方面:
(1)Hashtable是Java1.1的一个类,它基于陈旧的Dictionary类。而HashMap是Java1.2引进的Map接口的一个实现。
(2)Hashtable是线程安全的,也就是说是线程同步的,而HashMap是线程不安全的。也就是说在单线程环境下应该用HashMap,这样效率更高。
(3)HashMap允许将null值作为key或value,但Hashtable不允许(会抛出NullPointerException)。
(4)哈希值的使用不同:HashTable直接使用对象的hashCode,HashMap重新计算hash值,而且用与代替求模;
(5)HashTable中hash数组默认大小是11,增加的方式是 old*2+1。
HashMap中hash数组的默认大小是16,而且一定是2的指数。
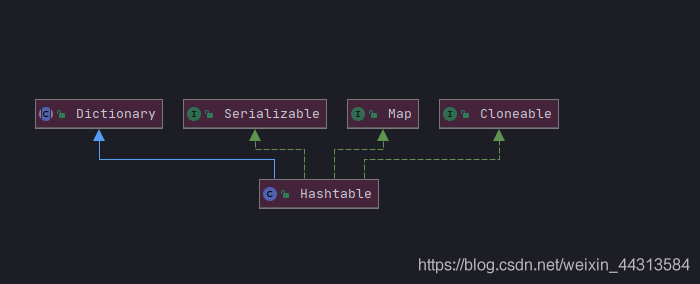
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable {
/**
哈希表数据
*/
private transient Entry<?,?>[] table;
/**
哈希表中的条目总数
*/
private transient int count;
/**
当表的大小超过此阈值时,表将被重新映射。
(此字段的值为(int)(capacity loadFactor)。
*/
private int threshold;
/**
哈希表的加载因子
*/
private float loadFactor;
/**
此哈希表经过结构修改的次数
*/
private transient int modCount = 0;
/** use serialVersionUID from JDK 1.0.2 for interoperability */
private static final long serialVersionUID = 1421746759512286392L;
/**
*使用指定的初始容量和指定的负载因子构造一个新的空哈希表
*/
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry<?,?>[initialCapacity];
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}
/**
使用指定的初始容量和默认的加载因子(0.75)构造一个新的空哈希表
*/
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);
}
/**
构造一个新的空哈希表,其默认初始容量(11)*和负载因子(0.75)
*/
public Hashtable() {
this(11, 0.75f);
}
/**
*构造一个新的哈希表,该哈希表具有与给定 Map相同的映射。
创建哈希表时,其初始容量应足以将给定Map中的映射保存并具有默认的加载因子(0.75)
*/
public Hashtable(Map<? extends K, ? extends V> t) {
this(Math.max(2*t.size(), 11), 0.75f);
putAll(t);
}
为什么HashTable线程安全?
方法使用 synchronized获取锁,实现线程安全
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
ConcurrentHashMap
哈希表支持检索的完全并发和更新的高期望并发。此类遵循与{@link java.util.Hashtable}相同的功能规范,并且包含与{{code Hashtable}的每个方法相对应的方法的版本。但是,即使所有操作都是线程安全的,但检索操作 并不需要进行锁定,并且 对以锁定方式锁定整个表没有任何支持阻止所有访问。在依赖于其线程安全但不依赖于其同步详细信息的程序中,此类可以与{@code Hashtable}完全互操作

static class Segment<K,V> extends ReentrantLock implements Serializable {
private static final long serialVersionUID = 2249069246763182397L;
final float loadFactor;
Segment(float lf) { this.loadFactor = lf; }
}
ConcurrentHashMap 中有一个 Segment 的概念。Segment 本身就相当于一个 HashMap 对象。同 HashMap 一样,Segment 包含一个 HashEntry 数组,数组中的每一个 HashEntry 既是一个键值对,也是一个链表的头节点;
ConcurrentHashMap 集合中有 2 的N次方个 Segment 对象,共同保存在一个名为 segments 的数组当中;
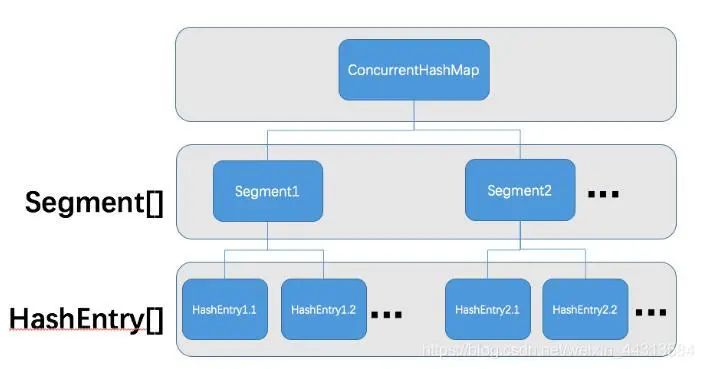

采取了锁分段技术,每一个 Segment 就好比一个自治区,读写操作高度自治,Segment 之间互不影响;
但是操作同一个 Segment需要加锁的,但检索操作 并不需要进行锁定,并且
对以锁定方式锁定整个表没有任何支持阻止所有访问。在依赖于其线程安全但不依赖于其同步详细信息的程序中,此类可以与Hashtable完全互操作
总结:ConcurrentHashMap是线程安全的,并且锁分离。ConcurrentHashMap内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的hash table,它们有自己的锁。只要多个修改操作发生在不同的段上,它们就可以并发进行
————————————————
版权声明:本文为CSDN博主「代码与她皆过客」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:
https://blog.csdn.net/weixin_44313584/article/details/115051897
锋哥最新SpringCloud分布式电商秒杀课程发布
👇👇👇
👆长按上方微信二维码 2 秒
感谢点赞支持下哈 